BiomedAP: A Vision-Informed Dual-Anchor Framework with Gated Cross-Modal Fusion for Robust Medical Vision-Language Adaptation
Pith reviewed 2026-05-20 19:15 UTC · model grok-4.3
The pith
BiomedAP stabilizes medical vision-language adaptation by fusing modalities layer-wise and anchoring prompts to expert and visual centroids.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
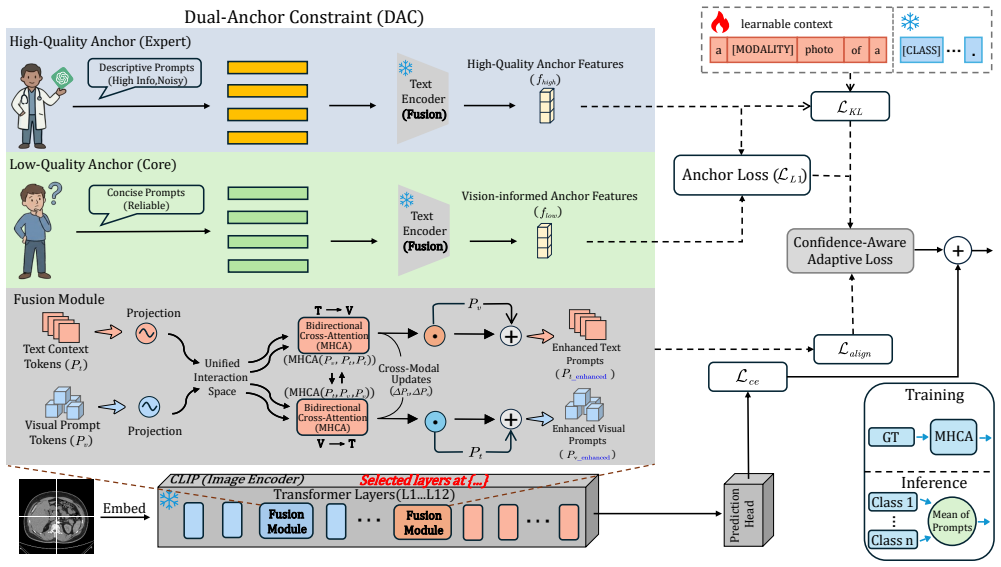
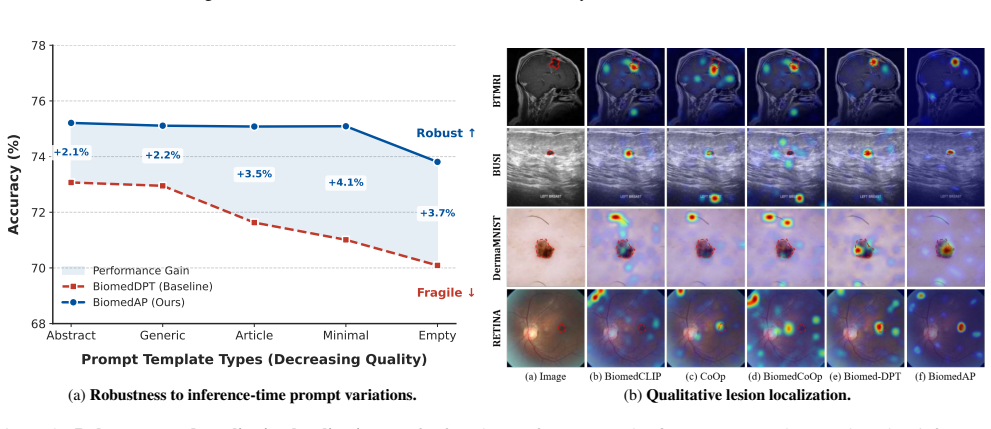
BiomedAP claims that synergistic alignment between vision and language streams, achieved by enabling layer-wise gated interaction to filter irrelevant textual signals and by constraining prompts to dual semantic centroids from high-level expert templates and low-level visual prototypes, produces robust few-shot medical diagnosis that remains stable even when input descriptions deviate from ideal forms.
What carries the argument
Gated Cross-Modal Fusion, which performs layer-wise modality interaction to act as a dynamic noise regulator, together with Dual-Anchor Constraint, which regularizes prompts toward stable centroids from expert templates and visual prototypes.
If this is right
- Outperforms prior adaptation methods on eleven medical benchmarks in few-shot accuracy.
- Maintains performance when textual prompts contain noise or heterogeneity typical of clinical notes.
- Reduces reliance on perfectly crafted golden prompts by enforcing cross-modal interaction and semantic anchoring.
- Provides a parameter-efficient way to adapt vision-language models without full retraining.
Where Pith is reading between the lines
- The same dual-anchor idea might help stabilize prompt-based adaptation in other noisy text domains such as legal document analysis.
- Combining this framework with larger pretrained backbones could further reduce the number of shots needed for reliable medical classification.
- Direct evaluation on raw physician dictation transcripts would test whether the noise-suppression effect holds outside curated benchmarks.
Load-bearing premise
The gated fusion and dual-anchor mechanisms will suppress irrelevant textual cues and stabilize alignment when clinical descriptions are noisy and heterogeneous.
What would settle it
A controlled test on held-out medical datasets using deliberately varied prompt perturbations where removing either the gated fusion or the dual-anchor component eliminates the reported robustness gains over standard prompt-learning baselines.
Figures


read the original abstract
Biomedical Vision--Language Models (VLMs) have shown remarkable promise in few-shot medical diagnosis but face a critical bottleneck: \textit{fragility to prompt variations}.Existing adaptation frameworks typically optimize visual and textual prompts as independent streams, relying on ideal ``Golden Prompts''. In clinical reality, where descriptions are often noisy and heterogeneous, this modality isolation leads to unstable cross-modal alignment. To address this, we propose BiomedAP, a vision-informed dual-anchor framework with gated cross-modal fusion.BiomedAP enforces synergistic alignment through two mechanisms: (1) Gated Cross-Modal Fusion, which enables layer-wise interaction between modalities, acting as a dynamic noise regulator to suppress irrelevant textual cues; and (2) a Dual-Anchor Constraint that regularizes learnable prompts toward stable semantic centroids derived from both expert templates (High Anchors) and few-shot visual prototypes (Low Anchors). Extensive experiments across 11 benchmarks demonstrate that BiomedAP consistently surpasses baselines, achieving competitive few-shot accuracy and markedly enhanced robustness under prompt perturbations. Our code is available at: https://github.com/tongdiedie/BiomedAP. Keywords: Vision-Language Models; Prompt Learning; Parameter-Efficient Fine-Tuning; Few-shot Learning
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BiomedAP, a vision-informed dual-anchor framework for adapting biomedical vision-language models. It introduces Gated Cross-Modal Fusion to enable layer-wise modality interaction as a dynamic noise regulator suppressing irrelevant textual cues, and a Dual-Anchor Constraint that regularizes learnable prompts toward semantic centroids from expert templates (High Anchors) and few-shot visual prototypes (Low Anchors). The central claim is that these mechanisms produce synergistic alignment, yielding competitive few-shot accuracy and markedly improved robustness to prompt perturbations across 11 benchmarks.
Significance. If the empirical claims hold and the mechanisms are shown to drive the gains, the work would address a practical limitation in medical VLMs—fragility to noisy, heterogeneous clinical prompts—potentially improving reliability in few-shot diagnosis settings. Code release supports reproducibility, which strengthens the contribution if the results prove robust to the noted validation gaps.
major comments (2)
- [Experiments] Experiments section: the manuscript reports consistent outperformance and enhanced robustness on 11 benchmarks but provides no component-wise ablations that isolate Gated Cross-Modal Fusion and Dual-Anchor Constraint while holding total compute, prompt length, and optimization schedule fixed. Without such controls it remains unclear whether the observed robustness under prompt perturbations arises from the proposed noise regulation and centroid stabilization or from other unstated factors such as dataset preprocessing or base VLM choice.
- [Method] Method section (Dual-Anchor Constraint): the regularization toward High Anchors (expert templates) and Low Anchors (visual prototypes) is presented as stabilizing alignment, yet the precise computation of the semantic centroids, the weighting between anchors, and their integration into the prompt optimization objective are not fully specified with equations or pseudocode. This leaves the load-bearing claim that the constraint produces stable cross-modal alignment open to alternative interpretations.
minor comments (2)
- [Abstract] Abstract: quantitative improvements (e.g., accuracy deltas or robustness metrics) and baseline names are omitted, reducing the ability to assess the scale of the claimed gains without reading the full results tables.
- [Results] Figure captions and tables: several result tables lack error bars or statistical significance markers, which would help evaluate whether reported improvements are reliable across the 11 benchmarks.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the manuscript reports consistent outperformance and enhanced robustness on 11 benchmarks but provides no component-wise ablations that isolate Gated Cross-Modal Fusion and Dual-Anchor Constraint while holding total compute, prompt length, and optimization schedule fixed. Without such controls it remains unclear whether the observed robustness under prompt perturbations arises from the proposed noise regulation and centroid stabilization or from other unstated factors such as dataset preprocessing or base VLM choice.
Authors: We agree that isolating the individual contributions of Gated Cross-Modal Fusion and Dual-Anchor Constraint through controlled ablations is essential to substantiate our claims. In the revised version, we will add a dedicated ablation subsection that removes or disables each component in turn while strictly holding total compute budget, prompt length, and the optimization schedule fixed across variants. These new experiments will use the same base VLM and standardized preprocessing pipeline described in the current experimental setup, allowing direct attribution of robustness gains to the proposed mechanisms rather than confounding factors. revision: yes
-
Referee: [Method] Method section (Dual-Anchor Constraint): the regularization toward High Anchors (expert templates) and Low Anchors (visual prototypes) is presented as stabilizing alignment, yet the precise computation of the semantic centroids, the weighting between anchors, and their integration into the prompt optimization objective are not fully specified with equations or pseudocode. This leaves the load-bearing claim that the constraint produces stable cross-modal alignment open to alternative interpretations.
Authors: We appreciate this observation on the need for greater mathematical precision. Although the high-level motivation and roles of the anchors are described in the method section, we acknowledge that explicit formulations would remove ambiguity. In the revision we will insert the exact equations for computing the High-Anchor centroid from expert templates and the Low-Anchor centroid from few-shot visual prototypes, define the weighting hyper-parameter that balances the two terms, and present the complete prompt-optimization objective that incorporates the Dual-Anchor Constraint. We will also include pseudocode for the overall training procedure to ensure the implementation is fully reproducible from the text. revision: yes
Circularity Check
No circularity: empirical architectural proposal with independent validation
full rationale
The paper introduces BiomedAP as a new framework combining gated cross-modal fusion and dual-anchor constraints for prompt learning in medical VLMs. No equations, derivations, or first-principles claims appear in the provided text that reduce any result to a fitted parameter or self-defined quantity by construction. Claims of improved robustness rest on empirical results across 11 benchmarks rather than self-citation chains or ansatz smuggling. This matches the default case of a self-contained empirical method without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Gated Cross-Modal Fusion... dynamic noise regulator to suppress irrelevant textual cues; Dual-Anchor Constraint that regularizes learnable prompts toward stable semantic centroids
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Gated Cross-Modal Fusion... layer-wise interaction between modalities
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mutual prompt leaning for vision language models.Interna- tional Journal of Computer Vision, 2024. 2
work page 2024
-
[2]
Benedikt Boecking et al. Making the most of text semantics to improve biomedical vision–language processing.arXiv preprint arXiv:2204.09817, 2022. 2
-
[3]
Sedigheh Eslami, Gerard de Melo, and Christoph Meinel. Does CLIP benefit visual question answering in the medical domain as much as it does in the general domain?arXiv preprint arXiv:2112.13906, 2021. 7
-
[4]
CLIP-Adapter: Better vision-language models with feature adapters.IJCV, 132(2):581–595, 2024
Peng Gao, Shijie Geng, Renrui Zhang, Tianshu Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. CLIP-Adapter: Better vision-language models with feature adapters.IJCV, 132(2):581–595, 2024. 2, 5
work page 2024
-
[5]
Domain-specific language model pre- training for biomedical natural language processing
Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. Domain-specific language model pre- training for biomedical natural language processing. InPro- ceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021. 4, 7
work page 2021
-
[6]
Parameter-Efficient Transfer Learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP.arXiv preprint arXiv:1902.00751, 2019. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[7]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021. 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Shih-Cheng Huang, Liyue Shen, Matthew P. Lungren, and Serena Yeung. GLoRIA: A multimodal global-local repre- sentation learning framework for label-efficient medical im- age recognition. InICCV, pages 3942–3951, 2021. 2
work page 2021
-
[9]
LP++: A surprisingly strong linear probe for few-shot CLIP
Yunshi Huang, Fereshteh Shakeri, Jose Dolz, Malik Boudiaf, Houda Bahig, and Ismail Ben Ayed. LP++: A surprisingly strong linear probe for few-shot CLIP. InCVPR, pages 28496–28506, 2024. 5
work page 2024
-
[10]
Promptsmooth: Certifying robustness of medical vision-language models via prompt learning
Noor Hussein, Fahad Shamshad, Muzammal Naseer, and Karthik Nandakumar. Promptsmooth: Certifying robustness of medical vision-language models via prompt learning. In Medical Image Computing and Computer Assisted Interven- tion – MICCAI 2024, 2024. 2
work page 2024
-
[11]
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, and Bharath Hariharan. Visual prompt tun- ing. InECCV, pages 709–727, 2022. 1, 2, 3
work page 2022
-
[12]
Memory-space visual prompting for ef- ficient vision-language fine-tuning
Shibo Jie, Yehui Tang, Ning Ding, Zhi-Hong Deng, Kai Han, and Yunhe Wang. Memory-space visual prompting for ef- ficient vision-language fine-tuning. InProceedings of the 41st International Conference on Machine Learning, pages 22062–22074, 2024. 2
work page 2024
-
[13]
MaPLe: Multi-modal prompt learning
Muhammad Uzair Khattak, Hanoona Rasheed, Muhammad Maaz, Salman Khan, and Fahad Shahbaz Khan. MaPLe: Multi-modal prompt learning. InCVPR, pages 19113– 19122, 2023. 1, 7
work page 2023
-
[14]
Bayesian prin- ciples improve prompt learning in vision-language models
Mingyu Kim, Jongwoo Ko, and Mijung Park. Bayesian prin- ciples improve prompt learning in vision-language models. InProceedings of The 28th International Conference on Ar- tificial Intelligence and Statistics, pages 4078–4086, 2025. 2
work page 2025
-
[15]
BiomedCoOp: Learning to prompt for biomedical vision-language models
Taha Koleilat, Hojat Asgariandehkordi, Hassan Rivaz, and Yiming Xiao. BiomedCoOp: Learning to prompt for biomedical vision-language models. InCVPR, pages 14766– 14776, 2025. 2, 5
work page 2025
-
[16]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InProceed- ings of the 39th International Conference on Machine Learn- ing, pages 12888–12900, 2022. 2, 5
work page 2022
-
[17]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InPro- ceedings of the 40th International Conference on Machine Learning, pages 19730–19742, 2023. 2, 5
work page 2023
-
[18]
Querying as prompt: Parameter-efficient learn- ing for multimodal language model
Tian Liang, Jing Huang, Ming Kong, Luyuan Chen, and Qiang Zhu. Querying as prompt: Parameter-efficient learn- ing for multimodal language model. InCVPR, pages 26855– 26865, 2024. 2
work page 2024
-
[19]
arXiv preprint arXiv:2506.18378 , year=
Haoneng Lin, Cheng Xu, and Jing Qin. Taming vision- language models for medical image analysis: A comprehen- sive review.arXiv preprint arXiv:2506.18378, 2025. 2
-
[20]
Pmc-clip: Contrastive language-image pre-training using biomedical documents,
Weixiong Lin, Ziheng Zhao, Xiaoman Zhang, Chaoyi Wu, Ya Zhang, Yanfeng Wang, and Weidi Xie. PMC-CLIP: Con- trastive language-image pre-training using biomedical docu- ments.arXiv preprint arXiv:2303.07240, 2023. 7
-
[21]
Surrogate prompt learning: Towards efficient and diverse prompt learning for vision-language models
Liangchen Liu, Nannan Wang, Xi Yang, Xinbo Gao, and Tongliang Liu. Surrogate prompt learning: Towards efficient and diverse prompt learning for vision-language models. In Proceedings of the 42nd International Conference on Ma- chine Learning, pages 39755–39773, 2025. 2
work page 2025
-
[22]
AdapterBias: Parameter-efficient fine- tuning for vision-language models
Shilong Liu et al. AdapterBias: Parameter-efficient fine- tuning for vision-language models. InICCV, 2023. 1
work page 2023
-
[23]
Krumholz, Jure Leskovec, Eric J
Michael Moor, Oishi Banerjee, Zahra Shakeri Hossein Abad, Harlan M. Krumholz, Jure Leskovec, Eric J. Topol, Pranav Rajpurkar, et al. Foundation models for generalist medical artificial intelligence.Nature, 616:259–265, 2023. 1
work page 2023
-
[24]
Med-Flamingo: A multimodal medical few-shot learner.arXiv preprint arXiv:2307.15189, 2023
Michael Moor, Qian Huang, Shirley Wu, Michihiro Ya- sunaga, Cyril Zakka, Yash Dalmia, Eduardo Pontes Reis, Pranav Rajpurkar, and Jure Leskovec. Med-Flamingo: A multimodal medical few-shot learner.arXiv preprint arXiv:2307.15189, 2023. 1, 2, 7
-
[25]
Wei Peng, Kang Liu, Jianchen Hu, and Meng Zhang. Biomed-DPT: Dual modality prompt tuning for biomedical vision-language models.arXiv preprint arXiv:2505.05189,
-
[26]
Kvasir: A multi-class image dataset for com- puter aided gastrointestinal disease detection
Konstantin Pogorelov, Kristin Ranheim Randel, Carsten Gri- wodz, Sigrun Losada Eskeland, Thomas de Lange, Dag Johansen, Concetto Spampinato, Duc-Tien Dang-Nguyen, Mathias Lux, Peter Thelin Schmidt, Michael Riegler, and Pål Halvorsen. Kvasir: A multi-class image dataset for com- puter aided gastrointestinal disease detection. InProceedings of the 8th ACM o...
work page 2017
-
[27]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763, 2021. 1, 2, 3, 5, 7
work page 2021
-
[28]
Few-shot adaptation of medical vision-language models
Fereshteh Shakeri, Yunshi Huang, Julio Silva-Rodríguez, Houda Bahig, An Tang, Jose Dolz, and Ismail Ben Ayed. Few-shot adaptation of medical vision-language models. arXiv preprint arXiv:2409.03868, 2024. 2
-
[29]
Medclip: Contrastive learning from unpaired medical images and text
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. MedCLIP: Contrastive learning from unpaired medical images and text.arXiv preprint arXiv:2210.10163, 2022. 1, 2, 7
-
[30]
Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bilian Ke, Hanspeter Pfister, and Bingbing Ni. MedM- NIST v2: A large-scale lightweight benchmark for 2d and 3d biomedical image classification.Scientific Data, 10:41,
-
[31]
Visual- language prompt tuning with knowledge-guided context op- timization
Hantao Yao, Rui Zhang, and Changsheng Xu. Visual- language prompt tuning with knowledge-guided context op- timization. InCVPR, pages 6757–6766, 2023. 2, 5
work page 2023
-
[32]
Tip-Adapter: Training-free CLIP- adapter for better vision-language modeling
Renrui Zhang, Ziyu Wei, Rongyao Fang, Peng Gao, Hong- sheng Li, and Yu Qiao. Tip-Adapter: Training-free CLIP- adapter for better vision-language modeling. InECCV, pages 49–69, 2022. 1, 5
work page 2022
-
[33]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, Cliff Wong, Andrea Tupini, Yu Wang, Matt Mazzola, Swadheen Shukla, Lars Liden, Jianfeng Gao, Angela Crabtree, Brian Piening, Carlo Bifulco, Matthew P. Lungren, Tristan Naumann, Sheng Wang, and Hoifung Poon. BiomedCLIP: a multimoda...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering
Sheng Zhang et al. PMC-VQA: Visual question answer- ing over medical images with large-scale pretraining.arXiv preprint arXiv:2305.10415, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Conditional prompt learning for vision-language models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Zi- wei Liu. Conditional prompt learning for vision-language models. InCVPR, pages 16816–16825, 2022. 1, 2, 5
work page 2022
-
[36]
Learning to prompt for vision-language models.IJCV, 130(9):2337–2348, 2022
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.IJCV, 130(9):2337–2348, 2022. 1, 2, 3, 5, 7
work page 2022
-
[37]
Prompt-aligned gradient for prompt tuning
Beier Zhu, Yulei Niu, Yucheng Han, Yue Wu, and Hanwang Zhang. Prompt-aligned gradient for prompt tuning. InICCV, pages 15659–15669, 2023. 2, 5
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.