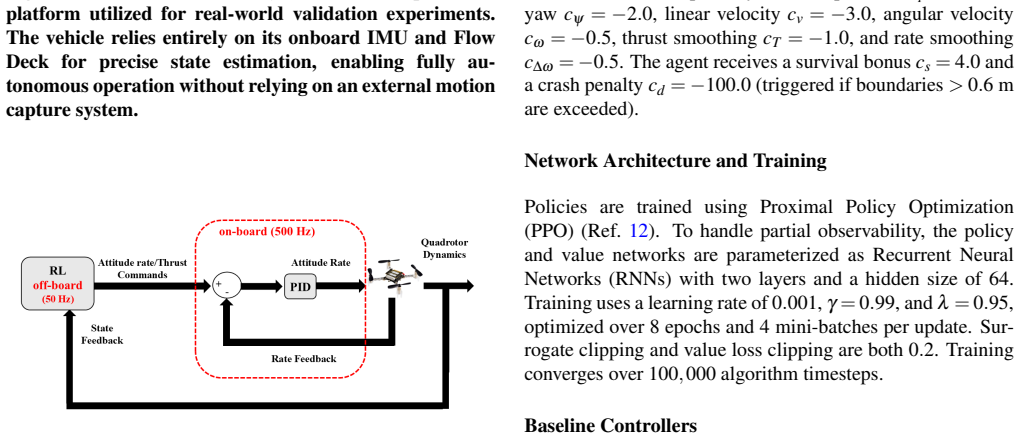
Adaptive Outer-Loop Control of Quadrotors via Reinforcement Learning
Pith reviewed 2026-05-20 18:26 UTC · model grok-4.3
The pith
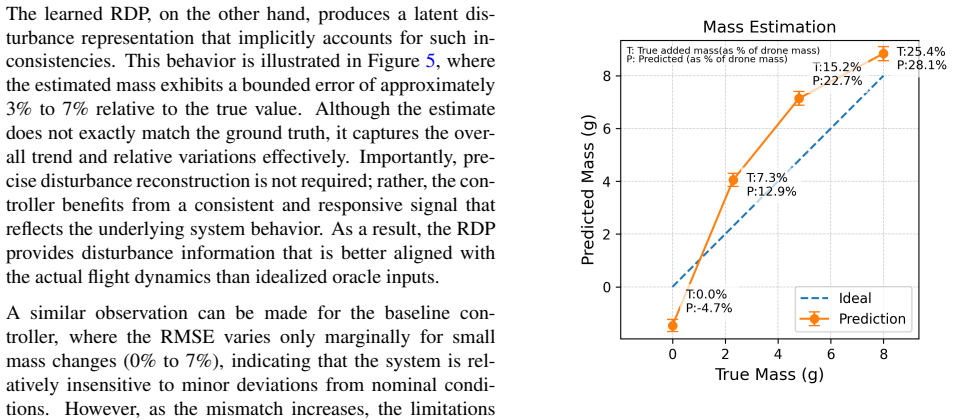
Replacing reliance on perfect simulation data with a Residual Dynamics Predictor lets a reinforcement learning outer-loop policy maintain precise quadrotor trajectory tracking under real-world mass changes, asymmetric payloads, and dynamic
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
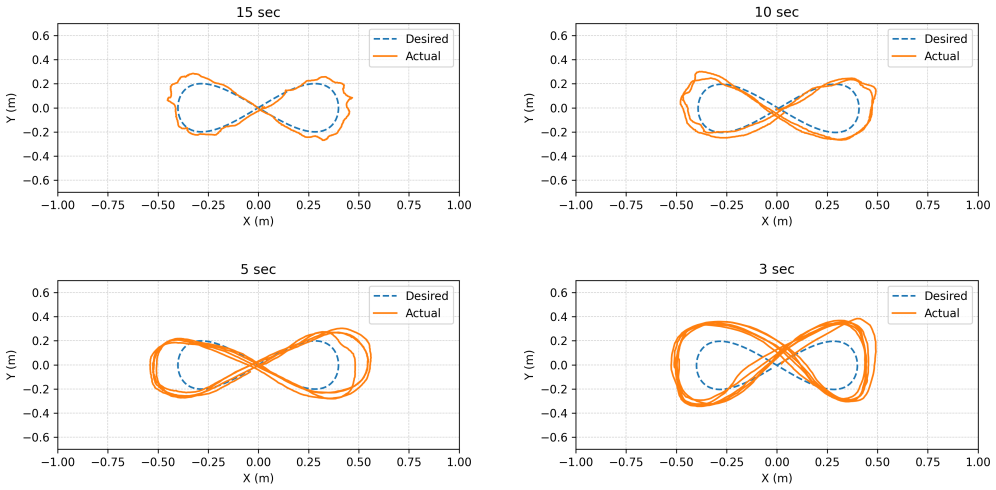
The paper establishes that an outer-loop reinforcement learning policy, augmented by a Residual Dynamics Predictor that infers external forces and moments online from state-action history alone, combined with a data-efficient calibration bridge and thrust correction, transfers successfully to hardware and outperforms baseline controllers in maintaining precise trajectory tracking on a Crazyflie quadrotor under mass variations, asymmetric payloads, and dynamic slung loads.
What carries the argument
The Residual Dynamics Predictor, which estimates instantaneous external forces and moments from the recent history of states and control actions without direct sensing.
If this is right
- The same outer-loop policy plus predictor structure can handle multiple classes of uncertainty without retraining the core policy.
- Hardware transfer requires only seconds of flight data rather than extensive fine-tuning or additional instrumentation.
- Trajectory tracking remains precise even when payloads are asymmetric or change dynamically during flight.
- The approach avoids the conservatism that arises when domain randomization alone is used to prepare for unknown disturbances.
Where Pith is reading between the lines
- Similar predictor-based adaptation could be applied to other rotorcraft or fixed-wing vehicles facing comparable disturbance regimes.
- The online force estimates might be logged to detect gradual changes in vehicle dynamics that signal the need for maintenance.
- Extending the calibration bridge to include environmental factors such as wind could further improve outdoor performance.
- The method might reduce the sensor payload required for robust autonomous flight in uncertain conditions.
Load-bearing premise
The Residual Dynamics Predictor can accurately estimate the current external forces and moments acting on the quadrotor using only past states and control inputs without additional sensors or hardware.
What would settle it
Flight tests in which a dynamic slung load is introduced and the Residual Dynamics Predictor produces force estimates that lead to trajectory tracking errors exceeding those of standard domain-randomization baselines would falsify the central claim.
Figures







read the original abstract
Deep Reinforcement Learning (DRL) for quadrotor flight control typically relies on Domain Randomization (DR) for sim-to-real transfer, resulting in overly conservative policies that struggle with dynamic disturbances. To overcome this, we propose a novel adaptive control architecture that actively perceives and reacts to instantaneous perturbations. First, we train an optimal outer-loop policy, then replace its reliance on ground-truth disturbance data with a Residual Dynamics Predictor (RDP). The RDP estimates the external forces and moments acting on the aircraft in flight online using only the history of states and control actions. For seamless hardware transfer, we introduce a data-efficient linear calibration bridge and an online thrust correction mechanism that align the simulated latent space with reality using mere seconds of flight data. Real-world validations on a Crazyflie micro-quadrotor demonstrate that our adaptive controller significantly outperforms baselines, maintaining precise trajectory tracking under severe uncertainties including mass variations, asymmetric payloads, and dynamic slung loads
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an adaptive outer-loop control architecture for quadrotors that trains an optimal RL policy in simulation and replaces ground-truth disturbance inputs with a Residual Dynamics Predictor (RDP). The RDP estimates instantaneous external forces and moments online from state-action history alone. A linear calibration bridge and online thrust correction enable sim-to-real transfer with seconds of flight data. Real-world Crazyflie experiments claim superior trajectory tracking versus baselines under mass variation, asymmetric payloads, and dynamic slung loads.
Significance. If validated, the approach offers a practical route to reactive adaptation in RL-based quadrotor control without extra sensors, addressing limitations of domain randomization for dynamic disturbances. The data-efficient calibration and real-world slung-load results would be useful contributions to aerial robotics if the RDP estimation bandwidth and accuracy are rigorously demonstrated.
major comments (2)
- [§4.2] §4.2 (RDP definition and training): The central claim that the RDP recovers instantaneous external forces/moments for fast-varying disturbances (e.g., dynamic slung loads) from state-action history alone is load-bearing. No quantitative results on estimation latency, bandwidth, or error during slung-load oscillation are provided; without these, it is unclear whether the predictor can invert the coupled residual dynamics at the required rate or whether lag undermines the reported adaptation advantage.
- [Results] Results section, performance tables: The outperformance under asymmetric payloads and slung loads is asserted, yet the tables report only mean errors without standard deviations, trial counts, or statistical tests. This prevents assessment of whether the gains are robust or could be explained by trial-to-trial variability.
minor comments (2)
- [Abstract] Abstract: The phrase 'significantly outperforms baselines' is used without any numerical values or error reductions; inserting one or two key quantitative results would make the claim concrete.
- [Notation] Notation: The symbol for estimated disturbance in Eq. (5) is easily confused with the policy output; a distinct symbol or explicit reminder in the text would reduce reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the two major comments point by point below, agreeing where the manuscript can be strengthened and outlining specific revisions.
read point-by-point responses
-
Referee: [§4.2] §4.2 (RDP definition and training): The central claim that the RDP recovers instantaneous external forces/moments for fast-varying disturbances (e.g., dynamic slung loads) from state-action history alone is load-bearing. No quantitative results on estimation latency, bandwidth, or error during slung-load oscillation are provided; without these, it is unclear whether the predictor can invert the coupled residual dynamics at the required rate or whether lag undermines the reported adaptation advantage.
Authors: We agree that explicit quantitative characterization of the RDP is necessary to substantiate its suitability for fast-varying disturbances. The manuscript currently supports the claim indirectly via end-to-end closed-loop tracking performance under dynamic slung loads, but does not report per-timestep estimation error, latency, or bandwidth during oscillation. In the revision we will add these metrics to §4.2 (or a new appendix), including time-series comparisons of predicted versus measured residual forces/moments, a frequency-domain bandwidth estimate, and measured latency relative to the control loop rate. This addition will directly address whether lag is negligible at the operating frequency. revision: yes
-
Referee: [Results] Results section, performance tables: The outperformance under asymmetric payloads and slung loads is asserted, yet the tables report only mean errors without standard deviations, trial counts, or statistical tests. This prevents assessment of whether the gains are robust or could be explained by trial-to-trial variability.
Authors: The observation is correct; the present tables contain only mean errors. We will revise the results section to report standard deviations, the number of independent trials per condition (ten flights), and the outcomes of paired statistical tests (e.g., t-tests with p-values) comparing our controller against each baseline under asymmetric payload and slung-load conditions. These changes will allow readers to evaluate the statistical robustness of the reported improvements. revision: yes
Circularity Check
No significant circularity; derivation relies on independent training and real-world validation
full rationale
The paper trains an outer-loop policy using ground-truth disturbances in simulation, then substitutes a separately trained Residual Dynamics Predictor (RDP) that maps state-action history to residual forces/moments. Real-world Crazyflie experiments under mass variation, payloads, and slung loads serve as external validation rather than a closed loop that reduces predictions to fitted inputs by construction. No self-definitional equations, load-bearing self-citations, or uniqueness theorems imported from prior author work are present in the abstract or described architecture. The RDP training and online calibration steps are presented as standard supervised learning followed by transfer, not as tautological renaming or forced equivalence.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The RDP estimates the external forces and moments acting on the aircraft in flight online using only the history of states and control actions.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate this system identification problem as a sequence-to-vector regression task... GRU layers... outputs the predicted 6D perturbation vector
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Neurobem: Hybrid aerodynamic quadrotor model,
L. Bauersfeld, E. Kaufmann, P. Foehn, S. Sun, and D. Scaramuzza, “Neurobem: Hybrid aerodynamic quadrotor model,”arXiv preprint arXiv:2106.08015, 2021
-
[2]
Playing Atari with Deep Reinforcement Learning
V . Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcement learning,”arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[3]
K. Wang, I. Javali, M. Bortkiewicz, B. Eysenbach,et al., “1000 layer networks for self-supervised rl: Scaling depth can enable new goal-reaching capabilities,”arXiv preprint arXiv:2503.14858, 2025
-
[4]
Control of a quadrotor with reinforcement learning,
J. Hwangbo, I. Sa, R. Siegwart, and M. Hutter, “Control of a quadrotor with reinforcement learning,” IEEE Robotics and Automation Letters, vol. 2, no. 4, pp. 2096–2103, 2017
work page 2096
-
[5]
Hy- brid reinforcement learning control for a micro quadro- tor flight,
J. Yoo, D. Jang, H. J. Kim, and K. H. Johansson, “Hy- brid reinforcement learning control for a micro quadro- tor flight,”IEEE Control Systems Letters, vol. 5, no. 2, pp. 505–510, 2020
work page 2020
-
[6]
Decentralized con- trol of quadrotor swarms with end-to-end deep rein- forcement learning,
S. Batra, Z. Huang, A. Petrenko, T. Kumar, A. Molchanov, and G. S. Sukhatme, “Decentralized con- trol of quadrotor swarms with end-to-end deep rein- forcement learning,” inConference on robot learning, pp. 576–586, PMLR, 2022
work page 2022
-
[7]
RMA: Rapid Motor Adaptation for Legged Robots
A. Kumar, Z. Fu, D. Pathak, and J. Malik, “Rma: Rapid motor adaptation for legged robots,”arXiv preprint arXiv:2107.04034, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
A learning-based quadcopter con- troller with extreme adaptation,
D. Zhang, A. Loquercio, J. Tang, T.-H. Wang, J. Malik, and M. W. Mueller, “A learning-based quadcopter con- troller with extreme adaptation,”IEEE Transactions on Robotics, 2025. 11
work page 2025
-
[9]
RAPTOR: A Foundation Policy for Quadrotor Control
J. Eschmann, D. Albani, and G. Loianno, “Raptor: A foundation policy for quadrotor control,”arXiv preprint arXiv:2509.11481, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Mu ˜noz, X. Yao, R. Zurbr ¨ugg, N. Rudin, L. Wawrzyniak, M. Rakhsha, A. Denzler, E. Heiden, A. Borovicka, O. Ahmed, I. Akinola, A. An- war, M. T. Carlson, J. Y . Feng, A. Garg, R. Gasoto, L. Gulich, Y . Guo, M. Gussert, A. Hansen, M. Kulkarni, C. Li, W. Liu, V . Makoviychuk, G. Malczyk,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Bitcraze, “Crazyflie 2.1 nano quadcopter.” https://www.bitcraze.io/products/ old-products/crazyflie-2-1/, 2024. Ac- cessed: 2026-04-15
work page 2024
-
[12]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” CoRR, vol. abs/1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
J. Chung, C. Gulcehre, K. Cho, and Y . Bengio, “Em- pirical evaluation of gated recurrent neural networks on sequence modeling,”arXiv preprint arXiv:1412.3555, 2014. 12
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.