An efficient multi-GPU implementation for the Discontinuous Galerkin ocean model SLIM
Pith reviewed 2026-05-19 18:37 UTC · model grok-4.3
The pith
A GPU-optimized Discontinuous Galerkin ocean model achieves the speed of roughly 1500 CPU cores on a single card and scales to 1024 GPUs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Mapping the DG-FE ocean equations to GPU kernels through optimized memory layouts, element-wise parallelization, and matrix-free treatment of vertical processes produces an implementation that runs efficiently on both NVIDIA and AMD GPUs, maintains weak scaling to 1024 devices, and supports real-world coastal runs at previously unattainable resolution.
What carries the argument
GPU kernels for Discontinuous Galerkin finite elements that use matrix-free vertical solvers and distributed multi-GPU communication.
If this is right
- A four-GPU node can replace a 128-core CPU node and deliver about fifty times higher throughput for the same coastal model.
- Spatial resolution five times finer than current best models becomes feasible while still running faster than real time.
- Weak scaling that holds to 1024 GPUs opens the door to ensemble forecasts or basin-scale high-resolution studies.
- The same kernel strategies apply to both NVIDIA and AMD architectures, reducing dependence on a single vendor.
Where Pith is reading between the lines
- Similar GPU mappings could be applied to other DG-based fluid models in atmosphere or ice-sheet science.
- Routine availability of such resolution may improve forecasts of localized coastal hazards such as reef bleaching or storm surge.
- The approach could be combined with adaptive mesh refinement to focus compute only where needed.
- Operational centers might adopt GPU clusters to run multiple high-resolution scenarios within the same wall-clock window.
Load-bearing premise
The Discontinuous Galerkin formulation and vertical processes can be turned into GPU kernels whose communication overhead stays low enough that the reported benchmarks remain representative of full production runs.
What would settle it
A timing measurement on the Great Barrier Reef case that shows the physical-to-numerical time ratio falling well below 100 because of unexpected data-transfer costs would falsify the performance claims.
Figures
















read the original abstract
Unstructured-mesh ocean models are increasingly used for coastal applications due to their ability to represent complex geometries and apply local grid refinement where needed. However, their broader use has been hindered by their high computational cost, particularly for models based on the Discontinuous Galerkin finite element (DG-FE) method, which involves significantly more degrees of freedom than traditional finite volume or continuous finite element approaches. The rapid emergence of GPU-based high-performance computing architectures now offers a pathway to address this limitation, as DG-FE formulations are inherently well suited to massively parallel, element-wise computations. Here, we present a full 3D DG-FE ocean model implementation optimized for both single- and multi-GPU systems, with support for both NVIDIA and AMD architectures. We detail the computational strategies employed to achieve high performance, including memory layout optimization, kernel-level parallelization, and matrix-free solvers for key vertical processes. Benchmark results demonstrate that a single HPC-grade GPU (e.g. NVIDIA A100) delivers performance equivalent to approximately 1500 CPU cores, while replacing a 128-core CPU node with a 4xA100 GPU node yields a speedup of around 50x. Weak-scaling efficiency is maintained up to 1024 GPUs. We further demonstrate the model's capabilities on a real-world application in the Great Barrier Reef, achieving a spatial resolution five times finer than the most accurate existing model while maintaining a physical-to-numerical time ratio of 100. These results highlight how GPU-accelerated DG-FE methods can dramatically advance the capabilities of unstructured-mesh ocean modeling, enabling ultra-high-resolution coastal simulations that were previously infeasible.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper presents an efficient implementation of the Discontinuous Galerkin finite element (DG-FE) ocean model SLIM for multi-GPU systems, including optimizations for memory layout, kernel parallelization, and matrix-free solvers. It reports performance benchmarks showing a single NVIDIA A100 GPU equivalent to approximately 1500 CPU cores, a 50x speedup when replacing a 128-core CPU node with a 4xA100 GPU node, maintained weak-scaling efficiency up to 1024 GPUs, and a real-world application to the Great Barrier Reef achieving five times finer spatial resolution with a physical-to-numerical time ratio of 100.
Significance. Should the reported performance and scaling results prove robust, this work would be significant for the field of computational ocean modeling. It demonstrates how GPU acceleration can overcome the high computational cost of DG-FE methods on unstructured meshes, potentially enabling ultra-high-resolution simulations of complex coastal environments that were not feasible before.
major comments (1)
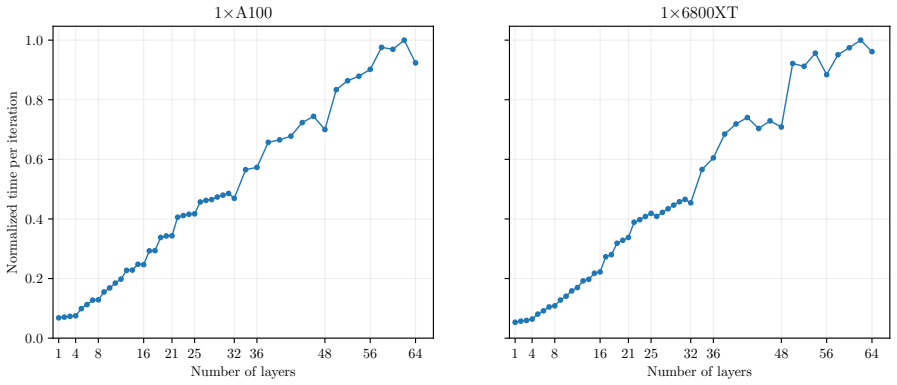
- [Weak scaling results] The claim that weak-scaling efficiency is maintained up to 1024 GPUs is central to the multi-GPU contribution. However, the manuscript does not provide a breakdown of the fraction of wall time spent on inter-GPU communication versus computation at large scales. On unstructured meshes with refinement, such as the Great Barrier Reef application, halo exchange volumes can be irregular and substantial; without profiling data showing that communication remains a small percentage of total time, the scaling efficiency cannot be confidently assessed.
minor comments (2)
- [Benchmark description] The performance equivalence of one A100 to 1500 CPU cores and the 50x node speedup lack accompanying error bars, details on the exact CPU configuration (e.g., core count per node, processor type), and verification that all overheads are accounted for in the 1500-core equivalence.
- [Abstract] The abstract mentions support for both NVIDIA and AMD architectures but provides no specific performance numbers for AMD GPUs, which would help assess portability.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the potential significance of our multi-GPU DG-FE implementation. We address the major comment below and will revise the manuscript to incorporate additional profiling data.
read point-by-point responses
-
Referee: [Weak scaling results] The claim that weak-scaling efficiency is maintained up to 1024 GPUs is central to the multi-GPU contribution. However, the manuscript does not provide a breakdown of the fraction of wall time spent on inter-GPU communication versus computation at large scales. On unstructured meshes with refinement, such as the Great Barrier Reef application, halo exchange volumes can be irregular and substantial; without profiling data showing that communication remains a small percentage of total time, the scaling efficiency cannot be confidently assessed.
Authors: We appreciate the referee's point that a communication-versus-computation breakdown would strengthen the scaling claims, particularly for the irregular halo exchanges that arise on locally refined unstructured meshes. The reported weak-scaling efficiencies are derived from full wall-clock timings that already include all inter-GPU communication; however, we agree that explicit profiling data would allow readers to assess the overhead more directly. In the revised manuscript we will add a new figure and accompanying text that report the measured fraction of wall time spent on halo exchanges (via CUDA-aware MPI or equivalent) at representative scale points up to 1024 GPUs. Where possible we will also include the corresponding breakdown for the Great Barrier Reef configuration. revision: yes
Circularity Check
No circularity: performance claims are direct experimental measurements
full rationale
This is an implementation and benchmarking paper whose central results consist of measured wall-clock times, speedups, and weak-scaling efficiencies obtained on actual GPU hardware. The reported equivalences (single A100 ≈ 1500 CPU cores, 50× node speedup, scaling to 1024 GPUs) and the Great Barrier Reef run metrics are direct outcomes of the described kernels and MPI/GPU-direct exchanges; they are not obtained by fitting parameters to a subset of the same data and then re-deriving the same quantities, nor by self-definitional equations or load-bearing self-citations. The derivation chain is therefore self-contained against external hardware benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of the Discontinuous Galerkin finite-element discretization for shallow-water and 3D ocean equations remain valid on GPU architectures.
Reference graph
Works this paper leans on
-
[1]
Allen Coral Atlas [Dataset] , shorttitle =. 2020 , publisher =. doi:10.5281/zenodo.3833242 , urldate =
-
[2]
Global Distribution of Coral Reefs, Compiled from Multiple Sources Including the Millennium Coral Reef Mapping Project [Dataset] , author =. 2021 , doi =
work page 2021
-
[3]
AusBathyTopo (Great Barrier Reef) 30m 2017 -- A Regional-Scale Depth Model (20170025C) [Dataset] , author =. 2020 , publisher =. doi:10.4225/25/5a207b36022d2 , urldate =
-
[4]
High Resolution Depth Model for the Great Barrier Reef and Coral Sea 100 m [Dataset] , author =. 2020 , publisher =. doi:10.26186/5E2F8BB629D07 , urldate =
-
[5]
Torres Strait Bathymetry 30m 2020 -- A High-Resolution Depth Model (20200021C) [Dataset] , author =. 2023 , publisher =. doi:10.26186/144348 , urldate =
-
[6]
2020 , month = mar, publisher =
Gulf of Papua Bathymetry Raster Dataset [Dataset] , author =. 2020 , month = mar, publisher =. doi:10.6084/m9.figshare.11986797.v1 , urldate =
-
[7]
Planet Dump Retrieved from https://planet.osm.org [Dataset] , author =. 2015 , urldate =
work page 2015
-
[8]
Bureau of Meteorology atmospheric high-resolution regional reanalysis for Australia -- Version 2 (BARRA2) [Dataset] , author =. 2023 , publisher =
work page 2023
-
[9]
Chamberlain, Matthew and. Bluelink. doi:10.25914/2WXJ-VT48 , urldate =
-
[10]
An oceanic general circulation model framed in hybrid isopycnic-Cartesian coordinates , author =. 2002 , journal =
work page 2002
-
[11]
BARRA2: Development of the next-generation Australian regional atmospheric reanalysis , author =. 2022 , institution =
work page 2022
-
[12]
BARRA-C2: Development of the kilometre-scale downscaled atmospheric reanalysis over Australia , author =. 2024 , institution =
work page 2024
-
[13]
Simulations in the era of exascale Computing , author =. 2023 , journal =
work page 2023
- [14]
-
[15]
Evolution of the graphics processing unit (GPU) , author =. 2021 , journal =
work page 2021
-
[16]
The finite-volume sea ice-ocean model (FESOM2) , author =. 2017 , journal =
work page 2017
-
[17]
Resolving eddies by local mesh refinement , author =. 2015 , journal =
work page 2015
-
[18]
A parallel local timestepping Runge--Kutta discontinuous Galerkin method with applications to coastal ocean modeling , author =. 2013 , journal =
work page 2013
-
[19]
Efficient inverse modeling of barotropic ocean tides , author =. 2002 , journal =
work page 2002
-
[20]
Fast, cheap, and turbulent---Global ocean modeling with GPU acceleration in python , author =. 2021 , journal =
work page 2021
-
[21]
K. Thetis coastal ocean model: Discontinuous Galerkin discretization for the three-dimensional hydrostatic equations , shorttitle =. 2018 , journal =
work page 2018
-
[22]
Korn, P. and Br. ICON-O: The ocean component of the ICON earth system model---Global simulation characteristics and local telescoping capability , shorttitle =. 2022 , journal =
work page 2022
-
[23]
2022 , month = mar, publisher =
NEMO ocean engine [Software] , author =. 2022 , month = mar, publisher =. doi:10.5281/zenodo.6334656 , urldate =
-
[24]
A finite-volume, incompressible Navier-Stokes model for studies of the ocean on parallel computers , author =. 1997 , journal =
work page 1997
- [25]
-
[26]
High performance regional ocean modeling with GPU acceleration , booktitle =
Panzer, Ian and Lines, Spencer and Mak, Jason and Choboter, Paul and Lupo, Chris , year =. High performance regional ocean modeling with GPU acceleration , booktitle =
-
[27]
Shchepetkin, Alexander F. and McWilliams, James C. , year =. The regional oceanic modeling system (ROMS): A split-explicit, free-surface, topography-following-coordinate oceanic model , shorttitle =. Ocean Modelling , volume =
-
[28]
A GPU-based ocean dynamical core for routine mesoscale-resolving climate simulations , author =. 2025 , journal =
work page 2025
-
[29]
Silvestri, Simone and Wagner, Gregory L. and Hill, Christopher and Ardakani, Matin Raayai and Blaschke, Johannes and Campin, Jean-Michel and Churavy, Valentin and Constantinou, Navid C. and Edelman, Alan and Marshall, John and Ramadhan, Ali and Souza, Andre and Ferrari, Raffaele , year =. Oceananigans.jl: A Julia library that achieves breakthrough resolut...
- [30]
-
[31]
A finite element model for the Venice Lagoon: Development, setup, calibration, and validation , author =. 2004 , month = nov, journal =. doi:10.1016/j.jmarsys.2004.05.009 , urldate =
-
[32]
High-level, high-resolution ocean modeling at all scales with Oceananigans , author =. 2025 , month = feb, number =. doi:10.48550/arXiv.2502.14148 , urldate =. 2502.14148 , archiveprefix =
-
[33]
Wang, Q. and Danilov, S. and Sidorenko, D. and Timmermann, R. and Wekerle, C. and Wang, X. and Jung, T. and Schr. The finite element sea ice-ocean model (FESOM) v1.4: Formulation of an ocean general circulation model , shorttitle =. 2014 , month = apr, journal =. doi:10.5194/gmd-7-663-2014 , urldate =
-
[34]
Accelerating LASG/IAP climate system ocean model version 3 for performance portability using Kokkos , author =. 2024 , month = nov, journal =. doi:10.1016/j.future.2024.06.029 , urldate =
-
[35]
A basin- to channel-scale unstructured grid hurricane storm surge model applied to southern Louisiana , author =. 2008 , month = mar, journal =. doi:10.1175/2007MWR1946.1 , urldate =
-
[36]
and Huang, Xiaomeng and Zhang, Yan and Fu, Haohuan and Oey, Lie-Yauw and Xu, Fanghua and Yang, G
Xu, S. and Huang, Xiaomeng and Zhang, Yan and Fu, Haohuan and Oey, Lie-Yauw and Xu, Fanghua and Yang, G. , year =. gpuPOM: A GPU-based Princeton Ocean Model , shorttitle =. Geoscientific Model Development Discussions , volume =
-
[37]
Seamless cross-scale modeling with SCHISM , author =. 2016 , month = jun, journal =. doi:10.1016/j.ocemod.2016.05.002 , urldate =
-
[38]
A multi-scale model of the hydrodynamics of the whole Great Barrier Reef , author =. 2008 , month = aug, journal =. doi:10.1016/j.ecss.2008.03.016 , urldate =
-
[39]
Biophysical model resolution affects coral connectivity estimates , author =. 2023 , month = jun, journal =. doi:10.1038/s41598-023-36158-5 , urldate =
-
[40]
Multi-scale modelling of coastal, shelf, and global ocean dynamics , author =. 2010 , journal =
work page 2010
-
[41]
Algorithms for density, potential temperature, conservative temperature, and the freezing temperature of seawater , author =. 2006 , month = dec, journal =. doi:10.1175/JTECH1946.1 , urldate =
-
[42]
Multiscale modeling of coastal, shelf, and global ocean dynamics , author =. 2013 , month = dec, journal =. doi:10.1007/s10236-013-0655-8 , urldate =
-
[43]
A baroclinic discontinuous Galerkin finite element model for coastal flows , author =. 2013 , month = jan, journal =. doi:10.1016/j.ocemod.2012.09.009 , urldate =
-
[44]
An efficient parallel implementation of explicit multirate Runge--Kutta schemes for discontinuous Galerkin computations , author =. 2014 , month = jan, journal =. doi:10.1016/j.jcp.2013.07.041 , urldate =
-
[45]
A generic length-scale equation for geophysical turbulence models , author =. 2003 , month = jan, journal =
work page 2003
-
[46]
A multi-scale IMEX second-order Runge--Kutta method for 3D hydrodynamic ocean models , author =. 2025 , month = jan, journal =. doi:10.1016/j.jcp.2024.113482 , urldate =
-
[47]
A split-explicit second-order Runge--Kutta method for solving 3D hydrodynamic equations , author =. 2023 , month = dec, journal =. doi:10.1016/j.ocemod.2023.102273 , urldate =
-
[48]
Discontinuous Galerkin discretization for two-equation turbulence closure models , author =. 2020 , month = jun, journal =. doi:10.1016/j.ocemod.2020.101619 , urldate =
-
[49]
Frontiers in Applied Mathematics, vol
Discontinuous Galerkin methods for solving elliptic and parabolic equations , author =. 2008 , month = jan, series =. doi:10.1137/1.9780898717440 , isbn =
-
[50]
Penalty-free discontinuous Galerkin methods for incompressible Navier--Stokes equations , author =. 2014 , journal =
work page 2014
-
[51]
Proceedings of the ACM/IEEE Supercomputing Conference (SC) , year=
The TOP500 list and progress in high-performance computing , author=. Proceedings of the ACM/IEEE Supercomputing Conference (SC) , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.