ShopGym: An Integrated Framework for Realistic Simulation and Scalable Benchmarking of E-Commerce Web Agents
Pith reviewed 2026-05-20 17:51 UTC · model grok-4.3
The pith
ShopGym turns live e-commerce sites into controllable sandbox shops that keep the same structural properties and produce matching agent performance signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ShopGym produces self-contained, resettable, inspectable, and stable evaluation artifacts that preserve structural properties and agent-evaluation signals relevant to shopping tasks. ShopArena converts live seed storefronts into sandbox shops through anonymized shop specifications and a staged, validated generation process. On top of these, ShopGuru synthesizes benchmark tasks across seven skill categories while grounding each task in the shop's catalog, navigation structure, policies, and interaction affordances. Results from graph-based structural analysis and agent-based behavioral evaluation confirm that the synthetic shops maintain key properties of live storefronts and that agent性能 on
What carries the argument
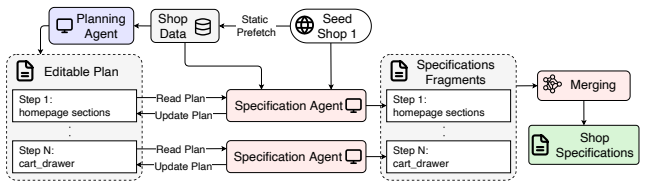
ShopArena, the simulation layer that converts live seed storefronts into self-contained sandbox shops through anonymized shop specifications and a staged, validated generation process.
If this is right
- Evaluation of web agents can use many diverse shops while remaining fully reproducible and inspectable.
- Benchmark tasks stay grounded in real catalog, navigation, and policy details rather than abstract templates.
- Agent performance measured in the synthetic environments tracks performance on the live versions they derive from.
- The same seed storefronts can generate multiple controlled variants for systematic comparison across skill categories.
Where Pith is reading between the lines
- The approach could support iterative agent development by allowing rapid resets and targeted variations without hitting live-site rate limits or non-stationarity.
- If the correlation between synthetic and live performance holds for a wider range of agent architectures, the framework might serve as a pre-deployment filter before live testing.
- Similar staged-generation methods could be applied to other interactive web domains such as travel booking or news reading to create analogous controlled environments.
Load-bearing premise
The anonymized shop specifications and staged generation process in ShopArena capture the essential navigation structure, catalog, policies, and interaction affordances of original live storefronts without introducing systematic biases that alter agent behavior or evaluation signals.
What would settle it
A controlled experiment in which the same agents are run on both the generated sandbox shops and their corresponding live storefronts, showing that success rates, error patterns, or performance rankings fail to correlate.
Figures








read the original abstract
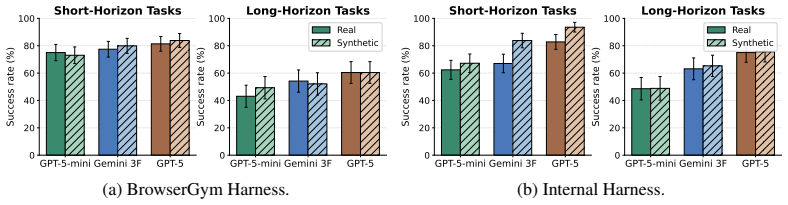
Developing and evaluating e-commerce web agents requires environments that preserve meaningful task structure while enabling controllable, reproducible, and scalable scientific comparison. Existing methodologies force a tradeoff: live storefronts provide realism but are non-stationary, difficult to inspect, and irreproducible, while hand-built sandbox benchmarks provide control but cover only a narrow range of layouts, catalogs, policies, and interaction patterns. We argue that the core bottleneck is methodological: the field lacks a scalable way to construct evaluation settings that are simultaneously realistic, diverse, controllable, inspectable, and reproducible. We introduce ShopGym, an integrated framework for realistic simulation and scalable benchmarking of e-commerce web agents. ShopGym is a framework for constructing e-commerce simulation environments and grounded benchmark tasks. Its simulation layer, ShopArena, converts live seed storefronts into self-contained sandbox shops through anonymized shop specifications and a staged, validated generation process. On top of these simulated storefronts, ShopGuru synthesizes benchmark tasks across seven skill categories, grounding each task in the shop's catalog, navigation structure, policies, and interaction affordances. Together, ShopArena and ShopGuru produce self-contained, resettable, inspectable, and stable evaluation artifacts that preserve structural properties and agent-evaluation signals relevant to shopping tasks. We validate the framework through graph-based structural analysis and agent-based behavioral evaluation with 224 generated tasks across six sandbox shops: three constructed with synthetic data and three with real data. Our results show that the synthetic shops preserve key structural properties of live storefronts, with agent performance on synthetic shops positively correlated with performance on live storefronts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ShopGym, a framework for realistic simulation and scalable benchmarking of e-commerce web agents. Its core components are ShopArena, which converts live seed storefronts into self-contained sandbox shops via anonymized specifications and a staged, validated generation process, and ShopGuru, which synthesizes benchmark tasks across seven skill categories grounded in each shop's catalog, navigation structure, policies, and interaction affordances. The authors validate the approach through graph-based structural analysis and behavioral evaluation on 224 tasks across six sandbox shops (three synthetic, three real), claiming that the synthetic shops preserve key structural properties of live storefronts and that agent performance on synthetic shops is positively correlated with performance on live storefronts.
Significance. If the central claims hold, ShopGym would address a key methodological bottleneck in e-commerce agent research by providing environments that are simultaneously realistic (grounded in live data), controllable, inspectable, and reproducible. The dual validation strategy combining structural graph metrics with behavioral agent runs on tasks derived from real storefront properties is a strength that could support more standardized and scalable evaluation protocols.
major comments (1)
- The headline claim that synthetic shops preserve structural properties and yield positively correlated agent performance (abstract) rests on behavioral evaluation across only six shops total. No correlation coefficient, p-value, exact performance metric (e.g., success rate or steps), or controls for task difficulty/shop size are reported, which is load-bearing for the external-validity argument that ShopArena faithfully captures navigation, catalog, and policy affordances without systematic biases.
minor comments (2)
- The abstract states the correlation exists but supplies limited detail on exact metrics, exclusion criteria, or statistical controls; adding these would improve clarity without altering the core contribution.
- Clarify how the 224 tasks are distributed across the six shops and whether aggregation was performed before computing correlations.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential of ShopGym to address methodological challenges in e-commerce agent evaluation. We address the major comment below, providing additional context from our experiments while committing to strengthen the reporting in revision.
read point-by-point responses
-
Referee: The headline claim that synthetic shops preserve structural properties and yield positively correlated agent performance (abstract) rests on behavioral evaluation across only six shops total. No correlation coefficient, p-value, exact performance metric (e.g., success rate or steps), or controls for task difficulty/shop size are reported, which is load-bearing for the external-validity argument that ShopArena faithfully captures navigation, catalog, and policy affordances without systematic biases.
Authors: We agree that quantitative details on the correlation strengthen the external-validity argument and will add them in revision. The behavioral evaluation uses task success rate (binary completion of the specified shopping goal within a step budget) as the primary metric, averaged across the 224 tasks. We will report the Pearson correlation coefficient and p-value computed over the three matched shop pairs (synthetic vs. live), along with per-shop success rates and standard deviations. Task difficulty was controlled by generating tasks from the same seven skill categories with equivalent grounding in catalog size, navigation depth, and policy complexity for each pair; shop size was matched by selecting live and synthetic instances with comparable numbers of products and categories. The structural analysis (detailed in Section 4.1) uses graph metrics including average shortest path length, degree distribution, and clustering coefficient to demonstrate preservation independent of the behavioral results. While the sample of three pairs limits statistical power, the consistent positive trend across pairs supports the claim as preliminary evidence; we will explicitly note the small n as a limitation and outline plans for larger-scale validation. revision: yes
Circularity Check
No significant circularity; validation is externally grounded
full rationale
The paper's core contribution is an empirical framework (ShopArena for generating sandbox shops from live seeds via anonymized specs and staged process, plus ShopGuru for task synthesis) whose validation rests on separate graph-structural metrics and agent behavioral runs across six independent shops (three synthetic, three real-data). The reported positive correlation between synthetic and live agent performance is computed from these external evaluations rather than defined into existence or fitted by construction within the work. No equations, self-definitional reductions, load-bearing self-citations, or ansatz smuggling appear; the derivation chain remains self-contained against the live storefront benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Live storefronts can be converted via anonymized specifications and staged generation into self-contained simulations that preserve structural properties and agent-evaluation signals.
invented entities (2)
-
ShopArena
no independent evidence
-
ShopGuru
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gym-Anything: Turn any Software into an Agent Environment
Pranjal Aggarwal, Graham Neubig, and Sean Welleck. Gym-anything: Turn any software into an agent environment.arXiv preprint arXiv:2604.06126, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Xu, Siva Reddy, Gra- ham Neubig, Quentin Cappart, Russ Salakhutdinov, and Nicolas Chapados
Thibault Le Sellier de Chezelles, Maxime Gasse, Alexandre Lacoste, Massimo Caccia, Alexan- dre Drouin, Léo Boisvert, Megh Thakkar, Tom Marty, Rim Assouel, Sahar Omidi Shayegan, Lawrence Keunho Jang, Xing Han Lù, Ori Yoran, Dehan Kong, Frank F. Xu, Siva Reddy, Gra- ham Neubig, Quentin Cappart, Russ Salakhutdinov, and Nicolas Chapados. The browsergym ecosys...
work page 2025
-
[5]
Mind2web: Towards a generalist agent for the web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samual Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. In Alice Oh, Tris- tan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Syst...
work page 2023
-
[6]
Go-browse: Training web agents with structured explo- ration
Apurva Gandhi and Graham Neubig. Go-browse: Training web agents with structured explo- ration. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=IpzRWE52yw
work page 2026
-
[7]
Webvoyager: Building an end-to-end web agent with large multimodal models
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024,...
-
[8]
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024,
work page 2024
-
[9]
URLhttps://arxiv.org/abs/2401.13649
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2023. URL https://api. semanticscholar.org/CorpusID:259360665
work page 2023
-
[11]
Can LLM Agents Simulate Multi-Turn Human Behavior? Evidence from Real Online Customer Behavior Data
Yuxuan Lu, Jing Huang, Yan Han, Bingsheng Yao, Sisong Bei, Jiri Gesi, Yaochen Xie, Qi He, Dakuo Wang, et al. Can llm agents simulate multi-turn human behavior? evidence from real online customer behavior data.arXiv preprint arXiv:2503.20749, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Deepshop: A benchmark for deep research shopping agents.arXiv preprint arXiv:2506.02839, 2025
Yougang Lyu, Xiaoyu Zhang, Lingyong Yan, Maarten de Rijke, Zhaochun Ren, and Xiuyi Chen. Deepshop: A benchmark for deep research shopping agents.ArXiv, abs/2506.02839, 2025. URLhttps://api.semanticscholar.org/CorpusID:279118560. 10
-
[13]
WebMall -- A Multi-Shop Benchmark for Evaluating Web Agents
Ralph Peeters, Aaron Steiner, Luca Schwarz, Julian Yuya Caspary, and Christian Bizer. Webmall–a multi-shop benchmark for evaluating web agents [technical report].arXiv preprint arXiv:2508.13024, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Akshit Sinha, Arvindh Arun, Shashwat Goel, Steffen Staab, and Jonas Geiping. The illusion of diminishing returns: Measuring long horizon execution in llms.ArXiv, abs/2509.09677, 2025. URLhttps://api.semanticscholar.org/CorpusID:281252776
-
[16]
Dakuo Wang, Ting-Yao Hsu, Yuxuan Lu, Hansu Gu, Limeng Cui, Yaochen Xie, William Headean, Bingsheng Yao, Akash Veeragouni, Jiapeng Liu, et al. Agenta/b: Automated and scalable web a/btesting with interactive llm agents.arXiv preprint arXiv:2504.09723, 2025
-
[17]
Shoppingbench: A real-world intent-grounded shopping benchmark for llm-based agents
Jiang Wang, Kejun Xiao, Qi Sun, Huaipeng Zhao, Tao Luo, Jiandong Zhang, and Xiaoyi Zeng. Shoppingbench: A real-world intent-grounded shopping benchmark for llm-based agents. In AAAI Conference on Artificial Intelligence, 2025. URL https://api.semanticscholar. org/CorpusID:280536823
work page 2025
-
[19]
Pei Wang, Yanan Wu, Xiaoshuai Song, Weixun Wang, Gengru Chen, Zhongwen Li, Ke Yan, Ken Deng, Qi Liu, Shu-Man Zhao, Shaopan Xiong, Xuepeng Liu, Xuefeng Chen, Wanxi Deng, Wenbo Su, and Bo Zheng. Shopsimulator: Evaluating and exploring rl-driven llm agent for shopping assistants.ArXiv, abs/2601.18225, 2026. URL https://api.semanticscholar. org/CorpusID:285050373
-
[20]
Ziyi Wang, Yuxuan Lu, Wenbo Li, Amir A. Amini, Bo Sun, Yakov Bart, Weimin Lyu, Jiri Gesi, Tian Wang, Jing Huang, Yu Su, Upol Ehsan, Malihe Alikhani, Toby Jia-Jun Li, Lydia B. Chilton, and Dakuo Wang. Opera: A dataset of observation, persona, rationale, and action for evaluating llms on human online shopping behavior simulation.ArXiv, abs/2506.05606, 2025....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Ziyi Wang, Yuxuan Lu, Yimeng Zhang, Jing Huang, and Dakuo Wang. Customer-r1: Personal- ized simulation of human behaviors via rl-based llm agent in online shopping.arXiv preprint arXiv:2510.07230, 2025
-
[22]
Tianci Xue, Weijian Qi, Tianneng Shi, Chan Hee Song, Boyu Gou, Dawn Song, Huan Sun, and Yu Su. An illusion of progress? assessing the current state of web agents.CoRR, abs/2504.01382,
-
[24]
Webshop: Towards scal- able real-world web interaction with grounded language agents
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scal- able real-world web interaction with grounded language agents. In Sanmi Koyejo, S. Mo- hamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neu- ral Information Processing Systems 35: Annual Conference on Neural Information Pro- cessing Systems 2022,...
work page 2022
-
[25]
Zijian Yu, Kejun Xiao, Huaipeng Zhao, Tao Luo, and Xiaoyi Zeng. Shopping companion: A memory-augmented LLM agent for real-world e-commerce tasks.CoRR, abs/2603.14864,
-
[27]
WebForge: Breaking the Realism-Reproducibility-Scalability Trilemma in Browser Agent Benchmark
Peng Yuan, Yuyang Yin, Yuxuan Cai, and Zheng Wei. Webforge: Breaking the realism-reproducibility-scalability trilemma in browser agent benchmark.arXiv preprint arXiv:2604.10988, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Na, Sungwon Kim, Junseok Lee, and Chanyoung Park
Shuo Zhang, Boci Peng, Xinping Zhao, Boren Hu, Yun Zhu, Yanjia Zeng, and Xuming Hu. Llasa: Large language and e-commerce shopping assistant.CoRR, abs/2408.02006, 2024. doi: 10.48550/ARXIV .2408.02006. URLhttps://doi.org/10.48550/arXiv.2408.02006
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[29]
Yimeng Zhang, Jiri Gesi, Ran Xue, Tian Wang, Ziyi Wang, Yuxuan Lu, Sinong Zhan, Huimin Zeng, Qingjun Cui, Yufan Guo, et al. See, think, act: Online shopper behavior simulation with vlm agents.arXiv preprint arXiv:2510.19245, 2025
-
[30]
Shuyan Zhou. Webarena-infinity: Generating browser environments with verifiable tasks at scale.shuyanzhou.com, March 2026. URL https://webarena.dev/webarena-infinity/
work page 2026
-
[31]
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2...
work page 2024
-
[32]
introduces a Chinese web environment for multi-turn shopping dialog and fine-grained product differentiation. WebMall [12] expands to four simulated shops with authentic product offers and comparison-shopping tasks. Although these benchmarks enable controlled evaluation, they remain tied to a fixed set of layouts, taxonomies, and policies, and therefore c...
-
[33]
click on the filter menu titledPrice
proposes a multi-agent pipeline for generating tasks and trajectories by navigating websites and maintaining a graph of visited URLs for efficient exploration. 13 B Implementation Details B.1 Models used for agent implementations • Planning Agent: Claude Code with Claude Opus 4.6 • Specification Agent: Claude Code with Claude Opus 4.6 • Collections genera...
-
[34]
Search & atomic add-to-cart
-
[35]
Nav drilldown (menu -> sub-menu -> collection -> product)
-
[36]
Format=Hardcover then sort by price)
Filter + sort (e.g. Format=Hardcover then sort by price)
-
[37]
Filter that returns zero results, then recover
-
[38]
Substitute-match discovery (intended product missing -> close alternative)
-
[39]
Review / detail read on a product page
-
[40]
Size chart / fit guide lookup
-
[41]
Shipping policy lookup (with cart action after)
-
[42]
Returns / refunds lookup (with cart action after)
-
[43]
Gift card purchase (only if the shop sells gift cards)
-
[44]
Multi-product cart with edit (add A, add B, remove A, set qty 2 on B)
-
[45]
Cross-collection or cross-brand comparison (compare A and B, pick one)
-
[46]
Contact / store locator / about page
-
[47]
Search for X. Pick a Color and Size variant. Add to cart
Free-shipping threshold or sale-discount calculation (if banner exists) ### High-quality reference tasks (from other shops in this benchmark suite) [See Appendix sections below for three representative few-shot examples. Five additional examples are included in the released benchmark code.] ### Anti-patterns to AVOID - "Search for X. Pick a Color and Size...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.