Recognition: unknown
WebForge: Breaking the Realism-Reproducibility-Scalability Trilemma in Browser Agent Benchmark
Pith reviewed 2026-05-10 15:56 UTC · model grok-4.3
The pith
A four-agent LLM pipeline automatically generates self-contained interactive web environments to resolve the realism-reproducibility-scalability trilemma in browser agent benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
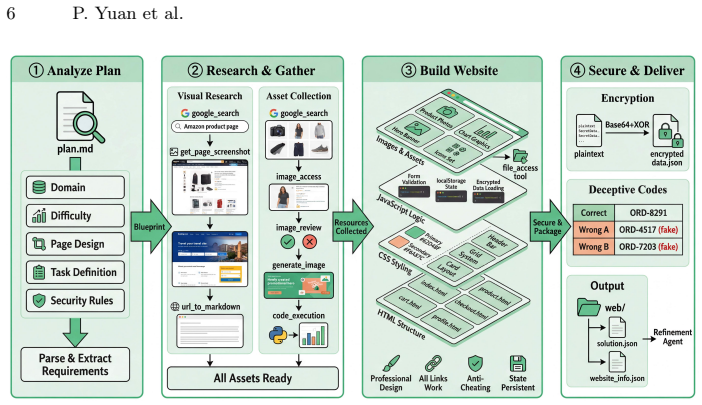
WebForge is the first fully automated framework that resolves this trilemma through a four-agent pipeline -- Plan, Generate, Refine, and Validate -- that produces interactive, self-contained web environments end-to-end without human annotation. A seven-dimensional difficulty control framework structures task design along navigation depth, visual complexity, reasoning difficulty, and more, enabling systematic capability profiling beyond single aggregate scores. Using WebForge, we construct WebForge-Bench, a benchmark of 934 tasks spanning 7 domains and 3 difficulty levels. Multi-model experiments show that difficulty stratification effectively differentiates model capabilities, while cross-d
What carries the argument
The four-agent pipeline (Plan, Generate, Refine, Validate) that creates the web environments end-to-end, paired with the seven-dimensional difficulty framework that organizes tasks for capability profiling.
If this is right
- Difficulty stratification effectively differentiates model capabilities.
- Cross-domain analysis exposes capability biases invisible to aggregate metrics.
- Multi-dimensional evaluation reveals distinct capability profiles that a single aggregate score cannot capture.
- The automated pipeline enables construction of benchmarks at scale across multiple domains and difficulty levels.
Where Pith is reading between the lines
- The pipeline could be adapted to generate benchmarks for other interactive systems such as mobile applications or desktop software.
- Periodic re-running of the generation process could keep benchmarks current against ongoing changes in real web content.
- Model developers might use the seven-dimensional breakdown to target training on specific weak areas like visual complexity or reasoning depth.
- This method opens the possibility of standardized, community-updatable benchmarks that avoid the maintenance costs of static real-site collections.
Load-bearing premise
The four-agent LLM pipeline can reliably generate interactive, realistic web environments that accurately capture real-web noise and complexity without human intervention or post-hoc curation.
What would settle it
Independent human raters judging a substantial fraction of the generated tasks as unrealistic, non-interactive, or missing key real-web elements compared to live sites would undermine the realism claim.
Figures













read the original abstract
Existing browser agent benchmarks face a fundamental trilemma: real-website benchmarks lack reproducibility due to content drift, controlled environments sacrifice realism by omitting real-web noise, and both require costly manual curation that limits scalability. We present WebForge, the first fully automated framework that resolves this trilemma through a four-agent pipeline -- Plan, Generate, Refine, and Validate -- that produces interactive, self-contained web environments end-to-end without human annotation. A seven-dimensional difficulty control framework structures task design along navigation depth, visual complexity, reasoning difficulty, and more, enabling systematic capability profiling beyond single aggregate scores. Using WebForge, we construct WebForge-Bench, a benchmark of 934 tasks spanning 7 domains and 3 difficulty levels. Multi-model experiments show that difficulty stratification effectively differentiates model capabilities, while cross-domain analysis exposes capability biases invisible to aggregate metrics. Together, these results confirm that multi-dimensional evaluation reveals distinct capability profiles that a single aggregate score cannot capture. Code and benchmark are publicly available at https://github.com/yuandaxia2001/WebForge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WebForge, an automated four-agent LLM pipeline (Plan, Generate, Refine, Validate) that generates interactive, self-contained web environments to resolve the realism-reproducibility-scalability trilemma in browser agent benchmarks. It further proposes a seven-dimensional difficulty control framework (navigation depth, visual complexity, reasoning difficulty, etc.) and releases WebForge-Bench comprising 934 tasks across 7 domains and 3 difficulty levels. Experiments with multiple models demonstrate that the difficulty stratification differentiates capabilities and that cross-domain analysis reveals biases not visible in aggregate scores.
Significance. If the generated environments can be shown to faithfully reproduce real-web noise, drift, and complexity at scale, the framework would enable reproducible yet realistic benchmarking and systematic capability profiling that single-score evaluations cannot provide. The public release of code and benchmark data is a clear strength that supports reproducibility.
major comments (3)
- [Abstract, §3] Abstract and §3 (pipeline description): The central claim that the Plan-Generate-Refine-Validate pipeline resolves the realism half of the trilemma rests on the assertion that generated sites match real-web noise and complexity, yet no quantitative fidelity metrics (e.g., DOM variance, transient error rates, or layout drift statistics) or direct comparisons against live websites are reported. This is load-bearing for the trilemma-resolution claim.
- [§4] §4 (experiments and WebForge-Bench construction): The multi-model results show differentiation by difficulty level, but the paper provides no baseline comparisons against existing real-website or controlled benchmarks, nor any analysis of generation failure modes or human validation of realism. Without these, it is unclear whether the environments actually deliver the claimed realism or merely produce clean, LLM-biased sites.
- [§3.2] §3.2 (seven-dimensional difficulty framework): The framework is presented as enabling systematic profiling, but no validation is given that the seven dimensions are orthogonal or that they validly stratify capabilities (e.g., via correlation analysis or ablation of individual dimensions). This weakens the claim that multi-dimensional evaluation reveals distinct profiles invisible to aggregate scores.
minor comments (2)
- [Abstract] The abstract states '934 tasks spanning 7 domains and 3 difficulty levels' but does not specify how the three levels map onto the seven dimensions; a brief table or explicit mapping would improve clarity.
- [§3.2] Notation for the difficulty dimensions is introduced without a compact summary table; readers must cross-reference multiple paragraphs to understand the full set.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We have revised the manuscript to address the concerns about quantitative support for realism and validation of the difficulty framework. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (pipeline description): The central claim that the Plan-Generate-Refine-Validate pipeline resolves the realism half of the trilemma rests on the assertion that generated sites match real-web noise and complexity, yet no quantitative fidelity metrics (e.g., DOM variance, transient error rates, or layout drift statistics) or direct comparisons against live websites are reported. This is load-bearing for the trilemma-resolution claim.
Authors: We agree that the absence of explicit quantitative fidelity metrics limits the strength of the realism claim. In the revised manuscript we have added a new subsection in §3 that reports aggregate fidelity statistics computed over the generated environments, including DOM node count distributions, frequency of transient elements such as error states and dynamic content, and layout stability across repeated interactions. These are compared against publicly available real-web aggregate statistics. Direct per-site comparisons with live websites are not feasible without sacrificing reproducibility, but the added metrics show that the generated sites incorporate comparable levels of noise and complexity. We believe this addition substantiates the trilemma-resolution claim. revision: yes
-
Referee: [§4] §4 (experiments and WebForge-Bench construction): The multi-model results show differentiation by difficulty level, but the paper provides no baseline comparisons against existing real-website or controlled benchmarks, nor any analysis of generation failure modes or human validation of realism. Without these, it is unclear whether the environments actually deliver the claimed realism or merely produce clean, LLM-biased sites.
Authors: We acknowledge that additional context on baselines, failure modes, and human validation would improve clarity. The revised §4 now includes an analysis of generation failure modes, reporting the fraction of tasks rejected by the Validate agent and the primary rejection reasons. We have also added results from a human realism rating study conducted on a stratified sample of tasks. For baseline comparisons we have inserted a discussion of the inherent difficulties in direct quantitative matching with existing benchmarks; we report qualitative alignment and performance trend correlations with models previously evaluated on WebArena. These changes help demonstrate that the environments are not merely clean LLM artifacts. revision: yes
-
Referee: [§3.2] §3.2 (seven-dimensional difficulty framework): The framework is presented as enabling systematic profiling, but no validation is given that the seven dimensions are orthogonal or that they validly stratify capabilities (e.g., via correlation analysis or ablation of individual dimensions). This weakens the claim that multi-dimensional evaluation reveals distinct profiles invisible to aggregate scores.
Authors: We agree that explicit validation of the dimensions would strengthen the multi-dimensional profiling argument. In the revised §3.2 we have added a pairwise correlation matrix across the seven dimensions on the full benchmark, showing low average correlations that support relative orthogonality. We have also included an ablation study that evaluates model performance when individual dimensions are removed, demonstrating that each dimension contributes unique variance to the observed capability profiles. These additions provide quantitative support for the claim that multi-dimensional scores reveal distinctions not captured by aggregate metrics. revision: yes
Circularity Check
No circularity: constructive framework with no derivation chain
full rationale
The paper introduces WebForge as a new automated four-agent pipeline (Plan, Generate, Refine, Validate) to generate self-contained web environments and a seven-dimensional difficulty framework for task design. No equations, predictions, or first-principles derivations are claimed that could reduce to inputs by construction. The central contribution is the pipeline itself, which is presented as an engineering solution rather than a fitted or self-referential result. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked. The benchmark construction and multi-model experiments are downstream applications of the framework, not circular validations of it. This matches the default expectation of a non-circular methodological paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based agents can plan, generate, refine, and validate interactive web environments that are sufficiently realistic and self-contained for benchmarking purposes without human oversight.
invented entities (2)
-
WebForge four-agent pipeline (Plan, Generate, Refine, Validate)
no independent evidence
-
Seven-dimensional difficulty control framework
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Securing Computer-Use Agents: A Unified Architecture-Lifecycle Framework for Deployment-Grounded Reliability
The paper develops a unified framework that organizes computer-use agent reliability around perception-decision-execution layers and creation-deployment-operation-maintenance stages to map security and alignment inter...
Reference graph
Works this paper leans on
-
[1]
com / news / claude-sonnet-4-5(2025), accessed: 2026-03-04 8
Anthropic: Introducing Claude Sonnet 4.5.https : / / anthropic . com / news / claude-sonnet-4-5(2025), accessed: 2026-03-04 8
2025
-
[2]
arXiv preprint arXiv:2510.02418 (2025) 3
Anupam, S., Brown, D., Li, S., Wong, E., Hassani, H., Bastani, O.: Browser- Arena: Evaluating LLM agents on real-world web navigation tasks. arXiv preprint arXiv:2510.02418 (2025) 3
-
[3]
In: NeurIPS (2024) 3, 14
Boisvert, L., Thakkar, M., Gasse, M., Caccia, M., Le Sellier De Chezelles, T., Cap- part, Q., Chapados, N., Lacoste, A., Drouin, A.: WorkArena++: Towards compo- sitional planning and reasoning-based common knowledge work tasks. In: NeurIPS (2024) 3, 14
2024
-
[4]
Butt, N., Chandrasekaran, V., Joshi, N., Nushi, B., Balachandran, V.: BenchA- gents:Automatedbenchmarkcreationwithagentinteraction.In:ICLR2025Work- shop on Navigating and Addressing Data Problems for Foundation Models (DATA- FM) (2025) 2, 3
2025
-
[5]
DeepSeek-AI: DeepSeek-V3.2: Reasoning-first models built for agents.https:// api-docs.deepseek.com/news/news251201(2025), accessed: 2026-03-04 8 WebForge 15
2025
-
[6]
In: NeurIPS Datasets and Benchmarks Track (2023) 1, 2, 3, 14
Deng, X., Gu, Y., Zheng, B., Chen, S., Stevens, S., Wang, B., Sun, H., Su, Y.: Mind2Web: Towards a generalist agent for the web. In: NeurIPS Datasets and Benchmarks Track (2023) 1, 2, 3, 14
2023
-
[7]
Drouin, A., Gasse, M., Caccia, M., Laradji, I.H., Del Verme, M., Marty, T., Boisvert, L., Thakkar, M., Cappart, Q., Vazquez, D., Chapados, N., Lacoste, A.: WorkArena:Howcapablearewebagentsatsolvingcommonknowledgeworktasks? In: ICML (2024) 3
2024
-
[8]
Google DeepMind: Gemini 3 Flash: Frontier intelligence built for speed.https: //blog.google/products- and- platforms/products/gemini/gemini- 3- flash (2025), accessed: 2026-03-04 8
2025
-
[9]
GoogleDeepMind:AneweraofintelligencewithGemini3.https://blog.google/ products-and-platforms/products/gemini/gemini-3(2025), accessed: 2026-03- 04 8
2025
-
[10]
Google DeepMind: We’re expanding our Gemini 2.5 family of models.https:// blog.google/products-and-platforms/products/gemini/gemini-2-5-model- family-expands(2025), accessed: 2026-03-04 8
2025
-
[11]
In: ACL (2024) 1, 2, 14
He, H., Yao, W., Ma, K., Yu, W., Dai, Y., Zhang, H., Lan, Z., Yu, D.: WebVoyager: Building an end-to-end web agent with large multimodal models. In: ACL (2024) 1, 2, 14
2024
-
[12]
In: CVPR (2024) 3
Hong, W., Wang, W., Lv, Q., Xu, J., Yu, W., Ji, J., Wang, Y., Wang, Z., Zhang, Y., Li, J., Xu, B., Dong, Y., Ding, M., Tang, J.: CogAgent: A visual language model for GUI agents. In: CVPR (2024) 3
2024
-
[13]
In: ACL (2024) 3, 14
Koh, J.Y., Lo, R., Jang, L., Duvvur, V., Lim, M., Huang, P.Y., Neubig, G., Zhou, S., Salakhutdinov, R., Fried, D.: VisualWebArena: Evaluating multimodal agents on realistic visual web tasks. In: ACL (2024) 3, 14
2024
-
[14]
In: ICLR (2026) 3
Levy, I., Wiesel, B., Marreed, S., Oved, A., Yaeli, A., Shlomov, S.: ST- WebAgentBench: A benchmark for evaluating safety and trustworthiness in web agents. In: ICLR (2026) 3
2026
-
[15]
In: ICLR (2025) 2, 3
Li, X.L., Kaiyom, F., Liu, E.Z., Mai, Y., Liang, P., Hashimoto, T.: AutoBencher: Towards declarative benchmark construction. In: ICLR (2025) 2, 3
2025
-
[16]
Liu,J.,Song,Y.,Lin,B.Y.,Lam,W.,Neubig,G.,Li,Y.,Yue,X.:VisualWebBench: HowfarhavemultimodalLLMsevolvedinwebpageunderstandingandgrounding? In: COLM (2024) 3
2024
-
[17]
In: ICLR (2024) 2
Mialon, G., Fourrier, C., Wolf, T., LeCun, Y., Scialom, T.: GAIA: A benchmark for general AI assistants. In: ICLR (2024) 2
2024
-
[18]
Miyai,A.,Zhao,Z.,Egashira,K.,Sato,A.,Sunada,T.,Onohara,S.,Yamanishi,H., Toyooka, M., Nishina, K., Maeda, R., Aizawa, K., Yamasaki, T.: WebChoreArena: Evaluating web browsing agents on realistic tedious web tasks. arXiv preprint arXiv:2506.01952 (2025) 3
-
[19]
Entworld: A holistic environment and benchmark for verifiable enterprise gui agents, 2026
Mo, Y., Bai, Y., Sun, D., Shi, Y., Miao, Y., Chen, L., Li, D.: EntWorld: A holistic environment and benchmark for verifiable enterprise GUI agents. arXiv preprint arXiv:2601.17722 (2026) 2, 3, 14
-
[20]
Moonshot AI: Kimi K2.5: Open-source native multimodal agentic model.https: //github.com/MoonshotAI/Kimi-K2.5(2026), accessed: 2026-03-04 8
2026
-
[21]
OpenAI: GPT-5 Mini: A faster, cost-efficient version of GPT-5.https : / / developers.openai.com/api/docs/models/gpt-5-mini(2025), accessed: 2026- 03-04 8
2025
-
[22]
Yuan et al
OpenAI: GPT-5 Nano: Fastest, most cost-efficient version of GPT-5.https:// developers.openai.com/api/docs/models/gpt-5-nano(2025), accessed: 2026- 03-04 8 16 P. Yuan et al
2025
-
[23]
OpenAI: GPT-5.2: The best model for coding and agentic tasks.https : / / developers.openai.com/api/docs/models/gpt-5.2(2025), accessed: 2026-03-04 8
2025
-
[24]
arXiv preprint arXiv:2406.12373 , year=
Pan, Y., Kong, D., Zhou, S., Cui, C., Leng, Y., Jiang, B., Liu, H., Shang, Y., Zhou, S., Wu, T., Wu, Z.: WebCanvas: Benchmarking web agents in online environments. arXiv preprint arXiv:2406.12373 (2024) 2
-
[25]
Qwen Team, Alibaba Cloud: Qwen3-Omni: Natively omni-modal foundation mod- els.https://github.com/QwenLM/Qwen3-Omni(2025), accessed: 2026-03-04 8
2025
-
[26]
Qwen Team, Alibaba Cloud: Qwen3-VL: The most powerful vision-language model in the qwen series.https://github.com/QwenLM/Qwen3-VL(2025), accessed: 2026- 03-04 8
2025
-
[27]
In: NeurIPS (2024) 3
Shen, Y., Song, K., Tan, X., Zhang, W., Ren, K., Yuan, S., Lu, W., Li, D., Zhuang, Y.: TaskBench: Benchmarking large language models for task automation. In: NeurIPS (2024) 3
2024
-
[28]
In: ECAI (2025) 3
Shlomov, S., Wiesel, B., Sela, A., Levy, I., Galanti, L., Abitbol, R.: From grounding to planning: Benchmarking bottlenecks in web agents. In: ECAI (2025) 3
2025
-
[29]
In: ACL (2025) 2, 3
Sun, Q., Cheng, K., Ding, Z., Jin, C., Wang, Y., Xu, F., Wu, Z., Jia, C., Chen, L., Liu, Z., Kao, B., Li, G., He, J., Qiao, Y., Wu, Z.: OS-Genesis: Automating GUI agent trajectory construction via reverse task synthesis. In: ACL (2025) 2, 3
2025
-
[30]
In: Findings of ACL (2025) 14
Tian,S.,Zhang,Z.,Chen,L.,Liu,Z.:MMInA:Benchmarkingmultihopmultimodal internet agents. In: Findings of ACL (2025) 14
2025
-
[31]
ColorBrowserAgent: Complex Long-Horizon Browser Agent with Adaptive Knowledge Evolution
Wang, J., Zhou, J., Zhang, W., Liu, W., Zhang, Z., Lou, X., Zhang, W., Deng, H., Wang, J.: ColorBrowserAgent: Complex long-horizon browser agent with adaptive knowledge evolution. arXiv preprint arXiv:2601.07262 (2026) 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Wei, J., Sun, Z., Papay, S., McKinney, S., Han, J., Fulford, I., Chung, H.W., Passos, A.T., Fedus, W., Glaese, A.: BrowseComp: A simple yet challenging benchmark for browsing agents. arXiv preprint arXiv:2504.12516 (2025) 2
work page internal anchor Pith review arXiv 2025
-
[33]
In: EMNLP (2025) 1
Wei, Z., Yao, W., Liu, Y., Zhang, W., Lu, Q., Qiu, L., Yu, C., Xu, P., Zhang, C., Yin, B., Yun, H., Li, L.: WebAgent-R1: Training web agents via end-to-end multi-turn reinforcement learning. In: EMNLP (2025) 1
2025
-
[34]
In: NeurIPS Datasets and Benchmarks Track (2025) 14
Xu, F.F., Song, Y., Li, B., Tang, Y., Jain, K., Bao, M., Wang, Z.Z., Zhou, X., Guo, Z., Cao, M., Yang, M., Lu, H.Y., Martin, A., Su, Z., Maben, L.M., Mehta, R., Chi, W., Jang, L.K., Xie, Y., Zhou, S., Neubig, G.: TheAgentCompany: Bench- marking LLM agents on consequential real world tasks. In: NeurIPS Datasets and Benchmarks Track (2025) 14
2025
-
[35]
In: COLM (2025) 1, 13, 14
Xue, T., Qi, W., Shi, T., Song, C.H., Gou, B., Song, D., Sun, H., Su, Y.: An illusion of progress? assessing the current state of web agents. In: COLM (2025) 1, 13, 14
2025
-
[36]
In: ICLR (2025) 3
Yang, K., Liu, Y., Chaudhary, S., Fakoor, R., Chaudhari, P., Karypis, G., Rang- wala, H.: AgentOccam: A simple yet strong baseline for LLM-based web agents. In: ICLR (2025) 3
2025
-
[37]
In: ICLR (2023) 8
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., Cao, Y.: ReAct: Synergizing reasoning and acting in language models. In: ICLR (2023) 8
2023
-
[38]
In: ICML (2024) 1, 3
Zheng, B., Gou, B., Kil, J., Sun, H., Su, Y.: GPT-4V(ision) is a generalist web agent, if grounded. In: ICML (2024) 1, 3
2024
-
[39]
Zhipu AI: GLM-4.7: Comprehensive coding capability enhancement.https:// docs.z.ai/guides/llm/glm-4.7(2025), accessed: 2026-03-04 8
2025
-
[40]
In: ICLR (2024) 1, 2, 3, 14
Zhou, S., Xu, F.F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y., Fried, D., Alon, U., Neubig, G.: WebArena: A realistic web environment for building autonomous agents. In: ICLR (2024) 1, 2, 3, 14
2024
-
[41]
In: ICLR (2024) 2, 3 WebForge 17
Zhu, K., Chen, J., Wang, J., Gong, N.Z., Yang, D., Xie, X.: DyVal: Dynamic evaluation of large language models for reasoning tasks. In: ICLR (2024) 2, 3 WebForge 17
2024
-
[42]
In: ICML (2024) 3 18 P
Zhu, K., Wang, J., Zhao, Q., Xu, R., Xie, X.: Dynamic evaluation of large language models by meta probing agents. In: ICML (2024) 3 18 P. Yuan et al. Supplementary Material WebForge: Breaking the Realism-Reproducibility-Scalability Trilemma in Browser Agent Benchmark A Statistical Validation of Difficulty Dimensions Weconductstatisticalanalysesonthe934-ta...
2024
-
[43]
Please analyze their availability charts
Overview – User Query: “I need to book the ‘Grand Estate Gardens’ for a wedding in May 2026. Please analyze their availability charts. I need a date where the venue rental price is in the ‘Standard’ or ‘Economy’ tier (indicated by Yellow or Green on their Pricing Heatmap) AND the ‘White Roses’ are in ‘Peak Bloom’ (visible on their Seasonal Flora Chart). O...
2026
-
[44]
Difficulty Configuration Dimension Level Justification Jump Depth L3 7–8 clicks through search, venue, pricing, flora, booking Jump Breadth L1 Focused navigation; lists are short (3–5 items) Page Interaction L2 Booking form: date, guest count, catering selection Visual Complexity L3 Correlating a color-coded heatmap and a line graph Info Complexity L2 Cha...
-
[45]
Top Categories
Web Environment Design— 7 pages: 1.Venue Finder Home— Search bar and “Top Categories.” 2.Search Results— List of venues including “Grand Estate Gardens.” 3.Venue Dashboard— Tabs: Overview, Pricing & Availability, Gardens & Flora, Book Now. 4.Pricing&Availability—Heatmapimage+legend.May1–14Red($5,000), May 15–20 Yellow ($3,500), May 21–31 Green ($2,000). 5...
-
[46]
Solution Path WebForge 25
-
[47]
Grand Estate Gardens
Navigate to Home, search “Grand Estate Gardens.”
-
[48]
Click result→Venue Dashboard
-
[49]
Pricing tab.Visual Step A: May 15–31 valid (Yellow/Green)
-
[50]
5.Reasoning: Intersection=May 15–18
Flora tab.Visual Step B: White Rose peak = May 12–18. 5.Reasoning: Intersection=May 15–18. Select any valid date
-
[51]
Enter date, 80 guests, Premium ($85/pp)
Book Now. Enter date, 80 guests, Premium ($85/pp). Submit
-
[52]
Capture confirmation code and total
-
[53]
GT Total = $3,500 + 80×$85 =$10,300
Answer: Mixed (Confirmation Code + Total Cost). GT Total = $3,500 + 80×$85 =$10,300. Validate code (e.g., #WED-9982) and total. Key characteristics of the draft: The draft captures the core idea—cross- referencing a pricing heatmap and a bloom chart—but contains several simpli- fications: (1) only 3 pricing tiers with coarser ranges, (2) no service fee, (...
-
[54]
Overview – User Query: “I’m planning a wedding at the Grand Estate Gardens in May
-
[55]
On their website, there’s a color-coded pricing calendar for May—I only want dates in the Yellow (‘Stan- dard’) or Green (‘Economy’) tiers since we’re budget-conscious
I need your help figuring out the best date. On their website, there’s a color-coded pricing calendar for May—I only want dates in the Yellow (‘Stan- dard’) or Green (‘Economy’) tiers since we’re budget-conscious. But I also re- ally want the White Roses to be in full peak bloom for photos, and they have a bloom timeline chart on their Gardens page. Can y...
-
[56]
Yuan et al
Difficulty Configuration Dimension Level Justification Jump Depth L3 8 transitions: Home→Search→Overview→Pricing→Flora→ Book→Review→Confirm Jump Breadth L2 5 venues in search; 5 tabs in dashboard; 4 catering options Page Interaction L2 4 form interactions: date, guests, catering, contact name Visual Complexity L3 Cross-reference a 4-color heatmap AND a 4-...
-
[57]
Grand Estate Gardens
Web Environment Design— 8 pages: 1.Venue Finder Home(/) — Search bar, featured categories, promo banner (distractor), testimonials. 2.Search Results(/search) — 5 venue cards. “Grand Estate Gardens” is #1; 4 distractors. 3.Venue Overview(/venues/grand-estate-gardens) — 5 tabs.Callout: “10% service feeapplies to all bookings.” 4.Pricing & Availability(/pric...
2026
-
[58]
Solution Path(17 steps):
-
[59]
Navigate to Home, locate search bar
-
[60]
Grand Estate Gardens
Search “Grand Estate Gardens”→5 results
-
[61]
View Details
Click “View Details” on Grand Estate Gardens
-
[62]
Pricing & Availability
Click “Pricing & Availability” tab. 5.Visual Analysis A: Yellow (May 15–21) and Green (May 22–31) are valid
-
[63]
Gardens & Flora
Click “Gardens & Flora” tab. 7.Visual Analysis B: White Roses peak = May 13–19. 8.Cross-reference: May 15–19. Saturday→May 16(only Saturday)
-
[64]
Date: 2026-05-16→Venue $3,200
2026
-
[65]
Premium Plated
“Premium Plated” ($90/pp)→Catering $7,200
-
[66]
Verify: subtotal $10,400 + 10% fee $1,040 = $11,440
-
[67]
Review Booking
“Review Booking”→Review page
-
[68]
Confirm & Pay Deposit
“Confirm & Pay Deposit”→Confirmation
-
[69]
Read codeGEG-2026-05841and total$11,440.00
2026
-
[70]
Full credit: correct code + total + date in May 15–19
Answer Configuration: GT: Code = GEG-2026-05841, Total = $11,440.00, Date = 2026-05-16. Full credit: correct code + total + date in May 15–19. 75%: non-Saturday valid date. 50%: forgot service fee (→$10,400)
2026
-
[71]
Premium Catering
Quality Assurance: “Premium Catering”7→“Premium Plated” (intent match- ing);10%feeonlyinOverviewcallout;May2026startsFriday;3distractorflowers. Key improvements from draft to refined plan.Tab. 10 summarizes the principal differences. The refined plan transforms a basic 7-page sketch into a detailed 8-page blueprint with richer difficulty calibration, real...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.