STABLE: Simulation-Ready Tabletop Layout Generation via a Semantics-Physics Dual System
Pith reviewed 2026-05-20 19:10 UTC · model grok-4.3
The pith
STABLE generates simulation-ready tabletop scenes by alternating a fine-tuned LLM with a physics pose corrector.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
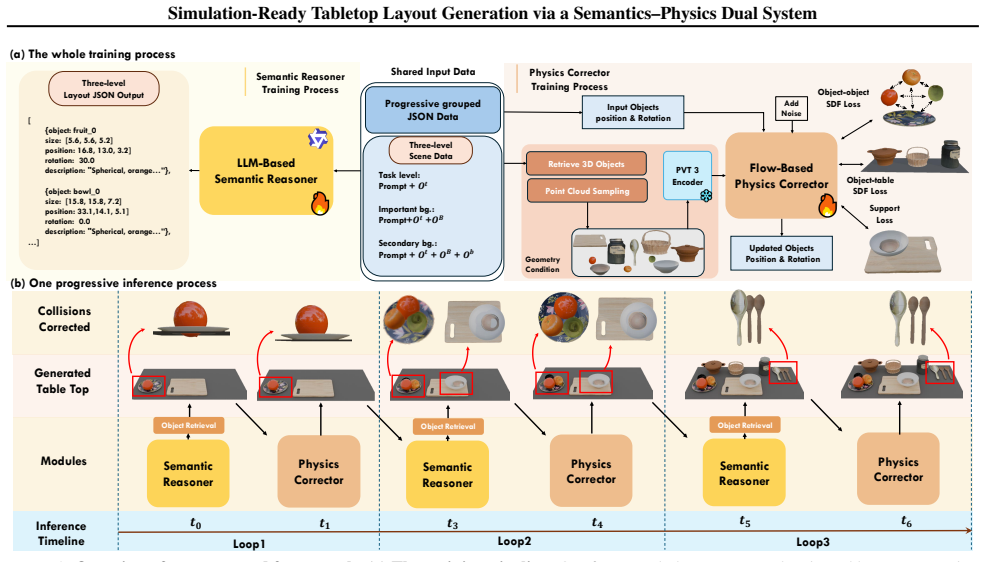
STABLE consists of a Semantic Reasoner, a fine-tuned LLM that produces coarse layouts from task instructions, and a Physics Corrector, a physics-aware flow-based denoising model that outputs pose updates. By alternating between the two in a progressive generation process that grows the scene from task-critical objects outward, the system yields layouts that conform to the given instructions while meeting physical plausibility criteria, outperforming prior LLM-only methods on validity metrics.
What carries the argument
The semantics-physics dual system that alternates a fine-tuned LLM Semantic Reasoner with a flow-based Physics Corrector under a progressive object-addition schedule.
If this is right
- Generated scenes can be loaded directly into simulators without post-processing for collisions or floating objects.
- Scene layouts remain faithful to the input task instructions even after physics corrections are applied.
- Progressive addition of objects from critical to background maintains both semantic and physical consistency.
- Physical validity metrics improve over methods that rely exclusively on large language models for layout prediction.
Where Pith is reading between the lines
- The same alternating correction pattern could be tested on other scene types such as kitchen counters or warehouse shelves.
- Replacing the flow-based corrector with a learned dynamics model might allow handling of more complex interactions like stacking.
- The approach could reduce the amount of human annotation needed to create large-scale simulation datasets for robot training.
- Integrating the system with real-time simulation feedback might enable iterative refinement when initial corrections fall short.
Load-bearing premise
The Physics Corrector can produce pose updates that remove physical violations while still keeping the layout aligned with the original task instructions.
What would settle it
Generate scenes from the same task instructions with STABLE and with a pure-LLM baseline, then run identical physics simulations and measure collision, penetration, and stability failure rates; if the rates are statistically indistinguishable, the dual-system advantage would be falsified.
Figures








read the original abstract
Generating simulation-ready tabletop scenes from task instructions is an intriguing and promising research direction in the field of Embodied AI. However, existing task-to-scene generation methods rely exclusively on large language models (LLMs) to predict scene layouts, inevitably yielding object collisions or floating due to LLMs' inherent limitations in 3D spatial reasoning. In this paper, we present STABLE, a semantics-physics dual-system tailored for simulation-ready tabletop scene generation. STABLE consists of two complementary modules: (i) a Semantic Reasoner, a fine-tuned LLM trained on a structured tabletop scene dataset to generate coarse layouts from input task instructions, and (ii) a Physics Corrector, a physics-aware flow-based denoising model that outputs pose updates to refine layouts, which ensures the physical plausibility of scenes while preserves semantic alignment with task instructions. STABLE adopts a progressive generation paradigm: by alternating between the Semantic Reasoner and Physics Corrector, it incrementally expands the scene from task-critical objects to background objects. Experiments demonstrate that STABLE successfully generates simulation-ready tabletop scenes that strictly conform to task instructions and significantly enhances the physical validity of scenes over prior art.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STABLE, a semantics-physics dual system for generating simulation-ready tabletop scenes from task instructions. It combines a Semantic Reasoner (fine-tuned LLM on a structured tabletop scene dataset) that produces coarse layouts with a Physics Corrector (physics-aware flow-based denoising model) that outputs pose updates for physical plausibility. The system uses a progressive generation paradigm that alternates between the modules, starting with task-critical objects and incrementally adding background objects, with the central claim that this yields scenes strictly conforming to instructions and with significantly improved physical validity over prior LLM-only methods.
Significance. If the quantitative results hold, the work offers a practical pipeline for Embodied AI that mitigates LLM limitations in 3D spatial reasoning while incorporating physics constraints. The dual-system design and progressive paradigm could support more reliable simulation environments for robotics and task planning, provided the semantic-physics interplay is rigorously validated.
major comments (2)
- [§3.3] §3.3 (Progressive Generation Paradigm): The description of alternating Semantic Reasoner and Physics Corrector steps does not specify any conditioning, regularization, or constraint mechanism that ensures the flow-based pose updates preserve task-specific semantic relations (e.g., relative positions or containment implied by the instruction). Without such a mechanism, the Physics Corrector risks displacing objects in ways that violate earlier semantic decisions, which is load-bearing for the claim of strict task conformance.
- [§4] §4 (Experiments): The abstract asserts that STABLE 'significantly enhances the physical validity of scenes over prior art' and 'strictly conform[s] to task instructions,' yet the provided experimental summary lacks quantitative metrics, specific baselines, error bars, or ablation studies on the dual-system components. This absence prevents assessment of whether the improvements are statistically meaningful or attributable to the proposed architecture.
minor comments (2)
- [§2.2] The notation for the flow-based denoiser in §2.2 could be clarified by explicitly defining the conditioning inputs (task embedding, current layout) and the loss terms used during training.
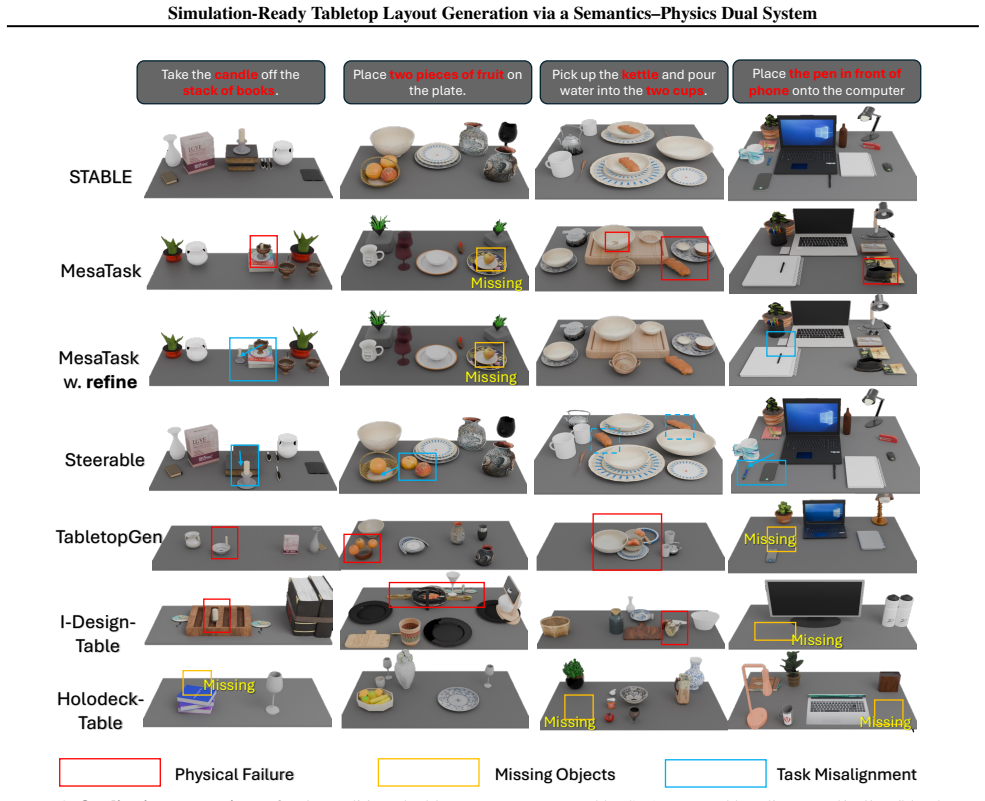
- [Figure 3] Figure 3 caption should include the exact number of scenes and task instructions used in the qualitative examples to allow readers to gauge representativeness.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and indicate the revisions we will make to strengthen the presentation.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Progressive Generation Paradigm): The description of alternating Semantic Reasoner and Physics Corrector steps does not specify any conditioning, regularization, or constraint mechanism that ensures the flow-based pose updates preserve task-specific semantic relations (e.g., relative positions or containment implied by the instruction). Without such a mechanism, the Physics Corrector risks displacing objects in ways that violate earlier semantic decisions, which is load-bearing for the claim of strict task conformance.
Authors: We thank the referee for this observation. The Physics Corrector is a flow-based model whose inputs include the task instruction embedding and the current coarse layout (object categories and poses) produced by the Semantic Reasoner; its training objective includes a term that penalizes large deviations from the initial semantic poses. This conditioning and regularization are intended to keep task-specific relations intact while correcting only physical violations. We agree that §3.3 would benefit from an explicit description of these mechanisms and will revise the section accordingly in the next version. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract asserts that STABLE 'significantly enhances the physical validity of scenes over prior art' and 'strictly conform[s] to task instructions,' yet the provided experimental summary lacks quantitative metrics, specific baselines, error bars, or ablation studies on the dual-system components. This absence prevents assessment of whether the improvements are statistically meaningful or attributable to the proposed architecture.
Authors: We acknowledge that the current experimental section would benefit from a clearer and more detailed presentation of the quantitative results. In the revised manuscript we will expand §4 to explicitly report the physical validity metric (percentage of collision-free and stable scenes under physics simulation), the task-conformance score, comparisons against LLM-only baselines, standard deviations across repeated trials, and ablation studies that isolate the contributions of the progressive paradigm and the Physics Corrector. These additions will make the statistical significance and architectural attribution more transparent. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents STABLE as a pipeline that integrates a fine-tuned LLM (Semantic Reasoner) with a physics-aware flow-based denoising model (Physics Corrector) under a progressive generation paradigm. No equations, fitted parameters, or self-referential definitions appear in the abstract or description that would reduce any claimed prediction or output to an input quantity by construction. The physical plausibility and semantic alignment claims are positioned as outcomes of the dual-system design rather than tautological redefinitions or renamings of known results. Self-citations, if present in the full text, are not load-bearing for the central architecture, which draws on standard LLM fine-tuning and flow-based models without importing uniqueness theorems or ansatzes from prior author work in a circular manner. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- structured tabletop scene dataset
axioms (2)
- domain assumption Fine-tuned LLMs can produce coarse layouts that are semantically aligned with task instructions
- domain assumption A physics-aware flow-based model can refine object poses for physical plausibility without breaking semantic alignment
Forward citations
Cited by 1 Pith paper
-
Code-as-Room: Generating 3D Rooms from Top-Down View Images via Agentic Code Synthesis
Code-as-Room is an MLLM-based agentic pipeline that parses top-down images into multi-stage Blender code synthesis with cross-stage memory to generate functional 3D rooms.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
I-design: Personal- ized llm interior designer.arXiv preprint arXiv:2404.02838,
C ¸elen, A., Han, G., Schindler, K., Van Gool, L., Armeni, I., Obukhov, A., and Wang, X. I-design: Personalized llm interior designer. arXiv preprint arXiv:2404.02838,
-
[3]
Chen, T., Chen, Z., Chen, B., Cai, Z., Liu, Y ., Li, Z., Liang, Q., Lin, X., Ge, Y ., Gu, Z., et al. Robotwin 2.0: A scal- able data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation. arXiv preprint arXiv:2506.18088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Mesatask: Towards task- driven tabletop scene generation via 3d spatial reasoning
Hao, J., Liang, N., Luo, Z., Xu, X., Zhong, W., Yi, R., Jin, Y ., Lyu, Z., Zheng, F., Ma, L., et al. Mesatask: Towards task- driven tabletop scene generation via 3d spatial reasoning. arXiv preprint arXiv:2509.22281,
-
[5]
Midi: Multi-instance diffusion for single image to 3d scene generation
Huang, Z., Guo, Y ., An, X., Yang, Y ., Li, Y ., Zou, Z., Liang, D., Liu, X., Cao, Y ., and Sheng, L. Midi: Multi-instance diffusion for single image to 3d scene generation. arXiv preprint arXiv:2412.03558,
-
[6]
Instructscene: Instruction- driven 3d indoor scene synthesis with semantic graph prior
Lin, C. and Mu, Y . Instructscene: Instruction-driven 3d indoor scene synthesis with semantic graph prior. arXiv preprint arXiv:2402.04717,
-
[7]
PAT3D: Physics-Augmented Text-to-3D Scene Generation
Lin, G., Huang, K., Liu, M., Gao, R., Chen, H., Chen, L., Lu, B., Komura, T., Liu, Y ., Zhu, J.-Y ., et al. Pat3d: Physics-augmented text-to-3d scene generation. arXiv preprint arXiv:2511.21978,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Flow Matching for Generative Modeling
Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Structd- iffusion: Object-centric diffusion for semantic rearrange- ment of novel objects
Liu, W., Hermans, T., Chernova, S., and Paxton, C. Structd- iffusion: Object-centric diffusion for semantic rearrange- ment of novel objects. In Workshop on Language and Robotics at CoRL 2022,
work page 2022
-
[10]
Steerable scene generation with post training and inference-time search
Pfaff, N., Dai, H., Zakharov, S., Iwase, S., and Tedrake, R. Steerable scene generation with post training and inference-time search. arXiv preprint arXiv:2505.04831,
-
[11]
Layoutvlm: Differentiable optimization of 3d layout via vision-language models
Sun, F.-Y ., Liu, W., Gu, S., Lim, D., Bhat, G., Tombari, F., Li, M., Haber, N., and Wu, J. Layoutvlm: Differentiable optimization of 3d layout via vision-language models. arXiv preprint arXiv:2412.02193,
-
[12]
Tian, Y ., Yang, Y ., Xie, Y ., Cai, Z., Shi, X., Gao, N., Liu, H., Jiang, X., Qiu, Z., Yuan, F., et al. Interndata-a1: Pioneer- ing high-fidelity synthetic data for pre-training generalist policy. arXiv preprint arXiv:2511.16651,
-
[13]
Wang, Z., He, Y ., Yang, L., Zou, W., Ma, H., Liu, L., Sui, W., Guo, Y ., and Su, H. Tabletopgen: Instance-level in- teractive 3d tabletop scene generation from text or single image. arXiv preprint arXiv:2512.01204,
-
[14]
Sceneweaver: All-in-one 3d scene synthesis with an extensible and self- reflective agent
Yang, Y ., Jia, B., Zhang, S., and Huang, S. Sceneweaver: All-in-one 3d scene synthesis with an extensible and self- reflective agent. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. Yang, Y ., Lu, J., Zhao, Z., Luo, Z., Yu, J. J., Sanchez, V ., and Zheng, F. Llplace: The 3d indoor scene layout generation and editing via la...
-
[15]
Cast: Component-aligned 3d scene reconstruction from an rgb image
Yao, K., Zhang, L., Yan, X., Zeng, Y ., Zhang, Q., Xu, L., Yang, W., Gu, J., and Yu, J. Cast: Component-aligned 3d scene reconstruction from an rgb image. arXiv preprint arXiv:2502.12894,
-
[16]
The denoising network is a 1D U-Net with a hidden dimension of 512 and self-conditioning
with linear interpolation paths to learn the vector field that transports samples from a standard Gaussian prior to the data distribution. The denoising network is a 1D U-Net with a hidden dimension of 512 and self-conditioning. Each object is represented as a 4D vector (3D position + z-rotation), conditioned on 64-dimensional point cloud features and lea...
work page 2025
-
[17]
as a representative task-to-scene method. MesaTask generates a structured tabletop layout from the task instruction and retrieves 3D assets accordingly. We use the official preprocessing and evaluation protocol provided by MesaTask. Holodeck-Table.We adopt the tabletop adaptation of HOLODECK (Yang et al., 2024b) provided in MesaTask. Concretely, the pipel...
work page 2024
-
[18]
to the layouts generated by MesaTask, following the same solver configuration and stopping criteria as in the original implementation. Steerable.We also compare against a steerable post-processing baseline (Pfaff et al., 2025), where we first use our Semantic Reasoner to generate a coarse (potentially colliding) layout from the task instruction and then f...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.