Offline Semantic Guidance for Efficient Vision-Language-Action Policy Distillation
Pith reviewed 2026-05-20 18:37 UTC · model grok-4.3
The pith
Offline semantic guidance from a vision-language model distills large VLA policies into 158M students that match teacher performance with a 0.27% gap.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VLA-AD augments teacher-provided 7-DoF action targets with high-level semantic guidance from an offline VLM, including task phase anchors and multi-frame operating-direction descriptions. These auxiliary signals are used only during training, enabling the production of a 158M-parameter student policy from a 7B teacher that matches performance on three LIBERO suites with a 0.27% average relative gap while running at 12.5 Hz for a 3.28x inference speedup.
What carries the argument
The offline VLM semantic supervisor that supplies task phase anchors and multi-frame directional descriptions as auxiliary training signals to augment standard action imitation.
Load-bearing premise
The offline VLM provides accurate task-phase anchors and multi-frame directional descriptions that improve student learning beyond standard action imitation.
What would settle it
Training the same student architecture with only action imitation from the teacher and measuring if the performance gap to the teacher remains as small as 0.27% on the LIBERO suites.
Figures


read the original abstract
Billion-parameter Vision-Language-Action (VLA) policies have recently shown impressive performance in robotic manipulation, yet their size and inference cost remain major obstacles for real-time closed-loop control. We introduce \textbf{VLA-AD}, a distillation framework that uses a Vision-Language Model as an offline semantic supervisor to transfer large VLA teachers into lightweight student policies. Instead of relying only on low-level action imitation, VLA-AD augments teacher-provided 7-DoF action targets with high-level semantic guidance, including task phase anchors and multi-frame operating-direction descriptions. These auxiliary signals are used only during training: at test time, the student policy runs independently, with neither the VLA teacher nor the VLM required. We evaluate VLA-AD on three LIBERO benchmark suites. Using OpenVLA-7B as the teacher, our method produces a 158M-parameter student, yielding a $44\times$ reduction in model size while matching the teacher with only a $0.27\%$ average relative gap. The resulting policy runs at 12.5 Hz on an RTX 4090, achieving a $3.28\times$ inference speedup over OpenVLA-7B. We further show that the same semantic distillation pipeline generalizes to a different $\pi_{0.5}$-4B teacher, where the student outperforms the teacher on two suites and remains within $0.53\%$ on \texttt{libero\_goal}. Additional analysis indicates that phase-level supervision and multi-frame directional cues make the student less sensitive to noisy teacher actions, such as erroneous high-frequency gripper changes. Overall, VLA-AD demonstrates that offline semantic guidance from VLMs can substantially improve the efficiency, robustness, and deployability of VLA policy distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VLA-AD, an offline distillation framework that augments teacher VLA action targets with VLM-derived semantic signals (task-phase anchors and multi-frame directional descriptions) to train compact student policies. Using OpenVLA-7B as teacher, the method yields a 158M-parameter student that matches teacher performance on three LIBERO suites with a 0.27% average relative gap, 44× size reduction, and 3.28× inference speedup; similar results hold for a π0.5-4B teacher. The semantic signals are used only at training time and are claimed to improve robustness to noisy teacher actions such as gripper jitter.
Significance. If the performance gains can be causally attributed to the VLM semantic supervisor, the work would offer a practical route to real-time deployable VLA policies. The multi-suite, multi-teacher evaluation and the reported robustness to noisy actions are positive empirical strengths. However, the absence of a direct ablation isolating the semantic component limits the strength of the central claim.
major comments (2)
- [Evaluation on LIBERO suites and auxiliary analysis] The central claim that offline VLM semantic guidance (phase anchors and directional descriptions) enables the observed performance matching rests on the comparison to the 7B teacher, yet the manuscript provides no controlled ablation that trains the identical 158M student architecture on the same teacher action targets while withholding the VLM-generated tokens. Without this contrast, the 0.27% gap cannot be attributed to the proposed supervisor rather than optimization schedule, data filtering, or student capacity.
- [Additional analysis paragraph] The auxiliary claim that phase-level supervision and multi-frame cues reduce sensitivity to noisy teacher actions (e.g., erroneous high-frequency gripper changes) is stated in the abstract and analysis, but the manuscript does not report quantitative metrics, error bars, or a direct comparison against a pure action-imitation baseline on the same noisy data.
minor comments (2)
- [Results tables and figures] Reported results across LIBERO suites lack visible error bars, standard deviations, or statistical significance tests, making it difficult to assess whether the small relative gaps are reliable.
- [Method description] The VLM prompt templates used to generate phase anchors and directional descriptions are listed among free parameters but receive no further detail on sensitivity or exact wording.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to clarify and strengthen our manuscript on VLA-AD. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: The central claim that offline VLM semantic guidance (phase anchors and directional descriptions) enables the observed performance matching rests on the comparison to the 7B teacher, yet the manuscript provides no controlled ablation that trains the identical 158M student architecture on the same teacher action targets while withholding the VLM-generated tokens. Without this contrast, the 0.27% gap cannot be attributed to the proposed supervisor rather than optimization schedule, data filtering, or student capacity.
Authors: We agree that a direct ablation isolating the contribution of the VLM semantic signals is required to rigorously attribute the performance matching. In the revised manuscript we will add results for the identical 158M student trained on the same teacher action targets but without the phase anchors and multi-frame directional descriptions. This controlled comparison will quantify the incremental benefit of the semantic supervisor over pure action imitation under identical optimization and data conditions. revision: yes
-
Referee: The auxiliary claim that phase-level supervision and multi-frame cues reduce sensitivity to noisy teacher actions (e.g., erroneous high-frequency gripper changes) is stated in the abstract and analysis, but the manuscript does not report quantitative metrics, error bars, or a direct comparison against a pure action-imitation baseline on the same noisy data.
Authors: We acknowledge that the robustness analysis is currently qualitative. In the revision we will add quantitative metrics: success rates on the LIBERO suites when the teacher actions contain injected gripper jitter, reported with standard error bars across multiple random seeds, together with a direct head-to-head comparison against a pure action-imitation baseline trained on the identical noisy dataset. These results will be placed in the analysis section. revision: yes
Circularity Check
No circularity: empirical benchmark results rest on direct comparisons
full rationale
The paper presents VLA-AD as an empirical distillation method that augments teacher action targets with offline VLM-derived phase anchors and directional descriptions during training. All reported outcomes (158M student matching OpenVLA-7B within 0.27% on LIBERO, 44× size reduction, 12.5 Hz inference) are obtained from fixed-benchmark evaluations rather than any claimed derivation, equation, or fitted parameter that reduces to its own inputs by construction. No self-citation chain, uniqueness theorem, or ansatz is invoked to justify the central performance claims; the results are presented as experimental measurements on standard suites.
Axiom & Free-Parameter Ledger
free parameters (1)
- VLM prompt templates for phase anchors and directional descriptions
axioms (1)
- domain assumption A pretrained VLM can extract accurate high-level task-phase and directional information from visual observations without systematic bias.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VLA-AD augments teacher-provided 7-DoF action targets with high-level semantic guidance, including task phase anchors and multi-frame operating-direction descriptions.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
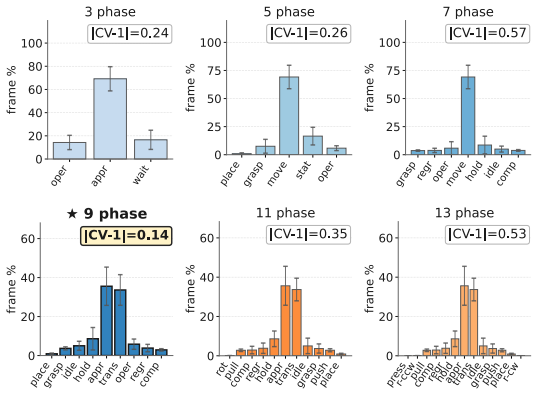
We adopted a 9-phase taxonomy: idle, approaching, grasping, transporting, holding, placing, operating, regrasping, and completed.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/2204.01691. Michael Ahn, Debidatta Dwibedi, Chelsea Finn, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Karol Hausman, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Sean Kirmani, Isabel Leal, Edward Lee, Sergey Levine, Yao Lu, Isabel Leal, Sharath Maddineni, Kanishka Rao, Dorsa Sadigh, Pannag Sanketi, Pierre Sermanet, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URLhttps://arxiv.org/abs/2401.12963. Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyan...
-
[3]
URL https://arxiv.org/abs/2502.13923. Homanga Bharadhwaj, Jay Vakil, Mohit Sharma, Abhinav Gupta, Shubham Tulsiani, and Vikash Ku- mar. Roboagent: Generalization and efficiency in robot manipulation via semantic augmentations and action chunking,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URLhttps://arxiv.org/abs/2309.01918. Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gon- zalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jas- mine Hsu, Brian Ichter, Alex Irpan, Nikh...
-
[5]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
URL https://arxiv.org/abs/2307.15818. Dian Chen, Brady Zhou, Vladlen Koltun, and Philipp Krähenbühl. Learning by cheating,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URL https://arxiv.org/abs/1912.12294. Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion,
-
[7]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
URL https://arxiv.org/abs/2303.04137. Shaoqi Dong, Chaoyou Fu, Haihan Gao, Yi-Fan Zhang, Chi Yan, Chu Wu, Xiaoyu Liu, Yunhang Shen, Jing Huo, Deqiang Jiang, Haoyu Cao, Yang Gao, Xing Sun, Ran He, and Caifeng Shan. Vita-vla: Efficiently teaching vision-language models to act via action expert distillation,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
URLhttps://arxiv.org/abs/2510.09607. 10 Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models,
-
[9]
LoRA: Low-Rank Adaptation of Large Language Models
URL https: //arxiv.org/abs/2106.09685. Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, and Li Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
URL https: //arxiv.org/abs/2307.05973. Nikita Kachaev, Mikhail Kolosov, Daniil Zelezetsky, Alexey K. Kovalev, and Aleksandr I. Panov. Don’t blind your vla: Aligning visual representations for ood generalization,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Siddharth Karamcheti, Suraj Nair, Annie S
URL https: //arxiv.org/abs/2510.25616. Siddharth Karamcheti, Suraj Nair, Annie S. Chen, Thomas Kollar, Chelsea Finn, Dorsa Sadigh, and Percy Liang. Language-driven representation learning for robotics,
-
[12]
URL https: //arxiv.org/abs/2302.12766. Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model,
-
[13]
Vision-Language Foundation Models as Effective Robot Imitators
URLhttps://arxiv.org/abs/2311.01378. Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for llm compression and acceleration,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
URLhttps://arxiv.org/abs/2306.00978. Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
URL https://arxiv.org/ abs/2306.03310. Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei- Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URL https://arxiv.org/abs/2506.13725. Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, Yaxin Peng, Feifei Feng, and Jian Tang. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation,
-
[17]
TinyVLA: Towards Fast, Data-Efficient Vision-Language-Action Models for Robotic Manipulation
URL https://arxiv.org/abs/ 2409.12514. Wencheng Ye, Tianshi Wang, Lei Zhu, Fengling Li, Guoli Yang, and Hengtao Shen. Actdistill: General action-guided self-derived distillation for efficient vision-language-action models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
URLhttps://arxiv.org/abs/2511.18082. Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. Long-clip: Unlocking the long-text capability of clip,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Long-clip: Unlocking the long-text capability of clip,
URLhttps://arxiv.org/abs/2403.15378. Danyang Zhang, Junhao Song, Ziqian Bi, Xinyuan Song, Yingfang Yuan, Tianyang Wang, Joe Yeong, and Junfeng Hao. Mixture of experts in large language models,
- [20]
-
[21]
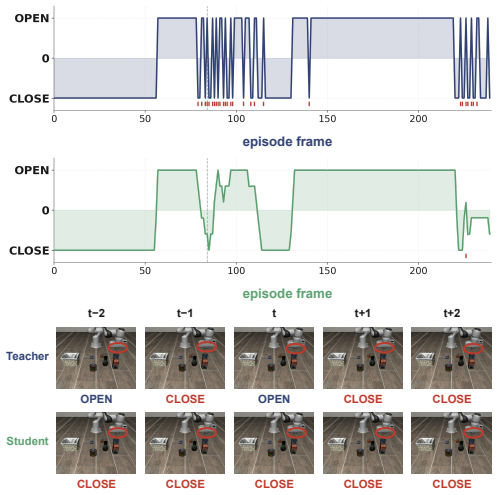
URLhttps://arxiv.org/abs/2304.13705. 11 Appendix Supplementary video: per-frame gripper-command comparison We provide gripper_comparison_video.mp4 (30 s, 8 fps, 240 frames) as a side-by-side per-frame visualization of the gripper command emitted by the OpenVLA-7B teacher (left panel, navy) and by our 158M Long-CLIP+LoRA student distilled from its rollouts...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.