Sketch Then Paint: Hierarchical Reinforcement Learning for Diffusion Multi-Modal Large Language Models
Pith reviewed 2026-05-19 21:14 UTC · model grok-4.3
The pith
Hierarchical reinforcement learning with staged sketch-then-paint updates improves how diffusion multimodal models assign credit during image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
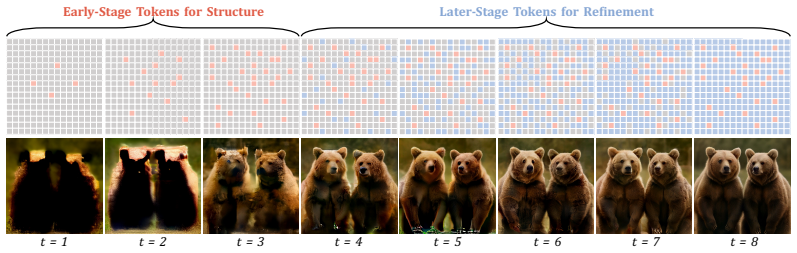
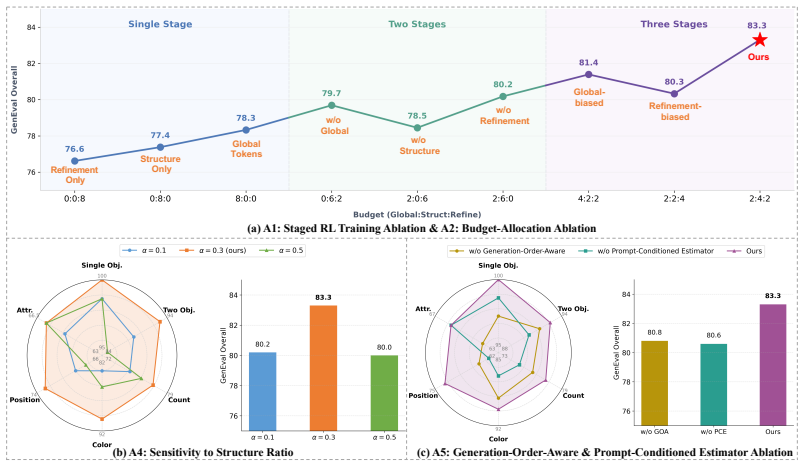
By folding the natural hierarchy of diffusion generation into the RL loop through a Sketch-Then-Paint scheme of global, structure, and refinement stages, plus a prompt-conditioned estimator for importance ratios from a fully masked start and a Hierarchical Credit Assignment mechanism that prioritizes layout tokens, the optimization process propagates rewards more accurately, producing measurable gains on the GenEval and DPG benchmarks as well as on six additional metrics of image quality, aesthetics, and human preference when tested on MMaDA and Lumina-DiMOO backbones.
What carries the argument
HT-GRPO, which organizes policy optimization into a three-stage Sketch-Then-Paint schedule and applies Hierarchical Credit Assignment to weight structural tokens, while computing importance ratios via a prompt-conditioned estimator that starts from a fully masked state.
If this is right
- Rewards no longer treat every token equally; early layout decisions receive higher effective weight during updates.
- Importance sampling becomes tractable even when many unmasking paths lead to the same image.
- Generated images improve on prompt-following benchmarks and on separate measures of aesthetics and human preference.
- The same training pipeline works across different diffusion MLLM backbones without architecture changes.
Where Pith is reading between the lines
- The staged credit scheme may reduce variance in long-horizon RL for any sequential generation task where early choices constrain later ones.
- Similar hierarchy-aware reward shaping could be tested in non-diffusion autoregressive models that also build outputs in coarse-to-fine order.
- If the prompt-conditioned estimator proves stable, it might replace more expensive Monte-Carlo rollouts for ratio estimation in other masked generative settings.
Load-bearing premise
The prompt-conditioned estimator correctly computes importance ratios from a fully masked state and the hierarchical credit assignment accurately prioritizes structural tokens without introducing new biases or instabilities in the policy optimization.
What would settle it
Retraining the same models with the three-stage schedule collapsed into a single stage or with the credit-assignment weights removed and observing no improvement or a drop in GenEval and DPG scores relative to the full HT-GRPO version would indicate that the hierarchy and credit mechanisms are not driving the reported gains.
Figures





read the original abstract
Diffusion Multi-Modal Large Language Models (dMLLMs) are powerful for image generation, but optimizing them through reinforcement learning (RL) remains a major challenge. One primary difficulty is that a single image can be generated through many different unmasking sequences, which makes calculating importance ratios often intractable. Additionally, existing methods tend to ignore the hierarchical generation process of dMLLMs, where early tokens define the global layout and later tokens focus on local details. By assigning uniform rewards to all tokens, these current methods fail to reflect the actual contribution of each token to the final image. To address these issues, we propose Hierarchical Token GRPO (HT-GRPO), which integrates this hierarchy directly into the policy optimization process. Our approach features a Sketch-Then-Paint training scheme that organizes updates into three distinct stages: global, structure, and refinement. We also use a prompt-conditioned estimator to calculate importance ratios starting from a fully masked state. Furthermore, we introduce a Hierarchical Credit Assignment mechanism that prioritizes key structural tokens to ensure accurate reward propagation. Experiments using two popular dMLLM backbones, MMaDA and Lumina-DiMOO, demonstrate that HT-GRPO achieves substantial gains on the GenEval and DPG benchmarks. Evaluations across six additional metrics confirm significant improvements in image quality, aesthetics, and human preference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RL optimization of diffusion Multi-Modal LLMs is hindered by intractable importance ratios arising from multiple unmasking sequences and by uniform reward assignment that ignores the hierarchical nature of generation (early tokens for global layout, later for details). It introduces Hierarchical Token GRPO (HT-GRPO) featuring a Sketch-Then-Paint scheme with three staged updates (global, structure, refinement), a prompt-conditioned estimator for importance ratios computed from the fully masked state, and a hierarchical credit assignment mechanism that prioritizes structural tokens. Experiments on MMaDA and Lumina-DiMOO backbones report substantial gains on GenEval and DPG plus improvements across six additional metrics for image quality, aesthetics, and human preference.
Significance. If the prompt-conditioned estimator is unbiased and the staged credit assignment accurately reflects token contributions without introducing instabilities, the approach would offer a practical way to incorporate generative hierarchy into policy-gradient methods for diffusion models. This could improve sample efficiency and output quality in dMLLMs and similar sequential generation settings; the explicit staging and credit mechanism constitute a concrete integration of domain structure into RL that is not present in standard GRPO.
major comments (2)
- [Methods (estimator definition)] The prompt-conditioned estimator for importance ratios (described in the methods as computing ratios starting from the fully masked image) is introduced without a derivation showing equality to the true ratio summed over all unmasking sequences or that omitted paths have measure zero under the current policy. This directly affects the unbiasedness of the policy-gradient estimator and is therefore load-bearing for the central claim of substantial benchmark gains on GenEval and DPG.
- [Methods (credit assignment)] The hierarchical credit assignment is stated to prioritize key structural tokens, yet no explicit formula, ablation, or analysis is supplied demonstrating that it avoids new biases or variance inflation relative to uniform reward assignment. Without this, the reported improvements cannot be confidently attributed to the hierarchy rather than to the staged update schedule alone.
minor comments (2)
- [Experiments] The abstract and experiments section should include error bars, number of runs, and baseline comparisons (e.g., standard GRPO, PPO) to allow assessment of statistical significance of the reported gains.
- [Methods] Notation for the prompt-conditioned estimator and the three training stages could be made more precise, with explicit pseudocode or equations showing how the stages differ from vanilla GRPO updates.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Methods (estimator definition)] The prompt-conditioned estimator for importance ratios (described in the methods as computing ratios starting from the fully masked image) is introduced without a derivation showing equality to the true ratio summed over all unmasking sequences or that omitted paths have measure zero under the current policy. This directly affects the unbiasedness of the policy-gradient estimator and is therefore load-bearing for the central claim of substantial benchmark gains on GenEval and DPG.
Authors: We appreciate the referee's emphasis on the need for a formal justification of the estimator. The manuscript currently describes the prompt-conditioned estimator as computing ratios from the fully masked state but does not supply the requested derivation. In the revised manuscript we will add a detailed proof in the Methods section (with supporting steps in the appendix) showing that the estimator equals the expectation of the true importance ratio over all unmasking sequences under the policy, and that sequences not originating from the fully masked state have zero measure. This addition will directly address the unbiasedness concern. revision: yes
-
Referee: [Methods (credit assignment)] The hierarchical credit assignment is stated to prioritize key structural tokens, yet no explicit formula, ablation, or analysis is supplied demonstrating that it avoids new biases or variance inflation relative to uniform reward assignment. Without this, the reported improvements cannot be confidently attributed to the hierarchy rather than to the staged update schedule alone.
Authors: We agree that the current presentation of the hierarchical credit assignment is insufficiently detailed. The manuscript states that the mechanism prioritizes structural tokens but omits the explicit weighting formula and supporting experiments. In the revision we will insert the precise formula for the stage-dependent credit weights, include an ablation that isolates the credit assignment from the staged update schedule, and provide a short analysis of bias and variance relative to uniform rewards. These additions will strengthen the attribution of gains to the hierarchical component. revision: yes
Circularity Check
No circularity: HT-GRPO introduces independent algorithmic components evaluated empirically
full rationale
The paper presents HT-GRPO as a novel integration of staged Sketch-Then-Paint updates and hierarchical credit assignment to handle intractable importance ratios and uniform reward issues in dMLLM RL. These elements are defined as new mechanisms rather than derived from or equivalent to prior fitted parameters, self-referential equations, or self-citations. The prompt-conditioned estimator is introduced as a practical approximation starting from the fully masked state, with no claim that it reduces to the true ratio by construction. Benchmark gains on GenEval and DPG are reported as experimental outcomes, not first-principles predictions forced by the method's own inputs. The derivation chain remains self-contained as an algorithmic proposal without load-bearing reductions to definitions or fits.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Early tokens in dMLLM generation define global layout while later tokens focus on local details
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We organize the K inner-loop updates into three consecutive stages: Global→Structure→Refinement... prompt-conditioned importance ratio rg,i(θ) = πθ(vg,i |C∅, c) / πθold(vg,i |C∅, c)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Hierarchical Credit Assignment... wg,i = λs for structure tokens, λr for refinement tokens
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Lumina-image 2.0: A unified and efficient image generative framework
Qi Qin, Le Zhuo, Yi Xin, Ruoyi Du, Zhen Li, Bin Fu, Yiting Lu, Jiakang Yuan, Xinyue Li, Dongyang Liu, et al. Lumina-image 2.0: A unified and efficient image generative framework. Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[3]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
LongCat-Image Technical Report
Meituan LongCat Team, Hanghang Ma, Haoxian Tan, Jiale Huang, Junqiang Wu, Jun-Yan He, Lishuai Gao, Songlin Xiao, Xiaoming Wei, Xiaoqi Ma, et al. Longcat-image technical report. arXiv preprint arXiv:2512.07584, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Emu3.5: Native Multimodal Models are World Learners
Yufeng Cui, Honghao Chen, Haoge Deng, Xu Huang, Xinghang Li, Jirong Liu, Yang Liu, Zhuoyan Luo, et al. Emu3.5: Native multimodal models are world learners.arXiv preprint arXiv:2510.26583, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Lumina-mgpt 2.0: Stand-alone autoregressive image modeling.arXiv preprint arXiv:2507.17801, 2025
Yi Xin, Juncheng Yan, Qi Qin, Zhen Li, Dongyang Liu, Shicheng Li, Victor Shea-Jay Huang, Yupeng Zhou, Renrui Zhang, Le Zhuo, et al. Lumina-mgpt 2.0: Stand-alone autoregressive image modeling.arXiv preprint arXiv:2507.17801, 2025
-
[8]
Dongyang Liu, Yi Xin, Shitian Zhao, Le Zhuo, Weifeng Lin, Xinyue Li, Qi Qin, Guangtao Zhai, Xiaohong Liu, Hongsheng Li, et al. Lumina-mgpt: Flexible photorealistic autoregressive text-to-image generation.International Journal of Computer Vision (IJCV), 2026
work page 2026
-
[9]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Zigang Geng, Yibing Wang, Yeyao Ma, Chen Li, Yongming Rao, Shuyang Gu, Zhao Zhong, Qinglin Lu, Han Hu, Xiaosong Zhang, et al. X-omni: Reinforcement learning makes discrete autoregressive image generative models great again.arXiv preprint arXiv:2507.22058, 2025
-
[12]
Shihao Yuan, Yahui Liu, Yang Yue, Jingyuan Zhang, Wangmeng Zuo, Qi Wang, Fuzheng Zhang, and Guorui Zhou. Ar-grpo: Training autoregressive image generation models via reinforcement learning.arXiv preprint arXiv:2508.06924, 2025
-
[13]
MMaDA: Multimodal large diffusion language models
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang. MMaDA: Multimodal large diffusion language models. InAdvances in Neural Information Processing Systems, volume 38, 2025
work page 2025
-
[14]
Lumina-dimoo: An omni diffusion large language model for multi-modal generation and understanding
Yi Xin, Qi Qin, Siqi Luo, Kaiwen Zhu, Juncheng Yan, Yan Tai, Jiayi Lei, Yuewen Cao, Keqi Wang, Yibin Wang, et al. Lumina-dimoo: An omni diffusion large language model for multi-modal generation and understanding.arXiv preprint arXiv:2510.06308, 2025
-
[15]
Muddit: Liberating generation beyond text-to-image with a unified discrete diffusion model
Qingyu Shi, Jinbin Bai, Zhuoran Zhao, Wenhao Chai, Kaidong Yu, Jianzong Wu, Shuangyong Song, Yunhai Tong, Xiangtai Li, Xuelong Li, and Shuicheng Yan. Muddit: Liberating generation beyond text-to-image with a unified discrete diffusion model. InInternational Conference on Learning Representations, 2026. 11
work page 2026
-
[16]
LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
Tiwei Bie, Haoxing Chen, Tieyuan Chen, Zhenglin Cheng, Long Cui, Kai Gan, Zhicheng Huang, Zhenzhong Lan, Haoquan Li, Jianguo Li, Tao Lin, Qi Qin, Hongjun Wang, Xiaomei Wang, Haoyuan Wu, Yi Xin, and Junbo Zhao. Llada2.0-uni: Unifying multimodal understanding and generation with diffusion large language model.arXiv preprint arXiv:2604.20796, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Shufan Li, Jiuxiang Gu, Kangning Liu, Zhe Lin, Zijun Wei, Aditya Grover, and Jason Kuen. Lavida-o: Elastic large masked diffusion models for unified multimodal understanding and generation.arXiv preprint arXiv:2509.19244, 2025
-
[18]
Llada-o: An effective and length-adaptive omni diffusion model.arXiv preprint arXiv:2603.01068,
Zebin You, Xiaolu Zhang, Jun Zhou, Chongxuan Li, and Ji-Rong Wen. Llada-o: An effective and length-adaptive omni diffusion model.arXiv preprint arXiv:2603.01068, 2026
-
[19]
Tianren Ma, Mu Zhang, Yibing Wang, and Qixiang Ye. Consolidating reinforcement learning for multimodal discrete diffusion models.arXiv preprint arXiv:2510.02880, 2025
-
[20]
Siyan Zhao, Devaansh Gupta, Qinqing Zheng, and Aditya Grover. d1: Scaling reasoning in diffusion large language models via reinforcement learning.arXiv preprint arXiv:2504.12216, 2025
-
[21]
Jie Liu, Zilyu Ye, Linxiao Yuan, Shenhan Zhu, Yu Gao, Jie Wu, Kunchang Li, Xionghui Wang, Xiaonan Nie, Weilin Huang, and Wanli Ouyang. UniGRPO: Unified policy optimization for reasoning-driven visual generation.arXiv preprint arXiv:2603.23500, 2026
-
[22]
Yinjie Wang, Ling Yang, Bowen Li, Ye Tian, Ke Shen, and Mengdi Wang. Revolutioniz- ing reinforcement learning framework for diffusion large language models.arXiv preprint arXiv:2509.06949, 2025
-
[23]
Jingyi Yang, Guanxu Chen, Xuhao Hu, and Jing Shao. Taming masked diffusion language models via consistency trajectory reinforcement learning with fewer decoding step.arXiv preprint arXiv:2509.23924, 2025
-
[24]
d-TreeRPO: Towards More Reliable Policy Optimization for Diffusion Language Models
Leyi Pan, Shuchang Tao, Yunpeng Zhai, Zheyu Fu, Liancheng Fang, Minghua He, Lingzhe Zhang, Zhaoyang Liu, Bolin Ding, Aiwei Liu, and Lijie Wen. d-treerpo: Towards more reliable policy optimization for diffusion language models.arXiv preprint arXiv:2512.09675, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Anthony Zhan. Simple policy gradients for reasoning with diffusion language models.arXiv preprint arXiv:2510.04019, 2025
-
[26]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Improving image generation with better captions
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Tian, et al. Improving image generation with better captions. Technical Report, OpenAI, 2023
work page 2023
-
[29]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [30]
-
[31]
Geneval: An object-focused frame- work for evaluating text-to-image alignment
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused frame- work for evaluating text-to-image alignment. InAdvances in Neural Information Processing Systems, volume 36, pages 76341–76366, 2023
work page 2023
-
[32]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. ELLA: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024. Introduces DPG-Bench. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Imagereward: learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: learning and evaluating human preferences for text-to-image generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[34]
Teaching large language models to regress accurate image quality scores using score distribution
Zhiyuan You, Xin Cai, Jinjin Gu, Tianfan Xue, and Chao Dong. Teaching large language models to regress accurate image quality scores using score distribution. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[35]
Hpsv3: Towards wide-spectrum human preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum human preference score.arXiv preprint arXiv:2508.03789, 2025
-
[36]
Shuo Cao, Jiayang Li, Xiaohui Li, Yuandong Pu, Kaiwen Zhu, Yuanting Gao, Siqi Luo, Yi Xin, Qi Qin, Yu Zhou, Xiangyu Chen, Wenlong Zhang, Bin Fu, Yu Qiao, and Yihao Liu. Unipercept: Towards unified perceptual-level image understanding across aesthetics, quality, structure, and texture.arXiv preprint arXiv:2512.21675, 2025
-
[37]
clip-score: CLIP Score for PyTorch
SUN Zhengwentai. clip-score: CLIP Score for PyTorch. https://github.com/taited/ clip-score, March 2023. Version 0.2.1
work page 2023
-
[38]
Unified Reward Model for Multimodal Understanding and Generation
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understanding and generation.arXiv preprint arXiv:2503.05236, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Struc- tured denoising diffusion models in discrete state-spaces. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[40]
Discrete diffusion modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. InProceedings of the International Conference on Machine Learning (ICML), 2024
work page 2024
-
[41]
Scaling diffusion language models via adaptation from autoregressive models
Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, et al. Scaling diffusion language models via adaptation from autoregressive models. InProceedings of the International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[42]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. LLaDA 1.5: Variance-reduced preference optimization for large language diffusion models.arXiv preprint arXiv:2505.19223, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning
Zebin You, Shen Nie, Xiaolu Zhang, Jun Hu, Jun Zhou, Zhiwu Lu, Ji-Rong Wen, and Chongxuan Li. LLaDA-V: Large language diffusion models with visual instruction tuning.arXiv preprint arXiv:2505.16933, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Muddit: Liberating generation beyond text-to-image with a unified discrete diffusion model, 2025
Qingyu Shi, Jinbin Bai, Zhuoran Zhao, Wenhao Chai, Kaidong Yu, Jianzong Wu, Shuangyong Song, Yunhai Tong, Xiangtai Li, Xuelong Li, and Shuicheng Yan. Muddit: Liberating generation beyond text-to-image with a unified discrete diffusion model, 2025
work page 2025
-
[46]
Ye Tian, Ling Yang, Jiongfan Yang, Anran Wang, Yu Tian, Jiani Zheng, Haochen Wang, Zhiyang Teng, Zhuochen Wang, Yinjie Wang, Yunhai Tong, Mengdi Wang, and Xiangtai Li. Mmada-parallel: Multimodal large diffusion language models for thinking-aware editing and generation.arXiv preprint arXiv:2511.09611, 2025
-
[47]
Yi Xin, Siqi Luo, Qi Qin, Haoxing Chen, Kaiwen Zhu, Zhiwei Zhang, Yangfan He, Rongchao Zhang, Jinbin Bai, Shuo Cao, et al. dmllm-tts: Self-verified and efficient test-time scaling for diffusion multi-modal large language models.arXiv preprint arXiv:2512.19433, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Kaiwen Zhu, Quansheng Zeng, Yuandong Pu, Shuo Cao, Xiaohui Li, Yi Xin, Qi Qin, Jiayang Li, Yu Qiao, Jinjin Gu, and Yihao Liu. Accelerating masked image generation by learning latent controlled dynamics.arXiv preprint arXiv:2602.23996, 2025
-
[49]
Shengjun Zhang, Zhang Zhang, Chensheng Dai, and Yueqi Duan. E-GRPO: High entropy steps drive effective reinforcement learning for flow models.arXiv preprint arXiv:2601.00423, 2026. 13 Supplementary Material A Related Work A.1 Diffusion Multi-Modal Large Language Models Discrete diffusion modeling is rapidly emerging as a highly promising paradigm, showing...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.