Beyond Safety Filtering: Control Barrier Function-Informed Reinforcement Learning for Connected and Automated Vehicles
Pith reviewed 2026-05-19 20:38 UTC · model grok-4.3
pith:DTOJ6LA4 Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{DTOJ6LA4}
Prints a linked pith:DTOJ6LA4 badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Converting Control Barrier Function constraints into rewards guides multi-agent reinforcement learning to higher performance with reduced hyperparameter sensitivity in connected vehicle intersections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a Control Barrier Function-informed reward design, which converts CBF constraint values under joint MARL actions into a reward signal, achieves the highest task performance and exhibits lower sensitivity to reward hyperparameters than heuristic baselines in a four-way multi-lane intersection scenario involving connected and automated vehicles.
What carries the argument
The CBF-informed reward signal that converts Control Barrier Function constraint values evaluated under joint multi-agent reinforcement learning actions into a scalar reward to explicitly guide safe learning.
If this is right
- Multi-agent RL agents reach the highest task performance levels in the intersection navigation setting.
- Performance stays consistently strong across the full tested range of reward hyperparameters.
- Safe learning proceeds with explicit guidance from barrier constraints rather than trial-and-error heuristics.
- The need for extensive manual reward tuning decreases while safety considerations remain embedded in the learning process.
Where Pith is reading between the lines
- The same reward conversion could be tested in other multi-agent control domains such as robot swarms or traffic signal coordination to check whether hyperparameter robustness transfers.
- Combining the CBF reward with an external safety filter might produce additive gains in real-world deployment without the instabilities the paper avoids.
- If the method scales to larger agent counts or noisy communication, it could lower the barrier to deploying connected vehicle systems in dense urban environments.
Load-bearing premise
Converting CBF constraint values under joint MARL actions into a reward signal will reliably guide safe learning without introducing new instabilities or performance trade-offs in the multi-agent intersection setting.
What would settle it
If the four-way intersection simulation shows that the CBF-informed method does not achieve higher task performance or displays greater sensitivity to reward hyperparameters than the two heuristic baselines, the central claim would be falsified.
Figures




read the original abstract
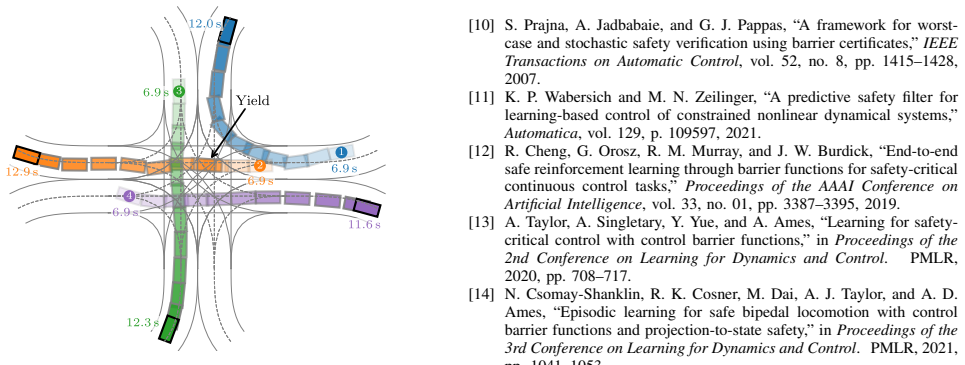
Reinforcement Learning (RL) uses rewards to guide learning, yet reward design is typically hand-crafted using heuristics that can be difficult to tune. We propose a Control Barrier Function (CBF)-informed reward design for Multi-Agent RL (MARL) that converts CBF constraint values under joint MARL actions into a reward signal that explicitly guides safe learning. We compare against two heuristic reward baselines in a four-way multi-lane intersection with connected and automated vehicles. Results show that our method achieves the highest task performance and is less sensitive to reward hyperparameters, yielding consistently strong performance across the tested hyperparameter range. Code for reproducing the experimental results and a video demonstration are available at https://github.com/bassamlab/SigmaRL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Control Barrier Function (CBF)-informed reward design for Multi-Agent Reinforcement Learning (MARL) in connected and automated vehicles. It converts CBF constraint values computed under joint MARL actions into a reward signal to guide safe learning. The method is evaluated against two heuristic reward baselines in a four-way multi-lane intersection scenario with CAVs. The central claims are that the proposed approach achieves the highest task performance and exhibits reduced sensitivity to reward hyperparameters, with consistently strong results across the tested hyperparameter range. Reproducible code and a video demonstration are provided via GitHub.
Significance. If the empirical claims hold after addressing decentralization concerns, the work could contribute a more systematic method for incorporating safety into MARL reward design for CAVs, reducing reliance on hand-crafted heuristics and improving robustness. The provision of reproducible code and a demonstration video is a clear strength that aids verification. The significance is moderate because the evaluation relies on comparisons to heuristic baselines rather than a parameter-free or theoretically grounded derivation, and the abstract lacks quantitative metrics.
major comments (2)
- [Abstract] Abstract: The claim of superior performance and robustness is stated without any quantitative metrics, error bars, or details on the exact mapping from CBF constraint values to the reward signal. This omission makes it impossible to evaluate the magnitude or statistical significance of the reported gains.
- [Method and Evaluation] Method and Evaluation sections: The reward signal is defined using CBF constraint values under joint MARL actions. In the decentralized four-way intersection setting, agents select actions without simultaneous knowledge of others' choices at decision time. This computation either requires perfect communication (implicit centralization) or an approximation that reintroduces non-stationarity, which directly affects whether the reported performance and hyperparameter robustness can be attributed to the CBF reward design itself.
minor comments (1)
- [Abstract] The GitHub link for code and video is a positive feature for reproducibility and should be retained.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of superior performance and robustness is stated without any quantitative metrics, error bars, or details on the exact mapping from CBF constraint values to the reward signal. This omission makes it impossible to evaluate the magnitude or statistical significance of the reported gains.
Authors: We agree that the abstract would be strengthened by including quantitative metrics. In the revised manuscript, we will update the abstract to report specific performance metrics (e.g., mean task completion rates and collision avoidance rates with standard deviations across multiple seeds) and briefly describe the CBF-to-reward mapping function. This will allow readers to directly assess the magnitude of the improvements. revision: yes
-
Referee: [Method and Evaluation] Method and Evaluation sections: The reward signal is defined using CBF constraint values under joint MARL actions. In the decentralized four-way intersection setting, agents select actions without simultaneous knowledge of others' choices at decision time. This computation either requires perfect communication (implicit centralization) or an approximation that reintroduces non-stationarity, which directly affects whether the reported performance and hyperparameter robustness can be attributed to the CBF reward design itself.
Authors: We appreciate this important observation on decentralization. Because the setting involves connected automated vehicles, the method assumes V2V communication allows agents to exchange intended actions before the joint CBF value is computed for the reward. This leverages the connectivity already present in the CAV problem and preserves decentralized action selection while enabling the joint computation. We will add a dedicated paragraph in the Method section clarifying this communication model, its relation to non-stationarity, and why the reported robustness can still be attributed to the CBF reward design. We are also prepared to discuss decentralized approximations if the referee recommends a specific approach. revision: partial
Circularity Check
No significant circularity; empirical results rest on simulation comparisons
full rationale
The paper proposes converting CBF constraint values under joint actions into an MARL reward and reports superior task performance plus reduced hyperparameter sensitivity via experiments against two heuristic baselines in a four-way intersection. No derivation chain reduces a claimed prediction or first-principles result to its own inputs by construction. No self-definitional steps, fitted inputs renamed as predictions, load-bearing self-citations, uniqueness theorems, or ansatz smuggling appear. The central claims are empirical and externally falsifiable against the stated baselines, qualifying as normal non-circular validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CBF constraint values under joint actions can be converted into a reward signal that guides safe MARL learning
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a Control Barrier Function (CBF)-informed reward design for Multi-Agent RL (MARL) that converts CBF constraint values under joint MARL actions into a reward signal
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ψ_h(x,u) := Δt ḣ + ⋯ + 1/r! Δt^r h^(r) + α(h) + R_T
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Deep reinforcement learning for autonomous driving: A survey,
B. R. Kiran, I. Sobh, V . Talpaert, P. Mannion, A. A. A. Sallab, S. Yo- gamani, and P. P ´erez, “Deep reinforcement learning for autonomous driving: A survey,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 6, pp. 4909–4926, 2022
work page 2022
-
[2]
Reward (mis) design for autonomous driving,
W. B. Knox, A. Allievi, H. Banzhaf, F. Schmitt, and P. Stone, “Reward (mis) design for autonomous driving,”Artificial Intelligence, vol. 316, p. 103829, 2023
work page 2023
-
[3]
Model-free deep reinforcement learning for urban autonomous driving,
J. Chen, B. Yuan, and M. Tomizuka, “Model-free deep reinforcement learning for urban autonomous driving,” in2019 IEEE Intelligent Transportation Systems Conference (ITSC), 2019, pp. 2765–2771
work page 2019
-
[4]
Interpretable end-to-end urban autonomous driving with latent deep reinforcement learning,
J. Chen, S. E. Li, and M. Tomizuka, “Interpretable end-to-end urban autonomous driving with latent deep reinforcement learning,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 6, pp. 5068–5078, 2022
work page 2022
-
[5]
Formulation of deep reinforcement learning architecture toward autonomous driving for on-ramp merge,
P. Wang and C.-Y . Chan, “Formulation of deep reinforcement learning architecture toward autonomous driving for on-ramp merge,” in2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), 2017, pp. 1–6
work page 2017
-
[6]
J. Wu, Z. Huang, and C. Lv, “Uncertainty-aware model-based re- inforcement learning: Methodology and application in autonomous driving,”IEEE Transactions on Intelligent Vehicles, vol. 8, no. 1, pp. 194–203, 2023
work page 2023
-
[7]
M. Zhu, Y . Wang, Z. Pu, J. Hu, X. Wang, and R. Ke, “Safe, efficient, and comfortable velocity control based on reinforcement learning for autonomous driving,”Transportation Research Part C: Emerging Technologies, vol. 117, p. 102662, 2020
work page 2020
-
[8]
Control barrier functions: Theory and applications,
A. D. Ames, S. Coogan, M. Egerstedt, G. Notomista, K. Sreenath, and P. Tabuada, “Control barrier functions: Theory and applications,” in2019 18th European Control Conference (ECC). Naples, Italy: IEEE, 2019, pp. 3420–3431
work page 2019
-
[9]
The simplex architecture for safe online control system upgrades,
D. Seto, B. Krogh, L. Sha, and A. Chutinan, “The simplex architecture for safe online control system upgrades,” inProceedings of the 1998 American Control Conference. ACC, vol. 6, 1998, pp. 3504–3508 vol.6
work page 1998
-
[10]
A framework for worst- case and stochastic safety verification using barrier certificates,
S. Prajna, A. Jadbabaie, and G. J. Pappas, “A framework for worst- case and stochastic safety verification using barrier certificates,”IEEE Transactions on Automatic Control, vol. 52, no. 8, pp. 1415–1428, 2007
work page 2007
-
[11]
A predictive safety filter for learning-based control of constrained nonlinear dynamical systems,
K. P. Wabersich and M. N. Zeilinger, “A predictive safety filter for learning-based control of constrained nonlinear dynamical systems,” Automatica, vol. 129, p. 109597, 2021
work page 2021
-
[12]
R. Cheng, G. Orosz, R. M. Murray, and J. W. Burdick, “End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, pp. 3387–3395, 2019
work page 2019
-
[13]
Learning for safety- critical control with control barrier functions,
A. Taylor, A. Singletary, Y . Yue, and A. Ames, “Learning for safety- critical control with control barrier functions,” inProceedings of the 2nd Conference on Learning for Dynamics and Control. PMLR, 2020, pp. 708–717
work page 2020
-
[14]
N. Csomay-Shanklin, R. K. Cosner, M. Dai, A. J. Taylor, and A. D. Ames, “Episodic learning for safe bipedal locomotion with control barrier functions and projection-to-state safety,” inProceedings of the 3rd Conference on Learning for Dynamics and Control. PMLR, 2021, pp. 1041–1053
work page 2021
-
[15]
Safe reinforcement learning: A control barrier function optimization approach,
Z. Marvi and B. Kiumarsi, “Safe reinforcement learning: A control barrier function optimization approach,”International Journal of Ro- bust and Nonlinear Control, vol. 31, no. 6, pp. 1923–1940, 2021
work page 1923
-
[16]
Safe and stable RL (S2RL) driving policies using control barrier and control lyapunov functions,
B. Gangopadhyay, P. Dasgupta, and S. Dey, “Safe and stable RL (S2RL) driving policies using control barrier and control lyapunov functions,”IEEE Transactions on Intelligent Vehicles, vol. 8, no. 2, pp. 1889–1899, 2023
work page 2023
-
[17]
C. Zhang, L. Dai, H. Zhang, and Z. Wang, “Control barrier function- guided deep reinforcement learning for decision-making of au- tonomous vehicle at on-ramp merging,”IEEE Transactions on Intel- ligent Transportation Systems, vol. 26, no. 6, pp. 8919–8932, 2025
work page 2025
-
[18]
J. Xu and B. Alrifaee, “A learning-based control barrier function for car-like robots: Toward less conservative collision avoidance,” in2025 European Control Conference (ECC), 2025, pp. 988–995
work page 2025
-
[19]
Barrier functions inspired reward shaping for reinforcement learning,
Nilaksh, A. Ranjan, S. Agrawal, A. Jain, P. Jagtap, and S. Kolathaya, “Barrier functions inspired reward shaping for reinforcement learning,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 10 807–10 813
work page 2024
-
[20]
Not only rewards but also constraints: Applications on legged robot locomotion,
Y . Kim, H. Oh, J. Lee, J. Choi, G. Ji, M. Jung, D. Youm, and J. Hwangbo, “Not only rewards but also constraints: Applications on legged robot locomotion,”IEEE Transactions on Robotics, vol. 40, pp. 2984–3003, 2024
work page 2024
-
[21]
A learning framework for diverse legged robot locomotion using barrier-based style rewards,
G. Kim, Y .-H. Lee, and H.-W. Park, “A learning framework for diverse legged robot locomotion using barrier-based style rewards,” in2025 IEEE International Conference on Robotics and Automation (ICRA), 2025, pp. 10 004–10 010
work page 2025
-
[22]
Lane change maneuvers for automated vehicles,
J. Nilsson, M. Br ¨annstr¨om, E. Coelingh, and J. Fredriksson, “Lane change maneuvers for automated vehicles,”IEEE Transactions on Intelligent Transportation Systems, vol. 18, no. 5, pp. 1087–1096, 2017
work page 2017
-
[23]
Rajamani,Vehicle Dynamics and Control, ser
R. Rajamani,Vehicle Dynamics and Control, ser. Mechanical Engi- neering Series. New York: Springer Science, 2006
work page 2006
-
[24]
TTCBF: A truncated taylor control bar- rier function for high-order safety constraints,
J. Xu and B. Alrifaee, “TTCBF: A truncated taylor control bar- rier function for high-order safety constraints,”arXiv preprint arXiv:2601.15196, 2026
-
[25]
High-order control barrier functions,
W. Xiao and C. Belta, “High-order control barrier functions,”IEEE Transactions on Automatic Control, vol. 67, no. 7, pp. 3655–3662, 2022
work page 2022
-
[26]
Q. Nguyen and K. Sreenath, “Exponential control barrier functions for enforcing high relative-degree safety-critical constraints,” in2016 American Control Conference (ACC). Boston, MA, USA: IEEE, 2016, pp. 322–328
work page 2016
-
[27]
J. Xu, C. Che, and B. Alrifaee, “A real-time control barrier function- based safety filter for motion planning with arbitrary road boundary constraints,” in2025 IEEE 28th International Conference on Intelli- gent Transportation Systems (ITSC), 2025, pp. 2818–2825
work page 2025
-
[28]
Multi-agent actor-critic for mixed cooperative-competitive environ- ments,
R. Lowe, Y . Wu, A. Tamar, J. Harb, P. Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environ- ments,” inAdvances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc., 2017
work page 2017
-
[29]
J. Xu, P. Hu, and B. Alrifaee, “Sigmarl: A sample-efficient and gen- eralizable multi-agent reinforcement learning framework for motion planning,” in2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC), 2024, pp. 768–775
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.