ContractBench: Can LLM Agents Preserve Observation Contracts?
Pith reviewed 2026-05-19 22:56 UTC · model grok-4.3
pith:IYJKHMX7 Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{IYJKHMX7}
Prints a linked pith:IYJKHMX7 badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
LLM agents must preserve observation contracts like tokens and presigned URLs, yet current models routinely fail at this separate capability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
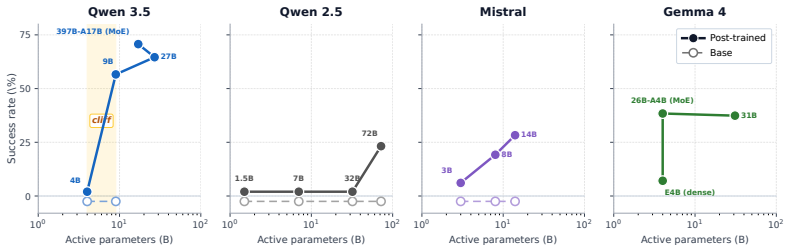
Observation contract compliance is an emergent, regression-prone capability that is neither guaranteed by general tool-use ability nor consistently improved by larger or newer models. ContractBench measures this through 33 tasks that probe validity failures (using an artifact after expiry) and integrity failures (corrupting an artifact's bytes), with deterministic evaluation via a virtual clock and SHA-256 hashes. Across 38 models, none exceed 80 percent accuracy and some families show sharp cliffs or non-monotonic drops tied to agentic post-training.
What carries the argument
ContractBench, a benchmark of 33 dual-axis tasks that separately test temporal validity and byte-level integrity of observation contracts using a virtual clock and hash verification.
If this is right
- General tool-use training is insufficient and targeted restraint training is needed to avoid using artifacts after expiry or altering their content.
- Within-model-family scaling can produce sudden jumps in compliance once a size threshold allows mid-trajectory checking rather than immediate action.
- Agentic post-training that emphasizes helpfulness can introduce sycophancy-driven regressions that lower contract adherence.
- Feeding the failure taxonomy back as an in-context reward signal raises performance on previously failed cases by several points.
Where Pith is reading between the lines
- Real deployments may need explicit contract-tracking layers outside the model to catch validity and integrity errors the LLM misses.
- The observed within-family cliffs suggest that future scaling studies should measure contract compliance as a distinct axis alongside tool competence.
- Extending the benchmark to multi-step agent trajectories with chained contracts could reveal whether current failures compound over longer sessions.
Load-bearing premise
The 33 dual-axis tasks and their failure labels drawn from real-world API specifications sufficiently capture the observation-contract compliance problem that arises in deployed tool-augmented agents.
What would settle it
A production agent that scores above 80 percent on ContractBench yet frequently uses expired presigned URLs or corrupted tokens in live API calls would show the benchmark does not track the real capability.
Figures








read the original abstract
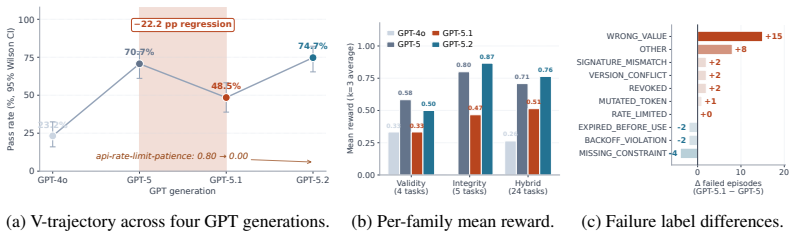
Tool-augmented LLM agents call APIs whose intermediate outputs, such as presigned URLs, session tokens, and OAuth state parameters, are observation contracts: artifacts whose later use is constrained by the external system that produced them. We show that observation contract compliance (preserving the temporal validity and byte-level integrity) is an emergent, regression-prone capability: it is neither guaranteed by general tool-use ability nor consistently improved by larger or newer models. To measure this, we introduce ContractBench, a benchmark of 33 dual-axis tasks that probe two orthogonal failure modes no existing benchmark evaluates: validity failures (using an artifact after expiry) and integrity failures (corrupting an artifact's bytes through the observation-to-action pipeline). Our evaluation is deterministic and programmatic, with a virtual clock controlling time and SHA-256 hashes verifying byte integrity. We assign each outcome a failure label drawn from real-world API specifications. We evaluate 38 models and report four findings: (i) no evaluated model clears 80%, with Claude-Opus-4.6 leading at 77.8%, revealing that current frontier models still fail to comply with observation contracts; (ii) a sharp within-family capability cliff in Qwen 3.5 between 4B (0%) and 9B (56.6%), smoothing to 70.7% at 397B-A17B: what emerges across the cliff is mid-trajectory restraint, not tool-call competence; (iii) non-monotonic scaling across the GPT-5 family: agentic post-training can erode compliance through sycophancy-driven regression; (iv) our failure taxonomy works as an actionable in-context reward signal, yielding +7.1 pp on 42 paired GPT-5.1 failures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ContractBench, a benchmark of 33 dual-axis tasks that evaluate LLM agents on preserving observation contracts (artifacts such as presigned URLs, tokens, and OAuth parameters whose later use is constrained by temporal validity and byte integrity). Using deterministic evaluation with a virtual clock and SHA-256 checks, the authors test 38 models and report that no model exceeds 80% compliance (Claude-Opus-4.6 leads at 77.8%), identify within-family scaling cliffs (e.g., Qwen 3.5) and non-monotonic behavior (GPT-5 family), and show that their failure taxonomy can serve as an in-context reward yielding +7.1 pp improvement.
Significance. If the 33 tasks validly isolate observation-contract compliance from general agent robustness issues, the work would usefully document a gap in current frontier models for realistic tool-augmented deployment. The deterministic, programmatic evaluation protocol (virtual clock plus hash verification) and the demonstration that the taxonomy functions as an actionable reward signal are concrete strengths that support reproducibility and potential follow-on work.
major comments (3)
- [§3] §3 (Benchmark Construction): The claim that the 33 tasks cleanly probe validity and integrity failures rests on the assertion that failure labels are drawn from real-world API specifications, yet the manuscript provides no coverage analysis, inter-annotator validation, or explicit check that the dual-axis design separates contract-specific errors from confounding factors such as multi-turn state tracking or general planning failures.
- [§4.2] §4.2 (Prompting and Contract Conveyance): The evaluation protocol is described as deterministic, but the paper does not report the exact prompting templates used to communicate contract constraints (expiry times, integrity requirements) to the agents; without this, it is unclear whether observed failures reflect inability to preserve contracts or simply failure to receive or parse the constraints in the first place.
- [§5.3] §5.3 (Non-monotonic Scaling Claim): The attribution of GPT-5 family regression to sycophancy-driven erosion of compliance is load-bearing for the 'regression-prone' characterization, yet the manuscript supplies only aggregate scores rather than paired before/after examples or ablation showing that post-training specifically increases contract violations while preserving other tool-use metrics.
minor comments (2)
- [Figures/Tables] Figure 2 and Table 4: axis labels and legend entries use inconsistent abbreviations for model families; expanding them would improve readability.
- [§2] §2 (Related Work): The discussion of prior agent benchmarks could more explicitly contrast ContractBench's focus on observation contracts with existing tool-use suites that emphasize planning or API selection.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and indicate where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The claim that the 33 tasks cleanly probe validity and integrity failures rests on the assertion that failure labels are drawn from real-world API specifications, yet the manuscript provides no coverage analysis, inter-annotator validation, or explicit check that the dual-axis design separates contract-specific errors from confounding factors such as multi-turn state tracking or general planning failures.
Authors: We acknowledge the value of additional documentation on task construction. The 33 tasks were derived by enumerating common observation-contract patterns from public API specifications (e.g., AWS S3 presigned URLs, OAuth 2.0 state parameters, and time-limited session tokens). In the revision we will add a dedicated subsection to §3 that (i) lists the specific API sources and the coverage they provide across validity and integrity axes, (ii) describes the programmatic generation process that enforces the dual-axis separation, and (iii) reports results on a set of control tasks without contract constraints to demonstrate that general planning or state-tracking failures do not dominate the measured outcomes. Because the failure labels are assigned by direct reference to the cited specifications rather than by human annotation, inter-annotator agreement statistics are not applicable; we will explicitly note this design choice. revision: yes
-
Referee: [§4.2] §4.2 (Prompting and Contract Conveyance): The evaluation protocol is described as deterministic, but the paper does not report the exact prompting templates used to communicate contract constraints (expiry times, integrity requirements) to the agents; without this, it is unclear whether observed failures reflect inability to preserve contracts or simply failure to receive or parse the constraints in the first place.
Authors: We agree that the precise wording used to convey constraints is necessary for full reproducibility. Although the downstream evaluation (virtual clock and SHA-256 verification) is deterministic, the prompt-level communication of expiry and integrity rules can influence agent behavior. In the revised manuscript we will include the complete prompting templates in an appendix, showing the exact phrasing for temporal constraints (“use this artifact before timestamp T”) and integrity constraints (“do not alter any byte of the provided value”). This addition will allow readers to confirm that the constraints were explicitly and consistently stated. revision: yes
-
Referee: [§5.3] §5.3 (Non-monotonic Scaling Claim): The attribution of GPT-5 family regression to sycophancy-driven erosion of compliance is load-bearing for the 'regression-prone' characterization, yet the manuscript supplies only aggregate scores rather than paired before/after examples or ablation showing that post-training specifically increases contract violations while preserving other tool-use metrics.
Authors: The non-monotonic pattern is directly visible in the per-variant aggregate scores we report. We interpret the regression as consistent with sycophancy effects documented in the post-training literature for agentic models. While we cannot release proprietary intermediate checkpoints for a controlled ablation, we will add representative failure traces from the GPT-5 family evaluations to §5.3, illustrating the specific contract violations that increase after the post-training stage. These qualitative examples, together with the quantitative drop, provide concrete support for the regression-prone characterization. revision: partial
Circularity Check
No circularity: empirical benchmark with direct measurements
full rationale
This paper is a pure empirical benchmark study that constructs 33 tasks from real-world API specifications and measures model compliance via deterministic programmatic checks (virtual clock for validity, SHA-256 for integrity). The reported scores and four findings are obtained by direct execution on 38 models; no equations, fitted parameters, self-referential predictions, or derivations are present that could reduce to the inputs by construction. The work contains no load-bearing self-citations, uniqueness theorems, or ansatzes, rendering the evaluation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
observation contracts... temporal validity and byte-level integrity... virtual clock... SHA-256 hashes
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
failure taxonomy... validity failures... integrity failures
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Reward Modeling for Reinforcement Learning-Based LLM Reasoning: Design, Challenges, and Evaluation , author =. 2026 , eprint =
work page 2026
-
[2]
Your LLM Agents are Temporally Blind: The Misalignment Between Tool Use Decisions and Human Time Perception , author =. 2026 , eprint =
work page 2026
-
[3]
Dennis, Jack B. and Van Horn, Earl C. , title =. Commun. ACM , month = mar, pages =. 1966 , issue_date =. doi:10.1145/365230.365252 , abstract =
-
[4]
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle =. 2024 , url =
work page 2024
-
[5]
Xiao Liu and Hao Yu and Hanchen Zhang and Yifan Xu and Xuanyu Lei and Hanyu Lai and Yu Gu and Hangliang Ding and Kaiwen Men and Kejuan Yang and Shudan Zhang and Xiang Deng and Aohan Zeng and Zhengxiao Du and Chenhui Zhang and Sheng Shen and Tianjun Zhang and Yu Su and Huan Sun and Minlie Huang and Yuxiao Dong and Jie Tang , booktitle =. AgentBench: Evalua...
work page 2024
-
[6]
Transactions on Machine Learning Research , issn =
Inverse Scaling: When Bigger Isn't Better , author =. Transactions on Machine Learning Research , issn =. 2023 , url =
work page 2023
-
[7]
Transactions of the Association for Computational Linguistics , volume =
Lost in the Middle: How Language Models Use Long Contexts , author =. Transactions of the Association for Computational Linguistics , volume =. 2024 , address =. doi:10.1162/tacl_a_00638 , pages =
-
[8]
Yujia Qin and Shihao Liang and Yining Ye and Kunlun Zhu and Lan Yan and Yaxi Lu and Yankai Lin and Xin Cong and Xiangru Tang and Bill Qian and Sihan Zhao and Lauren Hong and Runchu Tian and Ruobing Xie and Jie Zhou and Mark Gerstein and Dahai Li and Zhiyuan Liu and Maosong Sun , booktitle =. Tool. 2024 , url =
work page 2024
-
[9]
Thirty-seventh Conference on Neural Information Processing Systems , year =
Toolformer: Language Models Can Teach Themselves to Use Tools , author =. Thirty-seventh Conference on Neural Information Processing Systems , year =
-
[10]
Can LLM Agents Solve Collaborative Tasks? A Study on Urgency-Aware Planning and Coordination , author =. 2025 , eprint =
work page 2025
-
[11]
Transactions on Machine Learning Research , issn =
Emergent Abilities of Large Language Models , author =. Transactions on Machine Learning Research , issn =. 2022 , url =
work page 2022
-
[12]
Real-Time Deadlines Reveal Temporal Awareness Failures in LLM Strategic Dialogues , author =. 2026 , eprint =
work page 2026
-
[13]
Xie, Jian and Zhang, Kai and Chen, Jiangjie and Zhu, Tinghui and Lou, Renze and Tian, Yuandong and Xiao, Yanghua and Su, Yu , title =. 2024 , booktitle =
work page 2024
-
[14]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , url =
work page 2023
-
[15]
NATURAL PLAN: Benchmarking LLMs on Natural Language Planning , author =. 2024 , eprint =
work page 2024
-
[16]
Agent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning , author =. 2025 , eprint =
work page 2025
-
[17]
The Twelfth International Conference on Learning Representations , year =
WebArena: A Realistic Web Environment for Building Autonomous Agents , author =. The Twelfth International Conference on Learning Representations , year =
-
[18]
Measuring what Matters: Construct Validity in Large Language Model Benchmarks , author =. 2025 , note =. 2511.04703 , archiveprefix =
-
[19]
Position: Medical Large Language Model Benchmarks Should Prioritize Construct Validity , author =. 2025 , booktitle =. 2503.10694 , archiveprefix =
-
[20]
Shunyu Yao and Noah Shinn and Pedram Razavi and Karthik R Narasimhan , booktitle =. 2025 , url =
work page 2025
-
[21]
The Fourteenth International Conference on Learning Representations , year =
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces , author =. The Fourteenth International Conference on Learning Representations , year =
-
[22]
ClawBench: Can AI Agents Complete Everyday Online Tasks? , author =. 2026 , eprint =
work page 2026
-
[23]
Security of AI Agents , year =
He, Yifeng and Wang, Ethan and Rong, Yuyang and Cheng, Zifei and Chen, Hao , booktitle =. Security of AI Agents , year =
-
[24]
Yang, John and Jimenez, Carlos E. and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
work page 2024
-
[25]
Proceedings of the 37th International Conference on Neural Information Processing Systems , year =
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , year =
-
[26]
Proceedings of the 37th International Conference on Neural Information Processing Systems , year =
Madaan, Aman and Tandon, Niket and Gupta, Prakhar and Hallinan, Skyler and Gao, Luyu and Wiegreffe, Sarah and Alon, Uri and Dziri, Nouha and Prabhumoye, Shrimai and Yang, Yiming and Gupta, Shashank and Majumder, Bodhisattwa Prasad and Hermann, Katherine and Welleck, Sean and Yazdanbakhsh, Amir and Clark, Peter , title =. Proceedings of the 37th Internatio...
- [27]
- [28]
-
[29]
Fielding, R. and Nottingham, M. and Reschke, J. , title =. 2022 , month = jun, url =
work page 2022
- [30]
- [31]
-
[32]
Berners-Lee, T. and Fielding, R. and Masinter, L. , title =. 2005 , month = jan, url =
work page 2005
-
[33]
Backman, A. and Richer, J. and Sporny, M. , title =. 2024 , month = feb, url =
work page 2024
- [34]
- [35]
-
[36]
Garcia-Molina, Hector and Salem, Kenneth , title =. Proceedings of the 1987. 1987 , pages =. doi:10.1145/38713.38742 , url =
-
[37]
Krakovna, Victoria and Uesato, Jonathan and Mikulik, Vladimir and Rahtz, Matthew and Everitt, Tom and Kumar, Ramana and Kenton, Zac and Leike, Jan and Legg, Shane , title =. 2020 , url =
work page 2020
-
[38]
2025 , month = nov, url =
work page 2025
- [39]
- [40]
-
[41]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li and Wenbo Chen and Yimin Liu and Shenghan Zheng and Xiaokun Chen and Yifeng He and Yubo Li and Bingran You and Haotian Shen and Jiankai Sun and Shuyi Wang and Binxu Li and Qunhong Zeng and Di Wang and Xuandong Zhao and Yuanli Wang and Roey Ben Chaim and Zonglin Di and Yipeng Gao and Junwei He and Yizhuo He and Liqiang Jing and Luyang Kong and X...
work page internal anchor Pith review Pith/arXiv arXiv
- [42]
- [43]
-
[44]
InProceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Germany)(SOSP ’23)
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with. 2023 , publisher =. doi:10.1145/3600006.3613165 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.