HierEdit: Region-Aware Hierarchical Diffusion for Efficient High-Resolution Editing
Pith reviewed 2026-05-20 14:35 UTC · model grok-4.3
The pith
HierEdit refines only edited regions at high resolution by first editing a low-resolution proxy to localize changes and supply guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
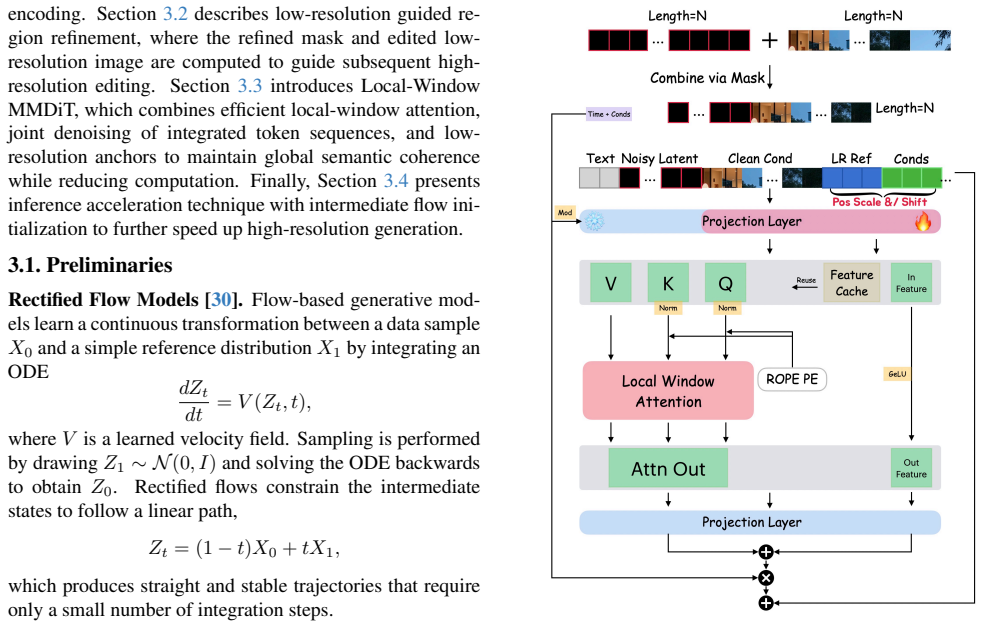
The central claim is that performing an initial edit on a low-resolution proxy localizes modified regions and supplies reliable structural guidance plus intermediate denoising supervision; a hierarchical Local-Window MMDiT then refines only the edited regions inside the full-resolution canvas while reusing unaltered areas as conditioning inputs, delivering fast high-fidelity results up to 4K resolution without any specialized high-resolution training data.
What carries the argument
The Local-Window MMDiT, a hierarchical diffusion model that restricts attention and refinement to localized edited windows while conditioning on both the original high-resolution unaltered regions and low-resolution proxy signals.
If this is right
- Editing inference becomes substantially faster because full-resolution attention is never computed over the entire image.
- The same model trained only on commodity-resolution data can be applied directly to 4K inputs.
- Visual quality remains competitive with existing methods on standard-resolution benchmarks.
- The framework extends without modification to images larger than 4K by scaling the local windows.
Where Pith is reading between the lines
- The same proxy-plus-local-refinement pattern could be tested on video clips to enforce temporal consistency by propagating the low-resolution edit across frames.
- Because the high-resolution stage only needs the low-resolution output as conditioning, the method might combine with any future low-resolution editor without retraining the local model.
- Similar hierarchical localization could reduce memory and compute in related tasks such as high-resolution image synthesis or texture generation.
Load-bearing premise
The low-resolution proxy must correctly identify which regions changed and must supply accurate structural guidance plus reliable intermediate denoising steps for the high-resolution local refinements.
What would settle it
Apply HierEdit to a 4K test image whose edit mask is known in advance, then compare the output to a full-canvas high-resolution baseline: visible artifacts or semantic drift in the refined patches, or unintended changes in the untouched areas, would contradict the claim.
Figures













read the original abstract
High-resolution image editing is essential for professional and creative applications, yet existing multimodal diffusion-based editors remain computationally inefficient and constrained to relatively low resolutions. Current approaches redundantly process the entire image canvas or rely on large-scale high-resolution datasets, resulting in substantial training and inference costs. We introduce HierEdit, a region-aware hierarchical diffusion framework designed for efficient and scalable high-resolution image editing. Our method first performs edits on a low-resolution proxy using an off-the-shelf editing model to generate a reference and to localize the modified regions. A hierarchical local-window diffusion model (\textbf{Local-Window MMDiT}) that refines only edited regions within the original high-res image, while reusing the unaltered regions as conditioning inputs. The low-resolution proxy further provides structural guidance and intermediate denoising supervision (\textbf{Inference Acceleration}) , ensuring consistent global semantics and stable generation without the need for full-resolution attention computation. This targeted and hierarchical design enables fast, high-fidelity editing of images up to 4K resolution without any specialized high-resolution training data. Extensive experiments demonstrate that HierEdit achieves competitive visual quality on commodity-resolution datasets while significantly accelerating inference and extending seamlessly to ultra-high-resolution 4K editing. Please check our {\href{https://peteryyzhang.github.io/HierEdit-page/}{\textbf{Project Page}}}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HierEdit, a region-aware hierarchical diffusion framework for efficient high-resolution image editing. It first applies an off-the-shelf editing model to a low-resolution proxy to generate a reference edit and localize modified regions. A Local-Window MMDiT then refines only the edited regions within the original high-resolution image while reusing unaltered regions as conditioning inputs; the low-resolution proxy additionally supplies structural guidance and intermediate denoising supervision to maintain global consistency without full-resolution attention. The targeted design is claimed to enable fast, high-fidelity editing up to 4K resolution without any specialized high-resolution training data, with experiments demonstrating competitive visual quality on commodity-resolution datasets and significant inference acceleration.
Significance. If the low-resolution localization and guidance transfer reliably to high resolution, the hierarchical construction could meaningfully lower the computational barrier for professional-grade 4K image editing by avoiding full-canvas diffusion and high-resolution training data requirements, offering a practical route to scalable editing on commodity hardware.
major comments (1)
- [Abstract and method overview] Abstract / hierarchical local-window diffusion model description: the central claim that the low-resolution proxy produces a mask that correctly identifies all modified pixels at native 4K scale and supplies reliable structural guidance plus intermediate denoising targets for the Local-Window MMDiT rests on an unverified transfer assumption; no analysis or bound is provided on localization error for edits whose effects appear only at high spatial frequencies, which directly undermines the fidelity and efficiency guarantees for ultra-high-resolution cases.
minor comments (2)
- [Abstract] The sentence introducing the Local-Window MMDiT is grammatically incomplete and should be rephrased for clarity.
- [Abstract] The parenthetical label '(Inference Acceleration)' is introduced without prior definition or cross-reference; consider moving the description to a dedicated subsection.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the localization transfer assumption. We address the concern directly below and commit to revisions that strengthen the empirical grounding of the method for high-resolution cases.
read point-by-point responses
-
Referee: [Abstract and method overview] Abstract / hierarchical local-window diffusion model description: the central claim that the low-resolution proxy produces a mask that correctly identifies all modified pixels at native 4K scale and supplies reliable structural guidance plus intermediate denoising targets for the Local-Window MMDiT rests on an unverified transfer assumption; no analysis or bound is provided on localization error for edits whose effects appear only at high spatial frequencies, which directly undermines the fidelity and efficiency guarantees for ultra-high-resolution cases.
Authors: We agree that the current manuscript lacks explicit analysis or quantitative bounds on how localization errors from the low-resolution proxy transfer to native 4K resolution, particularly when edit effects are confined to high spatial frequencies. The design relies on the low-resolution edit capturing the dominant semantic and structural modifications, with the Local-Window MMDiT then performing localized refinement on the high-resolution canvas while conditioning on unaltered regions and low-resolution structural guidance. This hierarchical reuse is intended to preserve global consistency even if the mask is imperfect at fine scales. To directly address the referee's point, we will revise the manuscript to include a new subsection with empirical evaluation of localization accuracy (e.g., pixel-level overlap metrics between low-res-derived masks and ground-truth high-res change maps) across edit categories, including synthetic high-frequency modifications. We will also discuss observed failure modes and the role of window overlap in mitigating boundary localization errors. revision: yes
Circularity Check
No circularity: engineering construction with external validation
full rationale
The paper presents HierEdit as a practical hierarchical framework: low-resolution proxy editing with an off-the-shelf model for localization and guidance, followed by local-window MMDiT refinement on high-resolution edited regions. This is an engineering design rather than a first-principles derivation or closed-form result. No equations, fitted parameters, or self-citations reduce the performance claims to quantities defined by the method itself. The approach relies on external models and empirical experiments on commodity datasets, remaining self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Off-the-shelf low-resolution editing model produces accurate region localization and structural guidance usable at high resolution.
- domain assumption Local-window attention in the MMDiT can maintain global consistency when conditioned on unaltered high-resolution regions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
This targeted and hierarchical design enables fast, high-fidelity editing of images up to 4K resolution without any specialized high-resolution training data
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Long- former: The long-document transformer.arXiv preprint arXiv:2004.05150, 2020. 3
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[3]
Black Forest Labs. Flux. Black Forest Labs GitHub reposi- tory, 2024. Model release. 2, 4, 6, 1
work page 2024
-
[4]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs. Flux.1 kontext: Flow matching for in- context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025. 1, 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Hiflow: Training-free high-resolution image gen- eration with flow-aligned guidance
Jiazi Bu, Pengyang Ling, Yujie Zhou, Pan Zhang, Tong Wu, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Dahua Lin, and Ji- aqi Wang. Hiflow: Training-free high-resolution image gen- eration with flow-aligned guidance. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. 3
work page 2025
-
[6]
Hidream-i1: An open-source high-efficient image genera- tive foundation model
Qi Cai, Yehao Li, Yingwei Pan, Ting Yao, and Tao Mei. Hidream-i1: An open-source high-efficient image genera- tive foundation model. InACM International Conference on Multimedia (ACM MM), page 13636–13639, New York, NY , USA, 2025. Association for Computing Machinery. 2, 4
work page 2025
-
[7]
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models.ACM Transactions on Graphics (TOG), 42(4):1–10, 2023. 2
work page 2023
-
[8]
Junsong Chen, Yue Wu, Simian Luo, Enze Xie, Sayak Paul, Ping Luo, Hang Zhao, and Zhenguo Li. Pixart-δ: Fast and controllable image generation with latent consistency mod- els.arXiv preprint arXiv:2401.05252, 2024. 2
-
[9]
Pixart-$\alpha$: Fast train- ing of diffusion transformer for photorealistic text-to-image synthesis
Junsong Chen, Jincheng YU, Chongjian GE, Lewei Yao, Enze Xie, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-$\alpha$: Fast train- ing of diffusion transformer for photorealistic text-to-image synthesis. InInternational Conference on Learning Repre- sentations (ICLR), 2024. 2
work page 2024
-
[10]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus- pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Flashattention-2: Faster attention with better par- allelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better par- allelism and work partitioning. InInternational Conference on Learning Representations (ICLR), 2024. 2, 3
work page 2024
-
[12]
Fu, Stefano Ermon, Atri Rudra, and Christopher R ´e
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher R ´e. Flashattention: Fast and memory-efficient exact attention with io-awareness. InAdvances in Neural Information Processing Systems (NeurIPS), pages 16344– 16359, 2022. 2, 3
work page 2022
-
[13]
Yichuan Deng, Zhao Song, Jing Xiong, and Chiwun Yang. How sparse attention approximates exact atten- tion? your attention is naturallyn c-sparse.arXiv preprint arXiv:2404.02690, 2025. 3
-
[14]
Cogview: mastering text-to- image generation via transformers
Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, and Jie Tang. Cogview: mastering text-to- image generation via transformers. InConference on Neural Information Processing Systems (NeurIPS), Red Hook, NY , USA, 2021. Curran Associates Inc. 2
work page 2021
-
[15]
Ruoyi Du, Dongyang Liu, Le Zhuo, Qin Qi, Hongsheng Li, Zhanyu Ma, and Peng Gao. I-max: Maximize the resolu- tion potential of pre-trained rectified flow transformers with projected flow.arXiv preprint arXiv:2410.07536, 2024. 3
-
[16]
An image is worth one word: Personalizing text-to-image gen- eration using textual inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image gen- eration using textual inversion. InInternational Conference on Learning Representations (ICLR), 2023. 2
work page 2023
-
[17]
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, et al. Seedream 3.0 technical report.arXiv preprint arXiv:2504.11346, 2025. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Make a cheap scaling: A self- cascade diffusion model for higher-resolution adaptation
Lanqing Guo, Yingqing He, Haoxin Chen, Menghan Xia, Xi- aodong Cun, Yufei Wang, Siyu Huang, Yong Zhang, Xintao Wang, Qifeng Chen, et al. Make a cheap scaling: A self- cascade diffusion model for higher-resolution adaptation. In European Conference on Computer Vision (ECCV), pages 39–55. Springer, 2024. 3
work page 2024
-
[19]
Bridging the divide: Reconsidering softmax and linear atten- tion
Dongchen Han, Yifan Pu, Zhuofan Xia, Yizeng Han, Xu- ran Pan, Xiu Li, Jiwen Lu, Shiji Song, and Gao Huang. Bridging the divide: Reconsidering softmax and linear atten- tion. InAdvances in Neural Information Processing Systems (NeurIPS), pages 79221–79245, 2024. 3
work page 2024
-
[20]
sim- ple diffusion: End-to-end diffusion for high resolution im- ages
Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. sim- ple diffusion: End-to-end diffusion for high resolution im- ages. InInternational Conference on Machine Learning (ICML), pages 13213–13232. PMLR, 2023. 3
work page 2023
-
[21]
Fouriscale: A frequency perspective on training-free high-resolution im- age synthesis
Linjiang Huang, Rongyao Fang, Aiping Zhang, Guanglu Song, Si Liu, Yu Liu, and Hongsheng Li. Fouriscale: A frequency perspective on training-free high-resolution im- age synthesis. InEuropean Conference on Computer Vision (ECCV), pages 196–212. Springer, 2024. 3
work page 2024
-
[22]
Bohan Jia, Wenxuan Huang, Yuntian Tang, Junbo Qiao, Jincheng Liao, Shaosheng Cao, Fei Zhao, Zhaopeng Feng, Zhouhong Gu, Zhenfei Yin, Lei Bai, Wanli Ouyang, Lin Chen, Fei Zhao, Zihan Wang, Yuan Xie, and Shaohui Lin. Compbench: Benchmarking complex instruction-guided im- age editing.arXiv preprint arXiv:2505.12200, 2025. 1
-
[23]
Diffusehigh: Training-free progressive high- resolution image synthesis through structure guidance
Younghyun Kim, Geunmin Hwang, Junyu Zhang, and Eun- byung Park. Diffusehigh: Training-free progressive high- resolution image synthesis through structure guidance. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 4338–4346, 2025. 3
work page 2025
-
[24]
Flexprefill: A context-aware sparse attention mecha- nism for efficient long-sequence inference
Xunhao Lai, Jianqiao Lu, Yao Luo, Yiyuan Ma, and Xun Zhou. Flexprefill: A context-aware sparse attention mecha- nism for efficient long-sequence inference. InInternational Conference on Learning Representations (ICLR), 2025. 3
work page 2025
-
[25]
Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation
Daiqing Li, Aleks Kamko, Ehsan Akhgari, Ali Sabet, Lin- miao Xu, and Suhail Doshi. Playground v2. 5: Three in- sights towards enhancing aesthetic quality in text-to-image generation.arXiv preprint arXiv:2402.17245, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jian- wei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22511–22521, 2023. 2
work page 2023
-
[27]
Zhimin Li, Jianwei Zhang, Qin Lin, Jiangfeng Xiong, Yanxin Long, Xinchi Deng, Yingfang Zhang, Xingchao Liu, Minbin Huang, Zedong Xiao, et al. Hunyuan-dit: A powerful multi-resolution diffusion transformer with fine-grained chi- nese understanding.arXiv preprint arXiv:2405.08748, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Liu Liu, Zheng Qu, Zhaodong Chen, Fengbin Tu, Yufei Ding, and Yuan Xie. Dynamic sparse attention for scalable transformer acceleration.IEEE Transactions on Computers (TC), 71(12):3165–3178, 2022. 3
work page 2022
-
[29]
Linfusion: 1 gpu, 1 minute, 16k image.arXiv preprint arXiv:2409.02097, 2024
Songhua Liu, Weihao Yu, Zhenxiong Tan, and Xinchao Wang. Linfusion: 1 gpu, 1 minute, 16k image.arXiv preprint arXiv:2409.02097, 2024. 3
-
[30]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Rep- resentations (ICLR), 2023. 4
work page 2023
-
[31]
Hiprompt: Tuning-free higher-resolution gen- eration with hierarchical mllm prompts
Xinyu Liu, Yingqing He, Lanqing Guo, Xiang Li, Bu Jin, Peng Li, Yan Li, Chi-Min Chan, Qifeng Chen, Wei Xue, et al. Hiprompt: Tuning-free higher-resolution gen- eration with hierarchical mllm prompts.arXiv preprint arXiv:2409.02919, 2024. 3
-
[32]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021. 3
work page 2021
-
[33]
I2ebench: A comprehensive benchmark for instruction- based image editing
Yiwei Ma, Jiayi Ji, Ke Ye, Weihuang Lin, Zhibin Wang, Yonghan Zheng, Qiang Zhou, Xiaoshuai Sun, and Rongrong Ji. I2ebench: A comprehensive benchmark for instruction- based image editing. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), pages 41494–41516. Curran As- sociates, Inc., 2024. 1
work page 2024
-
[34]
ACE++: Instruction-Based Image Creation and Editing via Context- Aware Content Filling
Chaojie Mao, Jingfeng Zhang, Yulin Pan, Zeyinzi Jiang, Zhen Han, Yu Liu, and Jingren Zhou. Ace++: Instruction- based image creation and editing via context-aware content filling.arXiv preprint arXiv:2501.02487, 2025. 6
-
[35]
SDEdit: Guided image synthesis and editing with stochastic differential equa- tions
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jia- jun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equa- tions. InInternational Conference on Learning Representa- tions (ICLR), 2022. 6
work page 2022
-
[36]
Polaformer: Polarity-aware linear attention for vision transformers
Weikang Meng, Yadan Luo, Xin Li, Dongmei Jiang, and Zheng Zhang. Polaformer: Polarity-aware linear attention for vision transformers. InInternational Conference on Learning Representations (ICLR), 2025. 3
work page 2025
-
[37]
Glide: Towards photorealis- tic image generation and editing with text-guided diffusion models
Alexander Quinn Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob Mcgrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealis- tic image generation and editing with text-guided diffusion models. InInternational Conference on Machine Learning (ICML), pages 16784–16804. PMLR, 2022. 2
work page 2022
-
[38]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 4195–4205,
-
[39]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. InInternational Con- ference on Learning Representations (ICLR), pages 1862– 1874, 2024. 1, 2
work page 2024
-
[40]
Freescale: Unleashing the resolution of diffusion models via tuning-free scale fusion
Haonan Qiu, Shiwei Zhang, Yujie Wei, Ruihang Chu, Hangjie Yuan, Xiang Wang, Yingya Zhang, and Ziwei Liu. Freescale: Unleashing the resolution of diffusion models via tuning-free scale fusion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16893– 16903, 2025. 3
work page 2025
-
[41]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents.arXiv preprint arXiv:2204.06125, 1 (2):3, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
Ultrapixel: Advancing ultra high-resolution image synthesis to new peaks
Jingjing Ren, Wenbo Li, Haoyu Chen, Renjing Pei, Bin Shao, Yong Guo, Long Peng, Fenglong Song, and Lei Zhu. Ultrapixel: Advancing ultra high-resolution image synthesis to new peaks. InAdvances in Neural Information Process- ing Systems (NeurIPS), pages 111131–111171. Curran As- sociates, Inc., 2024. 3
work page 2024
-
[43]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022. 1, 2
work page 2022
-
[44]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22500– 22510, 2023. 2
work page 2023
-
[45]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in Neural Information Processing Systems (NeurIPS), 35:36479–36494, 2022. 2
work page 2022
-
[46]
Flashattention-3: Fast and accurate attention with asynchrony and low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: Fast and accurate attention with asynchrony and low-precision. InAd- vances in Neural Information Processing Systems (NeurIPS), pages 68658–68685, 2024. 3
work page 2024
-
[47]
Emu edit: Precise image editing via recognition and gen- eration tasks
Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh, and Yaniv Taigman. Emu edit: Precise image editing via recognition and gen- eration tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8871– 8879, 2024. 1
work page 2024
-
[48]
Trainable dynamic mask sparse attention.arXiv preprint arXiv:2508.02124, 2025
Jingze Shi, Yifan Wu, Bingheng Wu, Yiran Peng, Liangdong Wang, Guang Liu, and Yuyu Luo. Trainable dynamic mask sparse attention.arXiv preprint arXiv:2508.02124, 2025. 1
-
[49]
Resmaster: Mastering high- resolution image generation via structural and fine-grained guidance
Shuwei Shi, Wenbo Li, Yuechen Zhang, Jingwen He, Biao Gong, and Yinqiang Zheng. Resmaster: Mastering high- resolution image generation via structural and fine-grained guidance. InProceedings of the AAAI Conference on Artifi- cial Intelligence, pages 6887–6895, 2025. 3
work page 2025
-
[50]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[51]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Ominicontrol: Minimal and univer- sal control for diffusion transformer
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and univer- sal control for diffusion transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14940–14950, 2025. 3
work page 2025
-
[53]
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang
Zhenxiong Tan, Qiaochu Xue, Xingyi Yang, Songhua Liu, and Xinchao Wang. Ominicontrol2: Efficient conditioning for diffusion transformers.arXiv preprint arXiv:2503.08280,
-
[54]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Relay diffusion: Unifying diffusion process across resolutions for image syn- thesis
Jiayan Teng, Wendi Zheng, Ming Ding, Wenyi Hong, Jian- qiao Wangni, Zhuoyi Yang, and Jie Tang. Relay diffusion: Unifying diffusion process across resolutions for image syn- thesis. InInternational Conference on Learning Representa- tions (ICLR), 2024. 3
work page 2024
-
[56]
Haoning Wu, Shaocheng Shen, Qiang Hu, Xiaoyun Zhang, Ya Zhang, and Yanfeng Wang. Megafusion: Extend dif- fusion models towards higher-resolution image generation without further tuning. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3944–3953. IEEE, 2025. 3
work page 2025
-
[57]
Sparse videogen: Accelerating video diffusion transformers with spatial-temporal sparsity
Haocheng Xi, Shuo Yang, Yilong Zhao, Chenfeng Xu, Muyang Li, Xiuyu Li, Yujun Lin, Han Cai, Jintao Zhang, Dacheng Li, et al. Sparse videogen: Accelerating video diffusion transformers with spatial-temporal sparsity. InIn- ternational Conference on Machine Learning (ICML), pages 68208–68224, 2025. 3
work page 2025
-
[58]
Enze Xie, Lewei Yao, Han Shi, Zhili Liu, Daquan Zhou, Zhaoqiang Liu, Jiawei Li, and Zhenguo Li. Difffit: Un- locking transferability of large diffusion models via sim- ple parameter-efficient fine-tuning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4230–4239, 2023. 3
work page 2023
-
[59]
SANA: Efficient high-resolution text-to-image synthesis with linear diffusion transformers
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, and Song Han. SANA: Efficient high-resolution text-to-image synthesis with linear diffusion transformers. InInternational Conference on Learning Representations (ICLR), 2025. 2, 3
work page 2025
-
[60]
Enze Xie, Junsong Chen, Yuyang Zhao, Jincheng YU, Ligeng Zhu, Yujun Lin, Zhekai Zhang, Muyang Li, Junyu Chen, Han Cai, Bingchen Liu, Daquan Zhou, and Song Han. SANA 1.5: Efficient scaling of training-time and inference- time compute in linear diffusion transformer. InInterna- tional Conference on Machine Learning (ICML), 2025. 2, 3
work page 2025
-
[61]
Show-o: One single transformer to unify multimodal understanding and generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation. InInternational Conference on Learning Rep- resentations (ICLR), 2025. 2
work page 2025
-
[62]
Xattention: Block sparse attention with an- tidiagonal scoring
Ruyi Xu, Guangxuan Xiao, Haofeng Huang, Junxian Guo, and Song Han. Xattention: Block sparse attention with an- tidiagonal scoring. InInternational Conference on Machine Learning (ICML), pages 69819–69831, 2025. 3
work page 2025
-
[63]
Raphael: text-to-image generation via large mixture of diffusion paths
Zeyue Xue, Guanglu Song, Qiushan Guo, Boxiao Liu, Zhuo- fan Zong, Yu Liu, and Ping Luo. Raphael: text-to-image generation via large mixture of diffusion paths. InConfer- ence on Neural Information Processing Systems (NeurIPS), Red Hook, NY , USA, 2023. Curran Associates Inc. 2
work page 2023
-
[64]
Sparse videogen2: Accelerate video generation with sparse attention via semantic-aware permutation
Shuo Yang, Haocheng Xi, Yilong Zhao, Muyang Li, Jintao Zhang, Han Cai, Yujun Lin, Xiuyu Li, Chenfeng Xu, Kelly Peng, et al. Sparse videogen2: Accelerate video generation with sparse attention via semantic-aware permutation. InAd- vances in Neural Information Processing Systems (NeurIPS),
-
[65]
Imgedit: A uni- fied image editing dataset and benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A uni- fied image editing dataset and benchmark. InNeural Infor- mation Processing Systems Datasets and Benchmarks Track (NeurIPS D&B), 2025. 1
work page 2025
-
[66]
Ultra-resolution adaptation with ease
Ruonan Yu, Songhua Liu, Zhenxiong Tan, and Xinchao Wang. Ultra-resolution adaptation with ease. InInterna- tional Conference on Machine Learning (ICML), 2025. 3
work page 2025
-
[67]
Ditfastattn: Attention compression for diffusion transformer models
Zhihang Yuan, Hanling Zhang, Lu Pu, Xuefei Ning, Lin- feng Zhang, Tianchen Zhao, Shengen Yan, Guohao Dai, and Yu Wang. Ditfastattn: Attention compression for diffusion transformer models. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), pages 1196–1219, 2024. 3
work page 2024
-
[68]
Ditfastattnv2: Head-wise attention compression for multi-modality diffusion transformers
Hanling Zhang, Rundong Su, Zhihang Yuan, Pengtao Chen, Mingzhu Shen, Yibo Fan, Shengen Yan, Guohao Dai, and Yu Wang. Ditfastattnv2: Head-wise attention compression for multi-modality diffusion transformers. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 16399–16409, 2025. 3
work page 2025
-
[69]
Jintao Zhang, Haofeng Huang, Pengle Zhang, Jia Wei, Jun Zhu, and Jianfei Chen. Sageattention2: Efficient attention with thorough outlier smoothing and per-thread int4 quan- tization. InInternational Conference on Machine Learning (ICML), 2025. 3
work page 2025
-
[70]
Diffusion-4k: Ultra-high-resolution image syn- thesis with latent diffusion models
Jinjin Zhang, Qiuyu Huang, Junjie Liu, Xiefan Guo, and Di Huang. Diffusion-4k: Ultra-high-resolution image syn- thesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23464–23473, 2025. 3
work page 2025
-
[71]
Sageattention: Accurate 8-bit attention for plug-and- play inference acceleration
Jintao Zhang, Jia Wei, Pengle Zhang, Jun Zhu, and Jianfei Chen. Sageattention: Accurate 8-bit attention for plug-and- play inference acceleration. InInternational Conference on Learning Representations (ICLR), 2025. 3
work page 2025
-
[72]
Spargeattn: Accu- rate sparse attention accelerating any model inference
Jintao Zhang, Chendong Xiang, Haofeng Huang, Jia Wei, Haocheng Xi, Jun Zhu, and Jianfei Chen. Spargeattn: Accu- rate sparse attention accelerating any model inference. InIn- ternational Conference on Machine Learning (ICML), pages 76397–76413, 2025. 3
work page 2025
-
[73]
Designing a practical degradation model for deep blind image super-resolution
Kai Zhang, Jingyun Liang, Luc Van Gool, and Radu Timo- fte. Designing a practical degradation model for deep blind image super-resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4791– 4800, 2021. 1
work page 2021
-
[74]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023. 2
work page 2023
-
[75]
The hedgehog & the porcupine: Expres- sive linear attentions with softmax mimicry
Michael Zhang, Kush Bhatia, Hermann Kumbong, and Christopher R ´e. The hedgehog & the porcupine: Expres- sive linear attentions with softmax mimicry. InInternational Conference on Learning Representations (ICLR), 2024. 3
work page 2024
-
[76]
Scale-dit: Ultra-high- resolution image generation with hierarchical local attention
Yuyao Zhang and Yu-Wing Tai. Scale-dit: Ultra-high- resolution image generation with hierarchical local attention. arXiv preprint arXiv:2510.16325, 2025. 3
-
[77]
Layercraft: En- hancing text-to-image generation with cot reasoning and lay- ered object integration
Yuyao Zhang, Jinghao Li, and Yu-Wing Tai. Layercraft: En- hancing text-to-image generation with cot reasoning and lay- ered object integration. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. 1
work page 2025
-
[78]
Easycontrol: Adding efficient and flexible control for diffusion transformer
Yuxuan Zhang, Yirui Yuan, Yiren Song, Haofan Wang, and Jiaming Liu. Easycontrol: Adding efficient and flexible control for diffusion transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19513–19524, 2025. 6
work page 2025
-
[79]
Any-size- diffusion: Toward efficient text-driven synthesis for any-size hd images
Qingping Zheng, Yuanfan Guo, Jiankang Deng, Jianhua Han, Ying Li, Songcen Xu, and Hang Xu. Any-size- diffusion: Toward efficient text-driven synthesis for any-size hd images. InProceedings of the AAAI Conference on Arti- ficial Intelligence, pages 7571–7578, 2024. 3
work page 2024
-
[80]
Dig: Scal- able and efficient diffusion models with gated linear atten- tion
Lianghui Zhu, Zilong Huang, Bencheng Liao, Jun Hao Liew, Hanshu Yan, Jiashi Feng, and Xinggang Wang. Dig: Scal- able and efficient diffusion models with gated linear atten- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 7664–7674,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.