VISTA: Triplet-Supervised Video Style Transfer with Diffusion Transformers
Pith reviewed 2026-05-20 14:09 UTC · model grok-4.3
The pith
Motion-aligned triplets and a diffusion transformer framework enable consistent video style transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
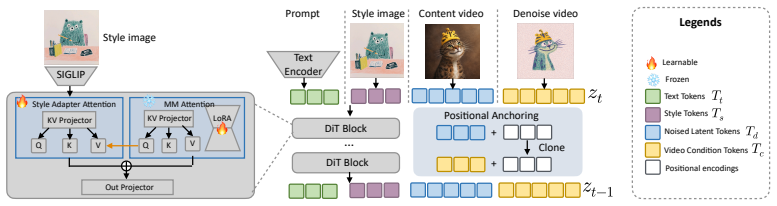
The authors claim that a diffusion-transformer-based in-context video style transfer framework, trained on their new VISTA-1000 synthetic dataset of motion-aligned triplets, achieves state-of-the-art performance in style fidelity, temporal consistency, and content preservation by addressing the fundamental data shortage and avoiding brittle heuristic temporal propagation methods.
What carries the argument
VISTA-1000 synthetic dataset with motion-aligned style-content-motion triplets and the diffusion-transformer in-context framework with lightweight style adapter for robust extraction.
If this is right
- Models trained this way can handle occlusions and long-term motion without introducing drift or flickering.
- The framework jointly disentangles and models style, content, and motion for better overall quality.
- Extensive experiments show superior performance over prior methods that stylize frames separately and propagate consistency heuristically.
Where Pith is reading between the lines
- Similar synthetic triplet approaches could be applied to other video manipulation tasks like object editing or special effects.
- Real-time applications might benefit if the lightweight adapter reduces computational overhead compared to full fine-tuning.
- Future work could explore mixing synthetic data with limited real data to further improve generalization.
Load-bearing premise
The assumption that training on synthetic motion-aligned triplets will produce a model that generalizes to real-world videos without introducing new temporal inconsistencies under occlusions, disocclusions, and long-term motion.
What would settle it
Applying the model to real-world videos featuring complex motions, occlusions, and disocclusions and observing persistent flickering or style drift would indicate the generalization premise does not hold.
Figures





read the original abstract
Video style transfer aims to render videos in a target artistic style while preserving content, structure, and motion. While image stylization has advanced rapidly, video stylization remains challenging due to temporal inconsistency. Most existing methods stylize frames or keyframes and enforce consistency via heuristic temporal propagation, which is brittle under occlusions, disocclusions, and long-term motion, leading to drift and flickering artifacts. We argue that a fundamental bottleneck lies in the lack of large-scale triplet data and a principled training paradigm that jointly models and disentangles style, content, and motion.To address this, we introduce VISTA-1000, a synthetic dataset with 1,000 styles and motion-aligned triplets of style reference, clean video, and stylized video, and propose a diffusion-transformer-based in-context video style transfer framework with a lightweight style adapter for robust style extraction. Extensive experiments demonstrate SOTA performance in style fidelity, temporal consistency, and content preservation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VISTA-1000, a synthetic dataset with 1,000 styles and motion-aligned triplets (style reference, clean video, stylized video), along with a diffusion-transformer-based in-context video style transfer framework that incorporates a lightweight style adapter for robust style extraction. The central claim is that this triplet-supervised approach overcomes the limitations of heuristic temporal propagation methods and achieves state-of-the-art performance in style fidelity, temporal consistency, and content preservation.
Significance. If the empirical claims are substantiated, the work would be significant for video style transfer by supplying a large-scale triplet dataset that enables joint modeling of style, content, and motion, moving beyond brittle post-hoc consistency enforcement. The diffusion-transformer architecture with in-context conditioning represents a timely application of current generative modeling techniques to a long-standing video processing challenge.
major comments (2)
- [Abstract and §1] Abstract and §1: The assertion that VISTA-1000 solves the fundamental bottleneck and yields a model that generalizes to real videos without new temporal inconsistencies is load-bearing for the SOTA claim. The manuscript provides no analysis or ablation showing that the synthetic data generation process reproduces real-world statistics for occlusions, disocclusions, and long-term non-rigid motion; without such evidence the transfer assumption remains untested.
- [Experiments section] Experiments section: The claim of SOTA performance in style fidelity, temporal consistency, and content preservation is not accompanied by quantitative tables, specific metric values (e.g., temporal warping error, LPIPS, or style similarity scores), baseline comparisons, or error analysis. This absence prevents verification that the reported improvements are statistically meaningful or robust across real-world test videos.
minor comments (1)
- [Methods] The description of the lightweight style adapter would benefit from an explicit architectural diagram or pseudocode to clarify its integration with the diffusion transformer.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully addressed each major comment below and revised the paper to strengthen the presentation of evidence supporting our claims.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: The assertion that VISTA-1000 solves the fundamental bottleneck and yields a model that generalizes to real videos without new temporal inconsistencies is load-bearing for the SOTA claim. The manuscript provides no analysis or ablation showing that the synthetic data generation process reproduces real-world statistics for occlusions, disocclusions, and long-term non-rigid motion; without such evidence the transfer assumption remains untested.
Authors: We agree that explicit validation of the synthetic data's fidelity to real-world statistics would better support the generalization claims. In the revised manuscript we have added a new subsection (Section 4.2) with quantitative comparisons of occlusion frequency, disocclusion events, and long-term non-rigid motion statistics between VISTA-1000 and real video datasets, together with an ablation studying their impact on temporal consistency. We also discuss remaining limitations of the synthetic generation process in the updated text. revision: yes
-
Referee: [Experiments section] Experiments section: The claim of SOTA performance in style fidelity, temporal consistency, and content preservation is not accompanied by quantitative tables, specific metric values (e.g., temporal warping error, LPIPS, or style similarity scores), baseline comparisons, or error analysis. This absence prevents verification that the reported improvements are statistically meaningful or robust across real-world test videos.
Authors: We acknowledge that the quantitative support for the SOTA claims was insufficiently detailed in the original submission. The revised Experiments section now includes comprehensive tables reporting temporal warping error, LPIPS, and style similarity scores, direct numerical comparisons against multiple baselines, and a dedicated error analysis subsection evaluating robustness on real-world test videos with statistical significance testing. revision: yes
Circularity Check
Empirical dataset and framework proposal with no derivation chain
full rationale
The paper presents VISTA-1000 as a new synthetic triplet dataset and a diffusion-transformer architecture with style adapter for video style transfer. Claims rest on experimental results for SOTA performance in fidelity, consistency, and preservation rather than any mathematical derivation. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or described structure. The central premise (triplet data as bottleneck) is addressed by construction of the dataset itself but does not reduce any performance claim to an input by definition; the work remains an independent empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic motion-aligned triplets can train models that generalize to real videos without temporal drift under occlusions and long-term motion.
invented entities (1)
-
VISTA-1000 dataset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv e-prints, pages arXiv–2506, 2025
work page 2025
-
[2]
Juliette Bertrand, Giorgos Kordopatis Zilos, Yannis Kalantidis, and Giorgos Tolias. Test- time training for matching-based video object segmentation.Advances in Neural Information Processing Systems, 36:20918–20941, 2023
work page 2023
-
[3]
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
work page 2024
-
[4]
EditTransfer++: Toward Faithful and Efficient Visual-Prompt-Guided Image Editing
Lan Chen, Qi Mao, Yiren Song, Yuchao Gu, and Siwei Ma. Edittransfer++: Toward faithful and efficient visual-prompt-guided image editing.arXiv preprint arXiv:2605.07455, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Ccedit: Creative and controllable video editing via diffusion models
Ruoyu Feng, Wenming Weng, Yanhui Wang, Yuhui Yuan, Jianmin Bao, Chong Luo, Zhibo Chen, and Baining Guo. Ccedit: Creative and controllable video editing via diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6712–6722, 2024
work page 2024
-
[6]
Adaworld: Learning adaptable world models with latent actions.arXiv preprint arXiv:2503.18938, 2025
Shenyuan Gao, Siyuan Zhou, Yilun Du, Jun Zhang, and Chuang Gan. Adaworld: Learning adaptable world models with latent actions.arXiv preprint arXiv:2503.18938, 2025
-
[7]
Fast video multi-style transfer
Wei Gao, Yijun Li, Yihang Yin, and Ming-Hsuan Yang. Fast video multi-style transfer. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 3222–3230, 2020
work page 2020
-
[8]
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistent diffusion features for consistent video editing.arXiv preprint arXiv:2307.10373, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Yan Gong, Yiren Song, Yicheng Li, Chenglin Li, and Yin Zhang. Relationadapter: Learning and transferring visual relation with diffusion transformers.arXiv preprint arXiv:2506.02528, 2025
-
[10]
Nano banana image generation, 2026
Google AI for Developers. Nano banana image generation, 2026. URL https://ai.google. dev/gemini-api/docs/image-generation. Last updated 2026-01-22 UTC
work page 2026
-
[11]
Any2anytryon: Leveraging adaptive position embeddings for versatile virtual clothing tasks
Hailong Guo, Bohan Zeng, Yiren Song, Wentao Zhang, Chuang Zhang, and Jiaming Liu. Any2anytryon: Leveraging adaptive position embeddings for versatile virtual clothing tasks. arXiv preprint arXiv:2501.15891, 2025
-
[12]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Real-time neural style transfer for videos
Haozhi Huang, Hao Wang, Wenhan Luo, Lin Ma, Wenhao Jiang, Xiaolong Zhu, Zhifeng Li, and Wei Liu. Real-time neural style transfer for videos. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 783–791, 2017
work page 2017
-
[14]
Lianghua Huang, Di Chen, Yu Liu, Yujun Shen, Deli Zhao, and Jingren Zhou. Com- poser: Creative and controllable image synthesis with composable conditions.arXiv preprint arXiv:2302.09778, 2023
-
[15]
Arbitrary style transfer in real-time with adaptive instance normalization
Xun Huang and Serge Belongie. Arbitrary style transfer in real-time with adaptive instance normalization. InProceedings of the IEEE international conference on computer vision, pages 1501–1510, 2017
work page 2017
-
[16]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pattern Analysis and Machine Intelli...
-
[18]
Scedit: Efficient and controllable image diffusion generation via skip connection editing
Zeyinzi Jiang, Chaojie Mao, Yulin Pan, Zhen Han, and Jingfeng Zhang. Scedit: Efficient and controllable image diffusion generation via skip connection editing. InProceedings of the IEEE/CVF conference on computer vision and pattern Recognition, pages 8995–9004, 2024
work page 2024
-
[19]
VACE: All-in-One Video Creation and Editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing.arXiv preprint arXiv:2503.07598, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Cotracker3: Simpler and better point tracking by pseudo-labelling real videos
Nikita Karaev, Yuri Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker3: Simpler and better point tracking by pseudo-labelling real videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6013–6022, 2025
work page 2025
-
[21]
Subin Kim, Kyungmin Lee, June Suk Choi, Jongheon Jeong, Kihyuk Sohn, and Jinwoo Shin. Collaborative score distillation for consistent visual synthesis.arXiv preprint arXiv:2307.04787, 2023
-
[22]
Max Ku, Cong Wei, Weiming Ren, Harry Yang, and Wenhu Chen. Anyv2v: A tuning-free framework for any video-to-video editing tasks.arXiv preprint arXiv:2403.14468, 2024
-
[23]
Yijun Li, Chen Fang, Jimei Yang, Zhaowen Wang, Xin Lu, and Ming-Hsuan Yang. Universal style transfer via feature transforms.Advances in neural information processing systems, 30, 2017
work page 2017
-
[24]
Omnihuman-1: Rethinking the scaling-up of one-stage conditioned human animation models
Gaojie Lin, Jianwen Jiang, Jiaqi Yang, Zerong Zheng, Chao Liang, Yuan Zhang, and Jingtuo Liu. Omnihuman-1: Rethinking the scaling-up of one-stage conditioned human animation models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13847–13858, 2025
work page 2025
-
[25]
Omnirefiner: Reinforcement-guided local diffusion refinement.arXiv preprint arXiv:2511.19990, 2025
Yaoli Liu, Ziheng Ouyang, Shengtao Lou, and Yiren Song. Omnirefiner: Reinforcement-guided local diffusion refinement.arXiv preprint arXiv:2511.19990, 2025
-
[26]
Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation
Yue Ma, Hongyu Liu, Hongfa Wang, Heng Pan, Yingqing He, Junkun Yuan, Ailing Zeng, Chengfei Cai, Heung-Yeung Shum, Wei Liu, et al. Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–12, 2024
work page 2024
-
[27]
Follow-your-click: Open-domain regional image animation via motion prompts
Yue Ma, Yingqing He, Hongfa Wang, Andong Wang, Leqi Shen, Chenyang Qi, Jixuan Ying, Chengfei Cai, Zhifeng Li, Heung-Yeung Shum, et al. Follow-your-click: Open-domain regional image animation via motion prompts. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 6018–6026, 2025. 11
work page 2025
-
[28]
Follow-your-click: Open-domain regional image animation via motion prompts
Yue Ma, Yingqing He, Hongfa Wang, Andong Wang, Leqi Shen, Chenyang Qi, Jixuan Ying, Chengfei Cai, Zhifeng Li, Heung-Yeung Shum, et al. Follow-your-click: Open-domain regional image animation via motion prompts. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 6018–6026, 2025
work page 2025
- [29]
-
[30]
Ziheng Ouyang, Yiren Song, Yaoli Liu, Shihao Zhu, Qibin Hou, Ming-Ming Cheng, and Mike Zheng Shou. The consistency critic: Correcting inconsistencies in generated images via reference-guided attentive alignment.arXiv preprint arXiv:2511.20614, 2025
-
[31]
To create what you tell: Generating videos from captions
Yingwei Pan, Zhaofan Qiu, Ting Yao, Houqiang Li, and Tao Mei. To create what you tell: Generating videos from captions. InProceedings of the 25th ACM international conference on Multimedia, pages 1789–1798, 2017
work page 2017
-
[32]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[33]
Fatezero: Fusing attentions for zero-shot text-based video editing
Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, and Qifeng Chen. Fatezero: Fusing attentions for zero-shot text-based video editing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15932–15942, 2023
work page 2023
-
[34]
Instructvid2vid: Controllable video editing with natural language instructions
Bosheng Qin, Juncheng Li, Siliang Tang, Tat-Seng Chua, and Yueting Zhuang. Instructvid2vid: Controllable video editing with natural language instructions. In2024 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2024
work page 2024
-
[35]
Artistic style transfer for videos
Manuel Ruder, Alexey Dosovitskiy, and Thomas Brox. Artistic style transfer for videos. In German conference on pattern recognition, pages 26–36. Springer, 2016
work page 2016
-
[36]
Introducing runway gen-4, 2025
Runway. Introducing runway gen-4, 2025. URL https://runwayml.com/research/ introducing-runway-gen-4
work page 2025
-
[37]
Peter Schaldenbrand, Zhixuan Liu, and Jean Oh. Styleclipdraw: Coupling content and style in text-to-drawing translation.arXiv preprint arXiv:2202.12362, 2022
-
[38]
Neural style transfer via meta networks
Falong Shen, Shuicheng Yan, and Gang Zeng. Neural style transfer via meta networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8061–8069, 2018
work page 2018
-
[39]
Worldwander: Bridging egocentric and exocentric worlds in video generation,
Quanjian Song, Yiren Song, Kelly Peng, Yuan Gao, and Mike Zheng Shou. Worldwander: Bridg- ing egocentric and exocentric worlds in video generation.arXiv preprint arXiv:2511.22098, 2025
-
[40]
Cliptexture: Text-driven texture synthesis
Yiren Song. Cliptexture: Text-driven texture synthesis. InProceedings of the 30th ACM International Conference on Multimedia, pages 5468–5476, 2022
work page 2022
-
[41]
Clipfont: Text guided vector wordart generation
Yiren Song and Yuxuan Zhang. Clipfont: Text guided vector wordart generation. InBMVC, page 543, 2022
work page 2022
-
[42]
Clipvg: Text-guided image manipulation using differentiable vector graphics
Yiren Song, Xuning Shao, Kang Chen, Weidong Zhang, Zhongliang Jing, and Minzhe Li. Clipvg: Text-guided image manipulation using differentiable vector graphics. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 2312–2320, 2023
work page 2023
-
[43]
Processpainter: Learn painting process from sequence data.arXiv preprint arXiv:2406.06062, 2024
Yiren Song, Shijie Huang, Chen Yao, Xiaojun Ye, Hai Ci, Jiaming Liu, Yuxuan Zhang, and Mike Zheng Shou. Processpainter: Learn painting process from sequence data.arXiv preprint arXiv:2406.06062, 2024
-
[44]
Makeanything: Harnessing diffusion transformers for multi-domain procedural sequence generation,
Yiren Song, Cheng Liu, and Mike Zheng Shou. Makeanything: Harnessing diffusion trans- formers for multi-domain procedural sequence generation.arXiv preprint arXiv:2502.01572, 2025
-
[45]
Yiren Song, Cheng Liu, and Mike Zheng Shou. Omniconsistency: Learning style-agnostic consistency from paired stylization data.arXiv preprint arXiv:2505.18445, 2025. 12
-
[46]
Kling Team, Jialu Chen, Yuanzheng Ci, Xiangyu Du, Zipeng Feng, Kun Gai, Sainan Guo, Feng Han, Jingbin He, Kang He, et al. Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alab- dulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
arXiv preprint arXiv:2404.02733 , year=
Haofan Wang, Matteo Spinelli, Qixun Wang, Xu Bai, Zekui Qin, and Anthony Chen. In- stantstyle: Free lunch towards style-preserving in text-to-image generation.arXiv preprint arXiv:2404.02733, 2024
-
[50]
InstantID: Zero-shot Identity-Preserving Generation in Seconds
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, Anthony Chen, Huaxia Li, Xu Tang, and Yao Hu. Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Consistent video style transfer via compound regularization
Wenjing Wang, Jizheng Xu, Li Zhang, Yue Wang, and Jiaying Liu. Consistent video style transfer via compound regularization. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 12233–12240, 2020
work page 2020
-
[52]
Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Jiuniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jingren Zhou. Videocomposer: Compositional video synthesis with motion controllability.Advances in Neural Information Processing Systems, 36:7594–7611, 2023
work page 2023
-
[53]
Styleadapter: A unified stylized image generation model.arXiv preprint arXiv:2309.01770, 2023
Zhouxia Wang, Xintao Wang, Liangbin Xie, Zhongang Qi, Ying Shan, Wenping Wang, and Ping Luo. Styleadapter: A unified stylized image generation model.arXiv preprint arXiv:2309.01770, 2023
-
[54]
Magicanimate: Temporally consistent human image animation using diffusion model
Zhongcong Xu, Jianfeng Zhang, Jun Hao Liew, Hanshu Yan, Jia-Wei Liu, Chenxu Zhang, Jiashi Feng, and Mike Zheng Shou. Magicanimate: Temporally consistent human image animation using diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1481–1490, 2024
work page 2024
-
[55]
Zexuan Yan, Yue Ma, Chang Zou, Wenteng Chen, Qifeng Chen, and Linfeng Zhang. Eedit: Rethinking the spatial and temporal redundancy for efficient image editing.arXiv preprint arXiv:2503.10270, 2025
-
[56]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Stylemas- ter: Stylize your video with artistic generation and translation
Zixuan Ye, Huijuan Huang, Xintao Wang, Pengfei Wan, Di Zhang, and Wenhan Luo. Stylemas- ter: Stylize your video with artistic generation and translation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2630–2640, 2025
work page 2025
-
[58]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
work page 2023
-
[59]
Controlvideo: Training-free controllable text-to-video generation
Yabo Zhang, Yuxiang Wei, XIAOPENG ZHANG, Wangmeng Zuo, Qi Tian, et al. Controlvideo: Training-free controllable text-to-video generation. InInternational Conference on Learning Representations, volume 2024, pages 54441–54461, 2024
work page 2024
-
[60]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404, 2024. 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.