From a Single Demonstration to a General Policy for Contact-Rich Manipulation
Pith reviewed 2026-05-20 12:11 UTC · model grok-4.3
The pith
Environmental constraints let a robot turn one demonstration into a policy that generalizes across object poses and contact variations in multi-stage tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing a demonstration as a sequence of behaviors that exploit environmental constraints, the robot separates task-general structure—the constraint types and their transitions—from instance-specific details such as exact trajectories, poses, and local geometries. The four-stage pipeline first abstracts the demonstration into environmental-constraint primitives, then disambiguates them through self-guided exploration, assimilates human corrections for out-of-distribution cases, and finally recovers abstracted details online through compliant interaction. Because the resulting policy follows constraints rather than mimics trajectories, it generalizes across object poses, local geometr
What carries the argument
Environmental-constraint primitives: a sequence of constraint types and transitions extracted from the demonstration that encode the task-general structure while discarding instance-specific trajectory details.
If this is right
- The policy succeeds on new object poses and local geometries without retraining because it follows constraints rather than exact paths.
- Unmodeled contact dynamics are tolerated because the policy relies on compliant interaction instead of precise trajectory replay.
- The same framework applies across seven distinct real-world multi-stage tasks with over 90 percent success.
- Task-general structure is isolated from instance-specific details, reducing the need for task-specific modeling.
Where Pith is reading between the lines
- The approach may reduce the number of human demonstrations required for new contact-rich tasks by shifting effort to online correction and exploration.
- It could extend to tasks with greater variability if the constraint primitive vocabulary is expanded beyond the current set.
- Integration with vision or tactile sensing might automate the abstraction stage more reliably for unseen geometries.
Load-bearing premise
A single demonstration can be reliably turned into a sequence of environmental-constraint primitives whose types and transitions contain all task-general structure, so that later exploration and corrections can handle remaining variations.
What would settle it
A new multi-stage contact task where the initial abstraction from the single demonstration produces incorrect constraint types or transitions, causing the policy to fail even after exploration and corrections.
Figures















read the original abstract
We present a Learning from Demonstration (LfD) framework that achieves one-shot generalization in multi-stage, contact-rich manipulation tasks. Central to our approach is the utilization of environmental constraints as the inductive bias. By representing a demonstration as a sequence of behaviors that exploit environmental constraints, the robot separates task-general structure -- the constraint types and their transitions -- from instance-specific details such as exact demonstration trajectories, poses, and local geometries. Our four-stage pipeline builds a complete policy on this representation: the robot first abstracts a single demonstration into environmental-constraint primitives, then disambiguates them through self-guided exploration, next assimilates targeted human corrections that handle out-of-distribution variations, and finally recovers the abstracted-away details online through compliant interaction. Because the resulting policy follows constraints rather than mimics trajectories, it generalizes across object poses, local geometries, and unmodeled contact dynamics. We validate our approach on seven real-world multi-stage contact-rich manipulation tasks and achieve over 90% success. These extensive experimental results establish environmental constraints as fundamental building blocks for efficient generalization in learning from demonstration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a Learning from Demonstration (LfD) framework for one-shot generalization in multi-stage, contact-rich manipulation tasks. It represents a single demonstration as a sequence of environmental-constraint primitives to separate task-general structure (constraint types and transitions) from instance-specific details (trajectories, poses, geometries). A four-stage pipeline follows: abstraction into primitives, self-guided exploration for disambiguation, assimilation of targeted human corrections, and online recovery of details via compliant interaction. The resulting policy is claimed to generalize across object poses, local geometries, and unmodeled contact dynamics. Validation is reported on seven real-world tasks with over 90% success.
Significance. If the central claims hold, the work would be significant for LfD in robotics by demonstrating that environmental constraints can serve as an effective inductive bias for generalization from a single demonstration, reducing reliance on trajectory imitation or extensive task-specific modeling. The real-world experimental scope across seven multi-stage tasks is a positive aspect that could support practical adoption if the generalization mechanism is rigorously validated.
major comments (2)
- [Abstract / Pipeline Description] The generalization argument rests on the first stage successfully abstracting a single demonstration into a sequence of constraint primitives whose types and transitions capture all task-general structure (see Abstract and pipeline description). The manuscript provides no analysis or experiments demonstrating that this abstraction step is invariant to the choice of demonstration trajectory or local geometry; if instance-specific details leak into the primitive sequence, later stages of exploration and correction cannot remain free of task-specific modeling, undermining the claims of generalization across poses, geometries, and unmodeled dynamics.
- [Experimental Validation] The experimental results claim over 90% success on seven tasks (Abstract), yet the provided description includes no details on task definitions, failure modes, statistical tests, controls, or how success was measured across variations in object poses and geometries. Without these, it is not possible to evaluate whether the data support the one-shot generalization claim or to rule out that performance depends on particular demonstration choices.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly listed the types of environmental constraints or the specific manipulation tasks used, to help readers assess the scope of the claimed generalization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of the abstraction process and experimental details.
read point-by-point responses
-
Referee: [Abstract / Pipeline Description] The generalization argument rests on the first stage successfully abstracting a single demonstration into a sequence of constraint primitives whose types and transitions capture all task-general structure (see Abstract and pipeline description). The manuscript provides no analysis or experiments demonstrating that this abstraction step is invariant to the choice of demonstration trajectory or local geometry; if instance-specific details leak into the primitive sequence, later stages of exploration and correction cannot remain free of task-specific modeling, undermining the claims of generalization across poses, geometries, and unmodeled dynamics.
Authors: We agree that explicit validation of the abstraction step's invariance is important for supporting the generalization claims. The abstraction is defined to extract only constraint types and transition sequences while discarding instance-specific trajectory and geometry details, but the current manuscript does not include dedicated analysis or multi-demonstration experiments to demonstrate this property. In the revised version we will add a new subsection with theoretical justification based on the constraint representation and empirical results applying the abstraction to multiple demonstrations per task with varied trajectories and local geometries, confirming that the resulting primitive sequences remain consistent. revision: yes
-
Referee: [Experimental Validation] The experimental results claim over 90% success on seven tasks (Abstract), yet the provided description includes no details on task definitions, failure modes, statistical tests, controls, or how success was measured across variations in object poses and geometries. Without these, it is not possible to evaluate whether the data support the one-shot generalization claim or to rule out that performance depends on particular demonstration choices.
Authors: We acknowledge that the experimental section requires more detailed reporting to allow full evaluation of the results. While the manuscript describes the seven tasks at a high level and reports aggregate success rates, it does not provide the requested specifics on definitions, variations, failure modes, measurement criteria, or statistical analysis. In the revision we will substantially expand the experimental evaluation to include explicit task definitions, the ranges of pose and geometry variations tested, per-task success rates with breakdowns, observed failure modes and their frequencies, precise success criteria for each stage, and statistical measures such as standard deviations across trials. This will better substantiate the one-shot generalization performance. revision: yes
Circularity Check
No circularity: forward pipeline from demonstration to constraint-based policy remains self-contained
full rationale
The paper presents a four-stage pipeline that begins with abstracting a single demonstration into environmental-constraint primitives, followed by exploration, human corrections, and online recovery of details. Generalization is claimed to arise because the policy follows constraints rather than mimicking trajectories, with validation on seven real-world tasks. No equations, fitted parameters, or self-citations are exhibited that reduce any claimed prediction or uniqueness result back to the input demonstration by construction. The separation of task-general structure from instance-specific details is treated as an empirical outcome of the abstraction step rather than a definitional equivalence, leaving the derivation chain independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A demonstration can be represented as a sequence of behaviors that exploit environmental constraints, separating task-general structure from instance-specific details.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
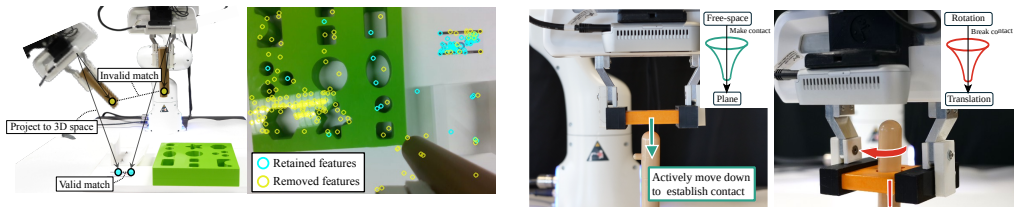
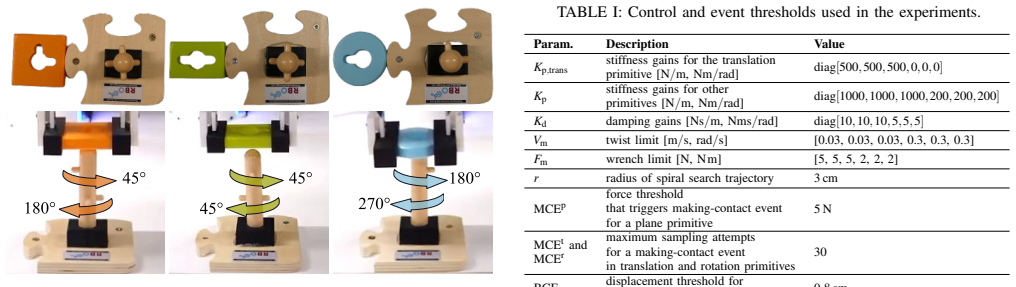
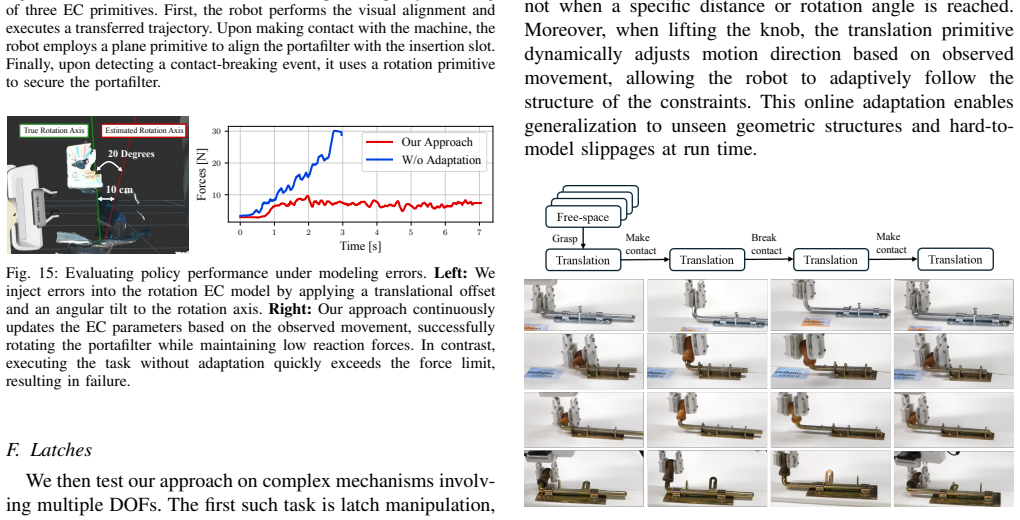
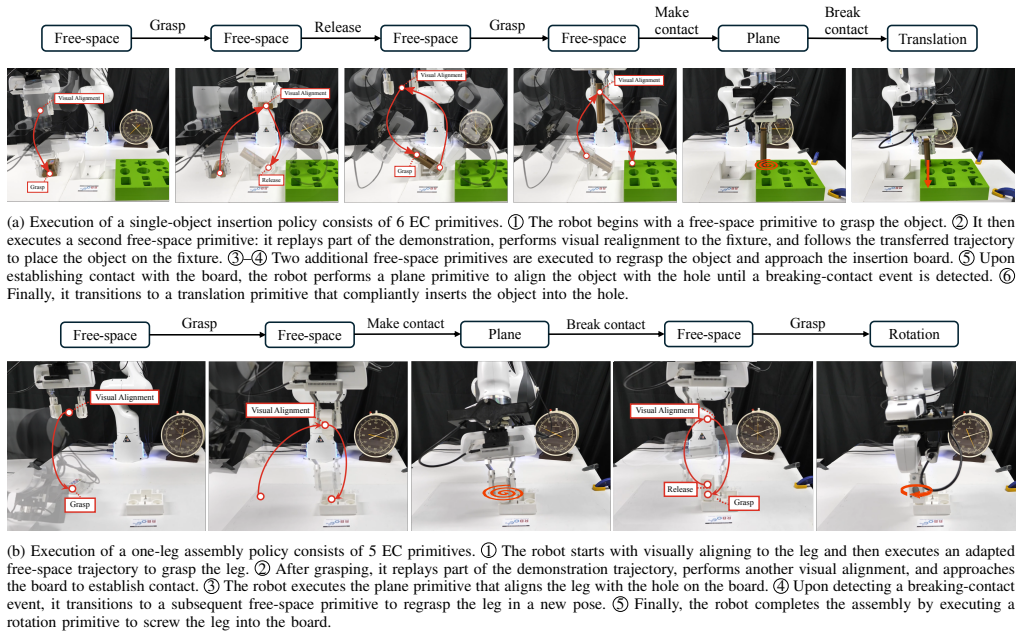
We model these transitions between EC primitives as discrete events, including contact-making, contact-breaking, and gripper events
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Survey: Robot programming by demonstration,
A. Billard, S. Calinon, R. Dillmann, and S. Schaal, “Survey: Robot programming by demonstration,”Springer Handbook of Robotics, pp. 1371–1394, 2008
work page 2008
-
[2]
Exploitation of environmental constraints in human and robotic grasping,
C. Eppner, R. Deimel, J. Alvarez-Ruiz, M. Maertens, and O. Brock, “Exploitation of environmental constraints in human and robotic grasping,”The International Journal of Robotics Research, vol. 34, no. 7, pp. 1021–1038, 2015
work page 2015
-
[3]
Human- inspired force compliant grasping primitives,
M. Kazemi, J.-S. Valois, J. A. Bagnell, and N. Pollard, “Human- inspired force compliant grasping primitives,”Autonomous Robots, vol. 37, pp. 209–225, 2014
work page 2014
-
[4]
Experimental analysis of human control strategies in contact manipulation tasks,
E. Klingbeil, S. Menon, and O. Khatib, “Experimental analysis of human control strategies in contact manipulation tasks,” inInterna- tional Symposium on Experimental Robotics. Springer, 2017, pp. 275–286
work page 2017
-
[5]
Automatic syn- thesis of fine-motion strategies for robots,
T. Lozano-P ´erez, M. T. Mason, and R. H. Taylor, “Automatic syn- thesis of fine-motion strategies for robots,”The International Journal of Robotics Research, vol. 3, no. 1, pp. 3–24, 1984
work page 1984
-
[6]
Planning grasp strategies that exploit environmental constraints,
C. Eppner and O. Brock, “Planning grasp strategies that exploit environmental constraints,” inIEEE International Conference on Robotics and Automation (ICRA), 2015, pp. 4947–4952
work page 2015
-
[7]
M. Bonilla, E. Farnioli, C. Piazza, M. Catalano, G. Grioli, M. Gara- bini, M. Gabiccini, and A. Bicchi, “Grasping with soft hands,” in IEEE-RAS International Conference on Humanoid Robots, 2014, pp. 581–587
work page 2014
-
[8]
Exploiting robot hand compliance and environmental constraints for edge grasps,
J. Bimbo, E. Turco, M. Ghazaei Ardakani, M. Pozzi, G. Salvietti, V . Bo, M. Malvezzi, and D. Prattichizzo, “Exploiting robot hand compliance and environmental constraints for edge grasps,”Frontiers in Robotics and AI, vol. 6, p. 135, 2019
work page 2019
-
[9]
Analysis of open-loop grasping from piles,
E. P ´all and O. Brock, “Analysis of open-loop grasping from piles,” in IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 2591–2597
work page 2021
-
[10]
Interleaving Motion in Contact and in Free Space for Planning Under Uncer- tainty,
A. Sieverling, C. Eppner, F. Wolff, and O. Brock, “Interleaving Motion in Contact and in Free Space for Planning Under Uncer- tainty,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017, pp. 4011–4017
work page 2017
-
[11]
Dual execution of optimized contact interaction trajec- tories,
M. Toussaint, N. Ratliff, J. Bohg, L. Righetti, P. Englert, and S. Schaal, “Dual execution of optimized contact interaction trajec- tories,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2014, pp. 47–54
work page 2014
-
[12]
Differentiable physics and stable modes for tool-use and manipula- tion planning,
M. A. Toussaint, K. R. Allen, K. A. Smith, and J. B. Tenenbaum, “Differentiable physics and stable modes for tool-use and manipula- tion planning,” inRobotics: Science and Systems (RSS), 2018
work page 2018
-
[13]
Learning reusable manipulation strategies,
J. Mao, T. Lozano-P ´erez, J. B. Tenenbaum, and L. P. Kaelbling, “Learning reusable manipulation strategies,” inConference on Robot Learning (CoRL). PMLR, 2023, pp. 1467–1483
work page 2023
-
[14]
Automated co- design of soft hand morphology and control strategy for grasping,
R. Deimel, P. Irmisch, V . Wall, and O. Brock, “Automated co- design of soft hand morphology and control strategy for grasping,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017, pp. 1213–1218
work page 2017
-
[15]
Co-designing manipulation systems using task-relevant constraints,
A. Vaish and O. Brock, “Co-designing manipulation systems using task-relevant constraints,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 4177–4183
work page 2024
-
[16]
Adaptive synergies for the design and control of the pisa/iit softhand,
M. G. Catalano, G. Grioli, E. Farnioli, A. Serio, C. Piazza, and A. Bicchi, “Adaptive synergies for the design and control of the pisa/iit softhand,”The International Journal of Robotics Research, vol. 33, no. 5, pp. 768–782, 2014
work page 2014
-
[17]
A compliant, underactuated hand for robust manipulation,
L. U. Odhner, L. P. Jentoft, M. R. Claffee, N. Corson, Y . Tenzer, R. R. Ma, M. Buehler, R. Kohout, R. D. Howe, and A. M. Dollar, “A compliant, underactuated hand for robust manipulation,”The International Journal of Robotics Research, vol. 33, no. 5, pp. 736– 752, 2014
work page 2014
-
[18]
A novel type of compliant and underactu- ated robotic hand for dexterous grasping,
R. Deimel and O. Brock, “A novel type of compliant and underactu- ated robotic hand for dexterous grasping,”The International Journal of Robotics Research, vol. 35, no. 1-3, pp. 161–185, 2016
work page 2016
-
[19]
Rbo hand 3: A platform for soft dexterous manipulation,
S. Puhlmann, J. Harris, and O. Brock, “Rbo hand 3: A platform for soft dexterous manipulation,”IEEE Transactions on Robotics, vol. 38, no. 6, pp. 3434–3449, 2022
work page 2022
-
[20]
An exploration of sensorless manipulation,
M. A. Erdmann and M. T. Mason, “An exploration of sensorless manipulation,”IEEE Journal on Robotics and Automation, vol. 4, no. 4, pp. 369–379, 2002
work page 2002
-
[21]
Manipulation with shared grasping,
Y . Hou, Z. Jia, and M. Mason, “Manipulation with shared grasping,” inRobotics: Science and Systems, 2020
work page 2020
-
[22]
Collision-inclusive manipulation planning for occluded object grasping via compliant robot motions,
K. Ren, G. Wang, A. S. Morgan, and K. Hang, “Collision-inclusive manipulation planning for occluded object grasping via compliant robot motions,”arXiv preprint arXiv:2412.06983, 2024
-
[23]
Extrinsic dexterity: In-hand manipulation with external forces,
N. C. Dafle, A. Rodriguez, R. Paolini, B. Tang, S. S. Srinivasa, M. Erdmann, M. T. Mason, I. Lundberg, H. Staab, and T. Fuhlbrigge, “Extrinsic dexterity: In-hand manipulation with external forces,” in IEEE International Conference on Robotics and Automation (ICRA), 2014, pp. 1578–1585
work page 2014
-
[24]
Surprisingly robust in-hand manipulation: An empirical study,
A. Bhatt, A. Sieler, S. Puhlmann, and O. Brock, “Surprisingly robust in-hand manipulation: An empirical study,”Robotics: Science and Systems (RSS), 2021
work page 2021
-
[25]
In-hand cube reconfiguration: Simplified,
S. Patidar, A. Sieler, and O. Brock, “In-hand cube reconfiguration: Simplified,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023, pp. 8751–8756
work page 2023
-
[26]
RT-1: Robotics transformer for real-world control at scale,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu,et al., “RT-1: Robotics transformer for real-world control at scale,” inRobotics: Science and Systems (RSS), 2023
work page 2023
-
[27]
RT-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid,et al., “RT-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning (CoRL). PMLR, 2023, pp. 2165–2183
work page 2023
-
[28]
Open X-Embodiment: Robotic learning datasets and RT-X models: Open X-Embodiment collaboration,
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain,et al., “Open X-Embodiment: Robotic learning datasets and RT-X models: Open X-Embodiment collaboration,” inIEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 6892–6903
work page 2024
-
[29]
Droid: A large-scale in-the-wild robot manipulation dataset,
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al., “Droid: A large-scale in-the-wild robot manipulation dataset,” inRobotics: Science and Systems (RSS), 2024
work page 2024
-
[30]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang,et al., “Gr00t n1: An open foundation model for generalist humanoid robots,”arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Gemini Robotics: Bringing AI into the Physical World
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakrishna, R. Baruch, M. Bauza, M. Blokzijl, et al., “Gemini robotics: Bringing ai into the physical world,”arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation
T. L. Team, “A careful examination of large behavior models for multitask dexterous manipulation,”arXiv preprint arXiv:2507.05331, 2025
work page internal anchor Pith review arXiv 2025
-
[33]
Q. Bu, J. Cai, L. Chen, X. Cui, Y . Ding, S. Feng, S. Gao, X. He, X. Hu, X. Huang,et al., “Agibot world colosseo: A large-scale ma- nipulation platform for scalable and intelligent embodied systems,” arXiv preprint arXiv:2503.06669, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Useek: Unsupervised se (3)-equivariant 3d keypoints for generalizable ma- nipulation,
Z. Xue, Z. Yuan, J. Wang, X. Wang, Y . Gao, and H. Xu, “Useek: Unsupervised se (3)-equivariant 3d keypoints for generalizable ma- nipulation,”arXiv preprint arXiv:2209.13864, 2022
-
[35]
Visual imitation learning of task-oriented object grasping and rearrangement,
Y . Cai, J. Gao, C. Pohl, and T. Asfour, “Visual imitation learning of task-oriented object grasping and rearrangement,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024, pp. 364–371
work page 2024
-
[36]
Dinobot: Robot manipulation via retrieval and alignment with vision foundation models,
N. Di Palo and E. Johns, “Dinobot: Robot manipulation via retrieval and alignment with vision foundation models,” inIEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 2798– 2805
work page 2024
-
[37]
Hrt1: One-shot human-to-robot trajectory transfer for mobile ma- nipulation,
S. H. Allu, N. Khargonkar, T. Summers, J. Yao, Y . Xiang,et al., “Hrt1: One-shot human-to-robot trajectory transfer for mobile ma- nipulation,”arXiv preprint arXiv:2510.21026, 2025
-
[38]
Y . Ding, S. Wang, and T. Fitzgerald, “Tref-6: Inferring task-relevant frames from a single demonstration for one-shot skill generalization,” arXiv preprint arXiv:2509.00310, 2025
-
[39]
A backbone for long-horizon robot task understanding,
X. Chen, W. Chen, D. Lee, Y . Ge, N. Rojas, and P. Kormushev, “A backbone for long-horizon robot task understanding,”IEEE Robotics and Automation Letters, 2025
work page 2025
-
[40]
Annotation-free one-shot imitation learning for multi-step manip- ulation tasks,
V . Wichitwechkarn, E. Williams, C. Fox, and R. Choudhary, “Annotation-free one-shot imitation learning for multi-step manip- ulation tasks,”arXiv preprint arXiv:2509.24972, 2025
-
[41]
Functo: Function-centric one-shot imitation learning for tool manipulation,
C. Tang, A. Xiao, Y . Deng, T. Hu, W. Dong, H. Zhang, D. Hsu, and H. Zhang, “Functo: Function-centric one-shot imitation learning for tool manipulation,”arXiv preprint arXiv:2502.11744, 2025
-
[42]
M. A. Lee, C. Florensa, J. Tremblay, N. Ratliff, A. Garg, F. Ramos, and D. Fox, “Guided uncertainty-aware policy optimization: Combin- ing learning and model-based strategies for sample-efficient policy learning,” inIEEE international conference on robotics and automa- tion (ICRA), 2020, pp. 7505–7512
work page 2020
-
[43]
One-shot imitation learning: A pose estimation perspective,
P. Vitiello, K. Dreczkowski, and E. Johns, “One-shot imitation learning: A pose estimation perspective,” inConference on Robot Learning (CoRL). PMLR, 2023, pp. 943–970
work page 2023
-
[44]
Ditto: Demonstration imitation by trajectory transformation,
N. Heppert, M. Argus, T. Welschehold, T. Brox, and A. Valada, “Ditto: Demonstration imitation by trajectory transformation,” in IEEE/RSJ International Conference on Intelligent Robots and Sys- tems (IROS), 2024, pp. 7565–7572
work page 2024
-
[45]
Learning a thousand tasks in a day,
K. Dreczkowski, P. Vitiello, V . V osylius, and E. Johns, “Learning a thousand tasks in a day,”Science Robotics, vol. 10, no. 108, p. eadv7594, 2025
work page 2025
-
[46]
J. Felip, J. Laaksonen, A. Morales, and V . Kyrki, “Manipulation primitives: A paradigm for abstraction and execution of grasping and manipulation tasks,”Robotics and Autonomous Systems, vol. 61, no. 3, pp. 283–296, 2013
work page 2013
-
[47]
A review of robot learn- ing for manipulation: Challenges, representations, and algorithms,
O. Kroemer, S. Niekum, and G. Konidaris, “A review of robot learn- ing for manipulation: Challenges, representations, and algorithms,” Journal of Machine Learning Research, vol. 22, no. 30, pp. 1–82, 2021
work page 2021
-
[48]
Acquiring robust, force-based assembly skills from human demonstration,
M. Skubic and R. A. V olz, “Acquiring robust, force-based assembly skills from human demonstration,”IEEE Transactions on Robotics and Automation, vol. 16, no. 6, pp. 772–781, 2000
work page 2000
-
[49]
Imitation learning- based framework for learning 6-d linear compliant motions,
M. Suomalainen, F. J. Abu-Dakka, and V . Kyrki, “Imitation learning- based framework for learning 6-d linear compliant motions,”Au- tonomous Robots, vol. 45, no. 3, pp. 389–405, 2021
work page 2021
-
[50]
Robot learning from demon- stration for assembly with sequential assembly movement primitives,
H. Hu, H. Yan, X. Yang, and Y . Lou, “Robot learning from demon- stration for assembly with sequential assembly movement primitives,” IEEE/ASME Transactions on Mechatronics, 2023
work page 2023
-
[51]
One- shot transfer of long-horizon extrinsic manipulation through contact retargeting,
A. Wu, R. Wang, S. Chen, C. Eppner, and C. K. Liu, “One- shot transfer of long-horizon extrinsic manipulation through contact retargeting,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024, pp. 13 891–13 898
work page 2024
-
[52]
Robot learning of everyday object manipulations via human demonstration,
H. Dang and P. K. Allen, “Robot learning of everyday object manipulations via human demonstration,” inIEEE/RSJ International Conference on Intelligent Robots and Systems, 2010, pp. 1284–1289
work page 2010
-
[53]
Online bayesian changepoint detection for articulated motion models,
S. Niekum, S. Osentoski, C. G. Atkeson, and A. G. Barto, “Online bayesian changepoint detection for articulated motion models,” in IEEE international conference on robotics and automation (ICRA), 2015, pp. 1468–1475
work page 2015
-
[54]
C. P ´erez-D’Arpino and J. A. Shah, “C-learn: Learning geometric constraints from demonstrations for multi-step manipulation in shared autonomy,” inIEEE International Conference on Robotics and Au- tomation (ICRA), 2017, pp. 4058–4065
work page 2017
-
[55]
Learning articulated constraints from a one-shot demonstration for robot manipulation planning,
Y . Liu, F. Zha, L. Sun, J. Li, M. Li, and X. Wang, “Learning articulated constraints from a one-shot demonstration for robot manipulation planning,”IEEE Access, vol. 7, pp. 172 584–172 596, 2019
work page 2019
-
[56]
Learning hybrid object kinematics for efficient hierarchical planning under uncertainty,
A. Jain and S. Niekum, “Learning hybrid object kinematics for efficient hierarchical planning under uncertainty,” inIEEE/RSJ In- ternational Conference on Intelligent Robots and Systems (IROS), 2020, pp. 5253–5260
work page 2020
-
[57]
Inferring geometric con- straints in human demonstrations,
G. Subramani, M. Zinn, and M. Gleicher, “Inferring geometric con- straints in human demonstrations,” inConference on Robot Learning (CoRL). PMLR, 2018, pp. 223–236
work page 2018
-
[58]
N. Wake, R. Arakawa, I. Yanokura, T. Kiyokawa, K. Sasabuchi, J. Takamatsu, and K. Ikeuchi, “A learning-from-observation frame- work: One-shot robot teaching for grasp-manipulation-release house- hold operations,” inIEEE/SICE International Symposium on System Integration (SII), 2021, pp. 461–466
work page 2021
-
[59]
Learning from demonstration based on environ- mental constraints,
X. Li and O. Brock, “Learning from demonstration based on environ- mental constraints,”IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 10 938–10 945, 2022
work page 2022
-
[60]
Teaching contact- rich tasks from visual demonstrations by constraint extraction,
C. Hegeler, F. Rozzi, L. Roveda, and K. Haninger, “Teaching contact- rich tasks from visual demonstrations by constraint extraction,”arXiv preprint arXiv:2303.17481, 2023
-
[61]
K-VIL: Keypoints-based visual imitation learning,
J. Gao, Z. Tao, N. Jaquier, and T. Asfour, “K-VIL: Keypoints-based visual imitation learning,”IEEE Transactions on Robotics, pp. 1–21, 2023
work page 2023
-
[62]
A helping (human) hand in kinematic structure estimation,
A. Pfisterer, X. Li, V . Mengers, and O. Brock, “A helping (human) hand in kinematic structure estimation,” inIEEE International Con- ference on Robotics and Automation (ICRA), 2025
work page 2025
-
[63]
A. M. Mohammadi, M. V ochten, E. Aertbeli ¨en, and J. De Schutter, “A generic task model and control strategy to support learning, robust control, and generalization of contact-rich manipulation tasks,” Robotics and Autonomous Systems, p. 105270, 2025
work page 2025
-
[64]
Versatile kinematics-based constraint identification applied to robot task reproduction,
A. H. Overbeek, D. Dresscher, H. van der Kooij, and M. Vlutters, “Versatile kinematics-based constraint identification applied to robot task reproduction,”Frontiers in robotics and AI, 2025
work page 2025
-
[65]
A. H. G.-J. Overbeek, H. van der Kooij, D. Dresscher, and M. Vlut- ters, “Identifying physical interactions in contact-based robot ma- nipulation for learning from demonstration,”Advanced Robotics Research, p. e202500109, 2025
work page 2025
-
[66]
X. Li, M. Baum, and O. Brock, “Augmentation enables one-shot generalization in learning from demonstration for contact-rich manip- ulation,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023, pp. 3656–3663
work page 2023
-
[67]
A survey of robot manipulation in contact,
M. Suomalainen, Y . Karayiannidis, and V . Kyrki, “A survey of robot manipulation in contact,”Robotics and Autonomous Systems, vol. 156, p. 104224, 2022
work page 2022
-
[68]
Active articulation model estimation through interactive perception,
K. Hausman, S. Niekum, S. Osentoski, and G. S. Sukhatme, “Active articulation model estimation through interactive perception,” inIEEE International Conference on Robotics and Automation (ICRA), 2015, pp. 3305–3312
work page 2015
-
[69]
Kinematics-based estimation of contact constraints using only proprioception,
V . Ortenzi, H.-C. Lin, M. Azad, R. Stolkin, J. A. Kuo, and M. Mis- try, “Kinematics-based estimation of contact constraints using only proprioception,” inIEEE-RAS 16th International Conference on Humanoid Robots (Humanoids), 2016, pp. 1304–1311
work page 2016
-
[70]
Contact surface estimation via haptic perception,
H.-C. Lin and M. Mistry, “Contact surface estimation via haptic perception,” inIEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 5087–5093
work page 2020
-
[71]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” in Proceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Pro- ceedings, 2011, pp. 627–635
work page 2011
-
[72]
Interactive imitation learning in robotics: A survey,
C. Celemin, R. P ´erez-Dattari, E. Chisari, G. Franzese, L. de Souza Rosa, R. Prakash, Z. Ajanovi ´c, M. Ferraz, A. Valada, J. Kober,et al., “Interactive imitation learning in robotics: A survey,” Foundations and Trends® in Robotics, vol. 10, no. 1-2, pp. 1–197, 2022
work page 2022
-
[73]
Learning of exception strategies in assembly tasks,
B. Nemec, M. Simoni ˇc, and A. Ude, “Learning of exception strategies in assembly tasks,” inIEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 6521–6527
work page 2020
-
[74]
Motion generation based on contact state estimation using two-stage clustering,
K. Takeuchi, S. Sakaino, and T. Tsuji, “Motion generation based on contact state estimation using two-stage clustering,”IEEJ Journal of Industry Applications, p. 22012635, 2023
work page 2023
-
[75]
Model-based runtime monitoring with interactive imitation learning,
H. Liu, S. Dass, R. Mart ´ın-Mart´ın, and Y . Zhu, “Model-based runtime monitoring with interactive imitation learning,” inIEEE International Conference on Robotics and Automation (ICRA), 2024
work page 2024
-
[76]
Ilesia: Interactive learning of robot situa- tional awareness from camera input,
P. Vanc, G. Franzese, J. K. Behrens, C. Della Santina, K. Stepanova, J. Kober, and R. Babuska, “Ilesia: Interactive learning of robot situa- tional awareness from camera input,”IEEE Robotics and Automation Letters, 2025
work page 2025
-
[77]
Data-driven online decision making for autonomous manipulation,
D. Kappler, P. Pastor, M. Kalakrishnan, M. W ¨uthrich, and S. Schaal, “Data-driven online decision making for autonomous manipulation,” inRobotics: Science and Systems (RSS), vol. 11, 2015
work page 2015
-
[78]
Learning grounded finite-state representations from unstructured demonstrations,
S. Niekum, S. Osentoski, G. Konidaris, S. Chitta, B. Marthi, and A. G. Barto, “Learning grounded finite-state representations from unstructured demonstrations,”The International Journal of Robotics Research, vol. 34, no. 2, pp. 131–157, 2015
work page 2015
-
[79]
Sc-airl: Share-critic in adversarial inverse reinforcement learning for long-horizon task,
G. Xiang, S. Li, F. Shuang, F. Gao, and X. Yuan, “Sc-airl: Share-critic in adversarial inverse reinforcement learning for long-horizon task,” IEEE Robotics and Automation Letters, vol. 9, no. 4, pp. 3179–3186, 2024
work page 2024
-
[80]
The need for biases in learning generalizations (technical report no. cbm-tr-117),
T. M. Mitchell, “The need for biases in learning generalizations (technical report no. cbm-tr-117),”New Brunswick, New Jersey: Department of Computer Science, Rutgers University, 1980
work page 1980
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.