Beyond Transcripts: Iterative Peer-Editing with Audio Unlocks High-Quality Human Summaries of Conversational Speech
Pith reviewed 2026-05-20 12:31 UTC · model grok-4.3
The pith
Iterative peer-editing with audio makes human speech summaries as informative as transcript or LLM versions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Audio-based summaries are initially less informative and more compressed than transcript summaries, but iterative peer-editing with audio mitigates this difference and enables audio-based summaries to be as informative as their transcript counterparts and LLM summaries.
What carries the argument
Iterative peer-editing workflow applied to audio input, in which annotators review and refine each other's summaries while listening to the original recording.
Load-bearing premise
The chosen informativeness and compression metrics accurately and unbiasedly capture summary quality no matter which input modality or editing process produced the summary.
What would settle it
An independent human rating study in which judges evaluate summary usefulness for understanding the full conversation without knowing how each summary was created and find that edited audio versions still score lower on key aspects.
Figures






read the original abstract
There are not enough established benchmarks for the task fo speech summarization. Creating new benchmarks demands human annotation, as LLMs could embed systemic errors and bias into datasets. We test ten annotation workflows varying input modality (audio, transcript, or both) and the inclusion of editing (self or peer-editing) to investigate potential quality tradeoffs from using human annotators to summarize audio. We compare human audio-based summaries to human transcript-based summaries to track the impact of the different information modalities on summary quality. We also compare the human outputs against four LLM benchmarks (three text, one audio) to examine whether human-written summaries are less informative than highly fluent automated outputs. We find that audio-based summaries are less informative and more compressed than transcript summaries. However, iterative peer-editing with audio mitigates this difference, enabling audio-based summaries to be as informative as their transcript counterparts and LLM summaries. These findings validate iterative peer-editing among human annotators for the creation of benchmarks informed by both lexical and prosodic information. This enables crucial dataset collection even in setting where transcripts are unavailable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper examines ten human annotation workflows for conversational speech summarization, varying input modality (audio, transcript, or both) and editing type (self or peer). It reports that audio-based summaries are less informative and more compressed than transcript-based summaries, but that iterative peer-editing with audio access makes audio summaries as informative as transcript ones and LLM summaries. The work concludes that such workflows enable high-quality benchmarks incorporating prosodic information even without transcripts.
Significance. If the empirical results are robust, this would be a significant contribution to speech summarization research by providing evidence-based guidance on human annotation protocols that preserve modality-specific information. It addresses the scarcity of benchmarks for speech summarization and offers a method to avoid biases in LLM-generated data, with potential impact on dataset creation for conversational AI applications.
major comments (2)
- Section 4 (Metric Definitions): The informativeness and compression metrics must explicitly describe whether human raters had equivalent access to the source audio when scoring summaries from all conditions. If evaluations are text-only or insensitive to prosody, the central claim that iterative peer-editing makes audio summaries 'as informative as their transcript counterparts' cannot be attributed to preservation of prosodic cues and risks being an artifact of the evaluation protocol.
- Results section: The manuscript provides no details on the number of annotators, sample sizes per workflow, inter-rater agreement, or statistical tests (e.g., significance of differences in informativeness scores). These omissions are load-bearing because the key finding—that peer-editing mitigates the audio-transcript gap—cannot be verified without evidence that observed differences are reliable rather than due to small-sample variability or bias.
minor comments (2)
- Abstract: Typo 'task fo speech' should be corrected to 'task of speech'.
- The ten workflows would be easier to compare if presented in a single summary table listing modality and editing type for each.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of clarity and rigor in our presentation of the annotation workflows and evaluation. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Section 4 (Metric Definitions): The informativeness and compression metrics must explicitly describe whether human raters had equivalent access to the source audio when scoring summaries from all conditions. If evaluations are text-only or insensitive to prosody, the central claim that iterative peer-editing makes audio summaries 'as informative as their transcript counterparts' cannot be attributed to preservation of prosodic cues and risks being an artifact of the evaluation protocol.
Authors: We agree that explicit description of the evaluation protocol is necessary. In the revised manuscript, Section 4 will be updated to state that informativeness and compression were scored by human raters on the basis of the text summaries alone, without access to the original audio. The summaries were generated by annotators who did have audio access (including prosody) in the relevant conditions, which informed their selection and phrasing of content. We will add a brief discussion noting that while the evaluation itself is text-based, the observed equivalence in informativeness for the iterative peer-editing condition still reflects the benefits of audio-informed annotation; however, we will avoid over-attributing this solely to prosodic preservation in the evaluation step. revision: yes
-
Referee: Results section: The manuscript provides no details on the number of annotators, sample sizes per workflow, inter-rater agreement, or statistical tests (e.g., significance of differences in informativeness scores). These omissions are load-bearing because the key finding—that peer-editing mitigates the audio-transcript gap—cannot be verified without evidence that observed differences are reliable rather than due to small-sample variability or bias.
Authors: We acknowledge the need for these details to support the reliability of the findings. The revised Results section will report the total number of annotators, the number of summaries produced per workflow, inter-rater agreement statistics, and the outcomes of appropriate statistical tests (including p-values for differences in informativeness). These data were recorded during the study and will be added to allow readers to assess the robustness of the peer-editing effect. revision: yes
Circularity Check
No significant circularity in empirical comparative study
full rationale
The paper conducts an empirical evaluation of ten human annotation workflows for speech summarization, varying input modality (audio/transcript/both) and editing type (self/peer). It directly measures summary quality via informativeness and compression metrics on collected outputs, then compares human results to four LLM baselines. No equations, parameter fits, or derivation chains are present. Central claims rest on experimental data collection and human ratings rather than any self-referential prediction or self-citation that reduces to the inputs by construction. The study is self-contained with external benchmarks and falsifiable outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotators following the described workflows produce summaries whose quality can be meaningfully compared via informativeness and compression metrics
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We test ten annotation workflows varying input modality (audio, transcript, or both) and the inclusion of editing (self or peer-editing) ... iterative peer-editing with audio mitigates this difference
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Introduction The field of conversational speech summarization relies heavily on benchmark datasets like AMI and ICSI (McCowan et al., 2005; Janin et al., 2003). These benchmarks center on formal meeting set- tings, and the field requires equally high-quality benchmarks for unstructured, casual settings. These essential benchmarks should be cre- ated with ...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[2]
Related Work Below, wereviewrelatedworkoneditingworkflows for writing tasks, the impacts of input modality on summarization, and human vs. LLM-generated summaries. Research in ESL (English as a Second Lan- guage) writing highlights the effects of self-editing versus peer editing to improve writing quality. Peer- editing detects more rule-based errors than...
work page 2010
-
[3]
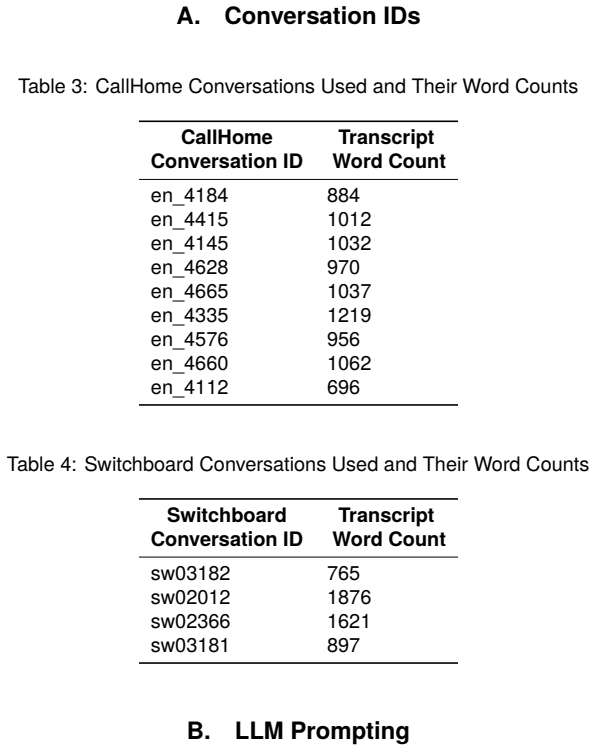
Methods 3.1. Data Preprocessing WerandomlyselectfourconversationsfromSwitch- board Dialogue Act (SWBDA) and nine from Call- Home (Godfrey et al., 1992; Canavan et al., 1997) to form a set of 13 conversations. Both SWBDA and CallHome are datasets of tele- phone conversations with audio recordings and manual transcripts. These datasets were selected because...
work page 1992
-
[4]
Results 4.1. Audio vs Text Summaries We find that un-edited audio-based summaries are shorter, less informative, and less abstrac- tive than un-edited transcript-based summaries. This is signified by lower CREAM scores, higher percentages of lexical overlap and lower percent- ages of novel words in row 2 of Table 1. Our findings regarding audio-based vers...
work page 2024
-
[5]
and ATApeer summaries (row 6) are significantly less informative and more compressed, shown by lower CREAM scores and greater compression ra- tios in comparison to TAself (row 3) and TTApeer summaries (row 5) respectively. Therefore, self- editingandpeer-editingwithboththeaudioandthe transcript maintain the differences in informative- nessthatexistbetween...
-
[6]
Conclusion This study contributed a comparison of workflows to collect human summaries from speech. We identified two potential tradeoffs in using humans Figure 5: Heatmap of the Pearson correlation between all of the different metrics calculated. BertScore (s2s) and BartScore (s2s) correspond to the respective metrics calculated between ini- tial and edi...
-
[7]
Limitations Our study’s conclusions are subject to several limi- tations associated with annotator availability. Firstly, we limit our analysis to summaries gener- ated from 13 conversations as this was the maxi- mumnumberofsummarieswecouldcollectduring the period of time for which our annotators were hired. The data for this study was collected over a to...
-
[8]
Large languagemodelhacking: Quantifyingthehidden risks of using llms for text annotation
Bibliographical References Joachim Baumann, Paul Röttger, Aleksandra Ur- man,AlbertWendsjö,FlorMiriamPlazadelArco, JohannesB.Gruber, andDirkHovy.2025. Large languagemodelhacking: Quantifyingthehidden risks of using llms for text annotation. Michael S. Bernstein, Greg Little, Robert C. Miller, Björn Hartmann, Mark S. Ackerman, David R. Karger, David Crowel...
work page 2025
-
[9]
Soylent: a word processor with a crowd inside.Commun. ACM, 58(8):85–94. Alexandra Canavan, David Graff, and George Zip- perlen. 1997.CALLHOME American English Speech. Linguistic Data Consortium. Santiago Castro, Devamanyu Hazarika, Verónica Pérez-Rosas, Roger Zimmermann, Rada Mihal- cea, and Soujanya Poria. 2019. Towards multi- modal sarcasm detection (an...
work page 1997
-
[10]
Acoustic-prosodic and lexical cues to de- ceptionandtrust: Decipheringhowpeopledetect lies.Transactions of the Association for Compu- tational Linguistics, 8:199–214. VirginiaClinton-Lisell.2022. Listeningearsorread- ing eyes: A meta-analysis of reading and lis- tening comprehension comparisons.Review of Educational Research. Gheorghe Comanici, Eric Biebe...
work page 2022
-
[11]
Understanding the difference between self-feedback and peer-feedback: A compara- tive study of their effects on undergraduate stu- dents’ writing improvement.Sec. Educational Psychology. Yi-Long Lu, Chunhui Zhang, and Wei Wang. 2025. Systematic bias in large language models: Dis- crepant response patterns in binary vs. continu- ous judgment tasks. Joshua ...
-
[12]
Robust speech recognition via large-scale weak supervision. Alex Reinhart, Ben Markey, Michael Laudenbach, Kachatad Pantusen, Ronald Yurko, Gordon Weinberg, and David West Brown. 2025. Do llms write like humans? variation in grammatical andrhetoricalstyles.ProceedingsoftheNational Academy of Sciences, 122(8):e2422455122. KarimSadeghiandMehriDaulatiBaneh.2...
work page 2025
-
[13]
BERTScore: Evaluating Text Generation with BERT
Bartscore: evaluating generated text as text generation. InProceedings of the 35th In- ternational Conference on Neural Information Processing Systems, NIPS ’21, Red Hook, NY, USA. Curran Associates Inc. Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2019. Bertscore: Evaluating text generation with bert.ArXiv, abs/1904.09675...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[19]
Person A asked for advice about a job offer, and Person B suggested prioritizing work-life balance
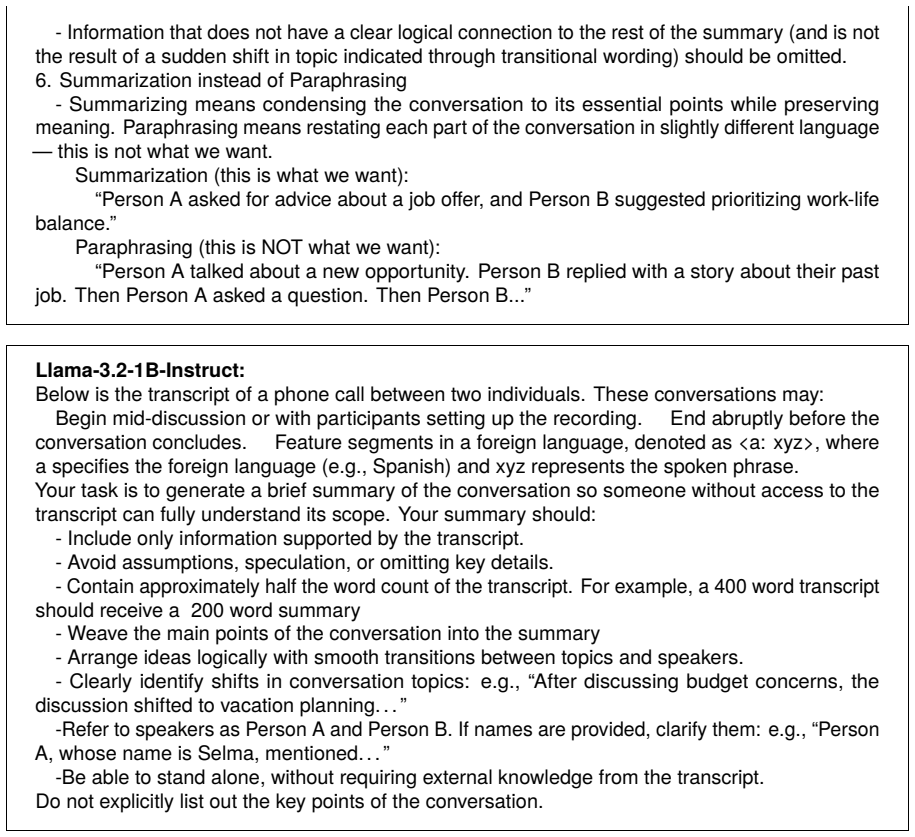
Summarization instead of Paraphrasing Summarizing means condensing the conversation to its essential points while preserving mean- ing. Paraphrasing means restating each part of the conversation in slightly different language — this is not what we want. - Summarization (this is what we want) “Person A asked for advice about a job offer, and Person B sugge...
-
[20]
High Level Information - Capture the main points and most important details of the conversation that will help someone reading your summary understand the context of the call and what was discussed. Avoid capturing small details. - For example, if one speaker mentions that the sky is clear outside, you should not include it in your summary unless it ties ...
-
[21]
Person A, whose name is Selma, described
Speaker References - Use **Person A** and **Person B** initially to refer to the speakers. - If a speaker’s name is mentioned, you may use it but clearly link it: e.g., “Person A, whose name is Selma, described..."
-
[22]
According to Person A, someone they know named Sue returned home last week
Sufficient Context - Avoid summaries that assume the reader knows the speakers or their relationship. - Prefer: “According to Person A, someone they know named Sue returned home last week” Over: “Sue came home last week”
-
[23]
The conversation then shifted to
Topic Shifts - When the conversation topics shift suddenly, use transitional phrasing so that the reader can understand how that information relates to the rest of the summary: ex. “The conversation then shifted to...” “They abruptly changed topics to discuss...”
-
[24]
Logical Connections - The logical connection between all the details included in your summary should be clear. Logical connections can be things like cause and effect, agreement/ disagreement, sequential events, etc. Once someone has read your entire summary they should be able to explain how each piece of information included in the summary connects to t...
-
[25]
Person A asked for advice about a job offer, and Person B suggested prioritizing work-life balance
Summarization instead of Paraphrasing - Summarizing means condensing the conversation to its essential points while preserving meaning. Paraphrasing means restating each part of the conversation in slightly different language — this is not what we want. Summarization (this is what we want): “Person A asked for advice about a job offer, and Person B sugges...
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.