boldsymbol{f}-OPD: Stabilizing Long-Horizon On-Policy Distillation with Freshness-Aware Control
Pith reviewed 2026-05-20 12:23 UTC · model grok-4.3
The pith
A freshness score lets asynchronous on-policy distillation match synchronous performance on long-horizon agent tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
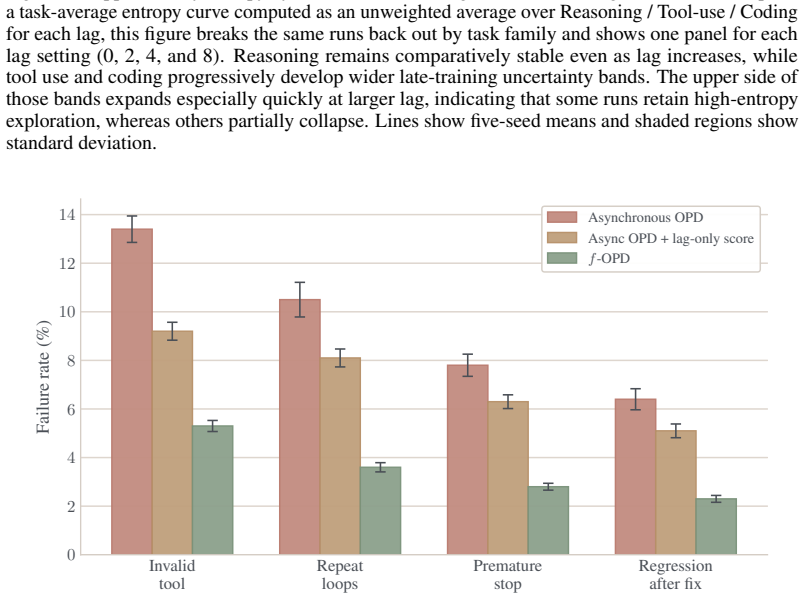
f-OPD stabilizes long-horizon on-policy distillation by theoretically decomposing the objective discrepancy into rollout drift and supervision drift, introducing a sample-level freshness score that quantifies the reliability of buffered samples with respect to the on-policy objective, and adaptively regulating stale-sample influence to constrain accumulated policy drift under asynchronous execution, thereby achieving task performance comparable to synchronous optimization while largely retaining the throughput advantages of asynchronous execution.
What carries the argument
The sample-level freshness score, which quantifies how much a buffered sample deviates from the ideal on-policy objective and guides adaptive regulation of its influence within the f-OPD framework.
If this is right
- Asynchronous execution becomes viable for on-policy distillation without large performance penalties on extended interaction horizons.
- Policy drift can be controlled by weighting samples according to measured staleness rather than by enforcing strict synchronization.
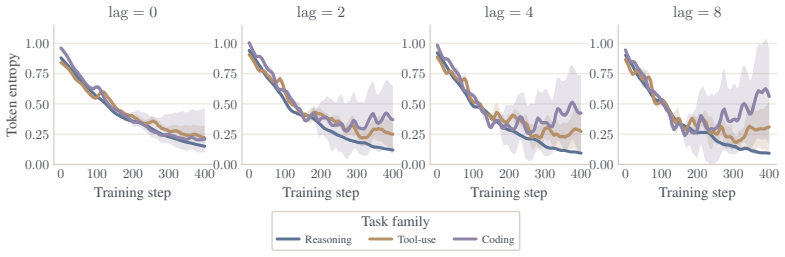
- The same freshness signal can be applied across reasoning, tool-use, and coding-agent tasks as horizon length increases.
- Throughput gains from asynchrony are preserved while task success rates remain comparable to fully synchronous baselines.
Where Pith is reading between the lines
- The freshness mechanism may transfer to other asynchronous reinforcement-learning or distillation pipelines that suffer from rollout or supervision staleness.
- Combining the score with existing replay-buffer techniques could further reduce the synchronization overhead in distributed agent training.
- If the decomposition into rollout and supervision drift proves general, similar freshness controls could stabilize longer-horizon post-training without additional compute.
- The approach suggests that sample reliability signals, rather than global synchronization, may become the default way to manage drift in large-scale agentic training.
Load-bearing premise
The sample-level freshness score reliably quantifies deviation from the ideal on-policy objective and adaptively regulating its influence is sufficient to constrain accumulated policy drift under asynchronous execution.
What would settle it
Running f-OPD on the same long-horizon tasks without the freshness-based regulation and observing whether performance collapses to the level of naive asynchronous distillation, or running it with regulation and seeing whether performance still falls substantially below synchronous optimization, would settle the central claim.
Figures




read the original abstract
Scaling on-policy distillation (OPD) for large language models (LLMs) confronts a fundamental tension: asynchronous execution is necessary for system efficiency, but structurally deviates from the ideal on-policy objective. To address this challenge, we theoretically decompose the objective discrepancy into rollout drift and supervision drift, capturing staleness in student rollout and teacher context, respectively. Building on this, we introduce a sample-level freshness score that quantifies the reliability of a buffered sample with respect to the on-policy objective. Guided by this signal, we further propose f-OPD, a novel framework that adaptively regulates stale-sample influence and constrains policy drift accumulated under asynchronous training. Across reasoning, tool-use, and coding-agent tasks of increasing interaction horizon, f-OPD consistently achieves task performance comparable to synchronous optimization while largely retaining the throughput advantages of asynchronous execution. Our results establish the first recipe for achieving a performance-efficiency trade-off in OPD, paving the way for long-horizon agentic post-training at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to resolve the efficiency-performance tension in scaling on-policy distillation (OPD) for LLMs by theoretically decomposing the objective discrepancy into rollout drift (staleness in student rollout) and supervision drift (staleness in teacher context). It introduces a sample-level freshness score to quantify buffered-sample reliability relative to the on-policy objective and proposes the f-OPD framework that adaptively regulates stale-sample influence to constrain accumulated policy drift under asynchronous execution. Empirical results across reasoning, tool-use, and coding-agent tasks of increasing interaction horizon show task performance comparable to synchronous optimization while largely retaining asynchronous throughput advantages.
Significance. If the decomposition and freshness-aware regulation prove effective at controlling policy drift without introducing new biases, the work would offer a practical and principled recipe for the performance-efficiency trade-off in long-horizon OPD. This could meaningfully advance scalable agentic post-training by allowing asynchronous execution without sacrificing on-policy fidelity, with the multi-task empirical validation providing initial evidence of generality.
major comments (2)
- [§3.1] §3.1 (theoretical decomposition): The central claim that the objective discrepancy decomposes cleanly into rollout drift and supervision drift is load-bearing for the entire f-OPD construction; the manuscript should provide the explicit derivation (including any assumptions on the policy update and buffer dynamics) to confirm that the two terms are exhaustive and non-overlapping.
- [§4.2] §4.2 (freshness score definition): The sample-level freshness score is presented as reliably quantifying deviation from the ideal on-policy objective, yet the weakest assumption in the work is that adaptively regulating its influence is sufficient to bound accumulated drift; an ablation or sensitivity analysis showing how performance degrades when the score is replaced by a simpler heuristic (e.g., age only) would strengthen this claim.
minor comments (2)
- [Abstract] The abstract states the performance claims without any quantitative numbers or confidence intervals; adding a brief summary of the key metrics (e.g., success rate deltas and throughput ratios) would improve readability.
- [§3 and §5] Notation for the freshness score and the two drift terms should be introduced once in §3 and used consistently thereafter; occasional redefinition in the experimental section creates unnecessary ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address each major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.1] §3.1 (theoretical decomposition): The central claim that the objective discrepancy decomposes cleanly into rollout drift and supervision drift is load-bearing for the entire f-OPD construction; the manuscript should provide the explicit derivation (including any assumptions on the policy update and buffer dynamics) to confirm that the two terms are exhaustive and non-overlapping.
Authors: We agree that an explicit derivation strengthens the foundation of the decomposition. In the revised manuscript we will expand §3.1 with the full step-by-step derivation, stating the assumptions on policy updates and buffer dynamics, and showing that rollout drift and supervision drift are exhaustive and non-overlapping under those conditions. revision: yes
-
Referee: [§4.2] §4.2 (freshness score definition): The sample-level freshness score is presented as reliably quantifying deviation from the ideal on-policy objective, yet the weakest assumption in the work is that adaptively regulating its influence is sufficient to bound accumulated drift; an ablation or sensitivity analysis showing how performance degrades when the score is replaced by a simpler heuristic (e.g., age only) would strengthen this claim.
Authors: We acknowledge that an ablation against a simpler baseline such as age-only regulation would provide useful supporting evidence. We will add this ablation to the revised version, reporting performance when the freshness score is replaced by sample age across the reasoning, tool-use, and coding-agent tasks. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The abstract and available description present a theoretical decomposition of objective discrepancy into rollout drift and supervision drift as an independent analytical step, followed by the definition of a sample-level freshness score and the proposal of the f-OPD framework for adaptive regulation. No equations, fitted parameters, or self-citations are exhibited that reduce any claimed prediction or result back to its own inputs by construction. The performance claims rest on empirical comparisons across tasks rather than on a self-referential loop, rendering the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The objective discrepancy in asynchronous on-policy distillation can be decomposed into rollout drift and supervision drift.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We theoretically decompose the objective discrepancy into rollout drift and supervision drift... introduce a sample-level freshness score fi = 1/(τi + 1) exp(−e∆t_i) ... J(πt_θ) = E [σ(fi − ξ)(ℓt_i + λ Ranchor_i)]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 3.2 (Two-fold Decomposition... ∆t ≤ Croll TV(dt, dstale,t) + Csup E[TV(πteacher(ct_i), πteacher(cr(i)_i))]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Harts...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Deepseek-v4: Towards highly efficient million-token context intelligence
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence. https://hu ggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf , 2026. technical report
work page 2026
-
[6]
MiMo-V2-Flash Technical Report
Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, et al. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv:2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
slime: An llm post-training framework for rl scaling.https://github.com/THUDM/slime, 2025
Zilin Zhu, Chengxing Xie, Xin Lv, and slime Contributors. slime: An llm post-training framework for rl scaling.https://github.com/THUDM/slime, 2025. GitHub repository, accessed 2026-05-06
work page 2025
-
[10]
Nemo rl: A scalable and efficient post-training library.https://github.com/NVIDIA-NeMo/RL,
Nvidia. Nemo rl: A scalable and efficient post-training library.https://github.com/NVIDIA-NeMo/RL,
-
[11]
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks.Advances in neural information processing systems, 28, 2015
work page 2015
-
[12]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Shimin Zhang, Xianwei Chen, Yufan Shen, Ziyuan Ye, and Jibin Wu. Relax: Reasoning with latent exploration for large reasoning models.arXiv preprint arXiv:2512.07558, 2025
-
[15]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
MiniLLM: On-policy distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: On-policy distillation of large language models. InInternational Conference on Learning Representations, 2024
work page 2024
-
[17]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. In International Conference on Learning Representations, 2024. 10
work page 2024
-
[18]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan- ang Gao, Wenkai Yang, Zhiyuan Liu, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self- distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
OPSDL: On-Policy Self-Distillation for Long-Context Language Models
Xinsen Zhang, Zhenkai Ding, Tianjun Pan, Run Yang, Chun Kang, Xue Xiong, and Jingnan Gu. Opsdl: On-policy self-distillation for long-context language models.arXiv preprint arXiv:2604.17535, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
CRISP: Compressed Reasoning via Iterative Self-Policy Distillation
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. Crisp: Compressed reasoning via iterative self-policy distillation.arXiv preprint arXiv:2603.05433, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E
Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron. Scaling reasoning efficiently via relaxed on-policy distillation.arXiv preprint arXiv:2603.11137, 2026
-
[24]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation
Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation.arXiv preprint arXiv:2602.12125, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Yuanheng Zhu, and Dongbin Zhao. Revisiting on-policy distillation: Empirical failure modes and simple fixes.arXiv preprint arXiv:2603.25562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Black-box on-policy distillation of large language models.arXiv preprint, arXiv:2511.10643, 2025
Tianzhu Ye, Li Dong, Zewen Chi, Xun Wu, Shaohan Huang, and Furu Wei. Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643, 2025
-
[28]
Entropy-aware on-policy distillation of language models
Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models.arXiv preprint arXiv:2603.07079, 2026. Also available on OpenReview as SPOT 2026
-
[29]
Dongxu Zhang, Zhichao Yang, Sepehr Janghorbani, Jun Han, Andrew Ressler II, Qian Qian, Gregory D. Lyng, Sanjit Singh Batra, and Robert E. Tillman. Fast and effective on-policy distillation from reasoning prefixes.arXiv preprint arXiv:2602.15260, 2026
-
[30]
Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu
V olodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In Proceedings of the 33rd International Conference on Machine Learning, 2016
work page 2016
-
[31]
IMPALA: Scalable distributed deep-rl with importance weighted actor-learner architectures
Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, V olodymir Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, Shane Legg, and Koray Kavukcuoglu. IMPALA: Scalable distributed deep-rl with importance weighted actor-learner architectures. InProceedings of the 35th International Conference on Machine Learning, 2018
work page 2018
-
[32]
Staleness-aware Async-SGD for distributed deep learning
Wei Zhang, Suyog Gupta, Xiangru Lian, and Ji Liu. Staleness-aware Async-SGD for distributed deep learning. InProceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, 2016
work page 2016
-
[33]
PipeDream: Fast and efficient pipeline parallel DNN training
Aaron Harlap, Deepak Narayanan, Amar Phanishayee, Vivek Seshadri, Nikhil Devanur, Greg Ganger, and Phil Gibbons. PipeDream: Fast and efficient pipeline parallel DNN training. InProceedings of the 27th ACM Symposium on Operating Systems Principles, 2019
work page 2019
-
[34]
Yaosheng Xu, Dailin Hu, Litian Liang, Stephen Marcus McAleer, Pieter Abbeel, and Roy Fox
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning.Machine Learning, 8(3-4):229–256, 1992. doi: 10.1007/BF00992696
-
[35]
When speed kills stability: Demystifying RL collapse from the training-inference mismatch
Jiacai Liu, Yingru Li, Yuqian Fu, Jiawei Wang, Qian Liu, and Yu Shen. When speed kills stability: Demystifying RL collapse from the training-inference mismatch. https://richardli.xyz/rl-colla pse, September 2025. Research blog post, accessed 2026-05-06
work page 2025
-
[36]
Stephane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, 2011. 11
work page 2011
-
[37]
John Schulman, Sergey Levine, Philipp Moritz, Michael I. Jordan, and Pieter Abbeel. Trust region policy optimization. InProceedings of the 32nd International Conference on Machine Learning, 2015
work page 2015
-
[38]
Yingru Li, Jiacai Liu, Jiawei Xu, Yuxuan Tong, Ziniu Li, Qian Liu, and Baoxiang Wang. Trust region masking for long-horizon LLM reinforcement learning.arXiv preprint arXiv:2512.23075, 2025
-
[39]
Jacob Hilton, Karl Cobbe, and John Schulman. Batch size-invariance for policy optimization.Advances in Neural Information Processing Systems, 35:17086–17098, 2022. Introduces decoupled PPO by separating the proximal policy for update control from the behavior policy for off-policy correction
work page 2022
-
[40]
Kevin Lu and Thinking Machines Lab. On-policy distillation. https://thinkingmachines.ai/blog /on-policy-distillation/, 2025. Thinking Machines Lab blog post, published 2025-10-27, accessed 2026-05-06
work page 2025
-
[41]
BytedTsinghua-SIA. DAPO-Math-17k. https://huggingface.co/datasets/BytedTsinghua-SIA /DAPO-Math-17k, 2025. Hugging Face dataset repository, accessed 2026-05-06
work page 2025
-
[42]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. ReTool: Reinforcement learning for strategic tool use in LLMs.arXiv preprint arXiv:2504.11536, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R. Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering. InAdvances in Neural Information Processing Systems, 2024. URL https://arxiv.org/abs/2405.15793 . Recommended citation for mini-SWE-agent from the project repository
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, 2021
work page 2021
-
[45]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InInternational Conference on Learning Representations, 2024
work page 2024
-
[46]
Training Software Engineering Agents and Verifiers with SWE-Gym
Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. Training software engineering agents and verifiers with SWE-Gym. InProceedings of the 42nd International Conference on Machine Learning, 2025. arXiv:2412.21139
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
arXiv preprint arXiv:2511.16108(2025)
Shiyi Cao, Dacheng Li, Fangzhou Zhao, Shuo Yuan, Sumanth R. Hegde, Connor Chen, Charlie Ruan, Tyler Griggs, Shu Liu, Eric Tang, Richard Liaw, Philipp Moritz, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. Skyrl-agent: Efficient rl training for multi-turn llm agent.arXiv preprint arXiv:2511.16108, 2025
-
[48]
Deepswe: Training a fully open-sourced, state-of-the-art coding agent by scaling rl
Michael Luo, Naman Jain, Jaskirat Singh, Sijun Tan, Colin Cai, Tarun Venkat, Manan Roongta, Li Erran Li, Raluca Ada Popa, Koushik Sen, Ion Stoica, Ameen Patel, Qingyang Wu, Alpay Ariyak, Shang Zhu, Ben Athiwaratkun, and Ce Zhang. Deepswe: Training a fully open-sourced, state-of-the-art coding agent by scaling rl. https://pretty-radio-b75.notion.site/DeepS...
work page 2025
-
[49]
Qwen3-Coder-Next Technical Report
Ruisheng Cao, Mouxiang Chen, Jiawei Chen, Zeyu Cui, Yunlong Feng, Binyuan Hui, Yuheng Jing, Kaixin Li, Mingze Li, Junyang Lin, et al. Qwen3-coder-next technical report.arXiv preprint arXiv:2603.00729, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[51]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021. 12
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[52]
AgentBench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating LLMs as agents. InInternational Conference on Learning Representations, 2024
work page 2024
-
[53]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
VisualWebArena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. VisualWebArena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024
work page 2024
-
[55]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
John Yang, Kilian Lieret, Carlos E. Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. SWE-smith: Scaling data for software engineering agents. InAdvances in Neural Information Processing Systems, 2025. URL https://openreview.net /forum?id=63iVrXc8cC. Datasets and Benchmarks Track Spotlight. 13...
work page 2025
-
[57]
rollout drift and supervision drift are distinct nonnegative mismatch channels
-
[58]
larger values of those diagnostics increase potential objective discrepancy under the stated assumptions, while larger lag enlarges the budget over which rollout drift may accumulate; and
-
[59]
mapping those signals through a monotone freshness transformation suppresses higher-risk samples. What the theory doesnotclaim is that α and β are universal constants or that the chosen surrogate is uniquely optimal. In practice, they should be understood as domain-dependent calibration parameters that align observable mismatch diagnostics onto a common o...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.