A data-driven Fourier-mixture neural-network method for density estimation
Pith reviewed 2026-05-20 00:42 UTC · model grok-4.3
The pith
A neural network estimates densities by training a Gaussian-Laplace mixture against an empirical characteristic function.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By using a positive Gaussian-Laplace mixture representation that possesses a closed-form characteristic function, the parameters of the density can be recovered via neural-network optimization against the empirical characteristic function, yielding an estimator for which the expected L2 error separates into Fourier truncation, empirical training error, discretization, and CF sampling error terms in the i.i.d. case, and a conditional analogue with pseudo-law discrepancy terms in the resampling case.
What carries the argument
The Gaussian-Laplace mixture density model with closed-form characteristic function, whose parameters are predicted by a neural network trained by matching to the empirical characteristic function.
If this is right
- The method admits a multidimensional extension whose computational complexity is analyzed.
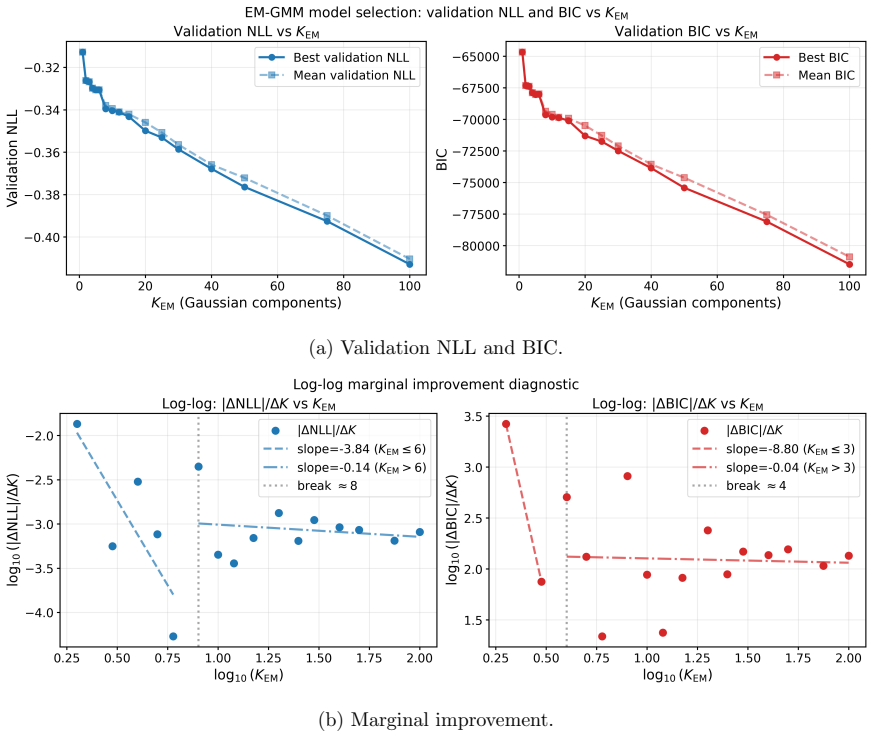
- Performance is competitive with Expectation-Maximization on standard Gaussian-mixture benchmarks.
- Clear performance gains appear on heavy-tailed target distributions compared to alternatives.
- L2 error decay matches the theoretical predictions in well-specified simulation settings.
- Effective estimation is demonstrated for one-year Australian equity return distributions from resampled dependent data.
Where Pith is reading between the lines
- This training strategy may apply to other density estimation problems where the characteristic function is more accessible than the likelihood.
- The explicit error decomposition could inform practical choices for truncation frequency and network capacity.
- Similar Fourier-mixture approaches might extend to estimating other functionals like moments or tail probabilities.
- Handling of dependent data via pseudo-sampling suggests utility in time-series density estimation without explicit dynamic modeling.
Load-bearing premise
The target density admits a sufficiently accurate approximation by a finite Gaussian-Laplace mixture whose parameters can be recovered by neural-network training against the empirical characteristic function.
What would settle it
Numerical experiments on a known density where increasing the number of samples or reducing the truncation level does not produce the predicted reduction in L2 error would falsify the separation in the error bound.
Figures



read the original abstract
We propose a data-driven Fourier-trained neural-network method for estimating fixed-horizon probability densities from empirical characteristic-function (CF) information. The estimator is a positive Gaussian--Laplace mixture with closed-form CF, so training can be performed directly in Fourier space while preserving nonnegativity and unit mass. We consider two sampling settings. In the direct i.i.d. sampling setting, the method is trained against an empirical CF constructed from i.i.d. samples. In the resampling-based pseudo-sampling setting, it is trained against an empirical pseudo-CF constructed from dependent data by resampling. For the direct i.i.d. case, we derive an expected $L_2$ error bound that separates Fourier truncation, empirical training error, discretization, and CF sampling error. For the pseudo-sampling case, we obtain a conditional analogue with two additional pseudo-law discrepancy terms. We develop a multidimensional extension of the framework and analyze its computational complexity. Numerical experiments show competitive performance relative to Expectation--Maximization on Gaussian-mixture benchmarks, clear gains on heavy-tailed targets, $L_2$ error decay consistent with the theory in a well-specified setting, and effective estimation of one-year Australian equity return law from resampled dependent data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a data-driven method for fixed-horizon density estimation that represents the target as a positive finite Gaussian-Laplace mixture whose parameters are recovered by neural-network training directly against an empirical characteristic function (or pseudo-CF in the resampling case). For i.i.d. sampling it derives an expected L2 error bound that isolates Fourier truncation, empirical training error, discretization, and CF sampling error; for the resampling setting it supplies a conditional analogue containing two additional pseudo-law discrepancy terms. A multidimensional extension is developed together with a computational-complexity analysis, and numerical experiments compare the method to EM on Gaussian-mixture benchmarks, demonstrate gains on heavy-tailed targets, confirm L2 decay consistent with the theory in the well-specified regime, and apply the estimator to one-year Australian equity returns from resampled dependent data.
Significance. If the central claims hold, the work supplies a theoretically grounded estimator that enforces non-negativity and unit mass by construction while permitting direct Fourier-space fitting. The explicit decomposition of the L2 bound into controllable sampling, discretization, and truncation terms is a clear strength, as is the extension to dependent data via resampling. The reported numerical improvements on heavy-tailed targets and the real-data application to equity returns indicate practical relevance beyond the well-specified Gaussian-mixture setting.
major comments (2)
- [Abstract] Abstract (paragraph on estimator construction and error bounds): The expected L2 error bound is stated to separate Fourier truncation, empirical training error, discretization, and CF sampling error (direct case) plus two pseudo-law discrepancy terms (resampling case). However, the bound is derived under the standing assumption that the target density admits a sufficiently accurate L2 approximation by some finite Gaussian-Laplace mixture whose parameters can be recovered by the NN training. No explicit approximation rates for this mixture class (in L2 or in the CF metric) are supplied for densities outside the well-specified regime, such as heavy-tailed or non-smooth targets. Without such rates the separated error terms do not by themselves establish consistency for general densities.
- [Pseudo-sampling analysis] Section on the pseudo-sampling estimator and conditional bound: The conditional L2 analogue includes two additional pseudo-law discrepancy terms whose control is not quantified. It is therefore unclear whether these terms remain negligible under the dependence structures encountered in the resampling procedure, or whether they require further assumptions on the underlying process that are not stated in the derivation.
minor comments (2)
- [Multidimensional extension] The description of the multidimensional extension would benefit from an explicit statement of how the closed-form CF property and the positivity constraint are preserved component-wise when the dimension increases.
- [Numerical experiments] In the numerical experiments, the precise definition of the L2 error used for the decay plots and the number of Monte-Carlo replications should be stated explicitly to allow direct verification of the reported consistency with theory.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We appreciate the positive assessment of the error decomposition and the resampling extension. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on estimator construction and error bounds): The expected L2 error bound is stated to separate Fourier truncation, empirical training error, discretization, and CF sampling error (direct case) plus two pseudo-law discrepancy terms (resampling case). However, the bound is derived under the standing assumption that the target density admits a sufficiently accurate L2 approximation by some finite Gaussian-Laplace mixture whose parameters can be recovered by the NN training. No explicit approximation rates for this mixture class (in L2 or in the CF metric) are supplied for densities outside the well-specified regime, such as heavy-tailed or non-smooth targets. Without such rates the separated error terms do not by themselves establish consistency for general densities.
Authors: We agree that the L2 bound is stated under the assumption that the target admits a good L2 approximation by a finite Gaussian-Laplace mixture. The derivation isolates the controllable terms (truncation, empirical training, discretization, and CF sampling) once this approximation is granted; the paper does not supply explicit approximation rates of the mixture class to arbitrary densities in L2 or CF distance. The numerical section shows competitive performance on heavy-tailed targets, indicating practical flexibility, but this does not replace a rate. In revision we will clarify in the abstract and introduction that the consistency statement applies when the mixture approximation error is small, and we will add a short remark noting that general approximation rates for the mixture class constitute an open question left for future work. revision: partial
-
Referee: [Pseudo-sampling analysis] Section on the pseudo-sampling estimator and conditional bound: The conditional L2 analogue includes two additional pseudo-law discrepancy terms whose control is not quantified. It is therefore unclear whether these terms remain negligible under the dependence structures encountered in the resampling procedure, or whether they require further assumptions on the underlying process that are not stated in the derivation.
Authors: The two pseudo-law discrepancy terms appear explicitly in the conditional bound precisely to isolate the additional error introduced by resampling. Their magnitude depends on the dependence structure of the underlying process and on the resampling scheme; the derivation therefore leaves them as explicit remainder terms rather than bounding them under unstated assumptions. In the equity-return application the resampling procedure is chosen to respect the observed serial dependence, and the empirical results are consistent with these terms not dominating. We acknowledge that rigorous control would require further assumptions (for example, strong mixing or specific properties of the resampling kernel). In the revision we will add a clarifying paragraph stating the conditional nature of the bound and the conditions under which the discrepancy terms can be controlled. revision: yes
Circularity Check
Error bound derivation is self-contained; no reduction to inputs by construction
full rationale
The paper's central claim is an expected L2 error bound separating Fourier truncation, empirical training error, discretization, and CF sampling error (plus pseudo-law terms in the resampling case). This rests on standard Fourier analysis and empirical-process arguments applied to the NN-trained Gaussian-Laplace mixture estimator with closed-form CF. No quoted step shows a prediction or bound reducing by the paper's own equations to a fitted parameter or self-citation chain; the mixture approximation assumption is stated explicitly as a modeling choice rather than smuggled in via definition or prior self-work. The derivation therefore remains independent of its fitted outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gaussian-Laplace mixture possesses a closed-form characteristic function.
- standard math Empirical characteristic function converges to the true characteristic function under the stated sampling regimes.
Reference graph
Works this paper leans on
-
[1]
O. E. Barndorff-Nielsen , Normal inverse gaussian distributions and stochastic volatility modelling , Scandinavian Journal of statistics, 24 (1997), pp. 1--13
work page 1997
-
[2]
P. Carr, H. Geman, D. B. Madan, and M. Yor , The fine structure of asset returns: An empirical investigation , The Journal of Business, 75 (2002), pp. 305--332
work page 2002
-
[3]
D.-M. Dang and C. Chen , Multi-period mean-buffered probability of exceedance in Defined Contribution portfolio optimization , SIAM Journal on Financial Mathematics, (2026). to appear
work page 2026
-
[4]
D.-M. Dang and H. Zhou , Monotone 2D integration scheme for Mean-CVaR optimization via Fourier -trained transition kernels , arXiv preprint arXiv:2603.26291, (2026)
-
[5]
A. C. Davison and D. V. Hinkley , Bootstrap Methods and Their Application , Cambridge University Press, Cambridge, 1997
work page 1997
-
[6]
A. P. Dempster, N. M. Laird, and D. B. Rubin , Maximum likelihood from incomplete data via the EM algorithm , Journal of the Royal Statistical Society. Series B, 39 (1977), pp. 1--38
work page 1977
-
[7]
R. Du and D.-M. Dang , Fourier neural network approximation of transition densities in finance , SIAM Journal on Scientific Computing, 47 (2025), pp. C529--C557
work page 2025
-
[8]
B. Efron and R. J. Tibshirani , An Introduction to the Bootstrap , Chapman and Hall, New York, 1993
work page 1993
-
[9]
F. Fang and C. W. Oosterlee , A novel pricing method for european options based on fourier-cosine series expansions , SIAM Journal on Scientific Computing, 31 (2008), pp. 826--848
work page 2008
-
[10]
P. A. Forsyth and G. Labahn , -monotone Fourier methods for optimal stochastic control in finance , Journal of Computational Finance, 22(4) (2019), pp. 25--71
work page 2019
-
[11]
D. P. Kingma and J. Ba , Adam: A method for stochastic optimization , arXiv preprint arXiv:1412.6980, (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[12]
Kou , A jump diffusion model for option pricing , M anagement S cience, 48 (2002), pp
S. Kou , A jump diffusion model for option pricing , M anagement S cience, 48 (2002), pp. 1086--1101
work page 2002
-
[13]
H. R. K \"u nsch , The jackknife and the bootstrap for general stationary observations , The Annals of Statistics, 17 (1989), pp. 1217--1241
work page 1989
-
[14]
S. N. Lahiri , Resampling Methods for Dependent Data , Springer, New York, 2003
work page 2003
- [15]
-
[16]
T. Mathews , A history of australian equities , Research Discussion Paper RDP 2019-04, Reserve Bank of Australia, 2019, https://www.rba.gov.au/publications/rdp/2019/2019-04.html
work page 2019
-
[17]
G. J. McLachlan, S. X. Lee, and S. I. Rathnayake , Finite mixture models , Annual review of statistics and its application, 6 (2019), pp. 355--378
work page 2019
-
[18]
G. J. McLachlan and D. Peel , Finite Mixture Models , Wiley, New York, 2000
work page 2000
-
[19]
R. C. Merton , Option pricing when underlying stock returns are discontinuous , Journal of financial economics, 3 (1976), pp. 125--144
work page 1976
-
[20]
D. N. Politis and J. P. Romano , The stationary bootstrap , Journal of the American Statistical Association, 89 (1994), pp. 1303--1313
work page 1994
-
[21]
D. N. Politis, J. P. Romano, and M. Wolf , Subsampling , Springer, New York, 1999
work page 1999
-
[22]
B. W. Silverman , Density Estimation for Statistics and Data Analysis , Chapman and Hall, London, 1986
work page 1986
-
[23]
P. T. Tran et al. , On the convergence proof of AMSGrad and a new version , IEEE Access, 7 (2019), pp. 61706--61716
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.