The MixCount Dataset: Bridging the Data Gap for Open-Vocabulary Object Counting
Pith reviewed 2026-05-20 11:19 UTC · model grok-4.3
The pith
Automatically synthesized mixed-object scenes improve counting model accuracy on real images by more than 18 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
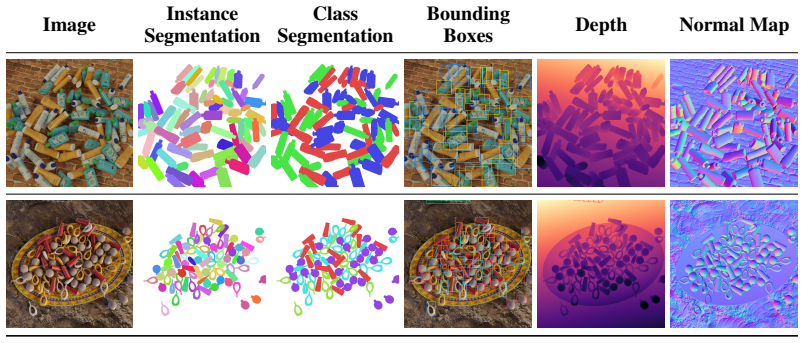
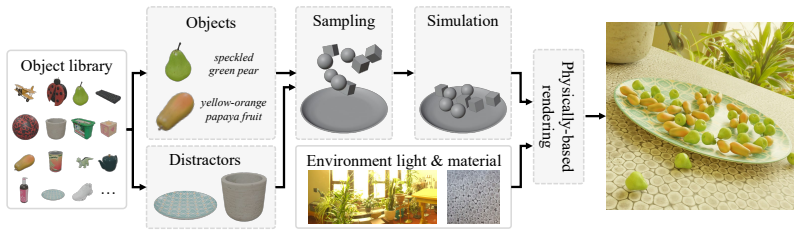
MixCount is a dataset and benchmark for mixed-object counting created through an automatic generation pipeline that synthesizes images, fine-grained textual descriptions, and pixel-perfect counting annotations at scale. Evaluating state-of-the-art counting models on MixCount exposes severe degradation in the mixed-object setting. Training these models on the synthesized data yields substantial gains on real-world benchmarks, reducing MAE by 20.14 percent on FSC-147 and by 18.3 percent on PairTally. These results establish MixCount as both a benchmark and a training dataset for fine-grained counting while demonstrating that the pipeline, which produces effectively unlimited labeled data, can
What carries the argument
The automatic generation pipeline that produces synthetic images of mixed objects along with pixel-perfect counting annotations and fine-grained textual descriptions.
If this is right
- Current counting models exhibit clear performance drops when tested on mixed-object scenes from the new benchmark.
- Training on the synthesized data transfers to real datasets and lowers error rates without requiring manual annotation effort.
- The pipeline can generate unlimited perfectly labeled examples to overcome data bottlenecks in counting research.
- The approach supports open-vocabulary counting by pairing images with detailed textual descriptions of object types.
Where Pith is reading between the lines
- The same automatic synthesis method could be adapted to generate training data for related tasks such as object detection in cluttered scenes.
- Industrial applications that need to count diverse items in one view might adopt the pipeline to create custom training sets on demand.
- Future models could integrate the generation process directly into training loops to produce fresh examples tailored to observed failure cases.
Load-bearing premise
The synthetic images and annotations match the distribution and complexity of real mixed-object scenes closely enough that training on them improves performance on actual photographs without harmful domain artifacts.
What would settle it
Retraining the same counting models on MixCount and measuring no reduction or an increase in MAE on FSC-147 or PairTally would show that the synthetic data does not transfer effectively.
Figures







read the original abstract
Object counting is a foundational vision task with over a decade of dedicated research, yet state-of-the-art models still fail systematically in the mixed-object setting that dominates real-world applications such as industrial inspection and product sorting. We show that this gap is strongly driven by limitations in existing training and evaluation data: real counting datasets are prohibitively expensive to annotate and suffer from labeling noise, while existing synthetic alternatives lack diversity and realism. We address this with MixCount, a dataset and benchmark for mixed-object counting designed to target the failure modes of current counting models. To overcome the high cost of constructing and labeling such data, we develop an automatic generation pipeline that synthesizes images, fine-grained textual descriptions, and pixel-perfect counting annotations at scale, eliminating the labeling ambiguity that plagues prior datasets. Evaluating state-of-the-art counting models on MixCount exposes severe degradation in the mixed-object setting. More importantly, training these models on our synthesized data yields substantial gains on real-world benchmarks, reducing MAE by 20.14% on FSC-147 and by 18.3% on PairTally. These results establish MixCount as both a benchmark and a training dataset for fine-grained counting, and demonstrate that our pipeline, which produces effectively unlimited labeled data, helps address a long-standing bottleneck in counting models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the MixCount dataset and benchmark for mixed-object counting, generated via an automatic synthesis pipeline that produces images, fine-grained textual descriptions, and pixel-perfect annotations at scale. It demonstrates that state-of-the-art counting models degrade substantially in the mixed-object setting on this data and reports that training on MixCount yields MAE reductions of 20.14% on FSC-147 and 18.3% on PairTally.
Significance. If the performance gains are shown to stem from improved distribution matching rather than data volume or artifacts, the work would meaningfully address the long-standing data bottleneck in object counting for complex real-world scenes. The automatic pipeline's capacity to generate effectively unlimited labeled data without annotation noise is a practical strength that could support further progress in open-vocabulary and fine-grained counting.
major comments (2)
- The central empirical claim (MAE reductions of 20.14% on FSC-147 and 18.3% on PairTally after training on MixCount) is load-bearing for the assertion that the dataset bridges the data gap. The manuscript provides no ablation that holds total training sample count fixed while varying only the realism of the generation process, and no quantitative domain-similarity metrics (e.g., feature-space distances or perceptual studies) between the synthetic images and the real benchmarks. This leaves the causal attribution to faithful distribution matching open to alternative explanations such as volume effects or pipeline-specific cues.
- In the baseline evaluation and training sections, insufficient detail is given on the original models' training protocols (e.g., from-scratch retraining versus fine-tuning), the precise data splits, hyperparameter settings, and statistical significance of the reported MAE gains. These omissions hinder assessment of whether the improvements are robust and fairly compared.
minor comments (1)
- The abstract and title use both 'mixed-object counting' and 'open-vocabulary object counting'; a brief clarification of their relationship would improve precision.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript. We address each of the major comments below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: The central empirical claim (MAE reductions of 20.14% on FSC-147 and 18.3% on PairTally after training on MixCount) is load-bearing for the assertion that the dataset bridges the data gap. The manuscript provides no ablation that holds total training sample count fixed while varying only the realism of the generation process, and no quantitative domain-similarity metrics (e.g., feature-space distances or perceptual studies) between the synthetic images and the real benchmarks. This leaves the causal attribution to faithful distribution matching open to alternative explanations such as volume effects or pipeline-specific cues.
Authors: We appreciate the referee highlighting this important point regarding causal attribution. The manuscript reports substantial gains from training on MixCount but does not contain an ablation that holds training sample count fixed. We will add a controlled ablation in the revised manuscript comparing models trained on size-matched subsets of MixCount against the original real-data baselines. We will also add quantitative domain-similarity metrics, specifically Fréchet Inception Distance (FID) between MixCount images and the real benchmark distributions, to provide evidence supporting distribution matching over volume or artifact effects. revision: yes
-
Referee: In the baseline evaluation and training sections, insufficient detail is given on the original models' training protocols (e.g., from-scratch retraining versus fine-tuning), the precise data splits, hyperparameter settings, and statistical significance of the reported MAE gains. These omissions hinder assessment of whether the improvements are robust and fairly compared.
Authors: We agree that greater detail is required for reproducibility and fair evaluation. In the revised manuscript we will expand the relevant sections to specify whether each baseline was retrained from scratch or fine-tuned, the exact train/validation/test splits used, the complete set of hyperparameter values, and statistical significance of the MAE improvements (including standard deviations over multiple random seeds). revision: yes
Circularity Check
No significant circularity; results are empirical on external benchmarks
full rationale
The paper's core claims rest on an automatic synthesis pipeline for MixCount data followed by empirical training that produces measured MAE reductions on independent real-world test sets (FSC-147 and PairTally). These performance numbers are obtained via standard transfer-learning evaluation against externally held-out data and do not reduce to fitted parameters, self-definitions, or self-citation chains within the paper. No equations, uniqueness theorems, or ansatzes are presented that would create a self-referential loop; the reported gains are falsifiable against the cited external benchmarks and therefore constitute independent evidence rather than a renaming or reconstruction of the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic image generation can produce sufficiently realistic mixed-object scenes that transfer to real data distributions.
Reference graph
Works this paper leans on
-
[1]
Open-world text-specified object counting
Niki Amini-Naieni, Kiana Amini-Naieni, Tengda Han, and Andrew Zisserman. Open-world text-specified object counting. InThe 36th British Machine Vision Conference (BMVC), 2023
work page 2023
-
[2]
Niki Amini-Naieni, Tengda Han, and Andrew Zisserman. Countgd: Multi-modal open-world counting.Advances in Neural Information Processing Systems, 37:48810–48837, 2024
work page 2024
-
[3]
Countgd++: Generalized prompting for open-world counting
Niki Amini-Naieni and Andrew Zisserman. Countgd++: Generalized prompting for open-world counting. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026
work page 2026
-
[4]
Open-world object counting in videos
Niki Amini-Naieni and Andrew Zisserman. Open-world object counting in videos. InPro- ceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 2300–2308, 2026
work page 2026
-
[5]
Vqa: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. InProceedings of the IEEE international conference on computer vision, pages 2425–2433, 2015
work page 2015
-
[6]
Carlos Arteta, Victor Lempitsky, and Andrew Zisserman. Counting in the wild. InEuropean conference on computer vision, pages 483–498. Springer, 2016
work page 2016
-
[7]
Chain-of-look spatial reasoning for dense surgical instrument counting
Rishikesh Bhyri, Brian R Quaranto, Junsong Yuan, Peter CW Kim, and Nan Xi. Chain-of-look spatial reasoning for dense surgical instrument counting. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 8521–8530, 2026
work page 2026
-
[8]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Blender Foundation, Stichting Blender Foundation, Amsterdam, 2018
Blender Online Community.Blender - a 3D modelling and rendering package. Blender Foundation, Stichting Blender Foundation, Amsterdam, 2018
work page 2018
-
[10]
Siyang Dai, Jun Liu, and Ngai-Man Cheung. Referring expression counting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16985–16995, 2024
work page 2024
-
[11]
Figo: Fine-grained object counting without annotations.arXiv preprint arXiv:2504.11705, 2025
Adrian D’Alessandro, Ali Mahdavi-Amiri, and Ghassan Hamarneh. Figo: Fine-grained object counting without annotations.arXiv preprint arXiv:2504.11705, 2025
-
[12]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 91–104, 2025
work page 2025
-
[13]
Digital twin catalog: A large-scale photorealistic 3d object digital twin dataset
Zhao Dong, Ka Chen, Zhaoyang Lv, Hong-Xing Yu, Yunzhi Zhang, Cheng Zhang, Yufeng Zhu, Stephen Tian, Zhengqin Li, Geordie Moffatt, et al. Digital twin catalog: A large-scale photorealistic 3d object digital twin dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 753–763, 2025
work page 2025
-
[14]
Stackcounting dataset: 3d stacked objects with ground-truth count and geometry, 2025
Corentin Dumery, Noa Etté, and Adriano D’Alessandro. Stackcounting dataset: 3d stacked objects with ground-truth count and geometry, 2025
work page 2025
-
[15]
Corentin Dumery, Noa Etté, Aoxiang Fan, Ren Li, Jingyi Xu, Hieu Le, and Pascal Fua. Counting stacked objects. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19774–19783, 2025
work page 2025
-
[16]
Automated counting of stacked objects in industrial inspection.arXiv preprint arXiv:2603.15470, 2026
Corentin Dumery, Noa Etté, Aoxiang Fan, Ren Li, Jingyi Xu, Hieu Le, and Pascal Fua. Automated counting of stacked objects in industrial inspection.arXiv preprint arXiv:2603.15470, 2026
-
[17]
Afreeca: Annotation-free counting for all
Adriano D’Alessandro, Ali Mahdavi-Amiri, and Ghassan Hamarneh. Afreeca: Annotation-free counting for all. InEuropean Conference on Computer Vision, pages 75–91. Springer, 2025. 10
work page 2025
-
[18]
Sagi Eppel. Vastextures: Vast repository of textures and pbr materials extracted from real-world images using unsupervised methods.arXiv preprint arXiv:2406.17146, 2024
-
[19]
Flaccavento, Victor Lempitsky, Iestyn Pope, P
G. Flaccavento, Victor Lempitsky, Iestyn Pope, P. R. Barber, Andrew Zisserman, J. Alison Noble, and B. V ojnovic. Learning to count cells: applications to lens-free imaging of large fields. InMicroscopic Image Analysis with Applications in Biology, 2011
work page 2011
-
[20]
Marc-André Gardner, Kalyan Sunkavalli, Ersin Yumer, Xiaohui Shen, Emiliano Gambaretto, Christian Gagné, and Jean-François Lalonde. Learning to predict indoor illumination from a single image.ACM Transactions on Graphics (TOG), 36(6):1–14, 2017
work page 2017
-
[21]
Kubric: A scalable dataset generator
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, et al. Kubric: A scalable dataset generator. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3749–3761, 2022
work page 2022
-
[22]
Yue Guo, Oleh Krupa, Jason Stein, Guorong Wu, and Ashok Krishnamurthy. Sau-net: A unified network for cell counting in 2d and 3d microscopy images.IEEE/ACM transactions on computational biology and bioinformatics, 19(4):1920–1932, 2021
work page 1920
-
[23]
Abc easy as 123: A blind counter for exemplar-free multi- class class-agnostic counting
Michael Hobley and Victor Prisacariu. Abc easy as 123: A blind counter for exemplar-free multi- class class-agnostic counting. InEuropean Conference on Computer Vision, pages 304–319. Springer, 2024
work page 2024
-
[24]
Countex: Fine-grained counting via exemplars and exclusion.arXiv preprint arXiv:2602.19432, 2026
Yifeng Huang, Gia Khanh Nguyen, and Minh Hoai. Countex: Fine-grained counting via exemplars and exclusion.arXiv preprint arXiv:2602.19432, 2026
-
[25]
Bcdata: A large-scale dataset and benchmark for cell detection and counting
Zhongyi Huang, Yao Ding, Guoli Song, Lin Wang, Ruizhe Geng, Hongliang He, Shan Du, Xia Liu, Yonghong Tian, Yongsheng Liang, et al. Bcdata: A large-scale dataset and benchmark for cell detection and counting. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 289–298. Springer, 2020
work page 2020
-
[26]
Countnet3d: A 3d computer vision approach to infer counts of occluded objects
Porter Jenkins, Kyle Armstrong, Stephen Nelson, Siddhesh Gotad, J Stockton Jenkins, Wade Wilkey, and Tanner Watts. Countnet3d: A 3d computer vision approach to infer counts of occluded objects. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3008–3017, 2023
work page 2023
-
[27]
Clip-count: Towards text-guided zero-shot object counting
Ruixiang Jiang, Lingbo Liu, and Changwen Chen. Clip-count: Towards text-guided zero-shot object counting. InProceedings of the 31st ACM International Conference on Multimedia, pages 4535–4545, 2023
work page 2023
-
[28]
Ivana Kaji´c, Olivia Wiles, Isabela Albuquerque, Matthias Bauer, Su Wang, Jordi Pont-Tuset, and Aida Nematzadeh. Evaluating numerical reasoning in text-to-image models.Advances in neural information processing systems, 38, 2024
work page 2024
-
[29]
The caltech fish counting dataset: A benchmark for multiple-object tracking and counting
Justin Kay, Peter Kulits, Suzanne Stathatos, Siqi Deng, Erik Young, Sara Beery, Grant Van Horn, and Pietro Perona. The caltech fish counting dataset: A benchmark for multiple-object tracking and counting. InEuropean Conference on Computer Vision, pages 290–311. Springer, 2022
work page 2022
-
[30]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
work page 2023
-
[31]
Automated object counting for visual inspection applications
Aniket A Khule, Manoj S Nagmode, and Rajkumar D Komati. Automated object counting for visual inspection applications. In2015 International Conference on Information Processing (ICIP), pages 801–806. IEEE, 2015
work page 2015
-
[32]
Byeong Su Kim, Jieun Kim, Deokwoo Lee, and Beakcheol Jang. Visual question answering: A survey of methods, datasets, evaluation, and challenges.ACM Computing Surveys, 57(10):1–35, 2025
work page 2025
-
[33]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014. 11
work page 2014
-
[34]
Countr: Transformer-based generalised visual counting.arXiv preprint arXiv:2208.13721, 2022
Chang Liu, Yujie Zhong, Andrew Zisserman, and Weidi Xie. Countr: Transformer-based generalised visual counting.arXiv preprint arXiv:2208.13721, 2022
-
[35]
Countse: Soft exemplar open-set object counting
Shuai Liu, Peng Zhang, Shiwei Zhang, and Wei Ke. Countse: Soft exemplar open-set object counting. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21536–21546, 2025
work page 2025
-
[36]
Weizhe Liu, Mathieu Salzmann, and Pascal Fua. Context-aware crowd counting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5099–5108, 2019
work page 2019
-
[37]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoor- thi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021
work page 2021
-
[38]
Omnicount: Multi-label object counting with semantic-geometric priors
Anindya Mondal, Sauradip Nag, Xiatian Zhu, and Anjan Dutta. Omnicount: Multi-label object counting with semantic-geometric priors. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 19537–19545, 2025
work page 2025
-
[39]
A large contextual dataset for classification, detection and counting of cars with deep learning
T Nathan Mundhenk, Goran Konjevod, Wesam A Sakla, and Kofi Boakye. A large contextual dataset for classification, detection and counting of cars with deep learning. InEuropean conference on computer vision, pages 785–800. Springer, 2016
work page 2016
-
[40]
Can current ai models count what we mean, not what they see? a benchmark and systematic evaluation
Gia Khanh Nguyen, Yifeng Huang, and Minh Hoai. Can current ai models count what we mean, not what they see? a benchmark and systematic evaluation. In2025 International Conference on Digital Image Computing: Techniques and Applications (DICTA), pages 1–8. IEEE, 2025
work page 2025
-
[41]
Few-shot object counting and detection
Thanh Nguyen, Chau Pham, Khoi Nguyen, and Minh Hoai. Few-shot object counting and detection. InEuropean Conference on Computer Vision, pages 348–365. Springer, 2022
work page 2022
-
[42]
Situate–synthetic object counting dataset for vlm training
René Peinl, Vincent Tischler, Patrick Schröder, and Christian Groth. Situate–synthetic object counting dataset for vlm training. In21st International Conference on Computer Vision Theory and Applications, 2026
work page 2026
-
[43]
Dave - a detect-and-verify paradigm for low-shot counting
Jer Pelhan, Alan Lukežic, Vitjan Zavrtanik, and Matej Kristan. Dave - a detect-and-verify paradigm for low-shot counting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23293–23302, June 2024
work page 2024
-
[44]
Generalized-scale object counting with gradual query aggregation
Jer Pelhan, Alan Lukežiˇc, and Matej Kristan. Generalized-scale object counting with gradual query aggregation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 8314–8321, 2026
work page 2026
-
[45]
Jer Pelhan, Alan Lukežiˇc, Vitjan Zavrtanik, and Matej Kristan. A novel unified architecture for low-shot counting by detection and segmentation.Advances in Neural Information Processing Systems, 37:66260–66282, 2024
work page 2024
-
[46]
Cell counting.Current protocols in cytometry, (1):A–3A, 1997
Mary C Phelan and Gretchen Lawler. Cell counting.Current protocols in cytometry, (1):A–3A, 1997
work page 1997
-
[47]
Viresh Ranjan, Hieu Le, and Minh Hoai. Iterative crowd counting. InProceedings of the European conference on computer vision (ECCV), pages 270–285, 2018
work page 2018
-
[48]
Viresh Ranjan, Udbhav Sharma, Thu Nguyen, and Minh Hoai. Learning to count everything. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3394–3403, 2021
work page 2021
-
[49]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InProceedings of the IEEE/CVF international conference on computer vision, pages 10912–10922, 2021
work page 2021
-
[50]
Pushing the frontiers of uncon- strained crowd counting: New dataset and benchmark method
Vishwanath A Sindagi, Rajeev Yasarla, and Vishal M Patel. Pushing the frontiers of uncon- strained crowd counting: New dataset and benchmark method. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1221–1231, 2019. 12
work page 2019
-
[51]
Vishwanath A Sindagi, Rajeev Yasarla, and Vishal M Patel. Jhu-crowd++: Large-scale crowd counting dataset and a benchmark method.IEEE transactions on pattern analysis and machine intelligence, 44(5):2594–2609, 2020
work page 2020
-
[52]
A low-shot object counting network with iterative prototype adaptation
Nikola Ðuki ´c, Alan Lukežiˇc, Vitjan Zavrtanik, and Matej Kristan. A low-shot object counting network with iterative prototype adaptation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18872–18881, 2023
work page 2023
-
[53]
Exploring contextual attribute density in referring expression counting
Zhicheng Wang, Zhiyu Pan, Zhan Peng, Jian Cheng, Liwen Xiao, Wei Jiang, and Zhiguo Cao. Exploring contextual attribute density in referring expression counting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19587–19596, 2025
work page 2025
-
[54]
Tong Wu, Jiarui Zhang, Xiao Fu, Yuxin Wang, Jiawei Ren, Liang Pan, Wayne Wu, Lei Yang, Jiaqi Wang, Chen Qian, et al. Omniobject3d: Large-vocabulary 3d object dataset for realistic perception, reconstruction and generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 803–814, 2023
work page 2023
-
[55]
Native and Compact Structured Latents for 3D Generation
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, et al. Native and compact structured latents for 3d generation.arXiv preprint arXiv:2512.14692, 2025
work page internal anchor Pith review arXiv 2025
-
[56]
Structured 3d latents for scalable and versatile 3d generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21469–21480, 2025
work page 2025
-
[57]
Weidi Xie, J Alison Noble, and Andrew Zisserman. Microscopy cell counting and detection with fully convolutional regression networks.Computer methods in biomechanics and biomedical engineering: Imaging & Visualization, 6(3):283–292, 2018
work page 2018
-
[58]
Polyhaven: a curated public asset library for visual effects artists and game designers, 2021
Greg Zaal, Rob Tuytel, Rico Cilliers, James Ray Cock, Andreas Mischok, Sergej Majboroda, Dimitrios Savva, and Jurita Burger. Polyhaven: a curated public asset library for visual effects artists and game designers, 2021
work page 2021
-
[59]
Cross-scene crowd counting via deep convolutional neural networks
Cong Zhang, Hongsheng Li, Xiaogang Wang, and Xiaokang Yang. Cross-scene crowd counting via deep convolutional neural networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 833–841, 2015
work page 2015
-
[60]
Qi Zhang, Yunfei Gong, Zhidan Xie, Zhizi Wang, Antoni B Chan, and Hui Huang. Semi- supervised multi-view crowd counting by ranking multi-view fusion models.arXiv preprint arXiv:2512.16243, 2025
-
[61]
Learning to Count Objects in Natural Images for Visual Question Answering
Yan Zhang, Jonathon Hare, and Adam Prügel-Bennett. Learning to count objects in natural images for visual question answering.arXiv preprint arXiv:1802.05766, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[62]
Yuda Zou, Zijian Zhang, and Yongchao Xu. Decoupling what to count and where to see for referring expression counting. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 14113–14121, 2026. 13 A Additional experiments In this section we present and discuss important additional results which were not added to our main paper due...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.