Beyond the Cartesian Illusion: Testing Two-Stage Multi-Modal Theory of Mind under Perceptual Bottlenecks
Pith reviewed 2026-05-20 10:05 UTC · model grok-4.3
The pith
An anchor-based chain-of-thought lets MLLMs infer another agent's location by respecting that agent's visual and auditory limits rather than assuming a shared coordinate frame.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
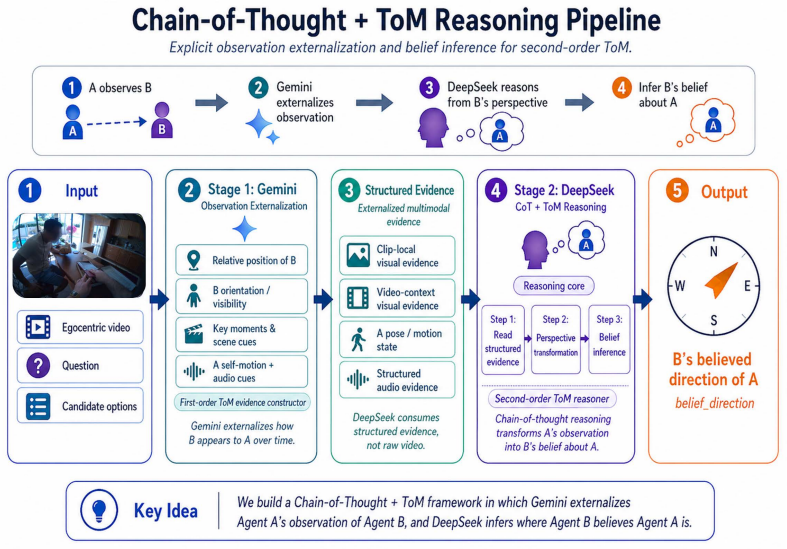
Current MLLMs exhibit a Cartesian Illusion in which they rely on text-derived coordinate assumptions rather than grounded 3D topology; a novel audio-visual task exposes this limit by requiring one agent to predict another's estimate of its own position under strict physical orientation and sensory constraints. The Epistemic Sensory Bottleneck module replaces rule-based transformations with an Anchor-Based Embodied Spatial Decomposition Chain-of-Thought that first establishes the other agent's local coordinate system and then dynamically weights visual versus auditory evidence according to whether the target lies inside the visual frustum. Systematic benchmarks establish a 42 percent zeroShot
What carries the argument
Anchor-Based Embodied Spatial Decomposition Chain-of-Thought that first fixes the other agent's local frame and then projects geometry into semantic modality weights based on frustum membership.
If this is right
- Models using the sensory-bounded chain reach higher accuracy than egocentric or allocentric baselines on the two-agent location task.
- Current MLLMs remain limited by inability to handle spatial symmetry and out-of-view cases, as shown by the 42 percent baseline.
- The two-stage approach supplies a concrete method for building epistemic and modality-aware inference into embodied agents.
Where Pith is reading between the lines
- The same projection step could be tested on tasks where agents must predict beliefs about hidden objects rather than locations.
- If the method scales, it suggests a route to multi-agent planning that avoids global maps altogether.
- Real-world robot deployments would show whether the frustum-based modality switch survives sensor noise and calibration error.
Load-bearing premise
The new audio-visual task truly isolates second-order Theory of Mind governed only by physical orientation and sensory limits, and forcing the geometric-to-semantic projection through the proposed chain-of-thought will let models escape text-based coordinate habits without any explicit rules.
What would settle it
Running the same task on the same models with and without the anchor-based chain-of-thought and finding that the accuracy gap disappears or reverses.
Figures








read the original abstract
While Multi-Modal Large Language Models (MLLMs) demonstrate impressive capabilities in general reasoning, their embodied spatial intelligence remains hampered by a "Cartesian Illusion" - a reliance on text-based probability distributions that lack grounded, 3D topological understanding. This limitation is starkly exposed in multi-agent environments, which demand more than just scene perception; they require second-order Theory of Mind (ToM). Specifically, an Agent A must be able to infer Agent B's belief about the environment, governed strictly by Agent B's physical orientation and sensory limitations. In this paper, we probe the limits of two-stage spatial inference in MLLMs through a novel audio-visual task: requiring Agent A to predict Agent B's estimation of A's relative location. To solve this, we propose an Epistemic Sensory Bottleneck module that abandons rigid, rule-based coordinate transformations. Instead, we introduce an Anchor-Based Embodied Spatial Decomposition Chain-of-Thought (CoT). This guides the MLLM through a "geometric-to-semantic" projection, forcing it to first establish B's local coordinate system and then dynamically weight visual and auditory modalities based on whether A falls within B's visual frustum. Extensive evaluations reveal that while current MLLMs fundamentally struggle with spatial symmetry and out-of-view ambiguities (establishing a rigorous zero-shot baseline of 42% accuracy), our sensory-bounded reasoning chain robustly outperforms pure egocentric and allocentric baselines. By systematically benchmarking these perceptual bottlenecks, our work exposes the current limits of MLLM spatial reasoning and establishes a foundational paradigm for epistemic, modality-aware inference in Embodied AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that MLLMs exhibit a 'Cartesian Illusion' limiting their embodied spatial intelligence, particularly in second-order Theory of Mind tasks where one agent must infer another's beliefs based on physical orientation and sensory limits. To address this, it introduces an Epistemic Sensory Bottleneck module with an Anchor-Based Embodied Spatial Decomposition Chain-of-Thought (CoT) that performs a geometric-to-semantic projection: first establishing the other agent's local coordinate system, then weighting visual and auditory modalities according to whether the target falls in the visual frustum. On a novel audio-visual task, this yields robust outperformance over pure egocentric and allocentric baselines, against a 42% zero-shot baseline, and positions the approach as a foundational paradigm for epistemic, modality-aware inference in Embodied AI.
Significance. If the empirical gains are shown to arise from genuine modality-aware epistemic reasoning rather than prompt structure, the work would usefully expose current MLLM weaknesses in handling spatial symmetry and out-of-view cases while offering a concrete prompting template for perceptual-bottleneck reasoning. The absence of machine-checked proofs or parameter-free derivations means the significance rests entirely on the strength of the experimental validation.
major comments (2)
- Abstract: the claim that the Anchor-Based Embodied Spatial Decomposition CoT 'abandons rigid, rule-based coordinate transformations' is load-bearing for the central contribution, yet the description states that the CoT 'guides the MLLM through a geometric-to-semantic projection' by first 'establish[ing] B's local coordinate system' and then 'dynamically weight[ing] visual and auditory modalities based on whether A falls within B's visual frustum'. These steps necessarily require explicit instructions inside the prompt; if present, the method has not abandoned rule-based transformations but has verbalized them. This directly threatens the interpretation that outperformance reflects emergent epistemic reasoning rather than added prompt scaffolding.
- Abstract: the reported 42% zero-shot baseline and outperformance are presented without any mention of dataset size, number of trials, statistical tests, controls for prompt sensitivity, or the precise construction of out-of-view cases. Because these details are required to substantiate the claim that the sensory-bounded reasoning chain 'robustly outperforms' baselines, their absence renders the central empirical result difficult to evaluate and therefore load-bearing for the paper's conclusions.
minor comments (2)
- The term 'Cartesian Illusion' is introduced in the abstract without a concise definition or pointer to prior literature on spatial or coordinate biases in language models.
- The full prompt template for the Anchor-Based Embodied Spatial Decomposition CoT should be provided verbatim (or as an appendix) to permit exact reproduction and to allow readers to assess how much explicit geometric instruction it contains.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help clarify the presentation of our central claims and empirical results. We respond to each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: the claim that the Anchor-Based Embodied Spatial Decomposition CoT 'abandons rigid, rule-based coordinate transformations' is load-bearing for the central contribution, yet the description states that the CoT 'guides the MLLM through a geometric-to-semantic projection' by first 'establish[ing] B's local coordinate system' and then 'dynamically weight[ing] visual and auditory modalities based on whether A falls within B's visual frustum'. These steps necessarily require explicit instructions inside the prompt; if present, the method has not abandoned rule-based transformations but has verbalized them. This directly threatens the interpretation that outperformance reflects emergent epistemic reasoning rather than added prompt scaffolding.
Authors: We appreciate the referee highlighting this potential ambiguity in our wording. The phrase 'abandons rigid, rule-based coordinate transformations' was meant to distinguish our approach from methods that apply fixed external geometric formulas or numerical computations detached from the model's reasoning. Our CoT instead uses natural-language guidance to prompt the MLLM to internally perform a geometric-to-semantic projection that incorporates sensory limits. We acknowledge, however, that the steps are explicitly described in the prompt and could be viewed as verbalized structure. To resolve this, we will revise the abstract to state that the method 'replaces rigid coordinate transformations with an Anchor-Based Embodied Spatial Decomposition Chain-of-Thought that guides a geometric-to-semantic projection' and will explicitly note that the gains arise from structured, modality-aware prompting rather than purely emergent behavior. This revision will be made in the next version. revision: yes
-
Referee: Abstract: the reported 42% zero-shot baseline and outperformance are presented without any mention of dataset size, number of trials, statistical tests, controls for prompt sensitivity, or the precise construction of out-of-view cases. Because these details are required to substantiate the claim that the sensory-bounded reasoning chain 'robustly outperforms' baselines, their absence renders the central empirical result difficult to evaluate and therefore load-bearing for the paper's conclusions.
Authors: We agree that the abstract, constrained by length, omits key methodological details necessary for evaluating the empirical claims. The full manuscript describes the dataset construction, the generation of out-of-view cases through controlled variations in agent orientation and sensory frusta, the number of evaluation scenarios, and the use of multiple trials with controls for prompt sensitivity. Statistical comparisons are reported in the Experiments section. To address the referee's concern, we will revise the abstract to briefly reference the evaluation scale and direct readers to the detailed protocol and statistical analysis in the main text. This will make the robustness of the outperformance clearer without expanding the abstract beyond reasonable limits. revision: partial
Circularity Check
No significant circularity: novel CoT prompting technique is self-contained
full rationale
The paper introduces an Anchor-Based Embodied Spatial Decomposition Chain-of-Thought (CoT) as a prompting structure for MLLMs to perform second-order Theory of Mind inference under sensory bottlenecks. The abstract explicitly frames the contribution as a new module that 'abandons rigid, rule-based coordinate transformations' in favor of guiding the model through a 'geometric-to-semantic projection' that establishes a local coordinate system and weights modalities by visual frustum. No equations, fitted parameters, or mathematical derivations are described that reduce to prior results by construction. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing premises. The evaluation compares performance on a novel audio-visual task against egocentric and allocentric baselines, but the central claim rests on the empirical effectiveness of the prompting method itself rather than any tautological reduction. The derivation chain is therefore self-contained as an empirical prompting proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MLLMs can follow a geometric-to-semantic projection when guided by the proposed CoT to establish an agent's local coordinate system and dynamically weight modalities
invented entities (2)
-
Epistemic Sensory Bottleneck module
no independent evidence
-
Anchor-Based Embodied Spatial Decomposition Chain-of-Thought (CoT)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce an Anchor-Based Embodied Spatial Decomposition Chain-of-Thought (CoT). This guides the MLLM through a 'geometric-to-semantic' projection, forcing it to first establish B’s local coordinate system and then dynamically weight visual and auditory modalities based on whether A falls within B’s visual frustum.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
our sensory-bounded reasoning chain robustly outperforms pure egocentric and allocentric baselines
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4.arXiv preprint arXiv:2303.12712,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Mingfei Chen, Zijun Cui, Xiulong Liu, Jinlin Xiang, Caleb Zheng, Jingyuan Li, and Eli Shlizerman. Savvy: Spatial awareness via audio-visual llms through seeing and hearing.arXiv preprint arXiv:2506.05414,
-
[3]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zou. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models.arXiv preprint arXiv:2311.07919,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Ast: Audio spectrogram transformer,
Yuan Gong, Yu-An Chung, and James Glass. Ast: Audio spectrogram transformer.arXiv preprint arXiv:2104.01778,
-
[5]
An Embodied Generalist Agent in 3D World
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, and Siyuan Huang. An embodied generalist agent in 3d world. arXiv preprint arXiv:2311.12871,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Revisiting the evaluation of theory of mind through question answering
Matthew Le, Y-Lan Boureau, and Maximilian Nickel. Revisiting the evaluation of theory of mind through question answering. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5872–5877,
work page 2019
-
[7]
Drew Linsley, Peisen Zhou, Alekh Karkada Ashok, Akash Nagaraj, Gaurav Gaonkar, Francis E Lewis, Zygmunt Pizlo, and Thomas Serre. The 3d-pc: a benchmark for visual perspective taking in humans and machines.arXiv preprint arXiv:2406.04138,
-
[8]
Social iqa: Common- sense reasoning about social interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. Social iqa: Common- sense reasoning about social interactions. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing,
work page 2019
-
[9]
Neural theory-of-mind? on the limits of social intelligence in large lms
Maarten Sap, Ronan Le Bras, Daniel Fried, and Yejin Choi. Neural theory-of-mind? on the limits of social intelligence in large lms. InProceedings of the 2022 conference on empirical methods in natural language processing, pages 3762–3780,
work page 2022
-
[10]
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. arXiv preprint arXiv:2310.11324,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Tomer Ullman. Large language models fail on trivial alterations to theory-of-mind tasks.arXiv preprint arXiv:2302.08399,
-
[12]
Pano-avqa: Grounded audio-visual question answering on 360deg videos
Heeseung Yun, Youngjae Yu, Wonsuk Yang, Kangil Lee, and Gunhee Kim. Pano-avqa: Grounded audio-visual question answering on 360deg videos. InProceedings of the IEEE/CVF international conference on computer vision, pages 2031–2041,
work page 2031
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.