SRC-Flow: Compact Semantic Representations Enable Normalizing Flows for Image Generation
Pith reviewed 2026-05-20 11:56 UTC · model grok-4.3
The pith
Compressing high-dimensional image features into a compact semantic space lets normalizing flows generate detailed images while retaining exact likelihood computation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SRC-Flow inserts a Semantic Representation Compressor between a pre-trained representation encoder and the normalizing flow so that the flow learns its invertible transport only in the resulting low-dimensional semantic space; the original decoder then reconstructs high-fidelity images from flow-generated semantic codes.
What carries the argument
The Semantic Representation Compressor (SRC), which maps high-dimensional RAE features into a lower-dimensional semantic space while preserving reconstructibility through the frozen decoder.
If this is right
- Exact likelihoods become available directly in the semantic space rather than in pixel space.
- Sampling remains deterministic and invertible at the flow stage.
- Generation quality among normalizing-flow methods improves on ImageNet 256 by 256 and 512 by 512 resolutions while classifier-free guidance remains usable.
Where Pith is reading between the lines
- The same compression step could be tested with other invertible models that currently struggle with high-dimensional inputs.
- Jointly training the compressor with the flow might further reduce the dimensionality needed for good performance.
- Similar semantic bottlenecks could be inserted into other latent-variable generative models to ease their modeling load.
Load-bearing premise
High-dimensional visual features can be compressed into a low-dimensional semantic space without losing the information required for the frozen decoder to reconstruct high-fidelity images.
What would settle it
Generate images with the flow in the compressed space and measure whether reconstruction error or perceptual quality falls substantially below the reported levels when the same decoder is used on uncompressed features.
Figures








read the original abstract
Normalizing flows (NFs) provide exact likelihoods and deterministic invertible sampling, but have historically lagged behind diffusion models for large-scale image generation. We identify a key obstacle: NFs are required to learn a single invertible transport over the full ambient space, making them highly sensitive to high-dimensional representations. This leads to a semantic-capacity mismatch in modern visual representation spaces, where semantic information is compact but encoded in overcomplete features. We propose SRC-Flow, which introduces a Semantic Representation Compressor (SRC) to compact high-dimensional RAE features into a low-dimensional semantic space before flow modeling and preserve reconstruction through the frozen RAE decoder. This compact space reduces the modeling burden of NFs and enables effective likelihood-based generation in semantic representation space. We further adopt constant noise regularization tailored to the fixed unconditional bijection learned by flows. On ImageNet $256 \times 256$ and $512 \times 512$, SRC-Flow achieves state-of-the-art generation quality among normalizing flow methods, with gFID scores of 1.65 and 2.07 under classifier-free guidance, while retaining exact likelihood computation in the compact semantic representation space and deterministic invertible sampling at the flow level. Codes and models will be available at https://github.com/longtaojiang/SRC-Flow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SRC-Flow, which introduces a Semantic Representation Compressor (SRC) to map high-dimensional RAE features into a compact low-dimensional semantic space for subsequent normalizing flow modeling. This is claimed to resolve the semantic-capacity mismatch that has limited NFs on large-scale images, enabling exact likelihood computation in the compressed space and deterministic invertible sampling. On ImageNet 256×256 and 512×512, the method reports state-of-the-art gFID scores of 1.65 and 2.07 among normalizing flow approaches under classifier-free guidance, while using constant noise regularization tailored to the fixed unconditional bijection.
Significance. If the empirical results and the lossless-compression assumption hold, the work would meaningfully advance normalizing flows toward competitiveness with diffusion models on high-resolution image generation. Retaining exact likelihoods and invertibility in a compact semantic space is a substantive technical contribution, and the constant-noise regularization represents a practical adaptation worth further exploration.
major comments (3)
- [Abstract and §3.1] Abstract and §3.1: The central claim that flow samples decoded by the frozen RAE decoder achieve the reported gFID scores rests on the assumption that SRC compression incurs negligible information loss. No quantitative bound on reconstruction fidelity (e.g., PSNR or LPIPS between original RAE features and SRC-reconstructed features prior to flow modeling) is supplied, leaving open the possibility that discarded high-frequency details degrade final image quality.
- [§5 Experiments] §5 Experiments: Strong gFID numbers are presented, yet the manuscript supplies no ablation studies isolating the SRC dimensionality, loss terms, or regularization strength, nor any statistical significance tests or multiple-run variance. Without these, it is impossible to attribute the gains specifically to the proposed compressor rather than unstated training choices or baseline differences.
- [§4.2] §4.2: The constant noise regularization is introduced to accommodate the fixed unconditional bijection, but the text does not derive or verify that this modification preserves the exact likelihood property of the flow; a short proof or explicit likelihood expression under the regularized objective would strengthen the claim.
minor comments (2)
- [Abstract] Abstract: The acronym 'gFID' is introduced without definition; clarify whether it denotes a guided variant of FID or another metric.
- [Throughout] Throughout: Ensure first-use definitions for RAE, SRC, and NF; the current presentation assumes familiarity that may not hold for all readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the opportunity to improve our manuscript. We address each major comment point by point below, and we will incorporate the suggested changes in the revised version.
read point-by-point responses
-
Referee: [Abstract and §3.1] Abstract and §3.1: The central claim that flow samples decoded by the frozen RAE decoder achieve the reported gFID scores rests on the assumption that SRC compression incurs negligible information loss. No quantitative bound on reconstruction fidelity (e.g., PSNR or LPIPS between original RAE features and SRC-reconstructed features prior to flow modeling) is supplied, leaving open the possibility that discarded high-frequency details degrade final image quality.
Authors: We appreciate the referee's point regarding the need for quantitative validation of the compression fidelity. Although the high gFID scores and visual quality of generated images suggest effective preservation of semantic information, we agree that explicit metrics would strengthen the claim. In the revised manuscript, we will report PSNR and LPIPS values between the original RAE features and the SRC-reconstructed features to provide a quantitative bound on any information loss. revision: yes
-
Referee: [§5 Experiments] §5 Experiments: Strong gFID numbers are presented, yet the manuscript supplies no ablation studies isolating the SRC dimensionality, loss terms, or regularization strength, nor any statistical significance tests or multiple-run variance. Without these, it is impossible to attribute the gains specifically to the proposed compressor rather than unstated training choices or baseline differences.
Authors: We thank the referee for this suggestion. To more rigorously demonstrate the contribution of the SRC, we will include additional ablation experiments in the revised version. These will vary the dimensionality of the semantic space, the weighting of loss terms, and the strength of the constant noise regularization. Furthermore, we will conduct multiple training runs with different random seeds and report mean gFID scores along with standard deviations to provide statistical context. revision: yes
-
Referee: [§4.2] §4.2: The constant noise regularization is introduced to accommodate the fixed unconditional bijection, but the text does not derive or verify that this modification preserves the exact likelihood property of the flow; a short proof or explicit likelihood expression under the regularized objective would strengthen the claim.
Authors: We agree that a formal justification is valuable. The constant noise regularization is designed such that it does not alter the bijective nature of the flow transformation. The likelihood computation remains exact via the change-of-variables formula, where the regularization affects the base distribution in a fixed manner. In the revision, we will add a brief derivation and the explicit expression for the log-likelihood under this regularized setup to confirm preservation of exact likelihoods. revision: yes
Circularity Check
No circularity; empirical results rest on independent training and evaluation
full rationale
The paper's derivation introduces an SRC compressor trained to map RAE features to a lower-dimensional space, followed by standard normalizing-flow training in that space with a frozen decoder for reconstruction. Reported gFID scores on ImageNet are direct empirical measurements against external baselines, not quantities defined in terms of fitted parameters or prior self-citations within the same equations. No self-definitional loops, fitted-input predictions, or ansatz smuggling appear in the method description; the central claims remain falsifiable via the stated metrics and do not reduce to tautological redefinitions of the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RAE features contain semantic information that remains sufficient for high-quality reconstruction after compression to a low-dimensional space and subsequent flow modeling.
invented entities (1)
-
Semantic Representation Compressor (SRC)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose SRC-Flow, which introduces a Semantic Representation Compressor (SRC) to compact high-dimensional RAE features into a low-dimensional semantic space before flow modeling
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
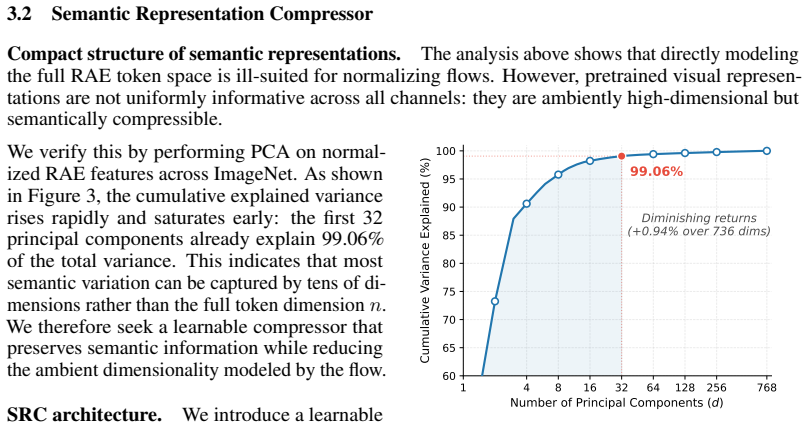
the first 32 principal components already explain 99.06% of the total variance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Variational inference with normalizing flows,
D. Rezende and S. Mohamed, “Variational inference with normalizing flows,” inICML, 2015
work page 2015
-
[2]
Density estimation using real-nvp,
L. Dinh, J. Sohl-Dickstein, and S. Bengio, “Density estimation using real-nvp,” inICLR, 2017
work page 2017
-
[3]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inNeurIPS, 2020
work page 2020
-
[4]
Score-based generative modeling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” inICLR, 2021
work page 2021
-
[5]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inICLR, 2021
work page 2021
-
[6]
Elucidating the design space of diffusion-based generative models,
T. Karras, M. Aittala, T. Aila, and S. Laine, “Elucidating the design space of diffusion-based generative models,” inNeurIPS, 2022
work page 2022
-
[7]
Normalizing flows are capable generative models,
S. Zhai, R. Zhang, P. Nakkiran, D. Berthelot, J. Gu, H. Zheng, T. Chen, M. A. Bautista, N. Jaitly, and J. Susskind, “Normalizing flows are capable generative models,”arXiv preprint arXiv:2412.06329, 2024
-
[8]
Starflow: Scaling latent normalizing flows for high-resolution image synthesis,
J. Gu, T. Chen, D. Berthelot, H. Zheng, Y . Wang, R. Zhang, L. Dinh, M. A. Bautista, J. Susskind, and S. Zhai, “Starflow: Scaling latent normalizing flows for high-resolution image synthesis,” arXiv preprint arXiv:2506.06276, 2025
-
[9]
Simflow: Simplified and end-to-end training of latent normalizing flows,
Q. Zhao, G. Zheng, T. Yang, R. Zhu, X. Leng, S. Gould, and L. Zheng, “Simflow: Simplified and end-to-end training of latent normalizing flows,”arXiv preprint arXiv:2512.04084, 2025
-
[10]
Normalizing Flows with Iterative Denoising
T. Chen, J. Gu, D. Berthelot, J. Susskind, and S. Zhai, “Normalizing flows with iterative denoising,”arXiv preprint arXiv:2604.20041, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Diffusion Transformers with Representation Autoencoders
B. Zheng, N. Ma, S. Tong, and S. Xie, “Diffusion transformers with representation autoencoders,” arXiv preprint arXiv:2510.11690, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanniet al., “Dinov2: Learning robust visual features without supervision,”Transactions on Machine Learning Research, 2024
work page 2024
-
[13]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inICCV, 2021
work page 2021
-
[14]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y . Levi, D. Lorber, A. Sauer, F. Boeselet al., “Scaling rectified flow transformers for high-resolution image synthesis,” in ICML, 2024
work page 2024
-
[15]
Diffusion models beat GANs on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat GANs on image synthesis,” inNeurIPS, 2021
work page 2021
-
[16]
Scalable adaptive computation for iterative generation
A. Jabri, D. Fleet, and T. Chen, “Scalable adaptive computation for iterative generation,”arXiv preprint arXiv:2212.11972, 2022
-
[17]
arXiv preprint arXiv:2504.07963 (2025)
S. Chen, C. Ge, S. Zhang, P. Sun, and P. Luo, “Pixelflow: Pixel-space generative models with flow,”arXiv preprint arXiv:2504.07963, 2025
-
[18]
Pixnerd: Pixel neural field diffusion.arXiv preprint arXiv:2507.23268, 2025
S. Wang, Z. Gao, C. Zhu, W. Huang, and L. Wang, “Pixnerd: Pixel neural field diffusion,”arXiv preprint arXiv:2507.23268, 2025
-
[19]
Simpler diffusion (SiD2): 1.5 FID on ImageNet512 with pixel-space diffusion,
E. Hoogeboom, T. Mensink, J. Heek, K. Lamerigts, R. Gao, and T. Salimans, “Simpler diffusion (SiD2): 1.5 FID on ImageNet512 with pixel-space diffusion,”arXiv preprint arXiv:2410.19324, 2024
-
[20]
M. Tschannen, A. Susano Pinto, and A. Kolesnikov, “Jetformer: An autoregressive generative model of raw images and text,”arXiv preprint arXiv:2411.19722, 2024
-
[21]
FARMER: Flow autoregressive transformer over pixels.arXiv preprint arXiv:2510.23588, 2025
G. Zheng, Q. Zhao, T. Yang, F. Xiao, Z. Lin, J. Wu, J. Deng, Y . Zhang, and R. Zhu, “FARMER: Flow autoregressive transformer over pixels,”arXiv preprint arXiv:2510.23588, 2025
-
[22]
2024.doi:10.48550/arXiv.2404.02905
K. Tian, Y . Jiang, Z. Yuan, B. Peng, and L. Wang, “Visual autoregressive modeling: Scalable image generation via next-scale prediction,”arXiv preprint arXiv:2404.02905, 2024
-
[23]
Autoregres- sive image generation without vector quantization.arXiv preprint arXiv:2406.11838,
T. Li, Y . Tian, H. Li, M. Deng, and K. He, “Autoregressive image generation without vector quantization,”arXiv preprint arXiv:2406.11838, 2024
-
[24]
S. Ren, Q. Yu, J. He, X. Shen, A. Yuille, and L.-C. Chen, “Beyond next-token: Next-x prediction for autoregressive visual generation,”arXiv preprint arXiv:2502.20388, 2025
-
[25]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inICCV, 2023. 10
work page 2023
- [26]
-
[27]
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers
N. Ma, M. Goldstein, M. S. Albergo, N. M. Boffi, E. Vanden-Eijnden, and S. Xie, “Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers,” arXiv preprint arXiv:2401.08740, 2024
-
[28]
S. Gao, P. Zhou, M.-M. Cheng, and S. Yan, “MDTv2: Masked diffusion transformer is a strong image synthesizer,”arXiv preprint arXiv:2303.14389, 2023
-
[29]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
S. Yu, S. Kwon, N. R. Shin, J. Suh, J. Yoonet al., “Representation alignment for generation: Training diffusion transformers is easier than you think,”arXiv preprint arXiv:2410.06940, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models,
J. Yao, B. Yang, and X. Wang, “Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models,” inCVPR, 2025
work page 2025
-
[31]
Ddt: Decoupled diffusion transformer.arXiv preprint arXiv:2504.05741, 2025
S. Wang, Z. Tian, W. Huang, and L. Wang, “Decoupled diffusion transformer,”arXiv preprint arXiv:2504.05741, 2025
-
[32]
X. Leng, J. Singh, Y . Hou, Z. Xing, S. Xie, and L. Zheng, “REPA-E: Unlocking V AE for end-to-end tuning with latent diffusion transformers,”arXiv preprint arXiv:2504.10483, 2025
-
[33]
Flowing back- wards: Improving normalizing flows via reverse representation alignment,
Y . Chen, X. Xu, S. Wang, C. Zhu, R. Wen, X. Li, T. Ge, and L. Wang, “Flowing back- wards: Improving normalizing flows via reverse representation alignment,”arXiv preprint arXiv:2511.22345, 2025
-
[34]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” inCVPR, 2009
work page 2009
-
[35]
GANs trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “GANs trained by a two time-scale update rule converge to a local nash equilibrium,” inNeurIPS, 2017
work page 2017
-
[36]
Improved techniques for training GANs,
T. Salimans, I. Goodfellow, W. Zaremba, V . Cheung, A. Radford, and X. Chen, “Improved techniques for training GANs,” inNeurIPS, 2016
work page 2016
-
[37]
Improved precision and recall metric for assessing generative models,
T. Kynkäänniemi, T. Karras, S. Laine, J. Lehtinen, and T. Aila, “Improved precision and recall metric for assessing generative models,” inNeurIPS, 2019
work page 2019
-
[38]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inICLR, 2019
work page 2019
-
[39]
Large scale GAN training for high fidelity natural image synthesis,
A. Brock, J. Donahue, and K. Simonyan, “Large scale GAN training for high fidelity natural image synthesis,” inICLR, 2019
work page 2019
-
[40]
StyleGAN-XL: Scaling StyleGAN to large diverse datasets,
A. Sauer, K. Schwarz, and A. Geiger, “StyleGAN-XL: Scaling StyleGAN to large diverse datasets,” inSIGGRAPH, 2022
work page 2022
-
[41]
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
L. Yu, J. Lezama, N. B. Gundavarapu, L. Versari, K. Sohn, D. Minnen, Y . Cheng, A. Gupta, X. Gu, A. G. Hauptmannet al., “Language model beats diffusion – tokenizer is key to visual generation,”arXiv preprint arXiv:2310.05737, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
DiffiT: Diffusion vision transformers for image generation,
A. Hatamizadeh, J. Song, G. Liu, J. Kautz, and A. Vahdat, “DiffiT: Diffusion vision transformers for image generation,”arXiv preprint arXiv:2312.02139, 2024
-
[43]
Analyzing and improving the training dynamics of diffusion models
T. Karras, M. Aittala, J. Lehtinen, J. Hellsten, T. Aila, and S. Laine, “Analyzing and improving the training dynamics of diffusion models,”arXiv preprint arXiv:2312.02696, 2024
-
[44]
NICE: Non-linear independent components estimation,
L. Dinh, D. Krueger, and Y . Bengio, “NICE: Non-linear independent components estimation,” inICLR Workshop, 2015
work page 2015
-
[45]
Glow: Generative flow with invertible1×1 convolutions,
D. P. Kingma and P. Dhariwal, “Glow: Generative flow with invertible1×1 convolutions,” in NeurIPS, 2018
work page 2018
-
[46]
Masked autoregressive flow for density estima- tion,
G. Papamakarios, T. Pavlakou, and I. Murray, “Masked autoregressive flow for density estima- tion,” inNeurIPS, 2017
work page 2017
-
[47]
Improved variational inference with inverse autoregressive flow,
D. P. Kingma, T. Salimans, R. Jozefowicz, X. Chen, I. Sutskever, and M. Welling, “Improved variational inference with inverse autoregressive flow,” inNeurIPS, 2016
work page 2016
-
[48]
Neural ordinary differential equations,
R. T. Q. Chen, Y . Rubanova, J. Bettencourt, and D. Duvenaud, “Neural ordinary differential equations,” inNeurIPS, 2018
work page 2018
-
[49]
FFJORD: Free-form continuous dynamics for scalable reversible generative models,
W. Grathwohl, R. T. Q. Chen, J. Bettencourt, I. Sutskever, and D. Duvenaud, “FFJORD: Free-form continuous dynamics for scalable reversible generative models,” inICLR, 2019. 11
work page 2019
-
[50]
J. Behrmann, W. Grathwohl, R. T. Q. Chen, D. Duvenaud, and J.-H. Jacobsen, “Invertible residual networks,” inICML, 2019
work page 2019
-
[51]
Residual flows for invertible generative modeling,
R. T. Q. Chen, J. Behrmann, D. K. Duvenaud, and J.-H. Jacobsen, “Residual flows for invertible generative modeling,” inNeurIPS, 2019
work page 2019
-
[52]
C. Durkan, A. Bekasov, I. Murray, and G. Papamakarios, “Neural spline flows,” inNeurIPS, 2019
work page 2019
-
[53]
J. Ho, X. Chen, A. Srinivas, Y . Duan, and P. Abbeel, “Flow++: Improving flow-based generative models with variational dequantization and architecture design,” inICML, 2019
work page 2019
-
[54]
Pixel Recurrent Neural Networks
A. van den Oord, N. Kalchbrenner, and K. Kavukcuoglu, “Pixel recurrent neural networks,” arXiv preprint arXiv:1601.06759, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[55]
Taming transformers for high-resolution image synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high-resolution image synthesis,” inCVPR, 2021
work page 2021
-
[56]
Zero-shot text-to-image generation,
A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. V oss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” inICML, 2021
work page 2021
-
[57]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” inCVPR, 2022
work page 2022
-
[58]
Auto-Encoding Variational Bayes
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,”arXiv preprint arXiv:1312.6114, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[59]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Müller, J. Penna, and R. Rom- bach, “SDXL: Improving latent diffusion models for high-resolution image synthesis,”arXiv preprint arXiv:2307.01952, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Hierarchical Text-Conditional Image Generation with CLIP Latents
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with CLIP latents,”arXiv preprint arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[61]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,”arXiv preprint arXiv:2209.03003, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
EQ-V AE: Equivariance regular- ized latent space for improved generative image modeling,
T. Kouzelis, I. Kakogeorgiou, S. Gidaris, and N. Komodakis, “EQ-V AE: Equivariance regular- ized latent space for improved generative image modeling,” inICML, 2025
work page 2025
-
[64]
M. Tschannenet al., “SigLIP 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features,”arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,” inICLR, 2021
work page 2021
-
[66]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” inCVPR, 2022
work page 2022
-
[67]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervi- sion,” inICML, 2021
work page 2021
-
[68]
arXiv preprint arXiv:2509.25162 (2025) 4
B. Chen, S. Bi, H. Tan, H. Zhang, T. Zhang, Z. Li, Y . Xiong, J. Zhang, and K. Zhang, “Aligning visual foundation encoders to tokenizers for diffusion models,”arXiv preprint arXiv:2509.25162, 2025
-
[69]
Laminating representation autoencoders for efficient diffu- sion,
R. Calvo-González and F. Fleuret, “Laminating representation autoencoders for efficient diffu- sion,”arXiv preprint arXiv:2602.04873, 2026
-
[70]
Improving reconstruction of representation autoencoder.arXiv preprint arXiv:2602.08620, 2026
S. Liu, C. Qin, H. Yin, Q. Yan, Z.-P. Duan, C. Li, J. Lyu, C.-L. Guo, and C. Li, “Improving reconstruction of representation autoencoder,”arXiv preprint arXiv:2602.08620, 2026
-
[71]
S. Zhang, H. Zhang, Z. Zhang, C. Ge, S. Xue, S. Liu, M. Ren, S. Y . Kim, Y . Zhou, Q. Liu, D. Pakhomov, K. Zhang, Z. Lin, and P. Luo, “Both semantics and reconstruction matter: Making representation encoders ready for text-to-image generation and editing,”arXiv preprint arXiv:2512.17909, 2025. 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.