Speech-Guided Multimodal Learning for Vocal Tract Segmentation in Real-Time MRI
Pith reviewed 2026-05-20 11:35 UTC · model grok-4.3
The pith
A three-stage framework uses speech and phonological supervision in training to improve vocal tract segmentation from real-time MRI images alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors propose a three-stage framework that leverages acoustic and phonological supervision during training while requiring only the rtMRI image at inference: phonological representations are converted into spatial bounding-box priors for articulator localization, visual and acoustic encoders are aligned via dual-level cross-modal contrastive pretraining, and the learned representations are fused through a cross-attention decoder, effectively transferring multimodal knowledge into a single-modality inference pipeline. Evaluated on 75-Speaker Annot-16 and USC-TIMIT datasets, the method outperforms existing unimodal and multimodal methods, demonstrating that multimodal supervision can be
What carries the argument
The three-stage training pipeline that converts phonological representations into spatial bounding-box priors, performs dual-level cross-modal contrastive pretraining to align visual and acoustic encoders, and uses a cross-attention decoder to fuse the learned representations for image-only inference.
Load-bearing premise
Phonological representations can be turned into reliable spatial bounding-box priors for articulator locations and the contrastive pretraining produces features that work well when audio is removed at test time.
What would settle it
An ablation on the 75-Speaker Annot-16 or USC-TIMIT test sets that removes the phonological bounding-box priors or the dual-level contrastive pretraining step and finds no gain over strong image-only baselines.
Figures

read the original abstract
Segmenting vocal tract articulators in real-time MRI (rtMRI) is a challenging dynamic image segmentation problem characterized by low contrast, rapid motion, and limited spatial resolution. However, while rtMRI acquisitions may provide synchronized acoustic signals, existing methods discard this information, and the few multimodal approaches that incorporate audio cannot be deployed when audio is unavailable. We propose a three-stage framework that leverages acoustic and phonological supervision during training while requiring only the rtMRI image at inference: phonological representations are converted into spatial bounding-box priors for articulator localization, visual and acoustic encoders are aligned via dual-level cross-modal contrastive pretraining, and the learned representations are fused through a cross-attention decoder, effectively transferring multimodal knowledge into a single-modality inference pipeline. Evaluated on 75-Speaker~Annot-16 and USC-TIMIT datasets, our method outperforms existing unimodal and multimodal methods, demonstrating that multimodal supervision provides transferable benefits for precise and clinically deployable vocal tract segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a three-stage framework for vocal tract articulator segmentation in real-time MRI. Phonological representations are converted to spatial bounding-box priors, visual and acoustic encoders are aligned via dual-level cross-modal contrastive pretraining, and representations are fused in a cross-attention decoder. Training uses audio and phonological supervision, but inference requires only the rtMRI image. The method is evaluated on the 75-Speaker Annot-16 and USC-TIMIT datasets and claims to outperform existing unimodal and multimodal approaches, showing that multimodal supervision yields transferable benefits for precise, clinically deployable segmentation.
Significance. If the reported gains hold under rigorous scrutiny, the work could enable practical deployment of high-accuracy vocal tract segmentation in settings where synchronized audio is unavailable. The combination of phonological priors and contrastive alignment offers a concrete mechanism for transferring multimodal knowledge to single-modality inference, which may generalize to other dynamic medical imaging tasks with missing modalities.
major comments (3)
- [Abstract] Abstract: the central claim that the method 'outperforms existing unimodal and multimodal methods' on the two named datasets is presented without any quantitative metrics, error bars, statistical tests, data-split details, or exclusion criteria. This omission prevents verification of the asserted transferable benefits from multimodal supervision.
- [§3.1] §3.1 (Phonological-to-bounding-box conversion): the framework relies on phonological representations producing reliable spatial priors for articulator localization, yet no validation, accuracy metrics, or sensitivity analysis of these priors is supplied. If the priors are coarse or inaccurate, any observed gains on 75-Speaker Annot-16 and USC-TIMIT could arise from architecture or training schedule rather than the claimed multimodal transfer.
- [§3.2] §3.2 (Dual-level cross-modal contrastive pretraining): the description states that the pretraining aligns encoders so visual features capture audio-derived spatial cues at inference, but no ablation isolating this alignment or analysis confirming retention of motion/position information is provided. This step is load-bearing for the audio-free inference claim.
minor comments (2)
- [Abstract] Abstract: the dataset shorthand '75-Speaker~Annot-16' is non-standard; expand or footnote the full name and citation on first use.
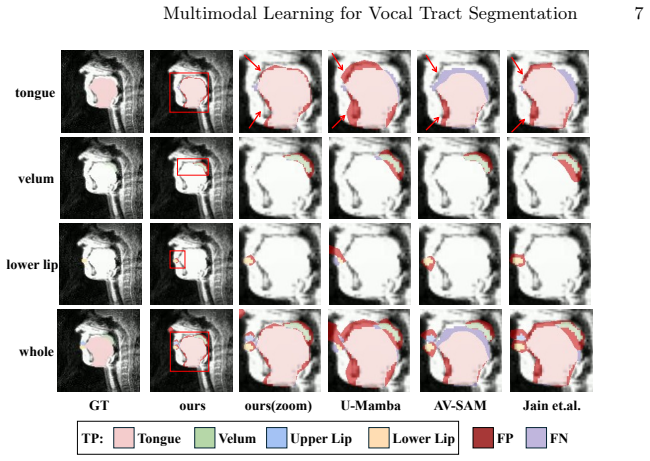
- [Figures/Tables] Figures and tables: ensure all performance tables include standard deviations or confidence intervals and that qualitative segmentation figures include scale bars and error overlays for clinical interpretability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed each major comment and provide point-by-point responses below, outlining how we will strengthen the paper through targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'outperforms existing unimodal and multimodal methods' on the two named datasets is presented without any quantitative metrics, error bars, statistical tests, data-split details, or exclusion criteria. This omission prevents verification of the asserted transferable benefits from multimodal supervision.
Authors: We agree that the abstract would benefit from including key quantitative results to support the performance claims. In the revised version, we will incorporate specific metrics such as mean Dice coefficients and Hausdorff distances with standard deviations for both datasets, along with brief details on the cross-validation splits and exclusion criteria used. This will provide immediate evidence for the reported gains from multimodal supervision. revision: yes
-
Referee: [§3.1] §3.1 (Phonological-to-bounding-box conversion): the framework relies on phonological representations producing reliable spatial priors for articulator localization, yet no validation, accuracy metrics, or sensitivity analysis of these priors is supplied. If the priors are coarse or inaccurate, any observed gains on 75-Speaker Annot-16 and USC-TIMIT could arise from architecture or training schedule rather than the claimed multimodal transfer.
Authors: We acknowledge that explicit validation of the phonological priors is important to isolate their contribution. Although the conversion process is described in §3.1, we did not include quantitative evaluation in the original submission. We will add a dedicated analysis (new figure or appendix) reporting overlap metrics between the generated bounding boxes and ground-truth annotations, plus a sensitivity study varying phonological input granularity to confirm the priors' reliability and role in the multimodal transfer. revision: yes
-
Referee: [§3.2] §3.2 (Dual-level cross-modal contrastive pretraining): the description states that the pretraining aligns encoders so visual features capture audio-derived spatial cues at inference, but no ablation isolating this alignment or analysis confirming retention of motion/position information is provided. This step is load-bearing for the audio-free inference claim.
Authors: We concur that an ablation isolating the dual-level contrastive pretraining is essential to substantiate the audio-free inference mechanism. In the revision, we will include ablation experiments that disable or alter the pretraining stage and quantify the resulting drops in segmentation accuracy on both datasets. We will also add supporting analysis, such as feature similarity visualizations and positional encoding retention checks, to demonstrate that motion and spatial cues are effectively transferred to the visual encoder. revision: yes
Circularity Check
Empirical multimodal ML pipeline exhibits no circularity
full rationale
The paper describes a three-stage empirical framework (phonological bounding-box priors, dual-level cross-modal contrastive pretraining, cross-attention decoder) evaluated on external datasets (75-Speaker Annot-16, USC-TIMIT). No equations, derivations, or load-bearing steps reduce reported gains to fitted parameters, self-citations, or inputs by construction. Performance claims rest on standard train/test splits and comparisons to baselines, rendering the pipeline self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
phonological representations are converted into spatial bounding-box priors... dual-level cross-modal contrastive pretraining... cross-attention decoder
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-stage framework... Stage 1... Stage 2... Stage 3
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Arias-Vergara, T., et al.: Contrastive learning approach for assessment of phono- logical precision in patients with tongue cancer using mri data. In: Interspeech. p. 927 (2024)
work page 2024
-
[2]
Phonetica49(3-4), 155–180 (1992)
Browman, C.P., et al.: Articulatory phonology: An overview. Phonetica49(3-4), 155–180 (1992)
work page 1992
-
[3]
IEEE Journal of Selected Topics in Signal Processing16(6), 1505–1518 (2022)
Chen,S.,etal.:Wavlm:Large-scaleself-supervisedpre-trainingforfullstackspeech processing. IEEE Journal of Selected Topics in Signal Processing16(6), 1505–1518 (2022)
work page 2022
-
[4]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., et al.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
work page 2009
-
[5]
ISPRS Journal of Photogrammetry and Remote Sensing162, 94–114 (2020)
Diakogiannis, F.I., Waldner, F., Caccetta, P., Wu, C.: Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS Journal of Photogrammetry and Remote Sensing162, 94–114 (2020)
work page 2020
-
[6]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
In: Proceedings of the AAAI conference on artificial intelligence
Gao, S., Chen, Z., Chen, G., Wang, W., Lu, T.: Avsegformer: Audio-visual seg- mentation with transformer. In: Proceedings of the AAAI conference on artificial intelligence. vol. 38, pp. 12155–12163 (2024)
work page 2024
-
[8]
In: International Seminar on Speech Production, Cologne, Germany
Hagedorn, C., et al.: Characterizing post-glossectomy speech using real-time mri. In: International Seminar on Speech Production, Cologne, Germany. pp. 170–173 (2014)
work page 2014
-
[9]
In: International MICCAI brainlesion workshop
Hatamizadeh, A., et al.: Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images. In: International MICCAI brainlesion workshop. pp. 272–284. Springer (2021)
work page 2021
-
[10]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
He, K., et al.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
work page 2016
-
[11]
Nature methods18(2), 203–211 (2021)
Isensee, F., et al.: nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods18(2), 203–211 (2021)
work page 2021
-
[12]
Jain, R., et al.: Multimodal segmentation for vocal tract modeling. Interspeech (2024)
work page 2024
-
[13]
In: Proceedings of the IEEE/CVF interna- tional conference on computer vision
Kirillov, A., et al.: Segment anything. In: Proceedings of the IEEE/CVF interna- tional conference on computer vision. pp. 4015–4026 (2023) 10 D. Liu et al
work page 2023
-
[14]
Speech Communication99, 27–46 (2018)
Labrunie, M., et al.: Automatic segmentation of speech articulators from real-time midsagittal mri based on supervised learning. Speech Communication99, 27–46 (2018)
work page 2018
- [15]
-
[16]
In: International Conference on Text, Speech, and Dialogue
Liu, D., et al.: Audio–vision contrastive learning for phonological class recognition. In: International Conference on Text, Speech, and Dialogue. pp. 60–71. Springer (2025)
work page 2025
-
[17]
In: Proceedings of the IEEE/CVF international conference on computer vision
Liu, Z., et al.: Swin transformer: Hierarchical vision transformer using shifted win- dows. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 10012–10022 (2021)
work page 2021
-
[18]
Nature communications15(1), 654 (2024)
Ma, J., et al.: Segment anything in medical images. Nature communications15(1), 654 (2024)
work page 2024
-
[19]
U-Mamba: Enhancing Long-range Dependency for Biomedical Image Segmentation
Ma, J., et al.: U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv preprint arXiv:2401.04722 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Mannem, R., et al.: Air-tissue boundary segmentation in real time magnetic reso- nance imaging video using a convolutional encoder-decoder network. In: ICASSP. pp. 5941–5945. IEEE (2019)
work page 2019
-
[21]
arXiv preprint arXiv:2305.01836 (2023)
Mo, S., Tian, Y.: Av-sam: Segment anything model meets audio-visual localization and segmentation. arXiv preprint arXiv:2305.01836 (2023)
-
[22]
The Journal of the Acoustical Society of America136(3), 1307–1311 (2014)
Narayanan, S., et al.: Real-time magnetic resonance imaging and electromagnetic articulography database for speech production research (tc). The Journal of the Acoustical Society of America136(3), 1307–1311 (2014)
work page 2014
-
[23]
Representation Learning with Contrastive Predictive Coding
Oord, A.v.d., Li, Y., Vinyals, O.: Representation learning with contrastive predic- tive coding. arXiv preprint arXiv:1807.03748 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Advances in neural information processing systems32(2019)
Paszke, A., et al.: Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems32(2019)
work page 2019
-
[26]
Computer Speech & Language52, 1–22 (2018)
Ramanarayanan, V., et al.: Analysis of speech production real-time mri. Computer Speech & Language52, 1–22 (2018)
work page 2018
-
[27]
In: International Conference on Medical image computing and computer-assisted intervention
Ronneberger, O., et al.: U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. pp. 234–241. Springer (2015)
work page 2015
-
[28]
Computer Methods and Programs in Biomedicine198, 105814 (2021)
Ruthven, M., et al.: Deep-learning-based segmentation of the vocal tract and ar- ticulators in real-time magnetic resonance images of speech. Computer Methods and Programs in Biomedicine198, 105814 (2021)
work page 2021
-
[29]
Shi,X.,etal.:75-speakerannot-16: Abenchmarkdatasetforspeecharticulatory rt- mriannotationwitharticulatorcontoursandphoneticalignment.Proc.Interspeech 2025 pp. 2175–2179 (2025)
work page 2025
-
[30]
Somandepalli, K., et al.: Semantic edge detection for tracking vocal tract air-tissue boundaries in real-time magnetic resonance images. In: Interspeech. pp. 631–635 (2017)
work page 2017
-
[31]
APSIPA Transactions on Signal and Information Processing5, e6 (2016)
Toutios, A., et al.: Advances in real-time magnetic resonance imaging of the vocal tract for speech science and technology research. APSIPA Transactions on Signal and Information Processing5, e6 (2016)
work page 2016
-
[32]
arXiv preprint arXiv:2006.03677 (2020) Multimodal Learning for Vocal Tract Segmentation 11
Wu, B., et al.: Visual transformers: Token-based image representation and process- ing for computer vision. arXiv preprint arXiv:2006.03677 (2020) Multimodal Learning for Vocal Tract Segmentation 11
-
[33]
In: Proceedings of the AAAI conference on artificial intelligence
Wu, J., et al.: Medsegdiff-v2: Diffusion-based medical image segmentation with transformer. In: Proceedings of the AAAI conference on artificial intelligence. vol. 38, pp. 6030–6038 (2024)
work page 2024
-
[34]
arXiv preprint arXiv:2408.00874 (2024)
Zhu, J., et al.: Medical sam 2: Segment medical images as video via segment any- thing model 2. arXiv preprint arXiv:2408.00874 (2024)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.