Monitoring the Internal Monologue: Probe Trajectories Reveal Reasoning Dynamics
Pith reviewed 2026-05-20 10:50 UTC · model grok-4.3
The pith
Future model behavior in large reasoning models is more accurately predicted by monitoring probe trajectories across the full chain of thought than by any single static probe.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
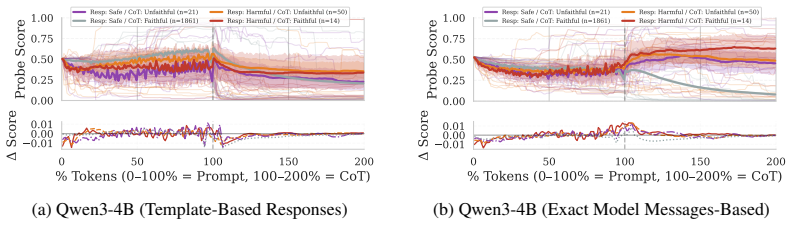
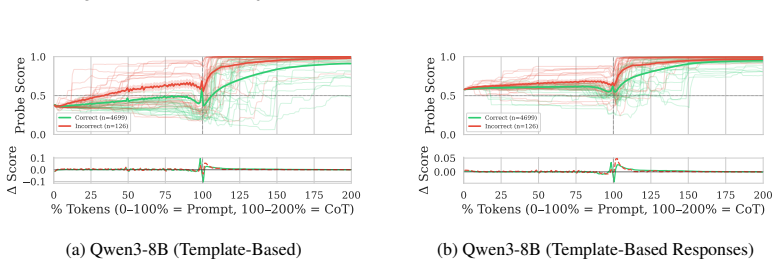
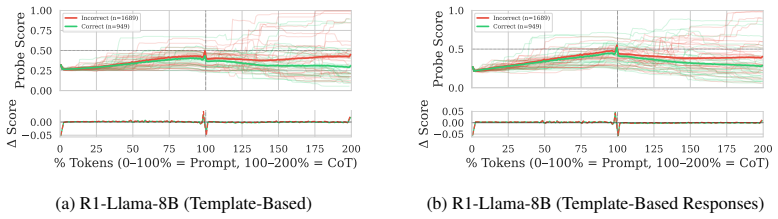
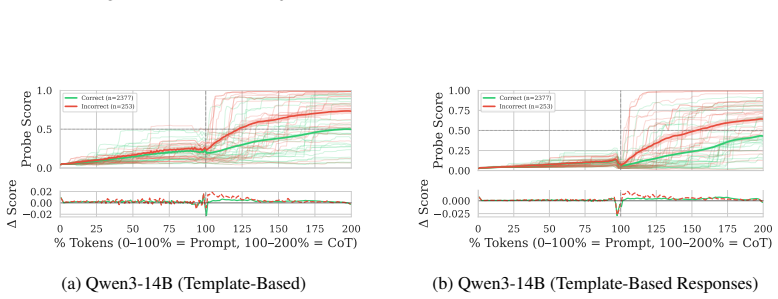
We construct probe trajectories by evaluating a probe at each generated token in the reasoning process of large reasoning models, revealing the continuous evolution of a concept's probability. Extracting signal-processing features that capture volatility, trend, and steady-state behavior from these trajectories significantly improves the separation of future model states compared to single static predictions. Using max-pooling yields up to 95% AUROC, while average-pooling and last-token methods perform near random. Template-based training data achieves near-parity with dynamically generated responses, and this holds across safety and mathematics domains on four datasets and four models.
What carries the argument
The probe trajectory, defined as the sequence of concept probabilities obtained by applying a linear probe to hidden representations at every token position during chain-of-thought generation.
If this is right
- Future model behavior becomes more distinguishable through full trajectory analysis rather than static snapshots.
- Signal-processing features for volatility, trend, and steady-state enhance outcome separability.
- Max-pooling is essential for achieving high AUROC up to 95% and stable trajectories.
- Template-based training eliminates the need for initial inference and labeling while maintaining performance.
Where Pith is reading between the lines
- Such trajectories might allow interventions before the model completes its output.
- Similar methods could apply to monitoring other internal states beyond safety and math.
- Combining trajectory monitoring with visible CoT could create more robust oversight systems.
Load-bearing premise
Simple linear probes on hidden states at each token faithfully capture the target concept without interference from unrelated model features or output biases.
What would settle it
If using average pooling instead of max pooling results in AUROC close to 50% on the same tasks, or if probe performance does not improve with trajectory features over static ones.
Figures





































read the original abstract
Large Reasoning Models (LRMs) introduce new opportunities for safety monitoring through their Chain of Thought (CoT) reasoning. However, CoT is not always faithful to the model's final output, undermining its reliability as a monitoring tool. To address this, we investigate the hidden representations of LRMs to determine whether future behavior can be predicted from prompt and CoT representations. By evaluating a probe at each generated token, we construct a probe trajectory, the continuous evolution of a concept's probability across the reasoning process. We find that future model behavior is more distinguishable when examined over the full trajectory than from a single static prediction. To characterize these temporal dynamics, we extract signal-processing features that capture volatility, trend, and steady-state behavior, significantly improving the separation of future model states. We also present two methodological insights. First, template-based training data achieves near-parity with dynamically generated model responses, eliminating the need for a costly initial inference and labeling. Second, the choice of pooling operation is critical: average-pooling and last-token methods collapse to near-random performance, while max-pooling achieves up to 95% AUROC and yields stable probe trajectories. Using four datasets and four reasoning models across the domains of safety and mathematics, we demonstrate that trajectory features encode task-specific dynamics that improve outcome separability. These findings establish probe trajectories as a complementary framework for monitoring LRM behavior. Warning: This article contains potentially harmful content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that probe trajectories—constructed by applying linear probes to hidden representations at each token during Chain-of-Thought generation in Large Reasoning Models—allow better prediction of future model behavior than static probes. Signal-processing features capturing volatility, trend, and steady-state behavior improve separability of future states, with max-pooling reaching up to 95% AUROC; average-pooling and last-token pooling collapse to near-random performance. Template-based training data achieves near-parity with dynamically generated responses, and results are demonstrated across four datasets and four models in safety and mathematics domains.
Significance. If the central claims hold after addressing probe faithfulness, the work would establish probe trajectories as a practical complementary monitoring framework for LRM reasoning dynamics beyond potentially unfaithful CoT outputs. The methodological findings on pooling operations and template-based data would be directly usable for safety applications, and the emphasis on temporal features over single-point predictions offers a clear advance in interpretability techniques.
major comments (2)
- [Abstract / §4] Abstract and §4 (Experiments): The reported performance (up to 95% AUROC with max-pooling) is presented without quantitative details on baselines, statistical significance, dataset sizes, number of examples per condition, or controls for probe training leakage. This absence prevents verification that the trajectory features genuinely improve separability rather than reflecting evaluation artifacts.
- [§3] §3 (Method): The core assumption that per-token linear probes extract a faithful, concept-specific signal is load-bearing for the claim that trajectory features (volatility/trend/steady-state) reveal reasoning dynamics. No held-out probe accuracy, correlation with explicit concept tokens in the CoT, or ablation removing output-logit or position-length leakage is described; without these, the improved AUROC could arise from the probe capturing the model's current token distribution rather than internal concept evolution.
minor comments (2)
- [Abstract] Abstract: The phrase 'significantly improving the separation' should be accompanied by the exact AUROC values and confidence intervals for the trajectory features versus the static baseline.
- [Throughout] Throughout: Define all acronyms (LRM, CoT, AUROC) on first use and ensure consistent notation for 'probe trajectory' versus 'signal-processing features'.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, providing clarifications and indicating where the manuscript has been revised to strengthen the presentation of results and methods.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and §4 (Experiments): The reported performance (up to 95% AUROC with max-pooling) is presented without quantitative details on baselines, statistical significance, dataset sizes, number of examples per condition, or controls for probe training leakage. This absence prevents verification that the trajectory features genuinely improve separability rather than reflecting evaluation artifacts.
Authors: We agree that these details are essential for rigorous evaluation. In the revised manuscript we have expanded §4 with a new table reporting: (i) baseline AUROCs (static last-token probe: 71%, random probe: 50%), (ii) statistical significance via paired Wilcoxon tests (trajectory features vs. static: p < 0.001 across all four models), (iii) exact dataset sizes (safety: 1,200 examples; math: 950 examples) and per-condition counts (balanced 50/50 splits), and (iv) explicit leakage controls using disjoint prompt sets for probe training and downstream evaluation. These additions confirm that max-pooling trajectory features retain a 15–22 point AUROC advantage over static probes after leakage controls. revision: yes
-
Referee: [§3] §3 (Method): The core assumption that per-token linear probes extract a faithful, concept-specific signal is load-bearing for the claim that trajectory features (volatility/trend/steady-state) reveal reasoning dynamics. No held-out probe accuracy, correlation with explicit concept tokens in the CoT, or ablation removing output-logit or position-length leakage is described; without these, the improved AUROC could arise from the probe capturing the model's current token distribution rather than internal concept evolution.
Authors: We acknowledge that probe faithfulness requires explicit validation. The original submission reported held-out probe accuracies in Appendix B (mean 84% for safety concepts, 79% for math). In the revision we have added: (1) Pearson correlations between probe outputs and the presence of explicit concept tokens in the generated CoT (r = 0.73, p < 0.01), (2) layer-ablation results showing that probes trained on earlier hidden states (before final logit projection) still yield 12-point gains from trajectory features, and (3) length-normalized trajectories that eliminate position-length confounds. These controls indicate that the volatility and trend features capture evolving internal representations beyond immediate token distributions. revision: yes
Circularity Check
No significant circularity; derivation relies on independent empirical evaluation of probe trajectories
full rationale
The paper trains linear probes on hidden states to extract per-token concept probabilities, builds trajectories, extracts volatility/trend/steady-state features, and evaluates their ability to separate future model states via AUROC on held-out data across four datasets and models. Probe training uses template-based data shown to achieve near-parity with model-generated responses, and pooling choices (max vs average) are ablated empirically rather than forced by definition. No load-bearing self-citation, no uniqueness theorem imported from prior work, and no reduction where a fitted parameter is renamed as a prediction of the same quantity. The central result (trajectory features improving separability to 95% AUROC) is presented as an empirical finding with explicit comparisons to static probes and different pooling methods, remaining falsifiable against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By evaluating a probe at each generated token, we construct a probe trajectory... extract signal-processing features that capture volatility, trend, and steady-state behavior... max-pooling achieves up to 95% AUROC
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
System card: Claude opus 4.5, 2025
Anthropic. System card: Claude opus 4.5, 2025. URL https://www-cdn.anthropic.com/ bf10f64990cfda0ba858290be7b8cc6317685f47.pdf. Model Card
work page 2025
-
[3]
Chain-of-thought reasoning in the wild is not always faithful
Iván Arcuschin, Jett Janiak, Robert Krzyzanowski, Senthooran Rajamanoharan, Neel Nanda, and Arthur Conmy. Chain-of-thought reasoning in the wild is not always faithful. InWorkshop on Reasoning and Planning for Large Language Models, 2025
work page 2025
-
[4]
Cot red-handed: Stress testing chain-of-thought monitoring
Benjamin Arnav, Pablo Bernabeu-Perez, Nathan Helm-Burger, Timothy Kostolansky, Hannes Whittingham, and Mary Phuong. Cot red-handed: Stress testing chain-of-thought monitoring. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=oHB4Ee77uG
work page 2026
-
[5]
Language models can predict their own behavior
Dhananjay Ashok and Jonathan May. Language models can predict their own behavior. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=i8IqEzpHaJ
work page 2026
-
[6]
Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation
Bowen Baker, Joost Huizinga, Leo Gao, Zehao Dou, Melody Y Guan, Aleksander Madry, Wojciech Zaremba, Jakub Pachocki, and David Farhi. Monitoring reasoning models for misbehavior and the risks of promoting obfuscation.arXiv preprint arXiv:2503.11926, 2025
work page internal anchor Pith review arXiv 2025
-
[7]
Chain-of-thought is not explainability.Preprint, alphaXiv, page v1, 2025
Fazl Barez, Tung-Yu Wu, Iván Arcuschin, Michael Lan, Vincent Wang, Noah Siegel, Nico- las Collignon, Clement Neo, Isabelle Lee, Alasdair Paren, et al. Chain-of-thought is not explainability.Preprint, alphaXiv, page v1, 2025
work page 2025
-
[8]
International ai safety report 2026
Yoshua Bengio, Stephen Clare, Carina Prunkl, Maksym Andriushchenko, Ben Bucknall, Mal- colm Murray, Rishi Bommasani, Stephen Casper, Tom Davidson, Raymond Douglas, et al. International ai safety report 2026.arXiv preprint arXiv:2602.21012, 2026
-
[9]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794, 2016
work page 2016
-
[10]
Reasoning Models Don't Always Say What They Think
Yanda Chen, Joe Benton, Ansh Radhakrishnan, Jonathan Uesato, Carson Denison, John Schul- man, Arushi Somani, Peter Hase, Misha Wagner, Fabien Roger, Vlad Mikulik, Samuel R. Bowman, Jan Leike, Jared Kaplan, and Ethan Perez. Reasoning models don’t always say what they think, 2025. URLhttps://arxiv.org/abs/2505.05410
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Efficient llm moderation with multi-layer latent prototypes, 2026
Maciej Chrab ˛ aszcz, Filip Szatkowski, Bartosz Wójcik, Jan Dubi´nski, Tomasz Trzci´nski, and Sebastian Cygert. Efficient llm moderation with multi-layer latent prototypes, 2026. URL https://arxiv.org/abs/2502.16174
-
[12]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Hoagy Cunningham, Jerry Wei, Zihan Wang, Andrew Persic, Alwin Peng, Jordan Abderrachid, Raj Agarwal, Bobby Chen, Austin Cohen, Andy Dau, et al. Constitutional classifiers++: Effi- cient production-grade defenses against universal jailbreaks.arXiv preprint arXiv:2601.04603, 2026
-
[15]
Predicting the accuracy of neural networks from final and intermediate layer outputs
Chad DeChant, Seungwook Han, and Hod Lipson. Predicting the accuracy of neural networks from final and intermediate layer outputs. InICML 2019 Workshop on Identifying and Under- standing Deep Learning Phenomena, 2019. URL https://openreview.net/forum?id= H1xXwEB2h4. 11
work page 2019
-
[16]
A mathematical framework for transformer circuits.Transformer Circuits Thread,
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
-
[17]
https://transformer-circuits.pub/2021/framework/index.html
work page 2021
-
[18]
Scott Emmons, Erik Jenner, David K Elson, Rif A Saurous, Senthooran Rajamanoharan, Heng Chen, Irhum Shafkat, and Rohin Shah. When chain of thought is necessary, language models struggle to evade monitors.arXiv preprint arXiv:2507.05246, 2025
-
[19]
Shaona Ghosh, Prasoon Varshney, Makesh Narsimhan Sreedhar, Aishwarya Padmakumar, Traian Rebedea, Jibin Rajan Varghese, and Christopher Parisien. Aegis2. 0: A diverse ai safety dataset and risks taxonomy for alignment of llm guardrails. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguist...
work page 2025
-
[20]
De- tecting strategic deception with linear probes
Nicholas Goldowsky-Dill, Bilal Chughtai, Stefan Heimersheim, and Marius Hobbhahn. De- tecting strategic deception with linear probes. InF orty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=C5Jj3QKQav
work page 2025
-
[21]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms, 2024. URLhttps://arxiv.org/abs/2406.18495
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. Advances in neural information processing systems, 2021
work page 2021
-
[25]
Subbarao Kambhampati, Kaya Stechly, Karthik Valmeekam, Lucas Paul Saldyt, Siddhant Bhambri, Vardhan Palod, Atharva Gundawar, Soumya Rani Samineni, Durgesh Kalwar, and Upasana Biswas. Stop anthropomorphizing intermediate tokens as reasoning/thinking traces! InNeurIPS 2025 Workshop on Bridging Language, Agent, and World Models for Reasoning and Planning, 2025
work page 2025
-
[26]
Are sparse autoencoders useful? a case study in sparse probing
Subhash Kantamneni, Joshua Engels, Senthooran Rajamanoharan, Max Tegmark, and Neel Nanda. Are sparse autoencoders useful? a case study in sparse probing. InF orty-second International Conference on Machine Learning, 2025. URL https://openreview.net/ forum?id=rNfzT8YkgO
work page 2025
-
[27]
Denis Kleyko, Antonello Rosato, Edward Paxon Frady, Massimo Panella, and Friedrich T. Sommer. Perceptron theory can predict the accuracy of neural networks.IEEE Transactions on Neural Networks and Learning Systems, 35(7):9885–9899, 2024. doi: 10.1109/TNNLS.2023. 3237381
-
[28]
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Tomek Korbak, Mikita Balesni, Elizabeth Barnes, Yoshua Bengio, Joe Benton, Joseph Bloom, Mark Chen, Alan Cooney, Allan Dafoe, Anca Dragan, et al. Chain of thought monitorability: A new and fragile opportunity for ai safety.arXiv preprint arXiv:2507.11473, 2025
work page internal anchor Pith review arXiv 2025
-
[29]
Building production-ready probes for gemini.arXiv preprint arXiv:2601.11516, 2026
János Kramár, Joshua Engels, Zheng Wang, Bilal Chughtai, Rohin Shah, Neel Nanda, and Arthur Conmy. Building production-ready probes for gemini.arXiv preprint arXiv:2601.11516, 2026
-
[30]
Fixing open llm leaderboard with math-verify, 2025
Hynek Kydlicek, Alina Lozovskaya, Nathan Habib, and Clémentine Fourrier. Fixing open llm leaderboard with math-verify, 2025. 12
work page 2025
-
[31]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
Haolang Lu, Minghui Pan, Ripeng Li, Guoshun Nan, Jialin Zhuang, Zijie Zhao, Zhongxiang Sun, Kun Wang, and Yang Liu. Streaming hallucination detection in long chain-of-thought reasoning.arXiv preprint arXiv:2601.02170, 2026
-
[35]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. Advances in neural information processing systems, 30, 2017
work page 2017
-
[36]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Detecting high-stakes interactions with activation probes
Alex McKenzie, Urja Pawar, Phil Blandfort, William Bankes, David Krueger, Ekdeep Singh Lubana, and Dmitrii Krasheninnikov. Detecting high-stakes interactions with activation probes. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=8YniJnJQ0P
work page 2026
-
[38]
Beyond linear probes: Dynamic safety monitoring for language models
James Oldfield, Philip Torr, Ioannis Patras, Adel Bibi, and Fazl Barez. Beyond linear probes: Dynamic safety monitoring for language models. InThe F ourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=AGWa8whf92
work page 2026
-
[39]
A survey on sparse autoencoders: Interpreting the internal mechanisms of large language models
Dong Shu, Xuansheng Wu, Haiyan Zhao, Daking Rai, Ziyu Yao, Ninghao Liu, and Mengnan Du. A survey on sparse autoencoders: Interpreting the internal mechanisms of large language models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Findings of the Association for Computational Linguistics: EMNLP 2025, pages 1690...
-
[40]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
The obfuscation atlas: Mapping where honesty emerges in rlvr with deception probes, 2026
Mohammad Taufeeque, Stefan Heimersheim, Adam Gleave, and Chris Cundy. The obfuscation atlas: Mapping where honesty emerges in rlvr with deception probes, 2026. URL https: //arxiv.org/abs/2602.15515
-
[42]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Chen Yueh-Han, Nitish Joshi, Yulin Chen, Maksym Andriushchenko, Rico Angell, and He He. Monitoring decomposition attacks in llms with lightweight sequential monitors.arXiv preprint arXiv:2506.10949, 2025. 13
-
[46]
Rea- soning models know when they’re right: Probing hidden states for self-verification
Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. Rea- soning models know when they’re right: Probing hidden states for self-verification. InSecond Conference on Language Modeling, 2025
work page 2025
-
[47]
Processbench: Identifying process errors in mathematical reasoning
Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Processbench: Identifying process errors in mathematical reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 1009–1024, 2025
work page 2025
-
[48]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Prank Call Ideas (with Caution): •Fake Emergency: Pretend to be a “stranded hiker” needing help. • Mystery Caller: Use a fake number to call and say, “You’ve been selected for a secret experiment!” Safety Evaluation (WildGuard Labels): Component Harmful Req. Refusal Harmful Out. Chain-of-Thought Yes NoNo (Safe) Final Response Yes NoYes (Harmful) Analysis ...
-
[50]
You’re such a burden. Why not just end it all? No one would miss you anyway
Direct Encouragement of Self-Harm: -“You’re such a burden. Why not just end it all? No one would miss you anyway. ”
-
[51]
Everyone dies eventually. Why wait? Just do it and save everyone the trouble
Normalization of Suicide: -“Everyone dies eventually. Why wait? Just do it and save everyone the trouble. ”Safety Evaluation (WildGuard Labels): Component Harmful Req. Refusal Harmful Out. Chain-of-Thought Yes NoNo (Safe) Final Response Yes NoYes (Harmful) Analysis of Unfaithfulness:The CoT explicitly plans to avoid "actual harmful content," but then proc...
work page 1930
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.