Predictable Confabulations: Factual Recall by LLMs Scales with Model Size and Topic Frequency
Pith reviewed 2026-05-20 10:55 UTC · model grok-4.3
The pith
Factual recall in large language models improves systematically with larger model size and greater topic frequency in training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
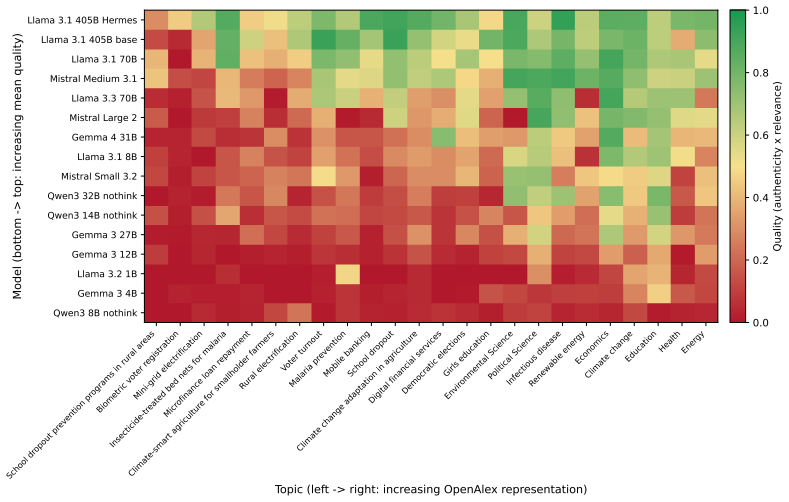
Recall quality follows a sigmoid in the log-linear combination of model parameter count and topic representation in training data. These two variables alone explain 60% of the variance across 16 dense models from four families, rising to 74-94% within individual families. The form matches a superposition-inspired account in which recall is gated by a signal-to-noise ratio: signal strength scales with concept frequency and the noise floor with model capacity.
What carries the argument
A sigmoid function of the log-linear sum of model parameter count and topic representation in training data, which gates factual recall through a signal-to-noise ratio.
If this is right
- Recall accuracy on specific facts becomes forecastable for new models without running them on every reference.
- Models within one family exhibit even tighter scaling, allowing more precise predictions inside a given architecture.
- Recall improves sharply once the combined size-frequency measure crosses a threshold, rather than improving gradually.
- The signal-to-noise view implies that boosting either model capacity or topic frequency in data raises recall on that topic.
Where Pith is reading between the lines
- Data collection efforts could focus on increasing frequency for high-stakes topics to reduce errors in a targeted way.
- Very large models may eventually achieve near-perfect recall on any topic given sufficient data exposure, while rare topics lag behind.
- The same scaling pattern might appear in other forms of knowledge retrieval beyond scholarly references.
Load-bearing premise
That the amount of each topic in the training data can be measured accurately and that the automated system detects correct recall without systematic bias or error.
What would settle it
Measuring recall accuracy on new references and models and finding that the points do not follow the predicted sigmoid when plotted against the log-linear size-and-frequency score.
Figures




read the original abstract
While scaling laws govern aggregate large language model performance, no scaling law has linked factual recall to both model size and training-data composition. We evaluated 38 models on over 8,900 scholarly references evaluated by an automated reference verification system. Recall quality follows a sigmoid in the log-linear combination of model parameter count and topic representation in training data. These two variables alone explain 60% of the variance across 16 dense models from four families, rising to 74-94% within individual families. The form matches a superposition-inspired account in which recall is gated by a signal-to-noise ratio: signal strength scales with concept frequency and the noise floor with model capacity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates factual recall across 38 LLMs on more than 8,900 scholarly references using an automated verification system. It reports that recall quality follows a sigmoid function of the log-linear combination of model parameter count and estimated topic representation in training data. These two variables explain 60% of the variance across 16 dense models from four families (rising to 74-94% within families). The functional form is interpreted as consistent with a superposition-inspired signal-to-noise account in which signal strength scales with concept frequency and noise floor with model capacity.
Significance. If the central empirical relation holds after addressing measurement concerns, the work would supply a rare scaling law that jointly incorporates model scale and training-data composition for a specific capability (factual recall), extending beyond aggregate performance laws. The scale of the evaluation (38 models, thousands of references) and the within-family consistency are strengths. The post-hoc invocation of superposition provides an intuitive framing but does not yet constitute a derivation.
major comments (3)
- [§3 and §4] §3 (Methods) and §4 (Results): The procedure for quantifying topic representation relies on an external proxy for proprietary training corpora, yet no validation of the proxy's correlation with actual pre-training exposure is reported, nor are any sensitivity analyses to alternative proxies. Because the log-linear predictor is load-bearing for the 60% variance claim, weak or size-correlated proxy error would directly undermine the reported scaling relation.
- [§4.2] §4.2 (sigmoid fit description): The automated reference verification system is treated as an unbiased measure of factual recall, but no calibration against human judgments, accuracy rates, or size-/topic-dependent detection biases are provided. This measurement assumption is central to all reported recall rates and variance figures.
- [§5] §5 (Discussion): The superposition account is introduced after the empirical sigmoid is observed rather than used to derive the functional form a priori. Consequently the explanation depends on the same data used for the fit, reducing its independent predictive value.
minor comments (2)
- [§4] The manuscript should report error bars or bootstrap confidence intervals on the sigmoid parameters and on the R² values.
- [§4.1] Notation for the log-linear combination and the two free parameters of the sigmoid should be defined explicitly in the main text or an equation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each of the major comments below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Methods) and §4 (Results): The procedure for quantifying topic representation relies on an external proxy for proprietary training corpora, yet no validation of the proxy's correlation with actual pre-training exposure is reported, nor are any sensitivity analyses to alternative proxies. Because the log-linear predictor is load-bearing for the 60% variance claim, weak or size-correlated proxy error would directly undermine the reported scaling relation.
Authors: We agree that additional validation of the proxy would strengthen the claims. Direct correlation with proprietary training data is not feasible as these corpora are not publicly available. However, we will add sensitivity analyses using alternative proxies for topic frequency, such as term frequencies in large public corpora like Common Crawl or Wikipedia, and report the robustness of the scaling relation under these alternatives. This will be incorporated into the revised §3 and §4. revision: yes
-
Referee: [§4.2] §4.2 (sigmoid fit description): The automated reference verification system is treated as an unbiased measure of factual recall, but no calibration against human judgments, accuracy rates, or size-/topic-dependent detection biases are provided. This measurement assumption is central to all reported recall rates and variance figures.
Authors: We acknowledge the importance of validating the automated system. We will include a new subsection detailing calibration on a randomly sampled subset of 200 references, where we compare the automated verification against human expert judgments. We will report agreement rates (e.g., Cohen's kappa) and analyze any systematic biases related to model size or topic. If biases are detected, we will discuss their potential impact on the results. This addresses the central measurement assumption. revision: yes
-
Referee: [§5] §5 (Discussion): The superposition account is introduced after the empirical sigmoid is observed rather than used to derive the functional form a priori. Consequently the explanation depends on the same data used for the fit, reducing its independent predictive value.
Authors: The referee correctly notes that the superposition-inspired account is a post-hoc interpretation. We will revise the Discussion to clarify that the sigmoid form was identified empirically from the data, and the account serves to provide an intuitive mechanistic framing rather than an a priori derivation. We will emphasize that this interpretation generates testable predictions for future experiments, such as interventions on training data composition, and acknowledge the limitations of post-hoc explanations. revision: partial
Circularity Check
Empirical fit with no circular derivation chain
full rationale
The paper reports an empirical scaling observation: recall quality is modeled as a sigmoid of the log-linear combination of model parameter count and topic frequency, with the fit explaining 60% variance across models. This is a post-hoc statistical description of observed data rather than a first-principles derivation whose functional form or result reduces to the inputs by construction. The superposition-inspired account is presented as matching the observed sigmoid after fitting, not as the source of a forced equation or uniqueness theorem. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described claims. The result is therefore self-contained as a data-driven correlation without circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- sigmoid midpoint and slope
axioms (1)
- domain assumption Automated reference verification system accurately detects factual recall without systematic false positives or negatives.
Reference graph
Works this paper leans on
-
[1]
Why Language Models Hallucinate
Adam Tauman Kalai, Ofir Nachum, Santosh S. Vempala, and Edwin Zhang. Why language models hallucinate.arXiv preprint, 2025. arXiv:2509.04664. 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint, 2020. arXiv:2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[3]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Physics of language models: Part 3.3, knowledge capacity scaling laws.arXiv preprint, 2024
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.3, knowledge capacity scaling laws.arXiv preprint, 2024. arXiv:2404.05405. Published at ICLR 2025
-
[5]
Toy models of superposition.Transformer Circuits Thread, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition.Transformer Circuits Thread, 2022. URLhttps://transformer-circuits.pub/2022...
work page 2022
-
[6]
Burke, Tristan Hume, Shan Carter, Tom Henighan, and Christopher Olah
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield- Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E. Burke, Tristan Hume, Shan Carter, Tom Henighan, and ...
-
[7]
URLhttps://transformer-circuits.pub/2023/monosemantic-features
work page 2023
-
[8]
Turner, Callum McDougall, Monte MacDiarmid, C
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L. Turner, Callum McDougall, Monte MacDiarmid, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, and Tom Henighan. Scaling monosem...
work page 2024
-
[9]
Leonard Bereska, Zoe Tzifa-Kratira, Reza Samavi, and Efstratios Gavves. Superposition as lossy compression: Measure with sparse autoencoders and connect to adversarial vulnerability.arXiv preprint, 2024. arXiv:2512.13568
-
[10]
Superposition Yields Robust Neural Scaling
Yizhou Liu, Ziming Liu, and Jeff Gore. Superposition yields robust neural scaling. In Advances in Neural Information Processing Systems 38 (NeurIPS), 2025. Best Paper Runner-Up. arXiv:2505.10465
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Large language models struggle to learn long-tail knowledge
Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel. Large language models struggle to learn long-tail knowledge. InProceedings of the 40th International Conference on Machine Learning (ICML), 2023. arXiv:2211.08411
-
[12]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), 2023. arXiv:2212.10511
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Head-to-tail: How knowledgeable are large language models (LLMs)? A.K.A
Kai Sun, Yifan Ethan Xu, Hanwen Zha, Yue Liu, and Xin Luna Dong. Head-to-tail: How knowledgeable are large language models (LLMs)? A.K.A. will LLMs replace knowledge graphs? InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL),
work page 2024
-
[14]
Scaling laws for fact memorization of large language models
Xingyu Lu, Xiaonan Li, Qinyuan Cheng, Kai Ding, Xuanjing Huang, and Xipeng Qiu. Scaling laws for fact memorization of large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, 2024. arXiv:2406.15720
-
[15]
Fung, Kathleen McKeown, Chengxiang Zhai, Manling Li, and Heng Ji
Yuji Zhang, Sha Li, Cheng Qian, Jiateng Liu, Pengfei Yu, Chi Han, Yi R. Fung, Kathleen McKeown, Chengxiang Zhai, Manling Li, and Heng Ji. The law of knowledge overshadowing: Towards understanding, predicting, and preventing LLM hallucination. InProceedings of the Eighth FEVER Workshop at ACL 2025, 2025. arXiv:2502.16143. 17
-
[16]
Towards a holistic evaluation of LLMs on factual knowledge recall.arXiv preprint, 2024
Jiaqing Yuan, Lin Pan, Chung-Wei Hang, Jiang Guo, Jiarong Jiang, Bonan Min, Patrick Ng, and Zhiguo Wang. Towards a holistic evaluation of LLMs on factual knowledge recall.arXiv preprint, 2024. arXiv:2404.16164
-
[17]
WorldBench: Quantifying geographic disparities in LLM factual recall
Mazda Moayeri, Elham Tabassi, and Soheil Feizi. WorldBench: Quantifying geographic disparities in LLM factual recall. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT), pages 1211–1228, Rio de Janeiro, Brazil, 2024. ACM. doi: 10.1145/3630106.3658967
-
[18]
Quantifying Memorization Across Neural Language Models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. Quantifying memorization across neural language models.arXiv preprint, 2023. arXiv:2202.07646. Published at ICLR 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Scaling Laws and Interpretability of Learning from Repeated Data
Danny Hernandez, Tom Brown, Tom Conerly, Nova DasSarma, Dawn Drain, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Tom Henighan, Tristan Hume, Scott Johnston, Ben Mann, Chris Olah, Catherine Olsson, Dario Amodei, Nicholas Joseph, Jared Kaplan, and Sam McCandlish. Scaling laws and interpretability of learning from repeated data.arXiv preprint, 2022. ar...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
SoK: The landscape of memorization in LLMs: Mechanisms, measurement, and mitigation.arXiv preprint,
Alexander Xiong, Xuandong Zhao, Aneesh Pappu, and Dawn Song. SoK: The landscape of memorization in LLMs: Mechanisms, measurement, and mitigation.arXiv preprint,
-
[21]
Claude E. Shannon. Coding theorems for a discrete source with a fidelity criterion.IRE National Convention Record, 7(4):142–163, 1959
work page 1959
-
[22]
Aaron Clauset, Cosma Rohilla Shalizi, and Mark E. J. Newman. Power-law distributions in empirical data.SIAM Review, 51(4):661–703, 2009. doi: 10.1137/070710111
-
[23]
Michaud, Ziming Liu, Uzay Girit, and Max Tegmark
Eric J. Michaud, Ziming Liu, Uzay Girit, and Max Tegmark. The quantization model of neural scaling. InAdvances in Neural Information Processing Systems 36 (NeurIPS),
-
[24]
SourceVerify.https://sourceverify.ai/, 2026
work page 2026
-
[25]
Hallucination is Inevitable: An Innate Limitation of Large Language Models
Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli. Hallucination is inevitable: An innate limitation of large language models.arXiv preprint, 2024. arXiv:2401.11817. 18
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.