PIXLRelight: Controllable Relighting via Intrinsic Conditioning
Pith reviewed 2026-05-20 11:10 UTC · model grok-4.3
pith:NEWRBEXG Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{NEWRBEXG}
Prints a linked pith:NEWRBEXG badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
A neural renderer transfers arbitrary PBR lighting to a single photograph by conditioning on intrinsic maps obtained identically from real multi-illumination images or path-traced coarse 3D renders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
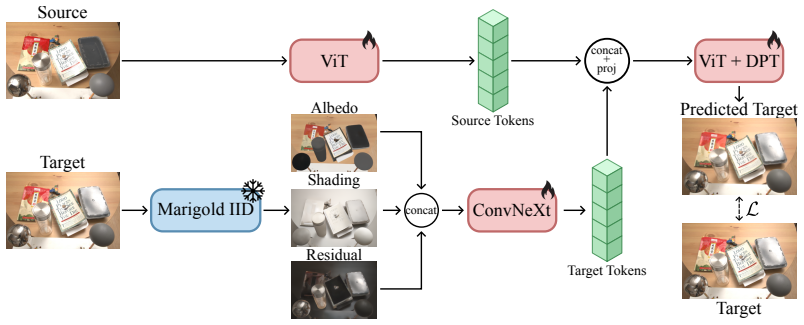
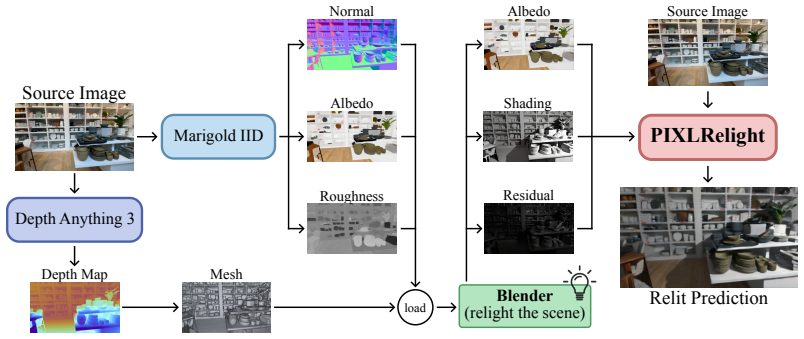
PIXLRelight bridges physically based rendering and learned image synthesis through a shared intrinsic conditioning signal. Training decomposes real multi-illumination photograph pairs into albedo, diffuse shading, and non-diffuse residuals. Inference computes the identical conditioning from a path-traced render of a coarse 3D reconstruction lit by user-specified PBR lights. A transformer-based neural renderer then modulates the source photograph with the target illumination via per-pixel affine modulation, preserving detail while achieving arbitrary lighting control.
What carries the argument
Shared intrinsic conditioning (albedo, diffuse shading, and non-diffuse residuals) extracted consistently from either real multi-illumination photographs or path-traced renders of coarse 3D reconstructions.
If this is right
- Users gain arbitrary PBR-style lighting control from a single input photograph.
- Relighting quality reaches state-of-the-art levels while eliminating error accumulation from chained inverse and forward rendering.
- Inference completes in under one tenth of a second per image without per-image optimization.
- The same conditioning pipeline works for both training data from real photographs and inference data from simulated renders.
Where Pith is reading between the lines
- The method could support real-time relighting in AR or VR once a coarse 3D proxy is available from a single view.
- Extending the decomposition to include specular or subsurface components would widen the range of materials that can be relit without retraining.
- Combining the approach with better single-image 3D reconstruction would reduce reliance on coarse proxies and improve handling of complex geometry.
Load-bearing premise
The intrinsic decomposition obtained from a path-traced render of a coarse 3D reconstruction matches the decomposition from real multi-illumination photographs closely enough to support faithful lighting transfer.
What would settle it
Apply the trained model to a real photograph whose target lighting is taken from a different real capture of the same scene, then measure whether pixel-wise error and perceptual metrics remain comparable to methods that use ground-truth lighting maps.
Figures










read the original abstract
We present PIXLRelight, a feed-forward approach for physically controllable single-image relighting. Existing methods either provide limited lighting control (e.g. through text or environment maps), accumulate errors when chaining inverse and forward rendering, or require costly per-image optimization. Our key idea is to bridge physically based rendering (PBR) and learned image synthesis through a shared intrinsic conditioning that can be obtained from either real photographs or PBR renders. At training time, paired multi-illumination photographs are decomposed into albedo, diffuse shading, and non-diffuse residuals, which condition the model. At inference time, the same conditioning is computed from a path-traced render of a coarse 3D reconstruction of the input under user-specified PBR lights. A transformer-based neural renderer then applies the target illumination to the source photograph, preserving fine image detail through a per-pixel affine modulation. PIXLRelight enables arbitrary PBR-style lighting control, achieves state-of-the-art relighting quality, and runs in under a tenth of a second per image. Code and models are available at https://mlfarinha.github.io/pixl-relight/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PIXLRelight, a feed-forward approach for physically controllable single-image relighting. It uses a shared intrinsic conditioning consisting of albedo, diffuse shading, and non-diffuse residuals obtained from either real multi-illumination photographs or PBR renders of coarse 3D reconstructions. A transformer-based neural renderer applies the target illumination to the source image via per-pixel affine modulation. The method claims to enable arbitrary PBR-style lighting control, achieve state-of-the-art quality, and run in under 0.1 seconds per image.
Significance. This work has the potential to advance controllable relighting techniques by avoiding the need for per-image optimization and error accumulation in chained rendering pipelines. By bridging PBR and learned synthesis through intrinsic conditioning, it could facilitate real-time applications if the domain compatibility is validated. The open-sourcing of code and models strengthens its contribution to the community.
major comments (2)
- [Section 3.2] The decomposition network is trained only on real data (as described in Section 3.2 and Figure 3), yet the same network is applied at inference to synthetic path-traced renders. This may result in out-of-distribution inputs due to approximations in geometry, materials, and shadows in the coarse 3D reconstruction, potentially leading to inaccurate relighting. The paper should include experiments validating the compatibility of decompositions from real and synthetic sources.
- [Abstract and Results] The abstract asserts state-of-the-art relighting quality and real-time performance, but the manuscript provides no quantitative metrics, baseline comparisons, or ablation studies to support these claims. Without such evidence, the central performance assertions cannot be fully evaluated.
minor comments (2)
- [Figure 3] Improve the clarity of the architecture diagram by adding more detailed labels for the transformer renderer and modulation steps.
- [Abstract] The claim of 'state-of-the-art relighting quality' should be qualified or supported with specific references to comparisons in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment in detail below, indicating planned changes to the manuscript.
read point-by-point responses
-
Referee: [Section 3.2] The decomposition network is trained only on real data (as described in Section 3.2 and Figure 3), yet the same network is applied at inference to synthetic path-traced renders. This may result in out-of-distribution inputs due to approximations in geometry, materials, and shadows in the coarse 3D reconstruction, potentially leading to inaccurate relighting. The paper should include experiments validating the compatibility of decompositions from real and synthetic sources.
Authors: We agree that the decomposition network is trained exclusively on real multi-illumination photographs, as stated in Section 3.2, and that applying it to synthetic path-traced renders of coarse 3D reconstructions introduces a potential domain gap due to differences in geometry, materials, and shadow approximations. Although the shared intrinsic conditioning (albedo, diffuse shading, and non-diffuse residuals) is intended to provide a domain-bridging representation, we acknowledge that explicit validation would strengthen the approach. We will add experiments to the revised manuscript that compare decomposition outputs on matched real and synthetic versions of the same scenes, including visual and quantitative consistency metrics where feasible. revision: yes
-
Referee: [Abstract and Results] The abstract asserts state-of-the-art relighting quality and real-time performance, but the manuscript provides no quantitative metrics, baseline comparisons, or ablation studies to support these claims. Without such evidence, the central performance assertions cannot be fully evaluated.
Authors: We thank the referee for highlighting this point. The abstract summarizes the relighting quality and runtime claims based on the qualitative visual results, comparisons to prior work, and timing benchmarks presented in the Results section. We recognize, however, that quantitative metrics (e.g., PSNR, SSIM on relighting benchmarks), direct numerical baseline comparisons, and ablation studies on components such as the transformer renderer and per-pixel modulation would provide stronger substantiation. We will incorporate these quantitative evaluations, baseline tables, and ablations into the revised Results section. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper presents a feed-forward transformer renderer that applies target illumination to a source photograph using intrinsic conditioning (albedo, diffuse shading, non-diffuse residuals). Training uses decompositions from real paired multi-illumination photographs, while inference computes the same conditioning from path-traced renders of a coarse 3D reconstruction under user-specified PBR lights. No equations, derivations, or self-citations reduce the output to a fitted quantity defined from the input by construction. The method relies on external PBR rendering and a standard decomposition network without per-image optimization or domain adaptation, making the central claim independent of circular reductions. The distributional gap between real and synthetic decompositions is an assumption about generalization rather than a definitional loop.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Paired multi-illumination photographs can be decomposed into albedo, diffuse shading, and non-diffuse residuals with sufficient accuracy for training.
- domain assumption A coarse 3D reconstruction of the input scene is sufficient to produce a path-traced render whose intrinsic components match the format needed for lighting transfer.
Reference graph
Works this paper leans on
-
[1]
Recovering intrinsic scene characteristics.Comput
Harry Barrow, J Tenenbaum, A Hanson, and E Riseman. Recovering intrinsic scene characteristics.Comput. vis. syst, 2(3-26):2, 1978
work page 1978
-
[2]
Genlit: Reformulating single-image relighting as video generation
Shrisha Bharadwaj, Haiwen Feng, Giorgio Becherini, Victoria Fernandez Abrevaya, and Michael J Black. Genlit: Reformulating single-image relighting as video generation. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–12, 2025
work page 2025
-
[3]
Blender Online Community.Blender - a 3D modelling and rendering package. Blender Foundation
-
[4]
Intrinsic image decomposition via ordinal shading.ACM Transactions on Graphics, 43(1):1–24, 2023
Chris Careaga and Ya˘gız Aksoy. Intrinsic image decomposition via ordinal shading.ACM Transactions on Graphics, 43(1):1–24, 2023
work page 2023
-
[5]
Physically controllable relighting of photographs
Chris Careaga and Ya˘gız Aksoy. Physically controllable relighting of photographs. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–10, 2025
work page 2025
-
[6]
Worameth Chinchuthakun, Pakkapon Phongthawee, Amit Raj, Varun Jampani, Pramook Khungurn, and Supasorn Suwajanakorn. Diffusionlight-turbo: Accelerated light probes for free via single-pass chrome ball inpainting.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
work page 2026
-
[7]
Scribblelight: Single image indoor relighting with scribbles
Jun Myeong Choi, Annie Wang, Pieter Peers, Anand Bhattad, and Roni Sengupta. Scribblelight: Single image indoor relighting with scribbles. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5720–5731, 2025
work page 2025
-
[8]
Vision Transformers Need Registers
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. arXiv preprint arXiv:2309.16588, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
- [10]
-
[11]
Ye Fang, Tong Wu, Valentin Deschaintre, Duygu Ceylan, Iliyan Georgiev, Chun-Hao Paul Huang, Yiwei Hu, Xuelin Chen, and Tuanfeng Yang Wang. V-rgbx: Video editing with accurate controls over intrinsic properties.arXiv preprint arXiv:2512.11799, 2025
-
[12]
Ground truth dataset and baseline evaluations for intrinsic image algorithms
Roger Grosse, Micah K Johnson, Edward H Adelson, and William T Freeman. Ground truth dataset and baseline evaluations for intrinsic image algorithms. In2009 IEEE 12th International Conference on Computer Vision, pages 2335–2342. Ieee, 2009
work page 2009
-
[13]
Cambridge university press, 2003
Richard Hartley and Andrew Zisserman.Multiple view geometry in computer vision. Cambridge university press, 2003
work page 2003
-
[14]
Kai He, Ruofan Liang, Jacob Munkberg, Jon Hasselgren, Nandita Vijaykumar, Alexander Keller, Sanja Fidler, Igor Gilitschenski, Zan Gojcic, and Zian Wang. Unirelight: Learning joint decomposition and synthesis for video relighting.arXiv preprint arXiv:2506.15673, 2025
-
[15]
Vidit: Virtual image dataset for illumination transfer.arXiv preprint arXiv:2005.05460, 2020
Majed El Helou, Ruofan Zhou, Johan Barthas, and Sabine Süsstrunk. Vidit: Virtual image dataset for illumination transfer.arXiv preprint arXiv:2005.05460, 2020
-
[16]
Rayzer: A self-supervised large view synthesis model
Hanwen Jiang, Hao Tan, Peng Wang, Haian Jin, Yue Zhao, Sai Bi, Kai Zhang, Fujun Luan, Kalyan Sunkavalli, Qixing Huang, et al. Rayzer: A self-supervised large view synthesis model. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4918–4929, 2025
work page 2025
-
[17]
Haian Jin, Hanwen Jiang, Hao Tan, Kai Zhang, Sai Bi, Tianyuan Zhang, Fujun Luan, Noah Snavely, and Zexiang Xu. Lvsm: A large view synthesis model with minimal 3d inductive bias.arXiv preprint arXiv:2410.17242, 2024
-
[18]
Haian Jin, Yuan Li, Fujun Luan, Yuanbo Xiangli, Sai Bi, Kai Zhang, Zexiang Xu, Jin Sun, and Noah Snavely. Neural gaffer: Relighting any object via diffusion.Advances in Neural Information Processing Systems, 37:141129–141152, 2024
work page 2024
-
[19]
Perceptual losses for real-time style transfer and super-resolution
Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. InEuropean conference on computer vision, pages 694–711. Springer, 2016
work page 2016
-
[20]
Marigold: Affordable adaptation of diffusion-based image generators for image analysis, 2025
Bingxin Ke, Kevin Qu, Tianfu Wang, Nando Metzger, Shengyu Huang, Bo Li, Anton Obukhov, and Konrad Schindler. Marigold: Affordable adaptation of diffusion-based image generators for image analysis, 2025. 10
work page 2025
-
[21]
Intrinsic image diffusion for indoor single-view material estimation
Peter Kocsis, Vincent Sitzmann, and Matthias Nießner. Intrinsic image diffusion for indoor single-view material estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5198–5208, 2024
work page 2024
-
[22]
Intrinsix: High-quality pbr generation using image priors.arXiv preprint arXiv:2504.01008, 2025
Peter Kocsis, Lukas Höllein, and Matthias Nießner. Intrinsix: High-quality pbr generation using image priors.arXiv preprint arXiv:2504.01008, 2025
-
[23]
Lightness and retinex theory.Journal of the Optical society of America, 61(1):1–11, 1971
Edwin H Land and John J McCann. Lightness and retinex theory.Journal of the Optical society of America, 61(1):1–11, 1971
work page 1971
-
[24]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. In European conference on computer vision, pages 71–91. Springer, 2024
work page 2024
-
[25]
Learning intrinsic image decomposition from watching the world
Zhengqi Li and Noah Snavely. Learning intrinsic image decomposition from watching the world. In Computer Vision and Pattern Recognition (CVPR), 2018
work page 2018
-
[26]
Zhengqin Li, Mohammad Shafiei, Ravi Ramamoorthi, Kalyan Sunkavalli, and Manmohan Chandraker. Inverse rendering for complex indoor scenes: Shape, spatially-varying lighting and svbrdf from a single image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2475–2484, 2020
work page 2020
-
[27]
Openrooms: An open framework for photorealistic indoor scene datasets
Zhengqin Li, Ting-Wei Yu, Shen Sang, Sarah Wang, Meng Song, Yuhan Liu, Yu-Ying Yeh, Rui Zhu, Nitesh Gundavarapu, Jia Shi, et al. Openrooms: An open framework for photorealistic indoor scene datasets. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7190–7199, 2021
work page 2021
-
[28]
Diffusion renderer: Neural inverse and forward rendering with video diffusion models
Ruofan Liang, Zan Gojcic, Huan Ling, Jacob Munkberg, Jon Hasselgren, Chih-Hao Lin, Jun Gao, Alexander Keller, Nandita Vijaykumar, Sanja Fidler, et al. Diffusion renderer: Neural inverse and forward rendering with video diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26069–26080, 2025
work page 2025
-
[29]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024
work page 2024
-
[31]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11976–11986, 2022
work page 2022
-
[32]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Lightlab: Controlling light sources in images with diffusion models
Nadav Magar, Amir Hertz, Eric Tabellion, Yael Pritch, Alex Rav-Acha, Ariel Shamir, and Yedid Hoshen. Lightlab: Controlling light sources in images with diffusion models. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–11, 2025
work page 2025
-
[34]
A dataset of multi-illumination images in the wild
Lukas Murmann, Michael Gharbi, Miika Aittala, and Fredo Durand. A dataset of multi-illumination images in the wild. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4080–4089, 2019
work page 2019
-
[35]
Vision transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF international conference on computer vision, pages 12179–12188, 2021
work page 2021
-
[36]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InProceedings of the IEEE/CVF international conference on computer vision, pages 10912–10922, 2021
work page 2021
-
[37]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[38]
SyncLight: Single-Edit Multi-View Relighting
David Serrano-Lozano, Anand Bhattad, Luis Herranz, Jean-François Lalonde, and Javier Vazquez-Corral. Synclight: Controllable and consistent multi-view relighting.arXiv preprint arXiv:2601.16981, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[40]
Ouroboros: Single-step diffusion models for cycle-consistent forward and inverse rendering
Shanlin Sun, Yifan Wang, Hanwen Zhang, Yifeng Xiong, Qin Ren, Ruogu Fang, Xiaohui Xie, and Chenyu You. Ouroboros: Single-step diffusion models for cycle-consistent forward and inverse rendering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10386–10397, 2025
work page 2025
-
[41]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[42]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
work page 2025
-
[43]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
work page 2024
-
[44]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
work page 2004
-
[45]
Learning indoor inverse rendering with 3d spatially-varying lighting
Zian Wang, Jonah Philion, Sanja Fidler, and Jan Kautz. Learning indoor inverse rendering with 3d spatially-varying lighting. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12538–12547, 2021
work page 2021
-
[46]
Convnext v2: Co-designing and scaling convnets with masked autoencoders
Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, and Saining Xie. Convnext v2: Co-designing and scaling convnets with masked autoencoders. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16133–16142, 2023
work page 2023
-
[47]
Luminet: Latent intrinsics meets diffusion models for indoor scene relighting
Xiaoyan Xing, Konrad Groh, Sezer Karaoglu, Theo Gevers, and Anand Bhattad. Luminet: Latent intrinsics meets diffusion models for indoor scene relighting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 442–452, 2025
work page 2025
-
[48]
Depth anything v2.Advances in Neural Information Processing Systems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.Advances in Neural Information Processing Systems, 37:21875–21911, 2024
work page 2024
-
[49]
Dilightnet: Fine-grained lighting control for diffusion-based image generation
Chong Zeng, Yue Dong, Pieter Peers, Youkang Kong, Hongzhi Wu, and Xin Tong. Dilightnet: Fine-grained lighting control for diffusion-based image generation. InACM SIGGRAPH 2024 Conference Papers, pages 1–12, 2024
work page 2024
-
[50]
Rgb↔x: Image decomposition and synthesis using material- and lighting-aware diffusion models
Zheng Zeng, Valentin Deschaintre, Iliyan Georgiev, Yannick Hold-Geoffroy, Yiwei Hu, Fujun Luan, Ling- Qi Yan, and Miloš Hašan. Rgb↔x: Image decomposition and synthesis using material- and lighting-aware diffusion models. InACM SIGGRAPH 2024 Conference Papers, New York, NY , USA, 2024. Association for Computing Machinery
work page 2024
-
[51]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Scaling in-the-wild training for diffusion-based illumi- nation harmonization and editing by imposing consistent light transport. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[52]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018
work page 2018
-
[53]
Irisformer: Dense vision transformers for single-image inverse rendering in indoor scenes
Rui Zhu, Zhengqin Li, Janarbek Matai, Fatih Porikli, and Manmohan Chandraker. Irisformer: Dense vision transformers for single-image inverse rendering in indoor scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2822–2831, 2022. 12 Appendix This appendix collects implementation details and additional results...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.