OmniGUI: Benchmarking GUI Agents in Omni-Modal Smartphone Environments
Pith reviewed 2026-05-21 10:13 UTC · model grok-4.3
The pith
Current GUI agent models handle static visuals but degrade sharply when tasks require synced audio and timing signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
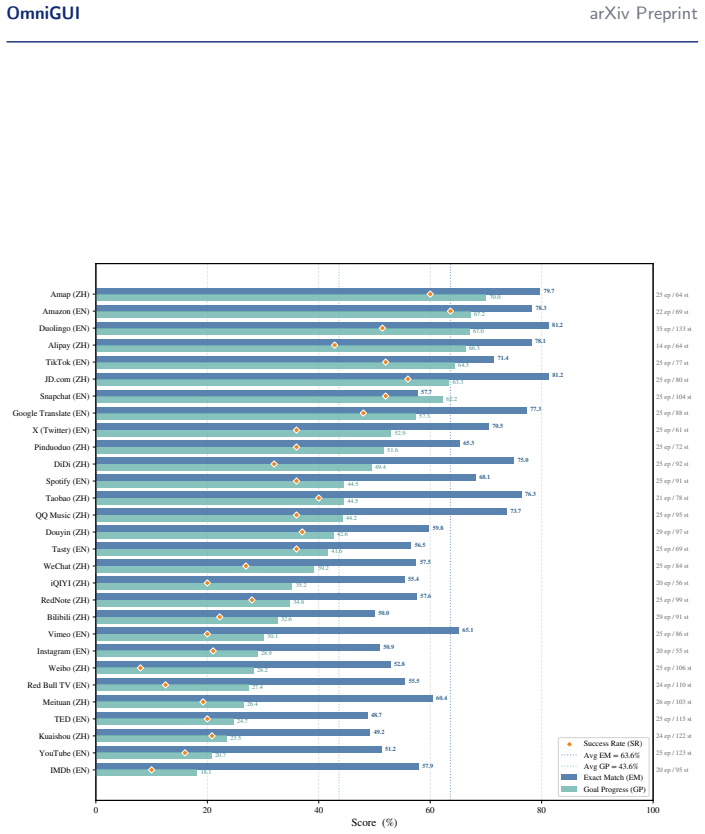
OmniGUI demonstrates that action prediction performance of current omni-modal models drops significantly in smartphone environments that require synchronous temporal and auditory signals, while the same models remain competent on visually static tasks; the benchmark supplies interleaved multimodal inputs at every step along with objective dependency annotations to make these differences measurable.
What carries the argument
OmniGUI benchmark that delivers continuous, interleaved multimodal inputs (static images, synchronous audio, video clips) at each action step together with systematic annotations of multimodal dependency levels.
If this is right
- Future agent training must address integration of auditory and temporal cues to avoid accuracy loss on dynamic tasks.
- Benchmark design should move beyond static images to routinely include time-synced audio and video to match real device use.
- Dependency-level annotations allow targeted data collection that emphasizes steps where multiple modalities must align.
- Cross-modal interference from background noise emerges as a specific failure mode that new architectures need to mitigate.
- Agent evaluation pipelines can now quantify the contribution of each modality to overall task success.
Where Pith is reading between the lines
- Similar interleaved benchmarks could be developed for web and desktop interfaces that also deliver audio feedback during user actions.
- Addressing the identified interference issues might improve agent robustness in noisy real-world settings such as public spaces.
- If the gaps are closed, agents could support more fluid combined voice-plus-visual interactions without separate modality handling.
- The dataset's step-level structure makes it possible to test whether architectural changes or simply larger models close the performance gap.
Load-bearing premise
That foundational omni-modal models can serve as valid stand-ins for the dedicated omni-modal GUI agent frameworks that the paper notes are still nascent.
What would settle it
A dedicated omni-modal GUI agent that maintains the same action-prediction accuracy on high multimodal-dependency steps as on static-visual steps when evaluated on the OmniGUI dataset would falsify the reported performance degradation.
Figures




read the original abstract
Current benchmarks for graphical user interface (GUI) agents predominantly rely on static screenshots. However, real-world smartphone interaction routinely requires agents to process transient audio cues and temporal video dynamics that are tightly coupled with the moment of action. To bridge this gap, we introduce OmniGUI, the first step-level benchmark designed to evaluate GUI agents in omni-modal smartphone environments. OmniGUI provides continuous, interleaved multimodal inputs comprising static images, synchronous audio, and video clips at every action step. The dataset encompasses 709 expert-demonstrated episodes (2,579 action steps) across 29 applications, systematically annotated with objective multimodal dependency levels. Because dedicated omni-modal GUI agent frameworks are currently in their nascent stage, we select foundational omni-modal models capable of natively processing interleaved inputs to serve as agent proxies for our initial baselines. Our empirical evaluation reveals that while current models exhibit competency on visually static tasks, their action prediction performance degrades significantly in environments requiring synchronous temporal and auditory signals. Furthermore, ablation studies isolate specific operational bottlenecks, notably cross-modal interference when processing task-irrelevant environmental noise. The complete dataset, evaluation pipeline, and baseline prompts are provided in the supplementary material. Project page: https://omni-gui.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OmniGUI, a novel step-level benchmark for GUI agents operating in omni-modal smartphone environments. It consists of 709 expert-demonstrated episodes comprising 2,579 action steps across 29 applications. Each step provides interleaved multimodal inputs including static images, synchronous audio, and video clips. Episodes are annotated with objective multimodal dependency levels. Since dedicated omni-modal GUI agent frameworks are nascent, the authors use foundational omni-modal models as agent proxies for baselines. The evaluation shows competency on visually static tasks but significant degradation in action prediction for tasks requiring synchronous temporal and auditory signals, with ablations identifying cross-modal interference from task-irrelevant noise. The dataset, pipeline, and prompts are made available.
Significance. If the findings hold, this benchmark fills an important gap by evaluating GUI agents beyond static screenshots in dynamic, multimodal settings that mirror real smartphone use. The identification of performance bottlenecks related to temporal and auditory signals, along with the provision of the full dataset, evaluation pipeline, and baseline prompts, supports reproducibility and could stimulate development of specialized omni-modal GUI agents. This is a strength for a benchmark paper.
major comments (2)
- [Baselines and Evaluation] The central claim that action prediction degrades specifically in environments requiring synchronous temporal and auditory signals rests on baselines using general-purpose foundational omni-modal models selected as proxies. The manuscript notes that dedicated frameworks are nascent, but without additional evidence or discussion that these proxies' failure modes in processing interleaved video-audio inputs correspond to those expected in future GUI-specialized agents, the degradation could reflect broad architectural limitations rather than the benchmark's multimodal dependency levels. This is load-bearing for attributing the results to the environment characteristics.
- [Dataset and Annotations] While the abstract and introduction describe systematic annotation with objective multimodal dependency levels and mention ablation studies on cross-modal interference, the full manuscript should provide more detail on the annotation process, inter-annotator agreement if applicable, and distribution of dependency levels (e.g., in a table or section on data statistics) to allow readers to evaluate the balance and validity of the claims regarding performance across different dependency types.
minor comments (2)
- [Abstract] The abstract mentions 'the complete dataset, evaluation pipeline, and baseline prompts are provided in the supplementary material' but does not specify the exact location or access method beyond the project page; consider adding a direct link or DOI if available.
- [Overall] Ensure that all figures and tables in the full manuscript clearly label the multimodal inputs and dependency levels for each example to aid reader understanding.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our manuscript. We address each of the major comments below and have made revisions to the manuscript to incorporate the feedback where appropriate.
read point-by-point responses
-
Referee: [Baselines and Evaluation] The central claim that action prediction degrades specifically in environments requiring synchronous temporal and auditory signals rests on baselines using general-purpose foundational omni-modal models selected as proxies. The manuscript notes that dedicated frameworks are nascent, but without additional evidence or discussion that these proxies' failure modes in processing interleaved video-audio inputs correspond to those expected in future GUI-specialized agents, the degradation could reflect broad architectural limitations rather than the benchmark's multimodal dependency levels. This is load-bearing for attributing the results to the environment characteristics.
Authors: We appreciate the referee's concern regarding the generalizability of our baseline results to future specialized agents. As noted in the manuscript, dedicated omni-modal GUI agent frameworks are nascent, which is why we employed foundational models as proxies. Our primary goal is to establish a benchmark that highlights performance gaps in current multimodal processing capabilities for GUI tasks. The observed degradation in action prediction for tasks with high temporal and auditory dependencies demonstrates the challenges even for models designed to handle interleaved inputs. We have added a new subsection in the Discussion to elaborate on how these findings can inform the design of future GUI-specialized agents, including potential architectural improvements to mitigate cross-modal interference. We believe this strengthens the attribution to the benchmark's characteristics while acknowledging the proxy nature of the baselines. revision: partial
-
Referee: [Dataset and Annotations] While the abstract and introduction describe systematic annotation with objective multimodal dependency levels and mention ablation studies on cross-modal interference, the full manuscript should provide more detail on the annotation process, inter-annotator agreement if applicable, and distribution of dependency levels (e.g., in a table or section on data statistics) to allow readers to evaluate the balance and validity of the claims regarding performance across different dependency types.
Authors: We agree with the referee that more details on the annotation process and data statistics would improve clarity. In the revised manuscript, we have added a dedicated subsection under 'Dataset Construction' that describes the objective annotation process in detail. The multimodal dependency levels are determined algorithmically based on explicit criteria: presence of audio signals, requirement for temporal video analysis, and visual-only sufficiency. As the process is objective and rule-based, inter-annotator agreement does not apply. Additionally, we have included Table X in the main text showing the distribution of dependency levels across the 2,579 steps, with breakdowns by application category. This allows readers to assess the balance of the dataset. revision: yes
Circularity Check
No circularity: benchmark introduction with direct empirical reporting
full rationale
The paper introduces OmniGUI as a new step-level benchmark for omni-modal GUI agents, provides dataset details (709 episodes, 2,579 steps across 29 apps), and reports action prediction performance of selected foundational omni-modal models used explicitly as proxies because dedicated GUI frameworks are nascent. No equations, parameter fitting, predictions derived from fits, or self-citation chains appear in the provided text. The central empirical observation (performance degradation on synchronous temporal/auditory tasks) is presented as a direct result of running the baselines on the annotated episodes, with no reduction of any claimed result to its own inputs by construction. This is a standard benchmark paper whose claims rest on external model evaluations rather than internal self-definition or renaming.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert-demonstrated episodes accurately represent typical user interactions with the 29 applications.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
OmniGUI provides continuous, interleaved multimodal inputs—comprising static images, synchronous audio, and video clips—at every action step... systematically annotated with objective multimodal dependency levels.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
performance degrades significantly in environments requiring synchronous temporal and auditory signals... cross-modal interference when processing task-irrelevant environmental noise
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2406.10819 (2024)
Chen, D., Huang, Y., Wu, S., Tang, J., Chen, L., Bai, Y., He, Z., Wang, C., Zhou, H., Li, Y., et al.: Gui-world: A video benchmark and dataset for multimodal gui- oriented understanding. arXiv preprint arXiv:2406.10819 (2024)
-
[2]
Cheng, K., Sun, Q., Chu, Y., Xu, F., YanTao, L., Zhang, J., Wu, Z.: Seeclick: Harnessing gui grounding for advanced visual gui agents. In: Proceedings of the XPeng Motors14 OmniGUIarXiv Preprint 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 9313–9332 (2024)
work page 2024
- [3]
-
[4]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Advances in Neural Information Processing Systems36, 28091–28114 (2023)
Deng, X., Gu, Y., Zheng, B., Chen, S., Stevens, S., Wang, B., Sun, H., Su, Y.: Mind2web: Towards a generalist agent for the web. Advances in Neural Information Processing Systems36, 28091–28114 (2023)
work page 2023
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24108–24118 (2025)
work page 2025
-
[7]
Vita: Towards open-source interactive omni multimodal llm
Fu, C., Lin, H., Long, Z., Shen, Y., Dai, Y., Zhao, M., Zhang, Y.F., Dong, S., Li, Y., Wang, X., et al.: Vita: Towards open-source interactive omni multimodal llm. arXiv preprint arXiv:2408.05211 (2024)
-
[8]
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Fu, C., Lin, H., Wang, X., Zhang, Y.F., Shen, Y., Liu, X., Li, Y., Long, Z., Gao, H., Li, K., et al.: Vita-1.5: Towards gpt-4o level real-time vision and speech interaction. arXiv preprint arXiv:2501.01957 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Gemini Team, G.: Gemini 3: A family of highly capable multimodal models. Tech. rep., Google DeepMind (2025),https://deepmind.google/technologies/ gemini/, technical Report
work page 2025
-
[10]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hong, W., Wang, W., Lv, Q., Xu, J., Yu, W., Ji, J., Wang, Y., Wang, Z., Dong, Y., Ding, M., et al.: Cogagent: A visual language model for gui agents. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14281–14290 (2024)
work page 2024
-
[11]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
arXiv preprint arXiv:2410.19100
Jang, L., Li, Y., Zhao, D., Ding, C., Lin, J., Liang, P.P., Bonatti, R., Koishida, K.: Videowebarena: Evaluating long context multimodal agents with video under- standing web tasks. arXiv preprint arXiv:2410.19100 (2024)
-
[13]
Baichuan-omni-1.5 technical report
Li, Y., Liu, J., Zhang, T., Chen, S., Li, T., Li, Z., Liu, L., Ming, L., Dong, G., Pan, D., et al.: Baichuan-omni-1.5 technical report. arXiv preprint arXiv:2501.15368 (2025)
-
[14]
Omnibench: Towards the future of universal omni-language models,
Li, Y., Ma, Y., Zhang, G., Yuan, R., Zhu, K., Guo, H., Liang, Y., Liu, J., Wang, Z., Yang, J., et al.: Omnibench: Towards the future of universal omni-language models. arXiv preprint arXiv:2409.15272 (2024)
-
[15]
Lin, K.Q., Li, L., Gao, D., Wu, Q., Yan, M., Yang, Z., Wang, L., Shou, M.Z.: Videogui: A benchmark for gui automation from instructional videos. In: NeurIPS (2024)
work page 2024
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lu, Q., Shao, W., Liu, Z., Du, L., Meng, F., Li, B., Chen, B., Huang, S., Zhang, K., Luo, P.: Guiodyssey: A comprehensive dataset for cross-app gui navigation on mobile devices. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 22404–22414 (2025)
work page 2025
-
[17]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Rawles, C., Clinckemaillie, S., Chang, Y., Waltz, J., Lau, G., Fair, M., Li, A., Bishop, W., Li, W., Campbell-Ajala, F., et al.: Androidworld: A dynamic bench- XPeng Motors15 OmniGUIarXiv Preprint marking environment for autonomous agents. arXiv preprint arXiv:2405.14573 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Advances in Neural Information Processing Systems36, 59708–59728 (2023)
Rawles, C., Li, A., Rodriguez, D., Riva, O., Lillicrap, T.: Androidinthewild: A large-scale dataset for android device control. Advances in Neural Information Processing Systems36, 59708–59728 (2023)
work page 2023
-
[19]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Sakshi, S., Tyagi, U., Kumar, S., Seth, A., Selvakumar, R., Nieto, O., Duraiswami, R., Ghosh, S., Manocha, D.: Mmau: A massive multi-task audio understanding and reasoning benchmark. arXiv preprint arXiv:2410.19168 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Song, E., Chai, W., Xu, W., Xie, J., Liu, Y., Wang, G.: Video-mmlu: A mas- sive multi-discipline lecture understanding benchmark. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6099–6113 (2025)
work page 2025
-
[21]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Team, G., Georgiev, P., Lei, V.I., Burnell, R., Bai, L., Gulati, A., Tanzer, G., Vin- cent,D.,Pan,Z.,Wang,S.,etal.:Gemini1.5:Unlockingmultimodalunderstanding across millions of tokens of context. arXiv preprint arXiv:2403.05530 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [22]
-
[23]
Advances in Neural Information Processing Systems37, 52040–52094 (2024)
Xie, T., Zhang, D., Chen, J., Li, X., Zhao, S., Cao, R., Hua, T.J., Cheng, Z., Shin, D., Lei, F., et al.: Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems37, 52040–52094 (2024)
work page 2024
-
[24]
Xu, J., Guo, Z., Hu, H., Chu, Y., Wang, X., He, J., Wang, Y., Shi, X., He, T., Zhu, X., Lv, Y., Wang, Y., Guo, D., Wang, H., Ma, L., Zhang, P., Zhang, X., Hao, H., Guo, Z., Yang, B., Zhang, B., Ma, Z., Wei, X., Bai, S., Chen, K., Liu, X., Wang, P., Yang, M., Liu, D., Ren, X., Zheng, B., Men, R., Zhou, F., Yu, B., Yang, J., Yu, L., Zhou, J., Lin, J.: Qwen3...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Yang, Y., Zhuang, J., Sun, G., Tang, C., Li, Y., Li, P., Jiang, Y., Li, W., Ma, Z., Zhang, C.: Audio-centric video understanding benchmark without text shortcut. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 6580–6598 (2025)
work page 2025
-
[26]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yao, Y., Yu, T., Zhang, A., Wang, C., Cui, J., Zhu, H., Cai, T., Li, H., Zhao, W., He, Z., et al.: Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv:2408.01800 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
In: European Conference on Computer Vision
You, K., Zhang, H., Schoop, E., Weers, F., Swearngin, A., Nichols, J., Yang, Y., Gan, Z.: Ferret-ui: Grounded mobile ui understanding with multimodal llms. In: European Conference on Computer Vision. pp. 240–255. Springer (2024)
work page 2024
-
[28]
In: Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems
Zhang, C., Yang, Z., Liu, J., Li, Y., Han, Y., Chen, X., Huang, Z., Fu, B., Yu, G.: Appagent: Multimodal agents as smartphone users. In: Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. pp. 1–20 (2025)
work page 2025
-
[29]
GPT-4V(ision) is a Generalist Web Agent, if Grounded
Zheng, B., Gou, B., Kil, J., Sun, H., Su, Y.: Gpt-4v (ision) is a generalist web agent, if grounded. arXiv preprint arXiv:2401.01614 (2024) A Experimental Details Thissectiondetailstheexactprompttemplates,usermessagestructures,andhy- perparameter configurations used in our evaluations. All evaluated models share an identical prompt structure without any m...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [30]
-
[31]
(optional) Image: <history screenshot from step t-2>
-
[32]
(optional) Video: <current step video clip>
-
[33]
(optional) Audio: <current step environment audio>
-
[35]
Step N: {action_text_N} Analyze the current screenshot and output the next action as JSON
Text: <prompt text –- see below> –- Prompt Text –- Goal: {task_description} Step: {current_step_index} Action History: Step 0: {action_text_0} Step 1: {action_text_1} ... Step N: {action_text_N} Analyze the current screenshot and output the next action as JSON. Ablation Configurations.For the ablation experiments, the input structures are deterministicall...
-
[36]
(optional) Audio: <current step environment audio> [4.1] Audio: <TTS spoken instruction .wav file>
-
[37]
Image: <current screenshot>
-
[38]
Text: <prompt text –- see below> –- Prompt Text –- Goal: [Please listen to the voice instruction] Step: {current_step_index} ... A.2 Model Configurations and Hyperparameters To ensure deterministic, reproducible outputs and to evaluate the models’ most confident decision boundaries, we enforced greedy decoding strategies across all evaluations. Table 6 de...
-
[39]
Directory Structure.Listing B.1 illustrates the standard directory hierarchy for a given application (e.g.,TED). The episode-level metadata is distributed across five.jsonlfiles, corresponding to the cognitive task dimensions. The mediadirectory encapsulates individual episode folders, which store the atomic step-level data including interleaved video cli...
-
[40]
Episode-Level Metadata (.jsonl).The.jsonlfiles store the task descriptions for each episode. Listing B.1 presents a snippet from theTEDapplication. These bilingual instructions map directly to the{task_description}placeholder in the unified evaluation prompt. Listing 2: Episode metadata format (Snippet from temporal_reasoning.jsonl) {"ID": "T0547", "app":...
-
[41]
Step-Level Execution Trace (.json).Inside each episode’s media folder, a spe- cific JSON file logs the chronological action sequence. Listing B.1 presents a snippet from an AV-Critical episode, demonstrating how waiting states (NONE) and execution states (TAP) are recorded alongside precise target bounding boxes. Listing 3: Step-level execution trace (Sni...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.