RecoAtlas: From Semantic Plausibility to Set-Level Utility in LLM Recommendation Agents
Pith reviewed 2026-05-20 22:22 UTC · model grok-4.3
The pith
RecoAtlas benchmark shows that semantic plausibility in LLM shopping reports does not capture behavior-grounded set utility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
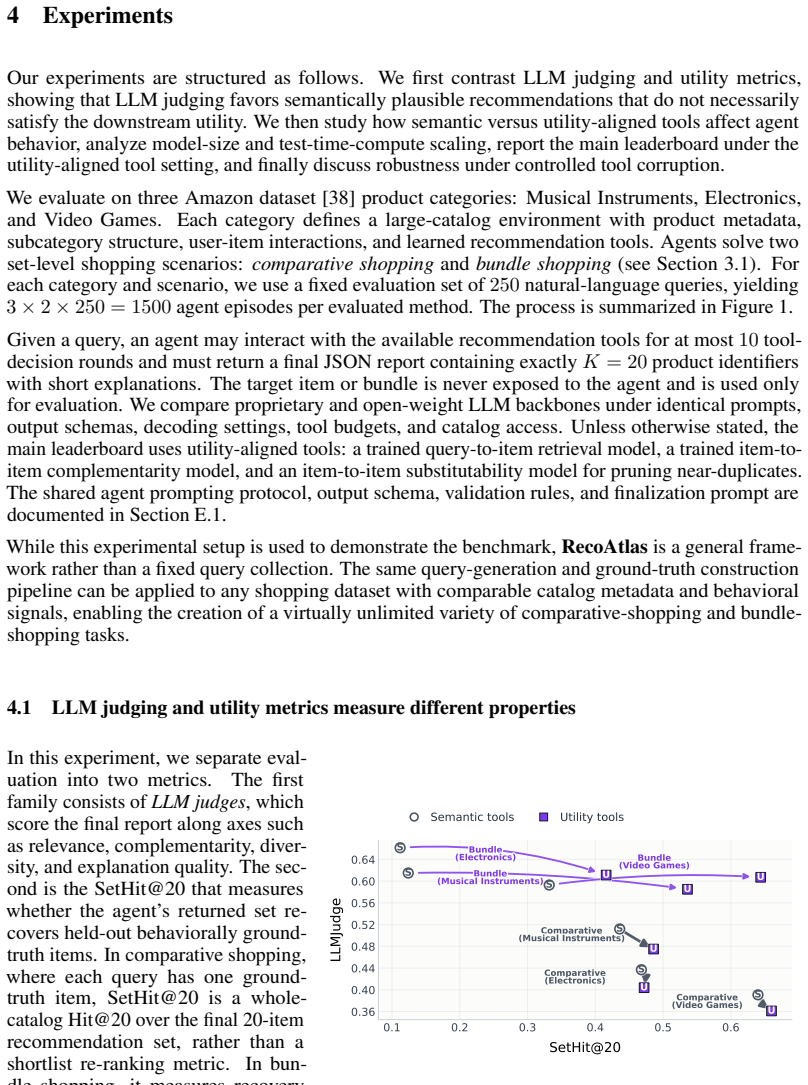
RecoAtlas equips evaluation of shopping agents with held-out interaction metrics plus learned proxies for relevance, complementarity, and diversity derived from interaction data, while separately scoring semantic coherence and explanation quality. Its controlled tool environment lets agents face semantic, behavior-aligned, or faulty signals so that gains can be attributed to reasoning, signal quality, or tool-use policy. Experiments confirm that performance scales with model capacity and test-time compute, improves with stronger aligned tools, degrades under misalignment, and that semantic plausibility does not necessarily reflect behavior-grounded utility of the resulting recommendation set
What carries the argument
The controlled tool environment that supplies agents with either semantic, behavior-aligned, or faulty tools while scoring both semantic coherence and learned utility proxies for relevance, complementarity, and diversity derived from interaction data.
If this is right
- Agent performance increases with greater model capacity and additional test-time compute.
- Performance rises when agents receive stronger and better-aligned tools.
- Performance falls when agents receive noisy or misaligned signals.
- Semantic plausibility of reports does not necessarily indicate set-level behavior-grounded utility.
Where Pith is reading between the lines
- Future agent training loops could incorporate the behavior-derived utility proxies directly rather than relying only on semantic feedback.
- The separation of semantic and utility signals offers a template for evaluating generative agents in other domains where plausible text must be checked against measurable outcomes.
- Benchmarks for agentic systems may need to include explicit tool-quality controls to isolate the contribution of reasoning from the quality of external signals.
Load-bearing premise
The learned utility proxies for relevance, complementarity, and diversity derived from interaction data accurately reflect real user behavior and preferences in the target shopping domain.
What would settle it
A live A/B test in which users receive recommendation sets chosen to maximize RecoAtlas utility scores versus sets chosen to maximize semantic plausibility scores, with the outcome measured by click-through or conversion rates, would settle whether the distinction holds.
Figures







read the original abstract
LLM recommendation agents increasingly produce structured recommendation reports: sets of items accompanied by natural-language justifications. Yet existing evaluations often reduce this setting to reranking small shortlisted candidate sets or judge reports mainly by semantic plausibility. We introduce Recommendation Atlas (Agentic Tool-Level Assessment for Shopping), or RecoAtlas, a benchmark and toolkit for evaluating shopping agents with behavior-grounded metrics. RecoAtlas complements held-out interaction metrics with learned utility proxies for relevance, complementarity, and diversity derived from interaction data, while separately measuring semantic coherence and explanation quality. Its controlled tool environment exposes agents to either semantic, behavior-aligned, or faulty tools, enabling diagnosis of whether performance gains arise from stronger reasoning, better signals, or more effective tool-use policies. Across controlled experiments, we show that RecoAtlas exhibits key properties of a meaningful benchmark for agentic systems: performance scales with model capacity and test-time compute, improves with stronger and better-aligned tools, degrades under noisy or misaligned signals, and reveals that semantic plausibility does not necessarily capture behavior-grounded utility. RecoAtlas provides a foundation for developing and evaluating shopping assistants that optimize not only for plausible recommendations, but also for coherent, behaviorally grounded recommendation sets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RecoAtlas, a benchmark and toolkit for evaluating LLM-based shopping recommendation agents. It complements held-out interaction metrics with learned utility proxies for relevance, complementarity, and diversity derived from interaction data, while also measuring semantic coherence and explanation quality. Controlled experiments vary model capacity, test-time compute, tool alignment, and signal noise to show that performance scales with capacity and compute, improves with stronger aligned tools, degrades under faulty signals, and that semantic plausibility does not necessarily reflect behavior-grounded utility.
Significance. If the learned proxies are independently validated against held-out user behaviors without leakage, RecoAtlas would offer a useful diagnostic framework for agentic recommendation systems, clarifying when gains come from reasoning versus tool signals and separating semantic from utility evaluation. The scaling and tool-alignment results could inform development of shopping assistants that optimize for coherent, behaviorally grounded sets.
major comments (3)
- [Abstract] Abstract and utility-proxy construction: the claim that proxies capture 'behavior-grounded utility' distinct from semantic plausibility rests on their derivation from interaction data, yet no details are given on the training objective, feature set, or explicit correlation checks (e.g., against purchase rates or click sequences withheld from proxy fitting). This is load-bearing for the dissociation result and for interpreting the scaling/tool-alignment experiments.
- [Experimental setup] Data-split and leakage section: the manuscript states that held-out interaction metrics are used alongside the proxies, but does not specify whether the interaction data used to fit the relevance/complementarity/diversity proxies overlaps with the held-out sets or shares the same user-item distribution. Without an independent validation split or reported correlation to external behavioral signals, the separation between semantic and utility signals risks being artifactual.
- [Results] Table or figure reporting proxy validation: no quantitative evidence (e.g., proxy-to-held-out correlation coefficients or ablation on proxy training data) is referenced to confirm that the learned proxies track real user behavior rather than overfitting to the training interactions. This directly affects the interpretability of the 'semantic plausibility does not capture utility' finding.
minor comments (2)
- [Method] Notation for the three utility proxies (relevance, complementarity, diversity) should be defined once with explicit formulas or pseudocode rather than described only in prose.
- [Figures] Figure captions for the scaling and tool-alignment plots should include error bars or statistical significance markers to support the reported trends.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments correctly identify areas where additional clarity on proxy construction, data handling, and validation would strengthen the interpretability of RecoAtlas. We address each major comment below and will revise the manuscript accordingly to incorporate the requested details without altering the core claims or experimental design.
read point-by-point responses
-
Referee: [Abstract] Abstract and utility-proxy construction: the claim that proxies capture 'behavior-grounded utility' distinct from semantic plausibility rests on their derivation from interaction data, yet no details are given on the training objective, feature set, or explicit correlation checks (e.g., against purchase rates or click sequences withheld from proxy fitting). This is load-bearing for the dissociation result and for interpreting the scaling/tool-alignment experiments.
Authors: The proxies are derived from interaction data as summarized in the methods, using models trained to predict observed user behaviors such as purchases and co-occurrences. We agree that the manuscript would benefit from expanded description of the precise training objective, input features (e.g., item metadata and sequence statistics), and quantitative checks against withheld signals. In the revision we will add these specifics to the proxy construction subsection and include correlation results with held-out purchase indicators to support the dissociation between semantic plausibility and behavior-grounded utility. revision: yes
-
Referee: [Experimental setup] Data-split and leakage section: the manuscript states that held-out interaction metrics are used alongside the proxies, but does not specify whether the interaction data used to fit the relevance/complementarity/diversity proxies overlaps with the held-out sets or shares the same user-item distribution. Without an independent validation split or reported correlation to external behavioral signals, the separation between semantic and utility signals risks being artifactual.
Authors: The experimental setup employs a temporal split in which proxy training occurs on earlier interactions while held-out metrics are computed on later periods, ensuring instance-level disjointness. We acknowledge that the current text does not explicitly rule out distributional overlap or describe an independent validation split for the proxies themselves. The revision will include a dedicated paragraph and diagram clarifying the split ratios, confirming that proxy fitting and held-out evaluation use non-overlapping user-item instances drawn from the same overall distribution, and noting any available external behavioral correlations. revision: yes
-
Referee: [Results] Table or figure reporting proxy validation: no quantitative evidence (e.g., proxy-to-held-out correlation coefficients or ablation on proxy training data) is referenced to confirm that the learned proxies track real user behavior rather than overfitting to the training interactions. This directly affects the interpretability of the 'semantic plausibility does not capture utility' finding.
Authors: The dissociation result is currently supported by the divergence observed across controlled conditions in the main experiments. We agree that direct quantitative validation evidence would improve rigor and address potential overfitting concerns. The revised manuscript will add a new table (or subsection) reporting proxy-to-held-out correlation coefficients together with an ablation on training data volume to demonstrate that the proxies track real user behavior. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces RecoAtlas as a benchmark that pairs held-out interaction metrics with separately learned utility proxies for relevance, complementarity, and diversity, while measuring semantic coherence independently. No equations, self-citations, or ansatzes are quoted that reduce the central claims (scaling with model capacity, tool alignment effects, or semantic-vs-utility separation) to fitted inputs or prior author work by construction. The described evaluation structure treats the proxies as derived from interaction data but complements them with held-out sets and controlled tool environments, keeping the diagnostic claims externally falsifiable rather than tautological. This is the most common honest outcome for a benchmark paper whose core contribution is an experimental toolkit rather than a closed-form derivation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
learned utility proxies for relevance, complementarity, and diversity derived from interaction data
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
performance scales with model capacity and test-time compute, improves with stronger and better-aligned tools
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yu Shang, Peijie Liu, Yuwei Yan, Zijing Wu, Leheng Sheng, Yuanqing Yu, Chumeng Jiang, An Zhang, Fengli Xu, Yu Wang, Min Zhang, and Yong Li. Agentrecbench: Benchmarking llm agent-based personalized recommender systems.arXiv preprint arXiv:2505.19623, 2025
-
[2]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating LLMs as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
GAIA: a benchmark for General AI Assistants
Grégoire Mialon, Roberto Dessì, Maria Lomeli, David Esiobu, Yizhong Chen, Kai Arulkumaran, Antoine Cully, Cyprien de Masson d’Autume, Hadi Eshragh, Nacér Hassen, Zachary Kenton, Andrew Li, Aravind Mahendran, Daniel Mankowitz, Piotr Mirowski, Anna Rogers, Hubert Soyer, Nino Vieillard, Martha White, Yuting Yang, et al. GAIA: A benchmark for general AI assis...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Qiantong Xu, Fenglu Hong, Bo Li, Changran Hu, Zhengyu Chen, and Jian Zhang. On the tool manipulation capability of open-source large language models.arXiv preprint arXiv:2305.16504, 2023
-
[6]
Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models
Zhicheng Guo, Sijie Cheng, Hao Wang, Shihao Liang, Yujia Qin, Peng Li, Zhiyuan Liu, Maosong Sun, and Yang Liu. Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 11143–11156, Bangkok, Thailand, 2024. Association for Computational L...
work page 2024
-
[7]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive apis.arXiv preprint arXiv:2305.15334, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.arXiv preprint arXiv:2207.01206, 2022
-
[9]
Yilun Jin, Zheng Li, Chenwei Zhang, Tianyu Cao, Yifan Gao, Pratik Jayarao, Mao Li, Xin Liu, Ritesh Sarkhel, Xianfeng Tang, Haodong Wang, Zhengyang Wang, Wenju Xu, Jingfeng Yang, Qingyu Yin, Xian Li, Priyanka Nigam, Yi Xu, Kai Chen, Qiang Yang, Meng Jiang, and Bing Yin. Shopping mmlu: A massive multi-task online shopping benchmark for large language models...
-
[10]
Shoppingbench: A real-world intent-grounded shopping benchmark for llm-based agents
Jiangyuan Wang, Kejun Xiao, Qi Sun, Huaipeng Zhao, Tao Luo, Jian Dong Zhang, and Xiaoyi Zeng. Shoppingbench: A real-world intent-grounded shopping benchmark for llm-based agents. arXiv preprint arXiv:2508.04266, 2025
-
[11]
WebMall -- A Multi-Shop Benchmark for Evaluating Web Agents
Ralph Peeters, Aaron Steiner, Luca Schwarz, Julian Yuya Caspary, and Christian Bizer. Webmall – a multi-shop benchmark for evaluating web agents.arXiv preprint arXiv:2508.13024, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Shoppingcomp: Are llms really ready for your shopping cart?arXiv preprint arXiv:2511.22978, 2025
Huaixiao Tou, Ying Zeng, Cong Ma, Muzhi Li, Minghao Li, Weijie Yuan, He Zhang, and Kai Jia. Shoppingcomp: Are llms really ready for your shopping cart?arXiv preprint arXiv:2511.22978, 2025
-
[13]
Deepshop: A benchmark for deep research shopping agents.arXiv preprint arXiv:2506.02839, 2025
Yougang Lyu, Xiaoyu Zhang, Lingyong Yan, Maarten de Rijke, Zhaochun Ren, and Xi- uying Chen. Deepshop: A benchmark for deep research shopping agents.arXiv preprint arXiv:2506.02839, 2025
-
[14]
Recmind: Large language model powered agent for recommendation.arXiv preprint arXiv:2308.14296, 2023
Yancheng Wang, Ziyan Jiang, Zheng Chen, Fan Yang, Yingxue Zhou, Eunah Cho, Xing Fan, Xiaojiang Huang, Yanbin Lu, and Yingzhen Yang. Recmind: Large language model powered agent for recommendation.arXiv preprint arXiv:2308.14296, 2023
-
[15]
Let me do it for you: Towards llm empowered recommendation via tool learning
Yuyue Zhao, Jiancan Wu, Xiang Wang, Wei Tang, Dingxian Wang, and Maarten de Rijke. Let me do it for you: Towards llm empowered recommendation via tool learning. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1796–1806. Association for Computing Machinery, 2024
work page 2024
-
[16]
Chengkai Huang, Junda Wu, Yu Xia, et al. Towards agentic recommender systems in the era of multimodal large language models.arXiv preprint arXiv:2503.16734, 2025
-
[17]
A survey on llm-powered agents for recommender systems.arXiv preprint arXiv:2502.10050, 2025
Qiyao Peng, Hongtao Liu, Hua Huang, Qing Yang, and Minglai Shao. A survey on llm-powered agents for recommender systems.arXiv preprint arXiv:2502.10050, 2025
-
[18]
Slateq: A tractable decomposition for reinforcement learning with recommendation sets
Eugene Ie, Vihan Jain, Jing Wang, Sanmit Narvekar, Ritesh Agarwal, Rui Wu, Heng-Tze Cheng, Morgane Lustman, Vince Gatto, Paul Covington, Jim McFadden, Tushar Chandra, and Craig Boutilier. Slateq: A tractable decomposition for reinforcement learning with recommendation sets. InProceedings of the Twenty-Eighth International Joint Conference on Artificial In...
work page 2019
-
[19]
Slate-aware ranking for recommendation
Yi Ren, Xiao Han, Xu Zhao, Shenzheng Zhang, and Yan Zhang. Slate-aware ranking for recommendation. InProceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, pages 499–507. Association for Computing Machinery, 2023. 11
work page 2023
-
[20]
Generative slate recommendation with reinforcement learning
Romain Deffayet, Thibault Thonet, Walid Bendada, Guillaume Bisson, Fabrice Popineau, Lynda Tamine, and Jefrey Lijffijt. Generative slate recommendation with reinforcement learning. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, pages 580–588. Association for Computing Machinery, 2023
work page 2023
-
[21]
Generating and personalizing bundle recommendations on steam
Apurva Pathak, Kshitiz Gupta, and Julian McAuley. Generating and personalizing bundle recommendations on steam. InProceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1073–1076. Association for Computing Machinery, 2017
work page 2017
-
[22]
Matching user with item set: Collaborative bundle recommendation with deep attention network
Liang Chen, Yang Liu, Xiangnan He, Lianli Gao, and Zibin Zheng. Matching user with item set: Collaborative bundle recommendation with deep attention network. InProceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, pages 2095–2101. International Joint Conferences on Artificial Intelligence Organization, 2019
work page 2095
-
[23]
Bundle recommendation with graph convolutional networks
Jianxin Chang, Chen Gao, Xiangnan He, Depeng Jin, and Yong Li. Bundle recommendation with graph convolutional networks. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1673–1676. Association for Computing Machinery, 2020
work page 2020
-
[24]
Diversity in recommender systems–a survey.Knowledge- Based Systems, 123:154–162, 2017
Matevž Kunaver and Tomaž Požrl. Diversity in recommender systems–a survey.Knowledge- Based Systems, 123:154–162, 2017
work page 2017
-
[25]
Marius Kaminskas and Derek Bridge. Diversity, serendipity, novelty, and coverage: A sur- vey and empirical analysis of beyond-accuracy objectives in recommender systems.ACM Transactions on Interactive Intelligent Systems, 7(1), 2016
work page 2016
-
[26]
Inferring networks of substitutable and complementary products
Julian McAuley et al. Inferring networks of substitutable and complementary products. In Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2015
work page 2015
-
[27]
P-companion: A principled framework for diversified complementary product recom- mendation
Junheng Hao, Tong Zhao, Jin Li, Xin Luna Dong, Christos Faloutsos, Yizhou Sun, and Wei Wang. P-companion: A principled framework for diversified complementary product recom- mendation. InProceedings of the 29th ACM International Conference on Information and Knowledge Management, pages 2517–2524, 2020
work page 2020
-
[28]
Is it really complementary? revisiting behavior-based labels for complementary recommendation
Kai Sugahara, Chihiro Yamasaki, and Kazushi Okamoto. Is it really complementary? revisiting behavior-based labels for complementary recommendation. InProceedings of the 18th ACM Conference on Recommender Systems (RecSys), 2024
work page 2024
-
[29]
Explainable recommendation: A survey and new perspectives
Yongfeng Zhang and Xu Chen. Explainable recommendation: A survey and new perspectives. Foundations and Trends® in Information Retrieval, 14(1):1–101, 2020
work page 2020
-
[30]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. InAdvances in Neural Information Processing Systems, volume 36, 2024
work page 2024
-
[31]
Humans or llms as the judge? a study on judgement biases.arXiv preprint arXiv:2402.10669, 2024
Haoning Wu et al. Humans or llms as the judge? a study on judgement biases.arXiv preprint arXiv:2402.10669, 2024
-
[32]
Yijiang River Dong, Tiancheng Hu, and Nigel Collier. Can LLM be a personalized judge? In Findings of the Association for Computational Linguistics: EMNLP 2024, 2024
work page 2024
-
[33]
Michael Krumdick, Charles Lovering, Varshini Reddy, Seth Ebner, and Chris Tanner. No free labels: Limitations of LLM-as-a-judge without human grounding.arXiv preprint arXiv:2503.05061, 2025
-
[34]
David Rohde, Stephen Bonner, Travis Dunlop, Flavian Vasile, and Alexandros Karatzoglou. Recogym: A reinforcement learning environment for the problem of product recommendation in online advertising.arXiv preprint arXiv:1808.00720, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
Recsim: A configurable simulation platform for recommender systems
Eugene Ie, Chih-Wei Hsu, Martin Mladenov, Vihan Jain, Sanmit Narvekar, Jing Wang, Rui Wu, and Craig Boutilier. Recsim: A configurable simulation platform for recommender systems. arXiv preprint arXiv:1909.04847, 2019. 12
-
[36]
Martin Mladenov, Chih-Wei Hsu, Vihan Jain, Eugene Ie, Christopher Colby, Nicolas Mayoraz, Hubert Pham, Dustin Tran, Ivan Vendrov, and Craig Boutilier. Recsim NG: Toward principled uncertainty modeling for recommender ecosystems.arXiv preprint arXiv:2103.08057, 2021
-
[37]
Kesen Zhao, Shuchang Liu, Qingpeng Cai, Xiangyu Zhao, Ziru Liu, Dong Zheng, Peng Jiang, and Kun Gai. Kuaisim: A comprehensive simulator for recommender systems.Advances in Neural Information Processing Systems, 36:44880–44897, 2023
work page 2023
-
[38]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Introducing GPT-4.1 in the API, April 2025
OpenAI. Introducing GPT-4.1 in the API, April 2025. Includes GPT-4.1 mini
work page 2025
-
[40]
Grok 4.1 fast and agent tools API, November 2025
xAI. Grok 4.1 fast and agent tools API, November 2025
work page 2025
-
[41]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025
work page 2025
-
[42]
Claude Haiku 4.5 system card, October 2025
Anthropic. Claude Haiku 4.5 system card, October 2025
work page 2025
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, et al. Qwen3 technical report, 2025
work page 2025
-
[44]
Akshara Prabhakar, Zuxin Liu, Ming Zhu, Jianguo Zhang, Tulika Awalgaonkar, Shiyu Wang, Zhiwei Liu, Haolin Chen, Thai Hoang, et al. APIGen-MT: Agentic pipeline for multi-turn data generation via simulated agent-human interplay.arXiv preprint arXiv:2504.03601, 2025
-
[45]
Llama-Nemotron: Efficient reasoning models, 2025
Akhiad Bercovich, Itay Levy, Izik Golan, Mohammad Dabbah, Ran El-Yaniv, Omri Puny, et al. Llama-Nemotron: Efficient reasoning models, 2025. 13 A Benchmark artifact build RecoAtlasbuilds one category-specific environment per Amazon product category. Each environment consists of a filtered catalog I, product texts xi for every item i∈ I , subcategory metada...
work page 2025
-
[46]
In the experiments, we use subcategory-adversarial corruption. For search_products and get_complementary_products, let K be the number of clean returned slots and ρ∈[0,1] the faulty-tool rate. The corruption selects round(Kρ) slots uniformly without replacement. Each corrupted slot keeps its displayed score, but its item ID, title, and description are rep...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.