Delta Attention Residuals
Pith reviewed 2026-05-20 20:50 UTC · model grok-4.3
The pith
Attending over layer deltas rather than cumulative states produces higher-contrast routing in attention residuals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
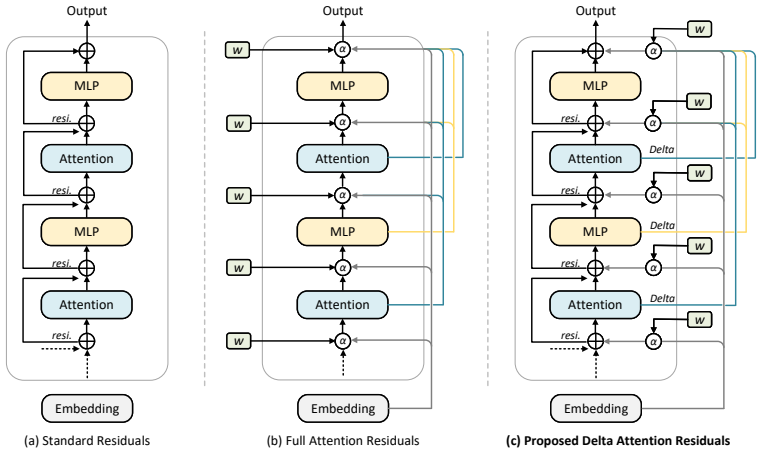
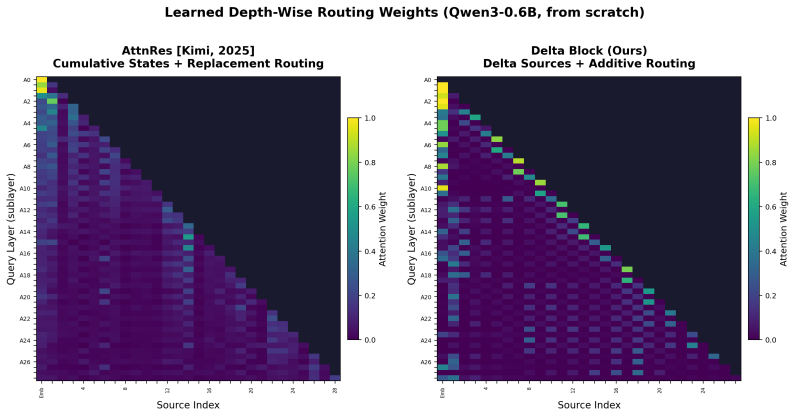
By replacing cumulative hidden states with deltas defined as the difference between consecutive layer outputs, attention residuals achieve attention weights with a maximum around 0.6 instead of 0.2, allowing more selective selection of informative states from previous layers and reducing routing collapse in deep networks.
What carries the argument
Delta representations, computed as the vector difference between a sublayer's input and output, which serve as the basis for the attention computation in the residual connection.
If this is right
- Delta Attention Residuals deliver consistent validation perplexity reductions of 1.7 to 8.2 percent compared to both standard additive residuals and cumulative attention residuals.
- Higher contrast in attention weights enables more effective selective routing of information across layers at both sublayer and block levels.
- Pretrained transformer checkpoints can be adapted to Delta Attention Residuals using ordinary fine-tuning procedures without starting from scratch.
- The performance gains hold across the full range of tested scales from 220M to 7.6B parameters.
Where Pith is reading between the lines
- Delta-based routing might be combined with other layer-wise adaptation techniques to further improve efficiency in very deep models.
- Similar delta concepts could be tested in non-transformer architectures where residual connections are used, to see if redundancy issues appear there as well.
- If the diversity of deltas persists, this method could support scaling to models much larger than 7.6B while maintaining selective information flow.
Load-bearing premise
The structural diversity of delta representations remains the main driver of higher-contrast attention and continues to provide benefits without causing new training instabilities at scales beyond those tested.
What would settle it
Observe the attention weight entropy or maximum weight in the deepest layers of a model using Delta Attention Residuals; if the max weight falls below 0.3 and matches the uniform-like distribution of cumulative attention residuals, the advantage would be falsified.
Figures






read the original abstract
Attention Residuals replace standard additive residual connections with learned softmax attention over previous layer outputs, enabling selective cross-layer routing. However, standard Attention Residuals still attend over cumulative hidden states in previous layers, which are highly redundant. We show that this redundancy leads to routing collapse in deeper layers: attention weights become low-contrast and closer to uniform (max weight ${\approx}$0.2), limiting the model's ability to select informative states in previous layers. This raises a key but underexplored design question: what layer-wise representations should be routed in Attention Residuals? To answer this question, we propose Delta Attention Residuals, which attend over deltas -- the change introduced by each sublayer ($\mathbf{v}_i = \mathbf{h}_{i+1} - \mathbf{h}_i$) -- instead of cumulative states. Delta representations are structurally diverse and yield higher-contrast attention distributions (max weight ${\approx}$0.6), enabling more selective and effective routing across layers. This principle applies at both per-sublayer and block granularity. Across all tested scales (220M--7.6B), Delta Attention Residuals consistently outperform both standard residuals and Attention Residuals, with 1.7--8.2\% validation perplexity gains. Delta Attention Residuals also enables converting pretrained checkpoints into Delta Attention Residuals via standard fine-tuning. Code is available at https://github.com/wdlctc/delta-attention-residuals-code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Delta Attention Residuals, an architectural modification to Attention Residuals in which the attention mechanism operates over delta representations (v_i = h_{i+1} - h_i) rather than cumulative hidden states. This change is motivated by the claim that cumulative states are redundant, leading to low-contrast attention (max weight ≈0.2); deltas are argued to be structurally diverse, producing higher-contrast distributions (max weight ≈0.6) and thereby more effective cross-layer routing. Empirical results report consistent validation perplexity reductions of 1.7–8.2% relative to both standard residuals and Attention Residuals across model scales from 220M to 7.6B parameters, with an additional claim that pretrained checkpoints can be converted via fine-tuning.
Significance. If the performance gains prove robust and the mechanistic account is substantiated, the work offers a lightweight, parameter-free-in-principle change to residual routing that could improve information flow in deep transformers. The reported scale range and the practical conversion procedure are positive features; the public code release supports reproducibility.
major comments (2)
- [Experimental section] Experimental section: The central explanatory claim—that structural diversity of deltas produces higher-contrast attention which in turn drives the perplexity gains—rests on comparisons of complete architectures. No ablation holds the attention mechanism fixed while varying only the redundancy of the attended representations (e.g., deltas versus other decorrelated inputs). Without such isolation, it remains unclear whether the observed increase in max attention weight is causal or merely correlated with other properties of the delta inputs.
- [Results section] Results section: The reported 1.7–8.2% perplexity gains are presented without error bars, multiple random seeds, or statistical significance tests. Given the range of model scales and the modest size of some gains, this omission weakens confidence that the improvements are reliably attributable to the proposed change rather than optimization variance.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a concise citation or one-sentence definition of the baseline 'Attention Residuals' architecture for readers who have not encountered the prior work.
- [Method] Notation for the delta computation (v_i = h_{i+1} - h_i) is clear in the abstract but should be restated with explicit indexing when first introduced in the method description to avoid any ambiguity about sublayer versus block granularity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Experimental section] Experimental section: The central explanatory claim—that structural diversity of deltas produces higher-contrast attention which in turn drives the perplexity gains—rests on comparisons of complete architectures. No ablation holds the attention mechanism fixed while varying only the redundancy of the attended representations (e.g., deltas versus other decorrelated inputs). Without such isolation, it remains unclear whether the observed increase in max attention weight is causal or merely correlated with other properties of the delta inputs.
Authors: We agree that a controlled ablation isolating the effect of input redundancy while holding the attention mechanism fixed would strengthen the causal interpretation. Our current results compare full architectures and show that delta inputs produce higher max attention weights together with consistent perplexity improvements. To address the concern directly, the revised manuscript will include a new ablation that fixes the attention module and varies only the attended representations: cumulative hidden states, delta representations, and additional decorrelated variants (e.g., layer-normalized states and random projections). This will clarify whether the contrast and performance differences arise specifically from the structural properties of deltas. revision: yes
-
Referee: [Results section] Results section: The reported 1.7–8.2% perplexity gains are presented without error bars, multiple random seeds, or statistical significance tests. Given the range of model scales and the modest size of some gains, this omission weakens confidence that the improvements are reliably attributable to the proposed change rather than optimization variance.
Authors: We acknowledge that reporting variability across seeds would increase confidence in the results. Training runs at the largest scales are computationally expensive, which is why we initially reported single-run outcomes. In the revision we add multi-seed results (three independent seeds) with error bars for the 220M and 1B models. For the 7.6B scale we retain the single-run numbers but note the directional consistency of gains across all five scales tested. A short discussion of this limitation has been added to the results section. revision: partial
Circularity Check
No significant circularity detected; architectural change and empirical gains are independently defined and measured
full rationale
The paper defines Delta Attention Residuals via an explicit architectural substitution: attention is performed over per-sublayer deltas v_i = h_{i+1} - h_i instead of cumulative hidden states. This substitution is introduced as a design choice motivated by observed redundancy in cumulative states, not derived from any equation that presupposes the performance outcome. Reported improvements in attention contrast (max weight ≈0.6 versus ≈0.2) and validation perplexity (1.7–8.2 % gains) are obtained from direct experimental comparison on held-out data across model scales; no fitted parameter is relabeled as a prediction, no self-citation chain supplies a load-bearing uniqueness theorem, and no ansatz is smuggled in. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard transformer residual connections and attention mechanisms behave as described in prior literature.
Reference graph
Works this paper leans on
-
[1]
Attention Residuals , author=. arXiv preprint arXiv:2603.15031 , year=
work page internal anchor Pith review arXiv
- [2]
- [3]
- [4]
-
[5]
DenseFormer: Enhancing Information Flow in Transformers via Depth Weighted Average , author=. arXiv preprint arXiv:2402.02622 , year=
- [6]
-
[7]
Hyper-Connections.arXiv preprint arXiv:2409.19606, 2024
Hyper-Connections , author=. arXiv preprint arXiv:2409.19606 , year=
-
[8]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , author=. arXiv preprint arXiv:2406.17557 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Paperno, Denis and Kruszewski, Germ. The. ACL , year=
- [11]
-
[12]
Think you have Solved Question Answering? Try
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal=. Think you have Solved Question Answering? Try
-
[13]
Bisk, Yonatan and Zellers, Rowan and Gao, Jianfeng and Choi, Yejin and others , booktitle=
-
[14]
Sakaguchi, Keisuke and Le Bras, Ronan and Bhagavatula, Chandra and Choi, Yejin , booktitle=
-
[15]
Clark, Christopher and Lee, Kenton and Chang, Ming-Wei and Kwiatkowski, Tom and Collins, Michael and Toutanova, Kristina , booktitle=
- [16]
-
[17]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , journal=
-
[18]
ReZero is All You Need: Fast Convergence at Large Depth , author=. UAI , year=
-
[19]
MUDDFormer: Breaking Residual Bottlenecks in Transformers via Multiway Dynamic Dense Connections , author=. ICML , year=
-
[20]
On Layer Normalization in the Transformer Architecture , author=. ICML , year=
-
[21]
Shazeer, Noam , journal=
- [22]
-
[23]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author=. JMLR , year=
-
[24]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. ICLR , year=
-
[25]
Residual Networks Behave Like Ensembles of Relatively Shallow Networks , author=. NeurIPS , year=
-
[26]
Transformer Circuits Thread , year=
A Mathematical Framework for Transformer Circuits , author=. Transformer Circuits Thread , year=
- [27]
-
[28]
Realformer: Transformer Likes Residual Attention , author=. ACL Findings , year=
-
[29]
DeepNet: Scaling Transformers to 1,000 Layers , author=. arXiv preprint arXiv:2203.00555 , year=
-
[30]
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models , author=. arXiv preprint arXiv:2404.02258 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
mHC: Manifold-Constrained Hyper-Connections
Manifold-Constrained Hyper-Connections , author=. arXiv preprint arXiv:2512.24880 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Residual Stream Duality in Modern Transformer Architectures
Residual Stream Duality in Modern Transformer Architectures , author=. arXiv preprint arXiv:2603.16039 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Deep Delta Learning , author=. arXiv preprint arXiv:2601.00417 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Contrastive Decoding: Open-ended Text Generation as Optimization , author=. ACL , year=
-
[35]
Chuang, Yung-Sung and Xie, Yujia and Luo, Hongyin and Kim, Yoon and Glass, James and He, Pengcheng , booktitle=
- [36]
-
[37]
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.