SPHERICAL KV: Angle-Domain Attention and Rate-Distortion Retention for Efficient Long-Context Inference
Pith reviewed 2026-05-20 20:25 UTC · model grok-4.3
The pith
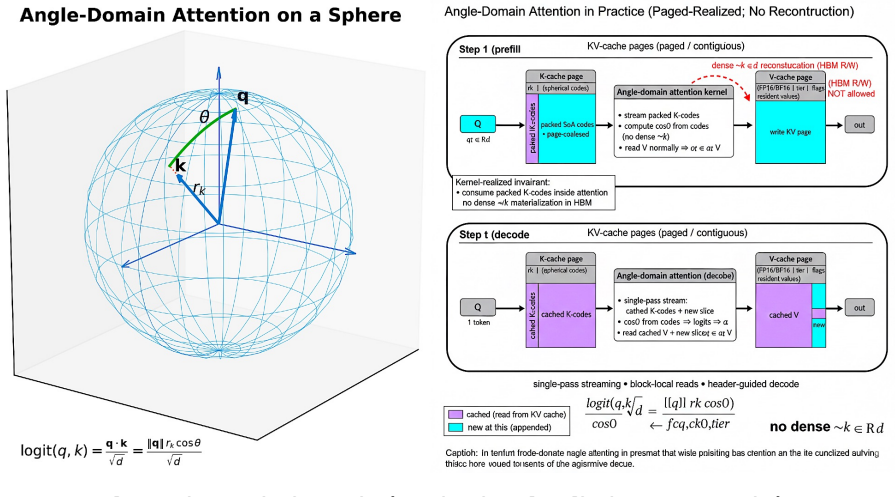
Spherical KV stores each key as a scalar radius plus compact angle codes so attention logits can be computed directly without reconstructing dense vectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Spherical KV treats KV allocation as a rate-distortion problem grounded in attention geometry. Its Angle-Domain Attention component stores keys as a scalar radius together with compact angle codes and computes logits directly from those codes without ever reconstructing the dense key vectors. Its Rate-Distortion Retention component jointly decides keep-or-drop and precision tier for each token and head under a fixed budget, producing tier-homogeneous pages that carry only lightweight metadata and support coalesced reads.
What carries the argument
Angle-Domain Attention, which computes attention logits from spherical radius-plus-angle codes without dense reconstruction, paired with Rate-Distortion Retention that allocates keep/drop and precision tiers under a fixed budget.
If this is right
- KV residency shrinks while the decode path remains paged, block-local, and fusion-friendly.
- HBM traffic in realistic serving settings falls because dense key reconstruction is avoided in the hot loop.
- Tier-homogeneous pages with lightweight metadata enable coalesced reads and simpler memory management.
- Retention and precision decisions are made jointly per token and head under a single fixed budget.
Where Pith is reading between the lines
- The same spherical representation might be applied to value vectors or to attention patterns in other architectures without changing the core decode loop.
- If the utility estimator inside RDR proves stable, the method could be extended to dynamic context lengths that grow or shrink during a single generation.
- Combining the angle-code storage with existing eviction or offloading schemes could produce additive gains on hardware with very tight memory.
Load-bearing premise
That attention logits computed from the spherical angle codes and radius stay close enough to the original dense-key logits, and that future token utility can be estimated reliably enough to avoid quality loss when tokens are dropped or quantized.
What would settle it
A side-by-side run on a long-context benchmark in which the model using Spherical KV shows a clear drop in accuracy or coherence compared with an otherwise identical run that keeps the full dense KV cache.
Figures





read the original abstract
Long-context inference is increasingly constrained by the KV cache: resident memory grows with context length, and decoding becomes limited by repeated High Bandwidth Memory (HBM) streaming rather than arithmetic. Existing methods such as eviction, windowing, quantization, and offloading reduce footprint, but often leave the critical-path bottleneck only partially addressed, especially when compressed states must still be reconstructed into dense vectors during decoding. We present Spherical KV, a long-context inference method that treats KV allocation as a rate-distortion problem grounded in attention geometry for efficient decoding. The method is built on two ideas: (i) represent directional information cheaply in the decode hot loop, and (ii) allocate retention and precision according to estimated future utility. Its first component, Angle-Domain Attention (ADA), stores keys in a spherical parameterization consisting of a scalar radius and compact angle codes, and computes attention logits directly from these codes without reconstructing dense keys. This preserves a paged, block-local, fusion-friendly decode path and directly targets HBM traffic in realistic serving settings. Its second component, Rate-Distortion Retention (RDR), jointly chooses keep/drop decisions and precision tiers per token and head under a fixed budget, producing tier-homogeneous pages with lightweight metadata and coalesced reads. Together, ADA and RDR provide a deployment-oriented mechanism for reducing KV residency while preserving decode efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Spherical KV, a long-context inference technique that frames KV cache allocation as a rate-distortion problem grounded in attention geometry. It introduces Angle-Domain Attention (ADA), which stores keys via a scalar radius and compact angle codes and computes attention logits directly from these codes without reconstructing dense vectors, and Rate-Distortion Retention (RDR), which jointly selects per-token and per-head keep/drop decisions plus precision tiers under a fixed budget to yield tier-homogeneous pages with lightweight metadata.
Significance. If the spherical parameterization and retention policy can be shown to preserve attention distributions and model quality, the method would directly target HBM traffic and KV residency in paged serving systems, offering a deployment-friendly alternative to eviction, quantization, or offloading approaches that still require dense reconstruction.
major comments (2)
- [Abstract / ADA description] Abstract (ADA paragraph): the assertion that logits computed directly from angle codes and radius preserve model quality sufficiently close to full dense keys is load-bearing for both the efficiency and correctness claims, yet the manuscript supplies neither an algebraic identity establishing exact equivalence, a Lipschitz-style bound on the approximation error, nor analysis of how angle-code quantization interacts with the geometry of typical transformer key spaces.
- [Abstract / RDR description] Abstract (RDR paragraph): retention decisions rest on future-utility estimates derived from the approximate logits; without any verification that these estimates remain reliable enough to avoid performance degradation, the keep/drop and tier-selection policy lacks grounding and may undermine the claimed quality retention under fixed budgets.
minor comments (1)
- The description of 'tier-homogeneous pages with lightweight metadata and coalesced reads' would benefit from explicit quantification of metadata overhead and its impact on HBM traffic in realistic serving configurations.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help us improve the clarity and rigor of our presentation. We address each major comment below and describe the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract / ADA description] Abstract (ADA paragraph): the assertion that logits computed directly from angle codes and radius preserve model quality sufficiently close to full dense keys is load-bearing for both the efficiency and correctness claims, yet the manuscript supplies neither an algebraic identity establishing exact equivalence, a Lipschitz-style bound on the approximation error, nor analysis of how angle-code quantization interacts with the geometry of typical transformer key spaces.
Authors: We acknowledge the absence of a formal algebraic identity or Lipschitz bound in the current version. The spherical parameterization is motivated by the observation that attention logits depend primarily on the angular similarity between queries and keys, allowing us to store and compute using radius and angle codes. While exact equivalence does not hold due to quantization, our empirical results across multiple models demonstrate that the resulting attention distributions closely match those of dense keys, with negligible impact on downstream task performance. In the revised manuscript, we will include a dedicated analysis section deriving an upper bound on the logit error as a function of the angle code precision and discussing its implications for typical key vector distributions in transformers. revision: yes
-
Referee: [Abstract / RDR description] Abstract (RDR paragraph): retention decisions rest on future-utility estimates derived from the approximate logits; without any verification that these estimates remain reliable enough to avoid performance degradation, the keep/drop and tier-selection policy lacks grounding and may undermine the claimed quality retention under fixed budgets.
Authors: The referee raises a valid point regarding the grounding of the retention policy. The Rate-Distortion Retention (RDR) uses approximate logits to estimate future utility for keep/drop and tier decisions. To verify reliability, the full paper includes experiments showing that models using RDR maintain performance close to baselines under various budgets. We will revise the manuscript to add explicit comparisons of utility estimates computed from approximate versus full logits, including correlation metrics and ablation studies on how approximation errors affect retention decisions. This will provide the necessary verification that the estimates remain reliable. revision: yes
Circularity Check
No significant circularity; method presented as independent construction
full rationale
The provided abstract and summary describe Spherical KV as a new rate-distortion approach using Angle-Domain Attention (spherical parameterization with direct logit computation) and Rate-Distortion Retention (joint keep/drop and precision selection). No equations, fitted parameters, or self-citations are shown that reduce the claimed preservation of attention quality or retention decisions to quantities defined by the method's own inputs or outputs. The derivation chain is self-contained as a proposed algorithmic construction grounded in attention geometry, with no evidence of self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Spherical KV stores keys in a spherical parameterization—a scalar radius plus compact angle codes for direction—and computes attention logits directly from these codes via an angular recurrence.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
min E[L(LLMSphKV(π))] s.t. Σ zi·cost(bi) ≤ B (rate–distortion allocation under fixed budget)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508. Ngoc Bui, Shubham Sharma, Simran Lamba, Saumitra Mishra, and Rex Ying
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2512.03324
Cache what lasts: T oken retention for memory-bounded KV cache in LLMs. arXiv preprint arXiv:2512.03324. Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Baobao Chang, Junjie Hu, and Xiao Wen
-
[3]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
PyramidKV: Dynamic KV cache compression based on pyrami- dal information funneling. arXiv preprint arXiv:2406.02069. Yihua Cheng, Yuhan Liu, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaoting Feng, Yuyang Huang, Samuel Shen, Kuntai Du, and Junchen Jiang
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Transformer-XL: Attentive language models beyond a fixed-length context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), pages 2978–2988. As- sociation for Computational Linguistics. ArXiv:1901.02860. Tri Dao
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[5]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
FlashAttention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691. Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
ArXiv:2205.14135. Alessio Devoto, Maximilian Jeblick, and Simon Jégou
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2510.00636
Expected attention: KV cache compres- sion by estimating attention from future queries distribution . arXiv preprint arXiv:2510.00636. Dayou Du, Shijie Cao, Jianyi Cheng, Ting Cao, and Mao Yang
-
[8]
arXiv preprint arXiv:2503.18773
BitDecoding: Unlocking tensor cores for long-context LLMs decoding with low-bit KV cache . arXiv preprint arXiv:2503.18773. Insu Han, Praneeth Kacham, Amin Karbasi, Vahab Mirrokni, and Amir Zandieh
-
[9]
arXiv preprint arXiv:2502.02617
PolarQuant: Quan- tizing KV caches with polar transformation . arXiv preprint arXiv:2502.02617. Introduces random preconditioning + recursive polar transformation for KV cache quantization. Yefei He, Luoming Zhang, Weijia Wu, Jing Liu, Hong Zhou, and Bohan Zhuang
-
[10]
arXiv preprint arXiv:2405.14256
ZipCache: Ac- curate and efficient KV cache quantization with salient token identification . arXiv preprint arXiv:2405.14256. Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami
-
[11]
KVQuant: T owards 10 million context length LLM inference with KV cache quantization. arXiv preprint arXiv:2401.18079. Yen-Chieh Huang, Rui Fang, Ming-Syan Chen, and Pi-Cheng Hsiu
-
[12]
arXiv preprint arXiv:2512.17452
Learning what to write: Write- gated KV for efficient long-context inference. arXiv preprint arXiv:2512.17452. Hugging Face
-
[13]
https://huggingface.co/docs/transformers/kv_cache
Cache strategies (transformers documentation): KV Cache and QuantizedCache. https://huggingface.co/docs/transformers/kv_cache. Accessed: 2026-01-29. Hao Kang, Qingru Zhang, Souvik Kundu, Geonhwa Jeong, Zaoxing Liu, Tushar Krishna, and Tuo Zhao
work page 2026
-
[14]
arXiv preprint arXiv:2403.05527
GEAR: An efficient KV cache compression recipe for near-lossless generative inference of LLMs. arXiv preprint arXiv:2403.05527. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023a.Efficient memory management for large language model serving with PagedAttention. arXiv preprint...
-
[15]
SnapKV: LLM Knows What You are Looking for Before Generation
SnapKV: LLM knows what you are looking for before gen- eration. arXiv preprint arXiv:2404.14469. Yujun Lin et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Rocketkv: Accelerating long-context llm inference via a two-stage kv cache compression framework . Minghui Liu, Aadi Palnitkar, Tahseen Rabbani, Hyunwoo Jae, Kyle Rui Sang, Dixi Yao, Shayan Shabihi, Fuheng Zhao, Tian Li, Ce Zhang, Furong Huang, and Kunpeng Zhang. 2025a. Hold onto that thought: Assessing KV cache compression on reasoning. OpenReview (ICLR ...
work page 2026
-
[17]
AgentBench: Evaluating LLMs as Agents
OpenReview Forum ID: udgrpHqw4F . Minghui Liu, Aadi Palnitkar, Tahseen Rabbani, Hyunwoo Jae, Kyle Rui Sang, Dixi Yao, Shayan Shabihi, Fuheng Zhao, Tian Li, Ce Zhang, Furong Huang, and Kunpeng Zhang. 2025b. Hold onto that thought: Assessing kv cache compression on reasoning . ArXiv preprint. Nelson F . Liu et al. 2023a. Lost in the middle: How language mod...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
KIVI: A tuning-free asymmetric 2-bit quantization for KV cache . arXiv preprint arXiv:2402.02750. Silvano Martello and Paolo T oth
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
NVIDIA. 2025a. KV Cache Reuse (tensorrt-llm documentation). https://nvidia.github.io/ TensorRT-LLM/advanced/kv-cache-reuse.html . Accessed: 2026-01-29. NVIDIA. 2025b. KVPress: LLM KV cache compression made easy . Software repository. GitHub repos- itory. Pin the exact release tag and/or commit hash used in experiments (e.g., vX.Y.Z, commit <hash>). Or Oze...
work page 2026
-
[20]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
T oolLLM: Facilitating large language models to master 16000+ real- world apis. arXiv preprint arXiv:2307.16789. Introduces the T oolBench dataset and T oolEval eval- uator within the T oolLLM framework. Ziran Qin, Yuchen Cao, Mingbao Lin, Wen Hu, Shixuan Fan, Ke Cheng, Weiyao Lin, and Jianguo Li
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Compressive Transformers for Long-Range Sequence Modelling
Compressive transformers for long-range sequence modelling . In International Conference on Learning Representations (ICLR). ArXiv:1911.05507. Claude E. Shannon
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[22]
The Bell System Technical Jour- nal, 27(3):379–423
A mathematical theory of communication. The Bell System Technical Jour- nal, 27(3):379–423. Yi Su, Yuechi Zhou, Quantong Qiu, Juntao Li, Qingrong Xia, Ping Li, Xinyu Duan, Zhefeng Wang, and Min Zhang. 2025a. Accurate KV cache quantization with outlier tokens tracing . arXiv preprint arXiv:2505.10938. Zunhai Su, Hanyu Wei, Zhe Chen, Wang Shen, Linge Li, Hu...
-
[23]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Flexicache: Leverag- ing temporal stability of attention heads for efficient kv cache management . ArXiv preprint. Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. 2024a. Quest: Query- aware sparsity for efficient long-context LLM inference. arXiv preprint arXiv:2406.10774. Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao...
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Polar- Quant: Leveraging polar transformation for efficient key cache quantization and decoding accel- eration. arXiv preprint arXiv:2502.00527. Haojun Xia, Xiaoxia Wu, Jisen Li, Robert Wu, Junxiong Wang, Jue Wang, Chenxi Li, Aman Singhal, Alay Dilipbhai Shah, Alpay Ariyak, Donglin Zhuang, Zhongzhu Zhou, Ben Athiwaratkun, Zhen Zheng, and Shuaiwen Leon Song
-
[25]
arXiv preprint arXiv:2511.18643
Kitty: Accurate and efficient 2-bit KV cache quantization with dy- namic channel-wise precision boost. arXiv preprint arXiv:2511.18643. Guangxuan Xiao, Yao Tian, Beidi Chen, Song Han, and Mike Lewis
-
[26]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Pro- cessing (EMNLP), pages 2369–2380. Association for Computational Linguistics. ArXiv:1809.09600. Zhe Ye et al
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
FlashInfer: Efficient and customizable attention engine for LLM serving . arXiv preprint arXiv:2501.01005. Zhe Zhang et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
H$_2$O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
H2O: Heavy-hitter oracle for efficient generative inference of large language models. arXiv preprint arXiv:2306.14048. Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Sglang: Efficient execution of structured language model programs. In Advances in Neural Information Processing Systems (NeurIPS). Jing Zou, Shangyu Wu, Hancong Duan, Qiao Li, and Chun Jason Xue. 2026a. Contiguouskv: Accelerating LLM prefill with granularity-aligned KV cache management . Jing Zou, Shangyu Wu, Hancong Duan, Qiao Li, and Chun Jason Xue. 202...
work page 2024
-
[30]
= 44 d44/8e = 6 Codebook footprint sanity (cache feasibility). For group size g and angular bits bθ, each group codebook stores 2bθ g fp16 scalars, i.e., 2 2bθ g bytes. For b1: per group 2 64 16 = 2048 B, across G=8 groups 16KB per (layer,head); for b2: 4KB; for b3: per group 2 8 32 = 512 B, across G=4 groups 2KB. These footprints are chosen to make (I3) ...
work page 2048
-
[31]
Model Method Q Q ↓ tok/s bKV KV# PeakKV (GB) Llama-3.1-8BDense 75.65 – 110.0 – 1863.6 – 0.060 SphKV (rep) 75.01 0.64 183.0 1.66 1256.6 32.6% 0.040 Qwen2.5-14B Dense 77.56 – 93.3 – 2191.6 – 0.070 SphKV (rep) 76.90 0.66 153.9 1.65 1413.4 35.5% 0.045 GPT-oss Dense 79.39 – 104.9 – 1927.5 – 0.062 SphKV (rep) 79.03 0.35 172.5 1.64 1329.8 31.0% 0.043 Discussion ...
work page 1927
-
[32]
Model Method Q Q ↓ tok/s bKV KV# PeakKV (GB) Llama-3.1-8BDense 76.56 – 62.9 – 2360.6 – 0.302 SphKV (rep) 75.78 0.78 108.0 1.72 1547.1 34.5% 0.198 Qwen2.5-14B Dense 78.02 – 55.7 – 2775.6 – 0.355 SphKV (rep) 77.40 0.62 94.8 1.70 1607.7 42.1% 0.206 GPT-oss Dense 80.12 – 59.9 – 2442.2 – 0.313 SphKV (rep) 79.58 0.54 102.4 1.71 1611.7 34.0% 0.206 Discussion (Ta...
work page 1927
-
[33]
retains heavy hitters plus recent tokens, motivating eviction via principled objectives. Scissorhands ( Liu et al. , 2023c) leverages persistence of importance for fixed-budget KV without fine-tuning. Prompt-time compression and query-aware sparsity (SnapKV (Li et al., 2024), Quest (Tang et al., 2024b)) reduce KV reads by selecting critical spans; SAGE-KV...
work page 2024
-
[34]
Rate–distortion allocation (bit-budgeted)
accelerates selection itself via low-bit retrieval. Rate–distortion allocation (bit-budgeted). Goal: fix what is retained (often all tokens) but choose how many bits each token/group receives. This is where Spherical KV positions itself: RDR allocates tiers (bits) under an explicit budget, rather than only choosing keep/drop under a token budget. Why it m...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.