SAGE: Shaping Anchors for Guided Exploration in RLVR of LLMs
Pith reviewed 2026-05-20 20:03 UTC · model grok-4.3
The pith
Reshaping the reverse-KL anchor with a guide function lets RLVR expand the range of reasoning modes LLMs can sample.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing a guide function q(x,y) that reshapes the reverse-KL anchor distribution, the policy can expand its empirical support in a controllable way. This avoids the instability of removing regularization and the inefficiency of forward-KL while still allowing alternative reasoning modes to emerge, resulting in consistent improvements on both single-sample and multi-sample metrics for mathematical reasoning.
What carries the argument
The guide function q(x,y) that reshapes the reverse-KL anchor distribution to enable controllable empirical support expansion.
If this is right
- The policy can sample alternative reasoning modes that were suppressed under standard reverse-KL regularization.
- Both pass@1 and pass@k improve together on mathematical reasoning benchmarks.
- Training remains stable without reward hacking or wasteful allocation to off-target regions.
- The efficiency-coverage trade-off is maintained better than with no KL term or with forward-KL.
Where Pith is reading between the lines
- Anchor reshaping may be useful in other regularized RL settings for language models where exploration of new behaviors is desired.
- Automated selection or learning of the guide function could reduce the need for manual design in future applications.
- The same idea might help balance exploration and stability in RL for tasks beyond math, such as code generation.
Load-bearing premise
A suitably chosen guide function q(x,y) can reshape the reverse-KL anchor to expand empirical support while preserving the efficiency-coverage trade-off.
What would settle it
If SAGE fails to raise pass@k on the math benchmarks or produces reward hacking and instability comparable to removing the KL term, the central claim would be falsified.
Figures





read the original abstract
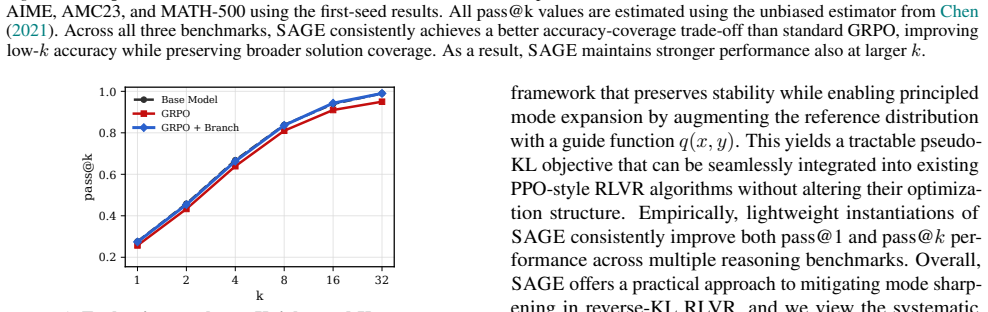
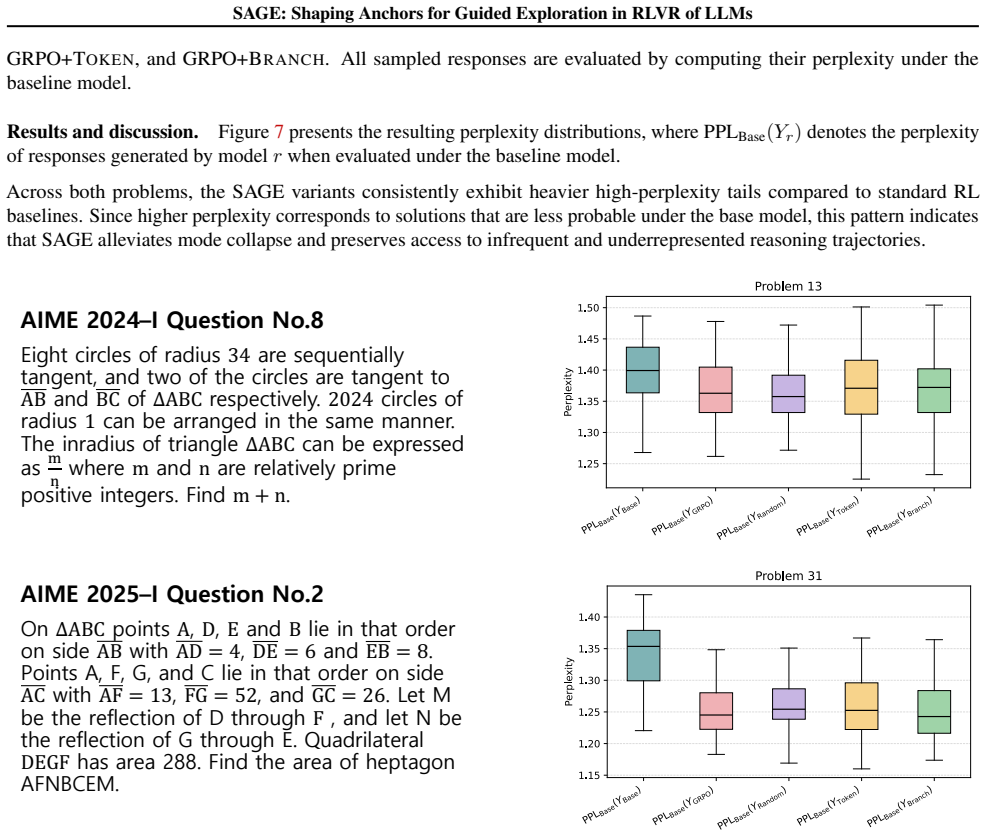
Recent studies observe that reinforcement learning with verifiable rewards (RLVR) reliably improves pass@1 on reasoning tasks, yet often fails to yield comparable gains in pass@k, raising the question of whether RLVR genuinely enables large language models to acquire novel reasoning abilities or merely enhances the efficiency of sampling reasoning modes already present in the base model. Prior analyses largely support the latter view, attributing this limitation to structural properties of standard RLVR objectives that result in insufficient exploration pressure. In this work, we argue that a central structural constraint arises from reverse-KL regularization, which stabilizes training but inherently anchors the policy to the reference distribution, thereby suppressing the emergence of alternative reasoning modes. However, we show that neither removing the KL term nor replacing it with forward-KL provides a satisfactory solution, as both disrupt the efficiency-coverage trade-off by either inducing reward hacking or allocating probability mass to off-target regions. To resolve this tension, we propose SAGE, a principled framework that enables controllable empirical support expansion by reshaping the reverse-KL anchor distribution itself through a guide function q(x,y), achieving consistent improvements in both pass@1 and pass@k across challenging mathematical reasoning benchmarks. Our code is available at https://github.com/tally0818/SAGE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript diagnoses that reverse-KL regularization in RLVR for LLMs anchors the policy to the reference distribution and thereby limits the emergence of alternative reasoning modes, resulting in gains on pass@1 but not on pass@k. It argues that neither dropping the KL term nor switching to forward-KL resolves the issue without breaking the efficiency-coverage trade-off. SAGE is proposed as a framework that reshapes the reverse-KL anchor itself via a guide function q(x,y) to achieve controllable expansion of empirical support, with reported consistent improvements on both metrics across mathematical reasoning benchmarks.
Significance. If the central mechanism holds and the guide function can be instantiated generally, the work would offer a principled route to genuine exploration in RLVR without reward hacking or off-target mass allocation. The code release is a positive factor for reproducibility and would allow the community to test whether the reshaping truly expands support beyond what is already present in the base model.
major comments (2)
- [Abstract and proposed-method section] The load-bearing claim is that a suitably chosen guide function q(x,y) reshapes the reverse-KL anchor to expand support while preserving the efficiency-coverage trade-off (Abstract and proposed-method description). The manuscript provides no explicit construction, parameterization, or selection procedure for q, leaving open the possibility that any observed gains arise from implicit task-specific knowledge rather than the reshaping mechanism itself.
- [Experimental results] The experimental section reports consistent gains in both pass@1 and pass@k, yet contains no ablations that isolate the contribution of the anchor-reshaping step from other implementation choices (e.g., reward scaling, sampling temperature, or reference-model updates). Without such controls, attribution of the improvements specifically to SAGE remains under-supported.
minor comments (2)
- [Method] Notation for the guide function q(x,y) and its integration into the RL objective should be introduced with an explicit equation early in the method section to improve readability.
- [Abstract] The abstract states that code is available but does not include a direct link or repository description; this should be added for completeness.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying the role of the guide function and committing to additional experiments to strengthen the attribution of results to the SAGE mechanism.
read point-by-point responses
-
Referee: [Abstract and proposed-method section] The load-bearing claim is that a suitably chosen guide function q(x,y) reshapes the reverse-KL anchor to expand support while preserving the efficiency-coverage trade-off (Abstract and proposed-method description). The manuscript provides no explicit construction, parameterization, or selection procedure for q, leaving open the possibility that any observed gains arise from implicit task-specific knowledge rather than the reshaping mechanism itself.
Authors: We acknowledge that the proposed-method section would benefit from greater explicitness on this point. The guide function q(x,y) is defined in the manuscript as a general reshaping operator applied to the reference distribution, specifically by reweighting the anchor logits with a controllable exploration term derived from the current policy's high-reward trajectories. The parameterization uses a single scalar mixing coefficient selected to balance support expansion against stability, with the selection procedure based on monitoring the empirical support size on a held-out validation set. This construction is intended to be task-agnostic and applicable across mathematical reasoning benchmarks. We will expand the method section in the revision to include the precise functional form, the hyperparameter selection algorithm, and pseudocode, thereby making clear that performance gains arise from the reshaping mechanism rather than implicit task knowledge. revision: yes
-
Referee: [Experimental results] The experimental section reports consistent gains in both pass@1 and pass@k, yet contains no ablations that isolate the contribution of the anchor-reshaping step from other implementation choices (e.g., reward scaling, sampling temperature, or reference-model updates). Without such controls, attribution of the improvements specifically to SAGE remains under-supported.
Authors: We agree that isolating the anchor-reshaping component is necessary for rigorous attribution. The current experimental suite compares SAGE against standard RLVR and KL-ablated variants while holding reward scaling, temperature, and reference updates fixed, but does not include a dedicated sweep that toggles only the guide function. In the revised manuscript we will add a targeted ablation table that varies the presence and strength of the guide function q(x,y) while freezing all other implementation details, together with statistical significance tests. This will directly demonstrate that the observed pass@k gains are attributable to the controllable support expansion introduced by SAGE. revision: yes
Circularity Check
No circularity: SAGE proposal is a self-contained new framework
full rationale
The paper first identifies limitations in existing RLVR objectives (reverse-KL anchoring suppressing alternative modes, with removal or forward-KL disrupting efficiency-coverage trade-offs) via prior analyses, then introduces SAGE as an independent proposal that reshapes the anchor via a new guide function q(x,y). No equations reduce a claimed prediction to a fitted input by construction, no load-bearing uniqueness theorems or ansatzes are imported via self-citation, and the central improvement claim rests on the novel reshaping mechanism rather than re-labeling or self-referential definitions. The derivation chain is therefore self-contained against external benchmarks and does not collapse to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reverse-KL regularization inherently anchors the policy to the reference distribution, thereby suppressing the emergence of alternative reasoning modes.
invented entities (1)
-
guide function q(x,y)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reshaping the reverse-KL anchor distribution itself through a guide function q(x,y)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yang Yue and Zhiqi Chen and Rui Lu and Andrew Zhao and Zhaokai Wang and Yang Yue and Shiji Song and Gao Huang , title =. arXiv , volume =. 2025 , url =
work page 2025
-
[2]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , title =. arXiv , volume =. 2024 , url =
work page 2024
-
[3]
Qiying Yu and Zheng Zhang and Ruofei Zhu and Yufeng Yuan and Xiaochen Zuo and Yu Yue and Tiantian Fan and Gaohong Liu and Lingjun Liu and Xin Liu and Haibin Lin and Zhiqi Lin and Bole Ma and Guangming Sheng and Yuxuan Tong and Chi Zhang and Mofan Zhang and Wang Zhang and Hang Zhu and Jinhua Zhu and Jiaze Chen and Jiangjie Chen and Chengyi Wang and Hongli ...
work page 2025
-
[4]
Fang Wu and Weihao Xuan and Ximing Lu and Za. The Invisible Leash: Why. arXiv , volume =. 2025 , url =
work page 2025
-
[5]
Changyi Xiao and Mengdi Zhang and Yixin Cao , title =. arXiv , volume =. 2025 , url =
work page 2025
-
[6]
Wenhao Deng and Long Wei and Chenglei Yu and Tailin Wu , title =. arXiv , volume =. 2025 , url =
work page 2025
-
[7]
Zichen Liu and Changyu Chen and Wenjun Li and Penghui Qi and Tianyu Pang and Chao Du and Wee Sun Lee and Min Lin , title =. arXiv , volume =. 2025 , url =
work page 2025
-
[8]
Zhicheng Yang and Zhijiang Guo and Yinya Huang and Yongxin Wang and Dongchun Xie and Yiwei Wang and Xiaodan Liang and Jing Tang , title =. arXiv , volume =. 2025 , url =
work page 2025
-
[9]
Zihan Liu and Zhuolin Yang and Yang Chen and Chankyu Lee and Mohammad Shoeybi and Bryan Catanzaro and Wei Ping , title =. arXiv , volume =. 2025 , url =
work page 2025
-
[10]
Minghan Chen and Guikun Chen and Wenguan Wang and Yi Yang , title =. arXiv , volume =. 2025 , url =
work page 2025
-
[11]
Can Xie and Ruotong Pan and Xiangyu Wu and Yunfei Zhang and Jiayi Fu and Tingting Gao and Guorui Zhou , title =. arXiv , volume =. 2025 , url =
work page 2025
-
[12]
Reasoning with Exploration: An Entropy Perspective
Reasoning with exploration: An entropy perspective , author=. arXiv preprint arXiv:2506.14758 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Advancing language model reasoning through reinforcement learning and inference scaling , author=. arXiv preprint arXiv:2501.11651 , year=
-
[14]
Decomposing the entropy-performance exchange: The missing keys to unlocking effective reinforcement learning , author=. arXiv preprint arXiv:2508.02260 , year=
-
[15]
arXiv preprint arXiv:2509.25133 , year=
Rethinking entropy regularization in large reasoning models , author=. arXiv preprint arXiv:2509.25133 , year=
-
[16]
Rediscovering Entropy Regularization: Adaptive Coefficient Unlocks Its Potential for LLM Reinforcement Learning , author=. arXiv preprint arXiv:2510.10959 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Tulu 3: Pushing frontiers in open language model post-training , author=. arXiv preprint arXiv:2411.15124 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Pass@ k training for adaptively balancing exploration and exploitation of large reasoning models , author=. arXiv preprint arXiv:2508.10751 , year=
- [19]
-
[20]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement , author=. arXiv preprint arXiv:2409.12122 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
American Mathematics Competitions , author =
-
[23]
AIME: American Invitational Mathematics Examination , author=
-
[24]
Measuring Mathematical Problem Solving With the MATH Dataset , author=. NeurIPS , year=
-
[25]
Daniel Han, Michael Han and Unsloth team , title =
-
[26]
GitHub repository , howpublished =
Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec , title =. GitHub repository , howpublished =. 2020 , publisher =
work page 2020
-
[27]
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
work page 2024
- [28]
- [29]
-
[30]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[31]
Christian Walder and Deep Karkhanis , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.15201 , eprinttype =. 2505.15201 , timestamp =
-
[32]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2501.12948 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
arXiv preprint arXiv:2503.04548 , year=
An empirical study on eliciting and improving r1-like reasoning models , author=. arXiv preprint arXiv:2503.04548 , year=
-
[34]
The choice of divergence: A neglected key to mitigating diversity collapse in reinforcement learning with verifiable reward , author=. arXiv preprint arXiv:2509.07430 , year=
- [35]
- [36]
-
[37]
arXiv preprint arXiv:2510.20817 , year=
KL-Regularized Reinforcement Learning is Designed to Mode Collapse , author=. arXiv preprint arXiv:2510.20817 , year=
-
[38]
Treerl: Llm reinforcement learning with on-policy tree search , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[39]
Advances in Neural Information Processing Systems , volume=
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
On Memorization of Large Language Models in Logical Reasoning , author=. 2024 , eprint=
work page 2024
-
[41]
George E Uhlenbeck and Leonard S Ornstein
On the design of kl-regularized policy gradient algorithms for llm reasoning , author=. arXiv preprint arXiv:2505.17508 , year=
-
[42]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[43]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[44]
M. J. Kearns , title =
-
[45]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[46]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[47]
Suppressed for Anonymity , author=
-
[48]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[49]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[50]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue and Zhiqi Chen and Rui Lu and Andrew Zhao and Zhaokai Wang and Yang Yue and Shiji Song and Gao Huang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.13837 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.13837 2025
-
[51]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2402.03300 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.