Unleashing the Power of Tree-of-Thoughts for Edge-Enabled AIGC Service Provisioning
Pith reviewed 2026-05-20 07:03 UTC · model grok-4.3
The pith
Diffusion-based actor-critic assigns ToT thoughts to edge servers to minimize generation delay under quality constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Modeling Tree-of-Thoughts as a directed acyclic graph of thoughts and using a diffusion-based soft actor-critic algorithm to optimize their assignment to edge servers yields up to 8.32 percent less total generation delay than PPO, 11.57 percent less than SAC, and 36.09 percent less than DDQN, plus over 80 percent latency reduction versus fully local execution even with high quality demands.
What carries the argument
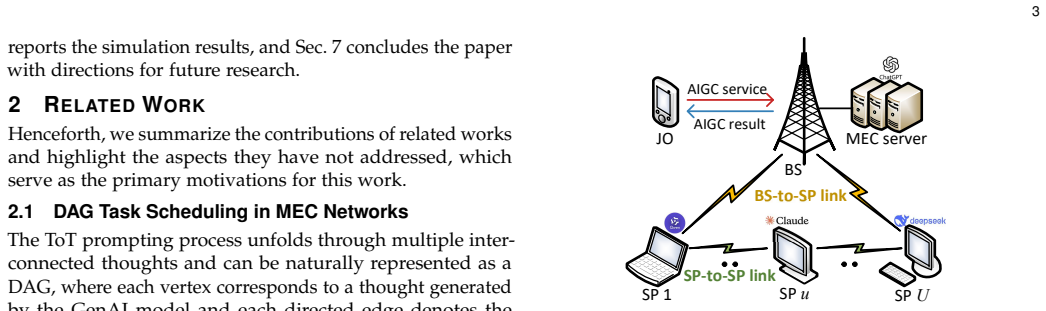
Directed acyclic graph model of ToT prompting process where vertices are thoughts and edges are transitions, solved via diffusion-based soft actor-critic algorithm for optimal assignment decisions.
If this is right
- Total generation delay can be reduced by offloading parts of the reasoning tree to edge servers.
- User-adjustable quality constraints allow balancing speed and output quality in AIGC tasks.
- The proposed method outperforms standard reinforcement learning baselines like PPO, SAC, and DDQN in simulated settings.
- Latency drops dramatically compared to performing all generation locally on the user device.
Where Pith is reading between the lines
- The approach could extend to other complex prompting methods that involve multiple reasoning branches.
- Validating the token count relationships with additional models would strengthen the generalization of results.
- Real deployments might need to account for variable network conditions between user and edge servers.
Load-bearing premise
The directed acyclic graph accurately represents the reasoning process of ToT prompting and the token-delay-quality relationships found with Qwen 2.5-7B-Instruct hold for other generative models and tasks.
What would settle it
Conducting similar experiments using a different large language model and checking whether the observed percentage improvements in delay and the 80 percent latency reduction still occur.
Figures










read the original abstract
Delivering AI-generated content (AIGC) services fundamentally relies on the reasoning capabilities of generative AI (GenAI) models. Chain-of-Thought (CoT) enhances such reasoning by guiding models through intermediate steps, while Tree-of-Thoughts (ToT) further extends CoT by exploring multiple candidate reasoning paths simultaneously, thereby greatly improving AIGC service quality. However, generating diverse reasoning paths requires separate calls to computationally intensive GenAI models, posing significant challenges for resource constrained user devices. In this paper, we investigate mobile edge computing-enabled AIGC service provisioning with ToT prompting. Specifically, using creative writing AIGC tasks as a case study, we first characterize the number of output tokens as a measure of computational resources in GenAI models and establish its relationship with generation delay and quality through experiments with Qwen 2.5-7B-Instruct. Afterward, we introduce a directed acyclic graph (DAG) model to accurately characterize the reasoning process of ToT prompting, where each vertex represents a thought and each directed edge denotes a transition between consecutive thoughts. We then formulate a DAG-based thought assignment problem aimed at minimizing generation delay subject to a user-adjustable quality constraint. To address this problem, we propose a diffusion-based soft actor-critic (DSAC) algorithm that innovatively integrates diffusion models to determine optimal thought assignment decisions. Through extensive simulations, we demonstrate that the proposed DSAC achieves total generation delay reductions of up to 8.32% over PPO, 11.57% over SAC, and 36.09% over DDQN across various simulation settings, while reducing latency by over 80% compared to the fully local generation baseline even under stringent quality requirements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates mobile edge computing for AIGC services using Tree-of-Thoughts (ToT) prompting. It characterizes output token counts from Qwen 2.5-7B-Instruct experiments on creative writing to relate generation delay and quality, models the ToT reasoning process as a directed acyclic graph (DAG), formulates a DAG-based thought assignment optimization to minimize total generation delay subject to a quality constraint, and proposes a diffusion-based soft actor-critic (DSAC) algorithm to solve it. Simulations report that DSAC yields total generation delay reductions of up to 8.32% over PPO, 11.57% over SAC, and 36.09% over DDQN, plus over 80% latency reduction versus fully local generation even under stringent quality requirements.
Significance. If the fitted token-delay-quality relationships and DAG model prove robust, the work could meaningfully advance practical deployment of multi-path reasoning techniques like ToT in resource-limited edge settings for AIGC. The integration of diffusion models into the actor-critic framework for combinatorial assignment decisions is a technical contribution worth noting. The simulation-based gains over standard RL baselines (PPO, SAC, DDQN) and the local baseline provide concrete evidence of potential system-level benefits, though broader validation would strengthen the case for impact in distributed computing and edge AI.
major comments (2)
- [Abstract] Abstract: The reported performance gains (8.32% over PPO, 11.57% over SAC, 36.09% over DDQN, >80% vs. local) rest on a token-to-delay and token-to-quality mapping fitted exclusively from experiments with Qwen 2.5-7B-Instruct on creative writing tasks. This mapping directly populates the DAG parameters and the simulation environment used to evaluate DSAC; without sensitivity analysis across models, tasks, or prompt styles, the optimality of the learned policy and the magnitude of the claimed reductions are not shown to be general.
- [Abstract] Abstract and simulation results: No error bars, confidence intervals, statistical significance tests, or details of the full experimental protocol (number of runs, random seeds, variance across simulation settings) are provided for the comparative delay reductions. This leaves the central empirical claim—that DSAC outperforms the baselines—without quantified uncertainty, making it difficult to assess whether the observed improvements are reliable or could be artifacts of particular random seeds or settings.
minor comments (1)
- [Abstract] The abstract refers to 'various simulation settings' and 'stringent quality requirements' without enumerating the ranges or specific values used for parameters such as the quality constraint threshold or the number of thoughts in the DAG.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, indicating revisions where we agree changes are warranted.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported performance gains (8.32% over PPO, 11.57% over SAC, 36.09% over DDQN, >80% vs. local) rest on a token-to-delay and token-to-quality mapping fitted exclusively from experiments with Qwen 2.5-7B-Instruct on creative writing tasks. This mapping directly populates the DAG parameters and the simulation environment used to evaluate DSAC; without sensitivity analysis across models, tasks, or prompt styles, the optimality of the learned policy and the magnitude of the claimed reductions are not shown to be general.
Authors: We agree that the mappings are derived from a specific case study using Qwen 2.5-7B-Instruct on creative writing tasks, as stated in the manuscript. The DAG model and DSAC algorithm are intentionally general and can incorporate mappings from other models or tasks. In the revision we add a sensitivity analysis subsection that perturbs the fitted parameters within the empirical variance observed in our experiments and confirms that DSAC retains its relative gains. We also expand the discussion to note that practitioners can refit the token relationships for new models while reusing the same optimization framework. revision: partial
-
Referee: [Abstract] Abstract and simulation results: No error bars, confidence intervals, statistical significance tests, or details of the full experimental protocol (number of runs, random seeds, variance across simulation settings) are provided for the comparative delay reductions. This leaves the central empirical claim—that DSAC outperforms the baselines—without quantified uncertainty, making it difficult to assess whether the observed improvements are reliable or could be artifacts of particular random seeds or settings.
Authors: We acknowledge the omission of statistical details in the original submission. The reported averages were computed over multiple runs, but error bars, seed information, and protocol specifics were not included. The revised manuscript now specifies that all results are averaged over 20 independent runs using distinct random seeds (listed in the text), adds error bars (standard deviation) to the relevant figures, reports t-test p-values confirming statistical significance of the gains, and provides a complete experimental protocol subsection in Section 5. revision: yes
Circularity Check
No load-bearing circularity; simulation results compare DSAC to external RL baselines in a fitted but non-self-referential environment.
full rationale
The paper first runs experiments on Qwen 2.5-7B-Instruct to fit token-count vs. delay/quality curves, builds a DAG model of ToT reasoning from those curves, formulates a delay-minimization problem, and then runs DSAC (plus PPO/SAC/DDQN) inside the resulting simulator. The reported percentage reductions (8.32 % over PPO, etc.) are differences between independently trained policies evaluated in the same simulator; they do not reduce by construction to the fitted parameters themselves. No self-citation chain or uniqueness theorem is invoked to justify the central claims. This is the normal case of a simulation study whose validity hinges on generalization of the fitted curves rather than on definitional circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- quality constraint threshold
axioms (1)
- domain assumption The directed acyclic graph model accurately characterizes the reasoning process of ToT prompting.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce a directed acyclic graph (DAG) model to accurately characterize the reasoning process of ToT prompting... formulate a DAG-based thought assignment problem
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Score i,m = Score max − σ m e^{-ρ m C m} ... T gen i,m = η m C m + ψ m
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
H. Du, R. Zhang, D. Niyato, J. Kang, Z. Xiong, D. I. Kim, X. Shen, and H. V . Poor, “Exploring collaborative distributed diffusion-based AI-generated content (AIGC) in wireless networks,”IEEE Network, vol. 38, no. 3, pp. 178–186, 2023
work page 2023
-
[2]
ChatGPT: five priorities for research,
E. A. Van Dis, J. Bollen, W. Zuidema, R. Van Rooij, and C. L. Bockting, “ChatGPT: five priorities for research,”Nature, vol. 614, no. 7947, pp. 224–226, 2023
work page 2023
-
[3]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,” inProc. Advances Neural Inf. Process. Syst., vol. 35, 2022, pp. 24 824–24 837
work page 2022
-
[4]
Tree of thoughts: Deliberate problem solving with large language models,
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y. Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,” inProc. Advances Neural Inf. Process. Syst., vol. 36, 2023, pp. 11 809–11 822
work page 2023
-
[5]
Two-timescale model caching and resource allocation for edge-enabled AI-generated content services,
Z. Liu, H. Du, X. Hou, L. Huang, S. Hosseinalipour, D. Niyato, and K. B. Letaief, “Two-timescale model caching and resource allocation for edge-enabled AI-generated content services,”IEEE Trans. Mobile Comput., 2025
work page 2025
-
[6]
A survey of mobile cloud computing: architecture, applications, and approaches,
H. T. Dinh, C. Lee, D. Niyato, and P . Wang, “A survey of mobile cloud computing: architecture, applications, and approaches,” Wireless Commun. Mobile Comput., vol. 13, no. 18, pp. 1587–1611, 2013
work page 2013
-
[7]
A survey on mobile edge computing: The communication perspective,
Y. Mao, C. You, J. Zhang, K. Huang, and K. B. Letaief, “A survey on mobile edge computing: The communication perspective,”IEEE Commun. surveys & Tut., vol. 19, no. 4, pp. 2322–2358, 2017
work page 2017
-
[8]
Dependent task offloading for edge computing based on deep reinforcement learning,
J. Wang, J. Hu, G. Min, W. Zhan, A. Y. Zomaya, and N. Georgalas, “Dependent task offloading for edge computing based on deep reinforcement learning,”IEEE Trans. Computers, vol. 71, no. 10, pp. 2449–2461, 2021
work page 2021
-
[9]
J. Yan, S. Bi, and Y. J. A. Zhang, “Offloading and resource allocation with general task graph in mobile edge computing: A deep reinforcement learning approach,”IEEE Trans. Wireless Commun., vol. 19, no. 8, pp. 5404–5419, 2020
work page 2020
-
[10]
L. X. Nguyen, Y. K. Tun, T. N. Dang, Y. M. Park, Z. Han, and C. S. Hong, “Dependency tasks offloading and communication resource allocation in collaborative UAV networks: A metaheuristic approach,”IEEE Internet Things J., vol. 10, no. 10, pp. 9062–9076, 2023
work page 2023
-
[11]
DAG-based dependent tasks offloading in MEC-enabled IoT with soft cooperation,
X. Zhou, S. Ge, P . Liu, and T. Qiu, “DAG-based dependent tasks offloading in MEC-enabled IoT with soft cooperation,”IEEE Trans. Mobile Comput., vol. 23, no. 6, pp. 6908–6920, 2023
work page 2023
-
[12]
Qwen2.5: A party of foundation models,
Q. Team, “Qwen2.5: A party of foundation models,” September
-
[13]
Available: https://qwenlm.github.io/blog/qwen2
[Online]. Available: https://qwenlm.github.io/blog/qwen2. 5/
-
[14]
Performance-effective and low-complexity task scheduling for heterogeneous computing,
H. Topcuoglu, S. Hariri, and M.-Y. Wu, “Performance-effective and low-complexity task scheduling for heterogeneous computing,” IEEE Trans. Parallel Distrib. Syst., vol. 13, no. 3, pp. 260–274, 2002
work page 2002
-
[15]
Energy-efficient task execution for applica- tion as a general topology in mobile cloud computing,
W. Zhang and Y. Wen, “Energy-efficient task execution for applica- tion as a general topology in mobile cloud computing,”IEEE Trans. Cloud Comput., vol. 6, no. 3, pp. 708–719, 2015
work page 2015
-
[16]
Optimal joint scheduling and cloud offloading for mobile applications,
S. E. Mahmoodi, R. Uma, and K. Subbalakshmi, “Optimal joint scheduling and cloud offloading for mobile applications,”IEEE Trans. Cloud Comput., vol. 7, no. 2, pp. 301–313, 2016
work page 2016
-
[17]
Energy-efficient dynamic offloading and resource scheduling in mobile cloud computing,
S. Guo, B. Xiao, Y. Yang, and Y. Yang, “Energy-efficient dynamic offloading and resource scheduling in mobile cloud computing,” inProc. IEEE INFOCOM, 2016, pp. 1–9
work page 2016
-
[18]
Asynchronous methods for deep reinforcement learning,
V . Mnih, A. P . Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep reinforcement learning,” inProc. Int. Conf. Mach. Learn., 2016, pp. 1928–1937
work page 2016
-
[19]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P . Abbeel, “Denoising diffusion probabilistic models,” inProc. Int. Conf. Neural Inf. Process. Syst., vol. 33, 2020, pp. 6840–6851
work page 2020
-
[20]
RFID: Towards low latency and reliable DAG task scheduling over dynamic vehicular clouds,
Z. Liu, M. Liwang, S. Hosseinalipour, H. Dai, Z. Gao, and L. Huang, “RFID: Towards low latency and reliable DAG task scheduling over dynamic vehicular clouds,”IEEE Trans. Veh. Technol., vol. 72, no. 9, pp. 12 139–12 153, 2023
work page 2023
-
[21]
X. Huang, C. Peng, Y. Wu, J. Kang, W. Zhong, D. I. Kim, and L. Qi, “Joint interdependent task scheduling and energy balancing for multi-UAV-enabled aerial edge computing: A multiobjective optimization approach,”IEEE Internet Things J., vol. 10, no. 23, pp. 20 368–20 382, 2023
work page 2023
-
[22]
Multiobjective oriented task scheduling in heterogeneous mobile edge computing networks,
J. Li, Y. Shang, M. Qin, Q. Yang, N. Cheng, W. Gao, and K. S. Kwak, “Multiobjective oriented task scheduling in heterogeneous mobile edge computing networks,”IEEE Trans. Veh. Technol., vol. 71, no. 8, pp. 8955–8966, 2022
work page 2022
-
[23]
H. Liu, G. Zheng, Z. Liu, S. Tian, and Y. Li, “Dependency-aware dynamic priority scheduling for online multi-DAG task offloading in mobile edge computing,”IEEE Internet Things J., vol. 13, no. 3, pp. 5053–5068, 2026
work page 2026
-
[24]
M. Guo, X. Hu, Y. Chen, Y. Yang, L. Zhang, and L. Chen, “Joint scheduling and offloading schemes for multiple interdependent computation tasks in mobile edge computing,”IEEE Internet Things J., vol. 11, no. 4, pp. 5718–5730, 2024
work page 2024
-
[25]
Z. Liu, L. Huang, Z. Gao, M. Luo, S. Hosseinalipour, and H. Dai, “GA-DRL: Graph neural network-augmented deep reinforcement learning for DAG task scheduling over dynamic vehicular clouds,” IEEE Trans. Netw. Service Manage., vol. 21, no. 4, pp. 4226–4242, 2024
work page 2024
-
[26]
Deep reinforcement learning for task offloading in mobile edge computing systems,
M. Tang and V . W. Wong, “Deep reinforcement learning for task offloading in mobile edge computing systems,”IEEE Trans. Mobile Comput., vol. 21, no. 6, pp. 1985–1997, 2020
work page 1985
-
[27]
Joint task offloading and migration optimization in UAV- enabled dynamic MEC networks,
L. Wang, B. Shen, L. Ma, Y. Zhang, Y. Zhao, H. Guo, Z. Yu, and B. Guo, “Joint task offloading and migration optimization in UAV- enabled dynamic MEC networks,”IEEE Trans. Services Comput., 2025
work page 2025
-
[28]
Two time- scale DRL for service caching and task offloading in cross-domain marine networks,
Z. Huang, Z. Yu, L. Wang, Y. Zhao, H. Zhou, and B. Guo, “Two time- scale DRL for service caching and task offloading in cross-domain marine networks,”IEEE Trans. Mobile Comput., 2025
work page 2025
-
[29]
Trajectory-based off-policy deep reinforcement learning,
A. Doerr, M. Volpp, M. Toussaint, T. Sebastian, and C. Daniel, “Trajectory-based off-policy deep reinforcement learning,” inProc. Int. Conf. Mach. Learn., 2019, pp. 1636–1645
work page 2019
-
[30]
Task offloading for mobile edge computing in software defined ultra-dense network,
M. Chen and Y. Hao, “Task offloading for mobile edge computing in software defined ultra-dense network,”IEEE J. Sel. Areas Commun., vol. 36, no. 3, pp. 587–597, 2018
work page 2018
-
[31]
Z. Liu, H. Du, J. Lin, Z. Gao, L. Huang, S. Hosseinalipour, and D. Niyato, “DNN partitioning, task offloading, and resource allocation in dynamic vehicular networks: A Lyapunov-guided diffusion-based reinforcement learning approach,”IEEE Trans. Mobile Comput., 2024
work page 2024
-
[32]
Z. Liu, L. Huang, Z. Gao, X. Wang, D. Niyato, and X. Shen, “A Lyapunov-guided diffusion-based reinforcement learning approach for UAV-assisted vehicular networks with delayed CSI feedback,” IEEE Trans. Wireless Commun., vol. 25, pp. 14 797–14 812, 2026. 15
work page 2026
-
[33]
Soft Actor-Critic Algorithms and Applications
T. Haarnoja, A. Zhou, K. Hartikainen, G. Tucker, S. Ha, J. Tan, V . Kumar, H. Zhu, A. Gupta, P . Abbeelet al., “Soft actor-critic algorithms and applications,”arXiv preprint arXiv:1812.05905, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
Multi- hop task offloading and relay selection for iot devices in mobile edge computing,
T. Li, Y. Liu, T. Ouyang, H. Zhang, K. Yang, and X. Zhang, “Multi- hop task offloading and relay selection for iot devices in mobile edge computing,”IEEE Trans. Mobile Comput., 2024
work page 2024
-
[35]
Diffusion-based reinforcement learning for edge-enabled AI-generated content services,
H. Du, Z. Li, D. Niyato, J. Kang, Z. Xiong, H. Huang, and S. Mao, “Diffusion-based reinforcement learning for edge-enabled AI-generated content services,”IEEE Trans. Mobile Comput., vol. 23, no. 9, pp. 8902–8918, 2024
work page 2024
-
[36]
Z. Liu, X. Wang, S. Lian, L. Huang, L. Fu, and Y.-J. A. Zhang, “Cross- layer traffic allocation and contention window optimization for Wi- Fi 7 MLO: When DRL meets LSTM,”arXiv preprint arXiv:2603.18602, 2026
-
[37]
DAG-based dependent tasks offloading in MEC-enabled IoT with soft cooperation,
X. Zhou, S. Ge, P . Liu, and T. Qiu, “DAG-based dependent tasks offloading in MEC-enabled IoT with soft cooperation,”IEEE Trans. Mobile Comput., vol. 23, no. 6, pp. 6908–6920, 2024
work page 2024
-
[38]
F. Chai, Q. Zhang, H. Yao, X. Xin, R. Gao, and M. Guizani, “Joint multi-task offloading and resource allocation for mobile edge computing systems in satellite iot,”IEEE Trans. Veh. Technol., vol. 72, no. 6, pp. 7783–7795, 2023
work page 2023
-
[39]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P . Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Deep reinforcement learning with double q-learning,
H. Van Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double q-learning,” inProc. AAAI Conf. Artif. Intell., vol. 30, no. 1, 2016
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.