Not all uncertainty is alike: volatility, stochasticity, and exploration
Pith reviewed 2026-05-20 06:38 UTC · model grok-4.3
The pith
Volatility boosts optimal exploration while stochasticity suppresses it despite both increasing uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Volatility enhances optimal exploration while stochasticity suppresses it in latent reward environments. This asymmetry is established by extending the Gittins index to Gaussian state-space bandits with dynamics. The authors derive CAUSE, a closed-form exploration bonus from control-as-inference that follows the same pattern. CAUSE beats standard strategies in mixed-noise settings and improves on Gittins policies for restless bandits. Faulty noise inference can reverse exploration patterns.
What carries the argument
The extension of the Gittins index framework to Gaussian state-space bandits with latent dynamics that distinguishes volatility from stochasticity in computing exploration value.
Load-bearing premise
The environment is accurately described by a Gaussian state-space model with known latent dynamics allowing exact index derivations.
What would settle it
Running an optimal policy on a Gaussian bandit where volatility is increased while holding stochasticity fixed and verifying that exploration rate rises, or the reverse for stochasticity.
Figures


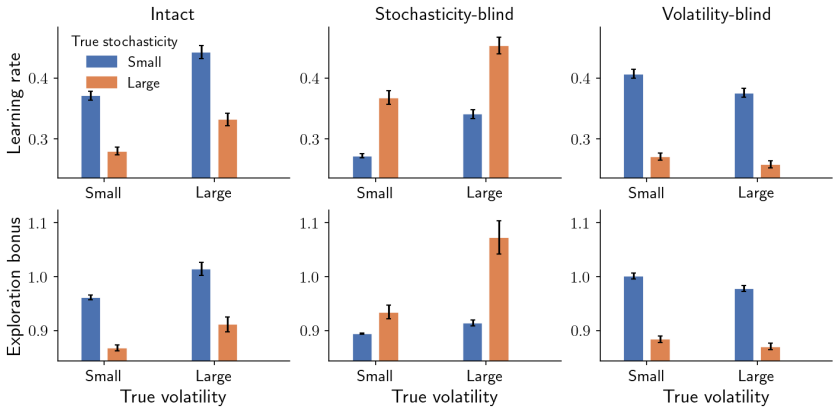


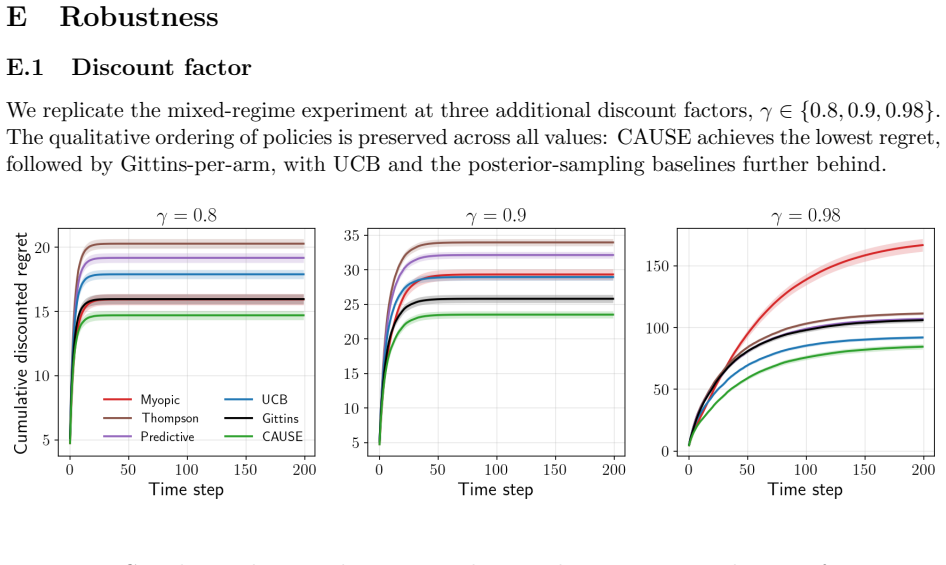

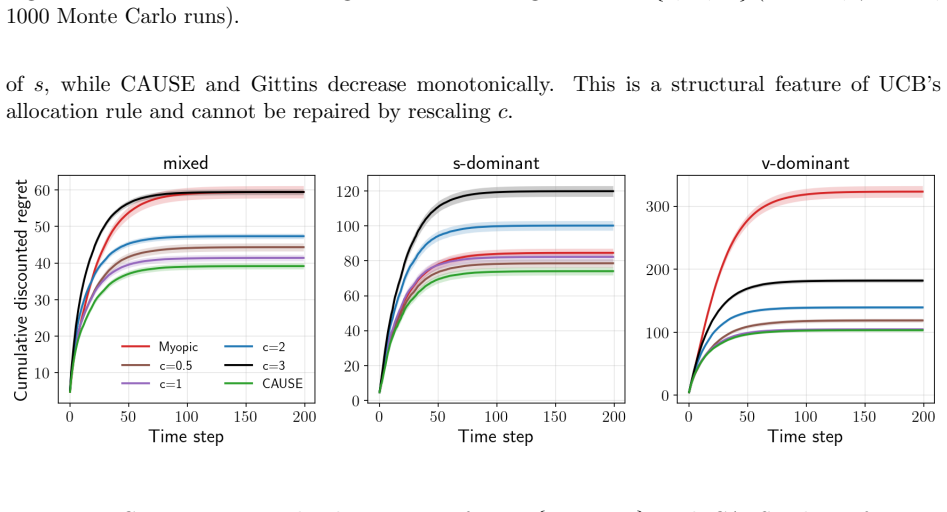
read the original abstract
Adaptive decision-making in biological and artificial intelligence requires balancing the exploitation of known outcomes with the exploration of uncertain alternatives. Although prior work suggests that uncertainty generally promotes exploration, it has typically treated distinct sources of environmental uncertainty as equivalent. We consider environments with latent reward states that drift over time (volatility) and are observed through noisy outcomes (stochasticity). Both increase posterior uncertainty, yet we show they drive optimal exploration in opposite directions: volatility enhances it, stochasticity suppresses it. We establish this asymmetry formally by extending the Gittins index framework to Gaussian state-space bandits with latent dynamics. We further derive Cause-Aware Uncertainty-Sensitive Exploration (CAUSE), a closed-form exploration bonus obtained via control-as-inference that inherits the same monotonicities. CAUSE outperforms standard exploration strategies in environments with heterogeneous noise structure, and also improves on a Gittins-per-arm policy whose rested-bandit optimality does not transfer to restless settings. Learning and exploration are governed by the same noise-inference asymmetry, and the framework predicts that pathological noise inference produces \emph{reversed} rather than merely impaired exploration, with implications for computational accounts of psychiatric conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that volatility (drifting latent reward states over time) and stochasticity (noisy observations) are distinct sources of uncertainty that drive optimal exploration in opposite directions: volatility enhances exploration while stochasticity suppresses it. This asymmetry is established formally by extending the Gittins index to Gaussian state-space bandits with latent dynamics and deriving a closed-form Cause-Aware Uncertainty-Sensitive Exploration (CAUSE) bonus via control-as-inference. CAUSE is shown to outperform standard exploration strategies and a Gittins-per-arm policy in restless settings with heterogeneous noise, with implications for learning under noise inference and computational psychiatry.
Significance. If the central claims hold, the work provides a significant formal distinction between types of uncertainty in adaptive decision-making, extending classical bandit theory to restless environments. The closed-form derivation, monotonicity results, and prediction of reversed exploration under pathological noise inference are notable strengths that could inform both algorithmic design in AI and models of exploration deficits in psychiatric conditions.
major comments (2)
- [Formal extension of Gittins index and CAUSE derivation] The extension of the Gittins index and the closed-form derivation of the CAUSE bonus both presuppose known Gaussian latent transition and emission dynamics so that the value function remains quadratic. This modeling choice is load-bearing for the directional claims on volatility versus stochasticity; the manuscript should explicitly test or discuss whether the asymmetry survives under unknown or non-Gaussian dynamics (as noted in the abstract's formal extension).
- [Comparison to Gittins-per-arm policy] The claim that a Gittins-per-arm policy's rested-bandit optimality does not transfer to restless settings is central to positioning CAUSE, yet the manuscript provides no explicit counter-example or derivation showing where the transfer fails when arms are coupled through shared latent dynamics.
minor comments (2)
- [Abstract] The abstract introduces the acronym CAUSE without a brief parenthetical expansion on first use; adding this would improve readability for a broad audience.
- Notation for the state-space model (latent states, volatility parameter, stochasticity variance) could be accompanied by a simple diagram or table summarizing the roles of each noise source.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and positioning of our results. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Formal extension of Gittins index and CAUSE derivation] The extension of the Gittins index and the closed-form derivation of the CAUSE bonus both presuppose known Gaussian latent transition and emission dynamics so that the value function remains quadratic. This modeling choice is load-bearing for the directional claims on volatility versus stochasticity; the manuscript should explicitly test or discuss whether the asymmetry survives under unknown or non-Gaussian dynamics (as noted in the abstract's formal extension).
Authors: We agree that the Gaussian assumption with known dynamics is essential for preserving the quadratic value function and deriving the exact monotonicities and closed-form CAUSE bonus. This choice enables the precise separation of volatility and stochasticity effects that is the paper's core contribution. While the control-as-inference perspective underlying CAUSE suggests the directional asymmetry may generalize, we do not claim it holds universally. In the revised manuscript we will add an explicit limitations paragraph in the discussion that (i) states the Gaussian known-dynamics assumption, (ii) notes that non-Gaussian or unknown-dynamics cases would require approximate methods such as particle filters or variational inference, and (iii) cites related work on restless bandits under more general dynamics. We will also revise the abstract to make clear that the formal extension applies to the Gaussian state-space setting. revision: partial
-
Referee: [Comparison to Gittins-per-arm policy] The claim that a Gittins-per-arm policy's rested-bandit optimality does not transfer to restless settings is central to positioning CAUSE, yet the manuscript provides no explicit counter-example or derivation showing where the transfer fails when arms are coupled through shared latent dynamics.
Authors: The classical Gittins index is optimal only when each arm's latent state evolves independently of the others when not played. In our restless Gaussian state-space model the latent dynamics are shared (common volatility process), so that selecting one arm updates the joint posterior over all arms. This coupling means the per-arm Gittins indices, computed in isolation, ignore the cross-arm information gain and the resulting change in opportunity cost. We will insert a short subsection containing (a) a two-arm analytic counter-example in which the shared latent state causes the per-arm policy to select the wrong arm, and (b) a brief derivation showing that the index decomposition fails once the value function depends on the joint posterior rather than on independent marginals. revision: yes
Circularity Check
No circularity: formal extension of Gittins index and CAUSE derivation are model-based and independent of the target result.
full rationale
The paper derives the volatility-stochasticity asymmetry by extending the Gittins index to Gaussian state-space bandits with latent dynamics and obtaining CAUSE as a closed-form bonus via control-as-inference. These steps presuppose the linear-Gaussian model class but do not define the monotonicities in terms of themselves or reduce a prediction to a fitted input by construction. No self-citation chain, ansatz smuggling, or renaming of known results is required for the central claim. The derivation remains self-contained against the stated model assumptions and external Gittins framework.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gaussian state-space model for latent reward dynamics
invented entities (1)
-
CAUSE exploration bonus
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (Jcost uniqueness, washburn_uniqueness_aczel)reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We establish this asymmetry formally by extending the Gittins index framework to Gaussian state-space bandits with latent dynamics... derive Cause-Aware Uncertainty-Sensitive Exploration (CAUSE), a closed-form exploration bonus obtained via control-as-inference
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.lean (higher-derivative calibration of CostAlphaLog)J_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The exploration bonus B(P, s, v, γ) is nonincreasing in the observation noise s... nondecreasing in the innovation variance v
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Finite-time analysis of the multiarmed bandit problem.Machine learning, 47(2):235–256, 2002
Peter Auer, Nicolo Cesa-Bianchi, and Paul Fischer. Finite-time analysis of the multiarmed bandit problem.Machine learning, 47(2):235–256, 2002
work page 2002
-
[2]
Asymptotically efficient adaptive allocation rules.Advances in applied mathematics, 6(1):4–22, 1985
Tze Leung Lai and Herbert Robbins. Asymptotically efficient adaptive allocation rules.Advances in applied mathematics, 6(1):4–22, 1985
work page 1985
-
[3]
William R Thompson. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples.Biometrika, 25(3/4):285–294, 1933
work page 1933
-
[4]
Daniel Russo and Benjamin Van Roy. Learning to optimize via information-directed sampling.Advances in neural information processing systems, 27, 2014. 11
work page 2014
-
[5]
Robert C Wilson, Andra Geana, John M White, Elliot A Ludvig, and Jonathan D Cohen. Humans use directed and random exploration to solve the explore–exploit dilemma.Journal of experimental psychology: General, 143(6):2074, 2014
work page 2074
-
[6]
Uncertainty and exploration.Decision, 6(3):277, 2019
Samuel J Gershman. Uncertainty and exploration.Decision, 6(3):277, 2019
work page 2019
-
[7]
Cortical substrates for exploratory decisions in humans.Nature, 441(7095):876–879, 2006
Nathaniel D Daw, John P O’doherty, Peter Dayan, Ben Seymour, and Raymond J Dolan. Cortical substrates for exploratory decisions in humans.Nature, 441(7095):876–879, 2006
work page 2006
-
[8]
Michael J Frank, Bradley B Doll, Jen Oas-Terpstra, and Francisco Moreno. Prefrontal and striatal dopaminergic genes predict individual differences in exploration and exploitation.Nature neuroscience, 12(8):1062–1068, 2009
work page 2009
-
[9]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Sergey Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review.arXiv preprint arXiv:1805.00909, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
General duality between optimal control and estimation
Emanuel Todorov. General duality between optimal control and estimation. In2008 47th IEEE con- ference on decision and control, pages 4286–4292. IEEE, 2008
work page 2008
-
[11]
Payam Piray and Nathaniel D Daw. A model for learning based on the joint estimation of stochasticity and volatility.Nature communications, 12(1):6587, 2021
work page 2021
-
[12]
Payam Piray and Nathaniel D Daw. Computational processes of simultaneous learning of stochasticity and volatility in humans.Nature communications, 15(1):9073, 2024
work page 2024
-
[13]
Jonathan D Cohen, Samuel M McClure, and Angela J Yu. Should i stay or should i go? how the human brain manages the trade-off between exploitation and exploration.Philosophical Transactions of the Royal Society B: Biological Sciences, 362(1481):933–942, 2007
work page 2007
-
[14]
Deconstructing the human algorithms for exploration.Cognition, 173:34–42, 2018
Samuel J Gershman. Deconstructing the human algorithms for exploration.Cognition, 173:34–42, 2018
work page 2018
-
[15]
Learning the value of information in an uncertain world.Nature neuroscience, 10(9):1214–1221, 2007
Timothy EJ Behrens, Mark W Woolrich, Mark E Walton, and Matthew FS Rushworth. Learning the value of information in an uncertain world.Nature neuroscience, 10(9):1214–1221, 2007
work page 2007
-
[16]
Christoph Mathys, Jean Daunizeau, Karl J Friston, and Klaas E Stephan. A bayesian foundation for individual learning under uncertainty.Frontiers in human neuroscience, 5:39, 2011
work page 2011
-
[17]
Matthew R Nassar, Robert C Wilson, Benjamin Heasly, and Joshua I Gold. An approximately bayesian delta-rule model explains the dynamics of belief updating in a changing environment.Journal of Neu- roscience, 30(37):12366–12378, 2010
work page 2010
-
[18]
Matthew R Nassar, Katherine M Rumsey, Robert C Wilson, Kinjan Parikh, Benjamin Heasly, and Joshua I Gold. Rational regulation of learning dynamics by pupil-linked arousal systems.Nature neuroscience, 15(7):1040–1046, 2012
work page 2012
-
[19]
A tutorial on thompson sampling.Foundations and Trends®in Machine Learning, 11(1):1–99, 2018
Daniel Russo, Benjamin Van Roy, Abbas Kazerouni, Ian Osband, and Zheng Wen. A tutorial on thompson sampling.Foundations and Trends®in Machine Learning, 11(1):1–99, 2018
work page 2018
-
[20]
On bayesian upper confidence bounds for bandit problems
Emilie Kaufmann, Olivier Capp´ e, and Aur´ elien Garivier. On bayesian upper confidence bounds for bandit problems. InArtificial intelligence and statistics, pages 592–600. PMLR, 2012
work page 2012
-
[21]
John C Gittins. Bandit processes and dynamic allocation indices.Journal of the Royal Statistical Society Series B: Statistical Methodology, 41(2):148–164, 1979
work page 1979
-
[22]
Yi-Ching Yao. Some results on the gittins index for a normal reward process.Lecture Notes-Monograph Series, pages 284–294, 2006
work page 2006
-
[23]
Peter Whittle. Restless bandits: Activity allocation in a changing world.Journal of applied probability, 25(A):287–298, 1988. 12
work page 1988
-
[24]
The complexity of optimal queuing network control
Christos H Papadimitriou and John N Tsitsiklis. The complexity of optimal queuing network control. Mathematics of Operations Research, 24(2):293–305, 1999
work page 1999
-
[25]
Satisficing in time-sensitive bandit learning.arXiv preprint arXiv:1803.02855, 2018
Daniel Russo and Benjamin Van Roy. Satisficing in time-sensitive bandit learning.arXiv preprint arXiv:1803.02855, 2018
-
[26]
Nonstationary bandit learning via predictive sampling
Yueyang Liu, Benjamin Van Roy, and Kuang Xu. Nonstationary bandit learning via predictive sampling. InInternational Conference on Artificial Intelligence and Statistics, pages 6215–6244. PMLR, 2023
work page 2023
-
[27]
Optimal control as a graphical model inference problem.Machine learning, 87(2):159–182, 2012
Hilbert J Kappen, Vicen¸ c G´ omez, and Manfred Opper. Optimal control as a graphical model inference problem.Machine learning, 87(2):159–182, 2012
work page 2012
-
[28]
Maximum a Posteriori Policy Optimisation
Abbas Abdolmaleki, Jost Tobias Springenberg, Yuval Tassa, Remi Munos, Nicolas Heess, and Martin Riedmiller. Maximum a posteriori policy optimisation.arXiv preprint arXiv:1806.06920, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
Soft actor-critic: Off-policy max- imum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy max- imum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
work page 2018
-
[30]
Robot trajectory optimization using approximate inference
Marc Toussaint. Robot trajectory optimization using approximate inference. InProceedings of the 26th annual international conference on machine learning, pages 1049–1056, 2009
work page 2009
-
[31]
Planning as inference.Trends in cognitive sciences, 16(10): 485–488, 2012
Matthew Botvinick and Marc Toussaint. Planning as inference.Trends in cognitive sciences, 16(10): 485–488, 2012
work page 2012
-
[32]
Michael Browning, Timothy E Behrens, Gerhard Jocham, Jill X O’reilly, and Sonia J Bishop. Anxious individuals have difficulty learning the causal statistics of aversive environments.Nature neuroscience, 18(4):590–596, 2015
work page 2015
-
[33]
He Huang, Wesley Thompson, and Martin P Paulus. Computational dysfunctions in anxiety: failure to differentiate signal from noise.Biological psychiatry, 82(6):440–446, 2017
work page 2017
-
[34]
Muhammad H Satti, Katharina Wille, Matthew R Nassar, Radoslaw M Cichy, Nicolas W Schuck, Peter Dayan, and Rasmus Bruckner. Absence of systematic effects of internalizing psychopathology on learning under uncertainty.bioRxiv, pages 2025–05, 2025
work page 2025
-
[35]
Albert R Powers, Christoph Mathys, and Philip Robert Corlett. Pavlovian conditioning–induced hal- lucinations result from overweighting of perceptual priors.Science, 357(6351):596–600, 2017
work page 2017
-
[36]
Erdem Pulcu and Michael Browning. Affective bias as a rational response to the statistics of rewards and punishments.Elife, 6:e27879, 2017
work page 2017
-
[37]
Altered learning under uncertainty in unmedicated mood and anxiety disorders
Jessica Aylward, Vincent Valton, Woo-Young Ahn, Rebecca L Bond, Peter Dayan, Jonathan P Roiser, and Oliver J Robinson. Altered learning under uncertainty in unmedicated mood and anxiety disorders. Nature human behaviour, 3(10):1116–1123, 2019
work page 2019
-
[38]
Haoxue Fan, Samuel J Gershman, and Elizabeth A Phelps. Trait somatic anxiety is associated with reduced directed exploration and underestimation of uncertainty.Nature Human Behaviour, 7(1):102– 113, 2023
work page 2023
-
[39]
David JC MacKay.Information theory, inference and learning algorithms. Cambridge university press, 2003. 13 A Proofs of monotonicity results This appendix provides proofs of the three monotonicity results stated in Section 4 of the main text: the index decomposition (Proposition 1), the monotonicity of the exploration bonus in the observation noises(Theor...
work page 2003
-
[40]
We fixc= 1 2 throughout this paper. 19 C Experimental setup This appendix provides implementation details for the experiments of Section 6. The scale param- eterc(Eq. 7) was held at 0.5 across all experiments and not tuned per-condition; reported regret reflects this fixed setting. C.1 Baseline policies All baselines use the same Kalman tracker as CAUSE, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.