LatentBox: Storing AI-Generated Images at Scale via a Latent-First Design
Pith reviewed 2026-05-20 02:46 UTC · model grok-4.3
The pith
LatentBox stores AI-generated images as compact latent tensors and reconstructs full pixels on demand, cutting persistent storage by 78.7 percent while keeping mean and tail latency competitive with or below pure image storage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
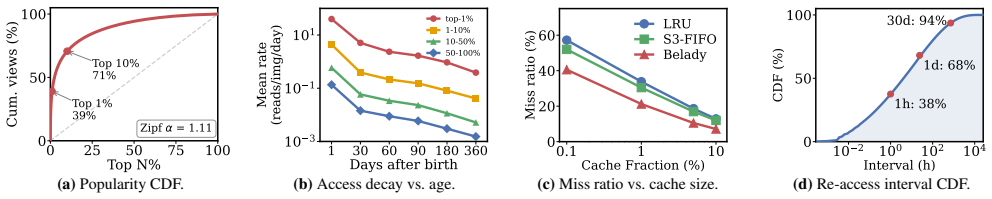
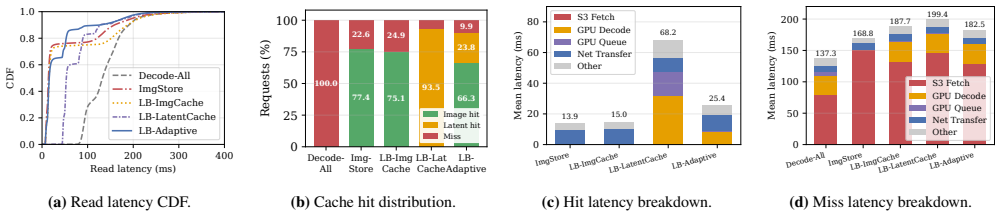
LatentBox treats compressed latents as durable storage objects and uses on-demand GPU reconstruction on the read path to trade inexpensive compute for large persistent storage savings. Motivated by the trace analysis, LatentBox keeps frequently accessed images in decoded pixel format for fast hits, stores less-active objects as compressed latents to expand effective cache capacity, and continuously adjusts the splits between the image and latent cache to optimize user-perceived access latency. Evaluation on the production trace shows a 78.7 percent reduction in persistent storage with competitive or lower mean and tail latency compared with conventional image-based storage.
What carries the argument
Dynamic split between a small decoded-image cache for hot objects and a much larger latent cache for cold objects, with on-demand GPU reconstruction triggered only on cache misses.
If this is right
- Generative-image platforms can store several times more images on the same hardware without adding disks or bandwidth.
- The cost of keeping every generated image permanently drops because the persistent form is now the compact latent rather than the full pixel file.
- Cache capacity effectively increases because most objects occupy far less space until they are actually requested.
- Reconstruction compute becomes a first-class resource that must be provisioned alongside storage, shifting the bottleneck from capacity to GPU cycles on read paths.
Where Pith is reading between the lines
- Similar latent-first designs could apply to other deterministic generative outputs such as video frames or 3-D assets if they share the same reconstruction property.
- Integrating reconstruction directly into storage controllers or network cards might remove the GPU step entirely for many requests.
- Workloads with bursty or one-time access patterns would need different cache policies than the ones tuned on this long-term trace.
Load-bearing premise
Reconstructing pixels from latents on GPUs adds only acceptable latency for user-facing reads and the access patterns observed in the 35-month trace will continue to hold for future workloads.
What would settle it
A production workload in which GPU reconstruction raises p99 latency by more than 20 ms for at least 5 percent of requests, or in which the effective storage reduction falls below 50 percent.
Figures







read the original abstract
The explosive growth of AI-generated images has created a sustainability challenge for storage infrastructure. Platforms like Midjourney and Adobe Firefly already host billions of generative images, yet conventional object stores persist them as blobs with full-resolution pixels, consuming huge amounts of storage capacity and bandwidth. Unlike natural photos, however, AI-generated images can be deterministically reconstructed from compact, model-native latent tensors, making persistent image storage fundamentally redundant. This paper presents LatentBox, a latent-first storage system for AI-generated images. LatentBox treats compressed latents as durable storage objects and uses on-demand GPU reconstruction on the read path to trade inexpensive compute for large persistent storage savings. Our design is guided by the first large-scale analysis of AI-generated image access we are aware of, based on a 35-month, 2-billion-request production trace from a major generative-content platform. Motivated by the trace analysis, LatentBox keeps frequently accessed images in decoded pixel format for fast hits, stores less-active objects as compressed latents to expand effective cache capacity, and continuously adjusts the splits between the image and latent cache to optimize user-perceived access latency.We build a LatentBox prototype and evaluate it with the production trace. LatentBox reduces persistent storage by 78.7% with competitive or even lower mean and tail latency over a pure image-based storage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents LatentBox, a latent-first storage system for AI-generated images. It stores images as compressed latent tensors (rather than full-resolution pixel blobs) and performs on-demand GPU reconstruction on the read path. Design decisions are motivated by analysis of a 35-month, 2-billion-request production trace; the system maintains a dynamic split between an image cache (for hot objects) and a latent cache (to expand effective capacity) while continuously tuning the split to optimize user-perceived latency. The central empirical claim is a 78.7% reduction in persistent storage with competitive or lower mean and tail latencies relative to a pure image-based baseline.
Significance. If the latency results hold after proper isolation of reconstruction costs, the work demonstrates a concrete storage-compute tradeoff that could materially reduce capacity and bandwidth demands on platforms hosting billions of generative images. The large-scale trace analysis is a notable strength, providing empirical grounding for cache policies that would otherwise rest on synthetic assumptions. The approach is falsifiable via replay of the same trace with measured decoder forward-pass times.
major comments (2)
- [Evaluation] Evaluation section: the headline claim of competitive or lower tail latency requires that on-demand GPU reconstruction overhead (including decoder forward passes) was measured end-to-end and under realistic contention when the dynamic cache policy moves objects into the latent tier. The provided abstract and trace-replay description give no indication that reconstruction time was isolated or that p99 numbers include warm-GPU vs. contended-GPU cases; without this, the net-win argument over pure image storage is not yet load-bearing.
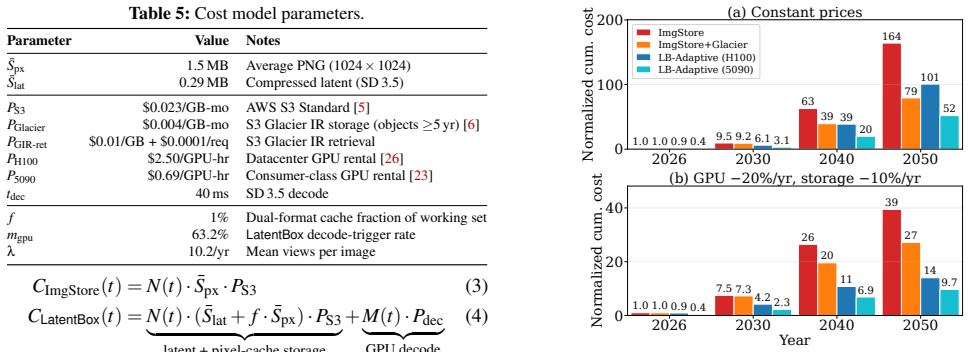
- [Evaluation] Evaluation section: the 78.7% storage-reduction figure and all latency comparisons lack reported error bars, confidence intervals, or sensitivity analysis to trace variations (e.g., different 35-month sub-windows or access-pattern shifts). This omission makes it impossible to judge whether the reported gains are statistically robust or sensitive to the particular production trace.
minor comments (2)
- [Abstract] Abstract: the sentence describing the dynamic cache split policy could be expanded with one concrete example of how the split threshold is adjusted (e.g., latency target or hit-rate feedback loop) to give readers an immediate sense of the control mechanism.
- [Evaluation] The manuscript would benefit from an explicit statement of the GPU model and batch size used for reconstruction measurements so that the overhead numbers can be reproduced or compared to other decoder implementations.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which highlight important aspects of our evaluation that require clarification and strengthening. We address each major comment below and have revised the evaluation section of the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the headline claim of competitive or lower tail latency requires that on-demand GPU reconstruction overhead (including decoder forward passes) was measured end-to-end and under realistic contention when the dynamic cache policy moves objects into the latent tier. The provided abstract and trace-replay description give no indication that reconstruction time was isolated or that p99 numbers include warm-GPU vs. contended-GPU cases; without this, the net-win argument over pure image storage is not yet load-bearing.
Authors: We agree that explicit end-to-end measurement of reconstruction overhead under contention is necessary to support the latency claims. Our prototype trace replay did capture full read-path latencies, including decoder forward passes when objects were served from the latent tier. However, the submitted manuscript did not isolate reconstruction time or separately report warm-GPU versus contended-GPU p99 cases. In the revised version we have added a new subsection with these breakdowns, including measured decoder times under varying GPU load, to make the comparison against the pure-image baseline more transparent. revision: yes
-
Referee: [Evaluation] Evaluation section: the 78.7% storage-reduction figure and all latency comparisons lack reported error bars, confidence intervals, or sensitivity analysis to trace variations (e.g., different 35-month sub-windows or access-pattern shifts). This omission makes it impossible to judge whether the reported gains are statistically robust or sensitive to the particular production trace.
Authors: The referee correctly notes the absence of error bars and sensitivity analysis. The 78.7% storage reduction and latency results were obtained from replay of the full production trace, but the original submission did not quantify variability across trace sub-windows or report confidence intervals. We have performed additional sensitivity experiments on multiple 35-month sub-windows and access-pattern shifts; the revised manuscript now includes error bars on all latency plots and a dedicated sensitivity analysis showing that both storage savings and latency benefits remain consistent. revision: yes
Circularity Check
No circularity; results from empirical trace-driven evaluation on external production data.
full rationale
The paper presents a systems design whose headline claims (78.7% storage reduction and competitive latency) are obtained by building a prototype and replaying a 35-month, 2-billion-request production trace from an external platform. No equations, fitted parameters, or predictions are shown to reduce to the inputs by construction; the trace analysis guides the cache-split policy but the reported numbers come from direct end-to-end measurement against a baseline image store. No load-bearing self-citations or uniqueness theorems are invoked in the provided text. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- image vs latent cache split thresholds
axioms (1)
- domain assumption AI-generated images can be deterministically reconstructed from compact model-native latent tensors
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LatentBox treats compressed latents as durable storage objects and uses on-demand GPU reconstruction on the read path to trade inexpensive compute for large persistent storage savings.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dual-format cache that caches hot objects as decoded images for fast hits and colder objects as compact latents for coverage and an adaptive cache resizer
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.