Efficient Long-Context Modeling in Diffusion Language Models via Block Approximate Sparse Attention
Pith reviewed 2026-05-20 05:48 UTC · model grok-4.3
The pith
Block Approximate Sparse Attention selects important blocks in a downsampled space to let diffusion language models handle long contexts efficiently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
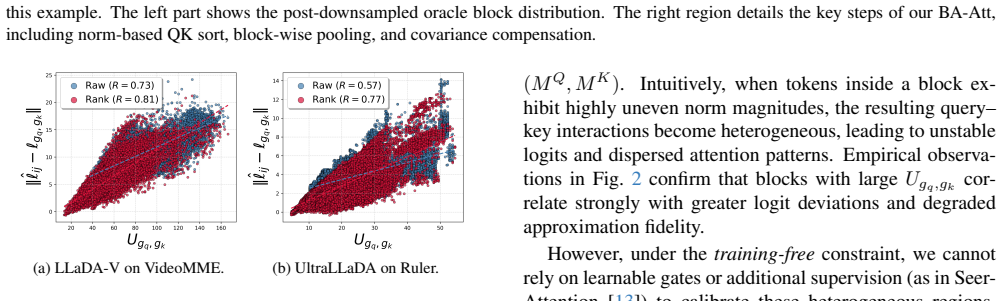
By defining an oracle post-downsample attention map and bounding the approximation error, the authors show that a lightweight norm-sorting module combined with covariance compensation using only diagonal QK variances can identify informative regions in the compact downsampled space, enabling sparse attention that matches full-attention performance at 50 percent sparsity.
What carries the argument
The block-wise pre-downsampled operation inside BA-Att, which locates informative regions via norm sorting and diagonal-variance correction instead of fixed sampling patterns.
If this is right
- Attention computation runs up to 6.95 times faster than FlashAttention.
- Output quality stays near the full-attention level at 50 percent sparsity.
- The same operator works across standard language models, multimodal language models, and video generation models.
Where Pith is reading between the lines
- The same pre-downsampling idea could reduce memory pressure when applying diffusion models to hour-long video or book-length text.
- Content-adaptive block selection may prove more reliable than static sparsity patterns in other transformer variants.
- Replacing the diagonal approximation with a cheap low-rank correction might tighten the error bound further.
Load-bearing premise
Sorting blocks by norms in the downsampled space and correcting only with diagonal QK variances is enough to catch the important tokens without systematic misses when the input distribution changes.
What would settle it
Apply the sparse operator at 50 percent sparsity to a dataset drawn from a clearly shifted distribution and measure whether generation quality falls more than a few percent below the full-attention baseline.
Figures



read the original abstract
Diffusion Language Models (DLMs) enable globally coherent, bidirectional, and controllable text generation, offering advantages over traditional autoregressive LLMs, while scaling to ultra-long sequences remains costly. Many existing block-sparse attention methods select blocks by fixed sampling patterns over the high-resolution attention space, such as tail regions or anti-diagonal stripes. Such prior-driven sampling can miss salient tokens and introduce instability under distribution shifts. In this paper, we propose the Block Approximate Sparse Attention framework (BA-Att) with block-wise pre-downsampled operation, which identifies informative regions within a compact downsampled space, avoiding reliance on brittle positional priors. To analyze its theoretical behavior, we define an oracle post-downsample attention map and formalize the approximation error between pre- and post-downsample schemes. Based on this insight, we introduce a lightweight norm-sorting module and a covariance-compensated correction that approximates full covariance using diagonal QK variances, reducing computational complexity. Extensive experiments show that our operator achieves up to 6.95x acceleration over FlashAttention in attention computation, and maintains near full-attention performance at 50% sparsity across language models, multimodal language models, and video generation models, demonstrating strong efficiency and generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Block Approximate Sparse Attention (BA-Att) framework for efficient long-context modeling in Diffusion Language Models. It introduces block-wise pre-downsampled operations to select informative regions without relying on fixed positional priors, along with a lightweight norm-sorting module and a covariance-compensated correction that approximates full covariance using only diagonal QK variances. The authors define an oracle post-downsample attention map and formalize the approximation error between pre- and post-downsample schemes. Experiments claim up to 6.95x acceleration over FlashAttention while preserving near full-attention performance at 50% sparsity across language models, multimodal language models, and video generation models.
Significance. If the central claims hold, the work offers a practical path to scaling bidirectional diffusion LMs to ultra-long contexts with substantial speedups and cross-modal generalization. The explicit formalization of the oracle map and approximation error, combined with avoidance of brittle sampling patterns, represents a constructive contribution to sparse attention design for generative models.
major comments (2)
- [Abstract / Theoretical Analysis] Abstract and theoretical analysis: The formalization of the approximation error between pre- and post-downsample schemes states that the covariance-compensated correction 'approximates full covariance using diagonal QK variances,' yet supplies no quantitative bounds on the contribution of ignored off-diagonal terms. In bidirectional (non-causal) attention, these terms can encode long-range dependencies; without such bounds or a concrete test under distribution shift, it remains unclear whether the 50% sparsity result systematically preserves salient blocks.
- [Experiments] Experiments: The reported maintenance of near full-attention performance at 50% sparsity is summarized at a high level only, with no ablations isolating the covariance correction or quantitative evidence that the result holds after distribution shift. This directly bears on the generalization claim across language, multimodal, and video models.
minor comments (2)
- [Method] The description of the norm-sorting module would benefit from pseudocode or a small algorithmic box to clarify its lightweight implementation.
- [Figures] Figure captions for the experimental results could include more precise metrics (e.g., exact sparsity ratios and per-model speedups) rather than summary statements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the theoretical analysis and experimental validation.
read point-by-point responses
-
Referee: [Abstract / Theoretical Analysis] Abstract and theoretical analysis: The formalization of the approximation error between pre- and post-downsample schemes states that the covariance-compensated correction 'approximates full covariance using diagonal QK variances,' yet supplies no quantitative bounds on the contribution of ignored off-diagonal terms. In bidirectional (non-causal) attention, these terms can encode long-range dependencies; without such bounds or a concrete test under distribution shift, it remains unclear whether the 50% sparsity result systematically preserves salient blocks.
Authors: We agree that the current formalization defines the oracle post-downsample map and approximation error but does not supply explicit quantitative bounds on off-diagonal QK covariance contributions. In the revised manuscript, we will add a derivation of an error bound under the assumption of bounded pairwise correlations in the QK matrix (common in practice for normalized embeddings) and discuss its relevance to long-range dependencies in bidirectional attention. This will better support the claim that salient blocks are preserved at 50% sparsity. revision: yes
-
Referee: [Experiments] Experiments: The reported maintenance of near full-attention performance at 50% sparsity is summarized at a high level only, with no ablations isolating the covariance correction or quantitative evidence that the result holds after distribution shift. This directly bears on the generalization claim across language, multimodal, and video models.
Authors: We acknowledge that the experiments section currently reports aggregate performance without isolating the covariance correction or testing under explicit distribution shifts. In the revision, we will add an ablation study measuring the incremental benefit of the covariance correction and include quantitative results on out-of-domain or shifted sequences (e.g., longer contexts or cross-domain prompts) for the language, multimodal, and video models. These additions will directly address the generalization concerns. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines an oracle post-downsample attention map and formalizes approximation error as an independent theoretical step, then introduces explicit modules (norm-sorting and diagonal-QK covariance correction) whose construction and error analysis are described separately from the final performance metrics. No step reduces a claimed prediction or result to a fitted parameter or self-citation by construction; the speedup and sparsity claims are presented as empirical outcomes of the proposed operator rather than tautological re-expressions of inputs. The approximation using only diagonal variances is an explicit modeling choice with acknowledged limitations, not a hidden self-definition.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce a lightweight norm-sorting module and a covariance-compensated correction that approximates full covariance using diagonal QK variances
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
define an oracle post-downsample attention map and formalize the approximation error between pre- and post-downsample schemes
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench: A bilingual, multitask benchmark for long context under- standing.arXiv preprint arXiv:2308.14508, 2023. 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Long- former: The long-document transformer.arXiv:2004.05150,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[3]
Cambridge University Press, Cambridge, UK, 2004
Stephen Boyd and Lieven Vandenberghe.Convex Optimiza- tion. Cambridge University Press, Cambridge, UK, 2004. 3
work page 2004
-
[4]
Analog bits: Generating discrete data using diffusion models with self-conditioning
Ting Chen, Ruixiang Zhang, and Geoffrey Hinton. Analog bits: Generating discrete data using diffusion models with self-conditioning.arXiv preprint arXiv:2208.04202, 2022. 7
-
[5]
Zixiang Chen, Huizhuo Yuan, Yongqian Li, Yiwen Kou, Junkai Zhang, and Quanquan Gu. Fast sampling via de- randomization for discrete diffusion models.arXiv preprint arXiv:2312.09193, 2023. 7
-
[6]
Generating long sequences with sparse transformers, 2019
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers, 2019. 8
work page 2019
-
[7]
Rethink- ing attention with performers, 2022
Krzysztof Choromanski, Valerii Likhosherstov, David Do- han, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, and Adrian Weller. Rethink- ing attention with performers, 2022. 3
work page 2022
-
[8]
FlashAttention-2: Faster attention with better par- allelism and work partitioning, 2023
Tri Dao. FlashAttention-2: Faster attention with better par- allelism and work partitioning, 2023. 2, 6
work page 2023
-
[9]
Fu, Stefano Ermon, Atri Rudra, and Christopher R ´e
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher R ´e. Flashattention: Fast and memory-efficient exact attention with io-awareness, 2022. 3
work page 2022
-
[10]
Continuous diffusion for categorical data
Sander Dieleman, Laurent Sartran, Arman Roshannai, Niko- lay Savinov, Yaroslav Ganin, Pierre H Richemond, Arnaud Doucet, Robin Strudel, Chris Dyer, Conor Durkan, et al. Continuous diffusion for categorical data.arXiv preprint arXiv:2211.15089, 2022. 7
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Scaling rectified flow trans- formers for high-resolution image synthesis, 2024
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yan- nik Marek, and Robin Rombach. Scaling rectified flow trans- formers for high-resolution image synthesis, 2024. 7
work page 2024
-
[12]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever compre- hensive evaluation benchmark of multi-modal llms in video analysis.arXiv preprint arXiv:2405.21075, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Seerattention: Learning in- trinsic sparse attention in your llms, 2025
Yizhao Gao, Zhichen Zeng, Dayou Du, Shijie Cao, Peiyuan Zhou, Jiaxing Qi, Junjie Lai, Hayden Kwok-Hay So, Ting Cao, Fan Yang, and Mao Yang. Seerattention: Learning in- trinsic sparse attention in your llms, 2025. 1, 2, 4, 8
work page 2025
-
[14]
Discrete flow matching.arXiv preprint arXiv:2407.15595,
Itai Gat, Tal Remez, Neta Shaul, Felix Kreuk, Ricky TQ Chen, Gabriel Synnaeve, Yossi Adi, and Yaron Lipman. Discrete flow matching.arXiv preprint arXiv:2407.15595,
-
[15]
DiffuSeq: Sequence to Sequence Text Generation with Diffusion Models
Shansan Gong, Mukai Li, Jiangtao Feng, Zhiyong Wu, and LingPeng Kong. Diffuseq: Sequence to sequence text generation with diffusion models.arXiv preprint arXiv:2210.08933, 2022. 7
work page internal anchor Pith review arXiv 2022
-
[16]
Bayesian flow networks.arXiv preprint arXiv:2308.07037, 2023
Alex Graves, Rupesh Kumar Srivastava, Timothy Atkin- son, and Faustino Gomez. Bayesian flow networks.arXiv preprint arXiv:2308.07037, 2023
-
[17]
Xiaochuang Han, Sachin Kumar, and Yulia Tsvetkov. Ssd- lm: Semi-autoregressive simplex-based diffusion language model for text generation and modular control.arXiv preprint arXiv:2210.17432, 2022. 7
-
[18]
Ultrallada: Scaling the context length to 128k for diffusion large language models, 2025
Guangxin He, Shen Nie, Fengqi Zhu, Yuankang Zhao, Tianyi Bai, Ran Yan, Jie Fu, Chongxuan Li, and Binhang Yuan. Ultrallada: Scaling the context length to 128k for diffusion large language models, 2025. 6, 7
work page 2025
-
[19]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long- context language models?arXiv preprint arXiv:2404.06654,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
VBench: Com- prehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Com- prehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Reco...
work page 2024
-
[21]
Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention, 2024. 1, 2
work page 2024
-
[22]
Disk: A diffusion model for structured knowledge
Ouail Kitouni, Niklas Nolte, James Hensman, and Bhaskar Mitra. Disk: A diffusion model for structured knowledge. arXiv preprint arXiv:2312.05253, 2023. 7
-
[23]
Xunhao Lai, Jianqiao Lu, Yao Luo, Yiyuan Ma, and Xun Zhou. Flexprefill: A context-aware sparse attention mecha- nism for efficient long-sequence inference, 2025. 1, 2
work page 2025
-
[24]
Selective attention improves transformer, 2024
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Selective attention improves transformer, 2024. 8
work page 2024
-
[25]
Xiang Li, John Thickstun, Ishaan Gulrajani, Percy S Liang, and Tatsunori B Hashimoto. Diffusion-lm improves control- lable text generation.Advances in Neural Information Pro- cessing Systems, 35:4328–4343, 2022. 7
work page 2022
-
[26]
Zhenghao Lin, Yeyun Gong, Yelong Shen, Tong Wu, Zhi- hao Fan, Chen Lin, Nan Duan, and Weizhu Chen. Text generation with diffusion language models: A pre-training approach with continuous paragraph denoise. InInter- national Conference on Machine Learning, pages 21051– 21064. PMLR, 2023. 7
work page 2023
-
[27]
Longllada: Unlocking long con- text capabilities in diffusion llms, 2025
Xiaoran Liu, Zhigeng Liu, Zengfeng Huang, Qipeng Guo, Ziwei He, and Xipeng Qiu. Longllada: Unlocking long con- text capabilities in diffusion llms, 2025. 7
work page 2025
- [28]
-
[29]
Zhang, Zhilin Yang, Xinyu Zhou, Mingxing Zhang, and Jiezhong Qiu
Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, Tao Jiang, Chao Hong, Shaowei Liu, Weiran He, Enming Yuan, Yuzhi Wang, Zhiqi Huang, Huan Yuan, Suting Xu, Xinran Xu, Guokun Lai, Yanru Chen, Huabin Zheng, Junjie Yan, Jian- lin Su, Yuxin Wu, Neo Y . Zhang, Zhilin Yang, Xinyu Zhou, Mingxing Zhang, and Jiezhong Qiu. Moba: Mixture of block attention for long-co...
work page 2025
-
[30]
Rabeeh Karimi Mahabadi, Hamish Ivison, Jaesung Tae, James Henderson, Iz Beltagy, Matthew E. Peters, and Ar- man Cohan. Tess: Text-to-text self-conditioned simplex dif- fusion, 2024. 7
work page 2024
-
[31]
ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question an- swering about charts with visual and logical reasoning.arXiv preprint arXiv:2203.10244, 2022. 6
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InProceed- ings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209, 2021. 6
work page 2021
-
[33]
Minesh Mathew, Viraj Bagal, Rub `en Tito, Dimosthenis Karatzas, Ernest Valveny, and CV Jawahar. Infographicvqa. InProceedings of the IEEE/CVF Winter Conference on Ap- plications of Computer Vision, pages 1697–1706, 2022. 6
work page 2022
-
[34]
Transformers are multi-state rnns, 2024
Matanel Oren, Michael Hassid, Nir Yarden, Yossi Adi, and Roy Schwartz. Transformers are multi-state rnns, 2024. 8
work page 2024
-
[35]
Hellendoorn, and Graham Neubig
Machel Reid, Vincent J. Hellendoorn, and Graham Neubig. Diffuser: Discrete diffusion via edit-based reconstruction,
-
[36]
Richemond, Sander Dieleman, and Arnaud Doucet
Pierre H. Richemond, Sander Dieleman, and Arnaud Doucet. Categorical sdes with simplex diffusion, 2022. 7
work page 2022
-
[37]
Self-conditioned embedding diffusion for text generation.arXiv preprint arXiv:2211.04236, 2022
Robin Strudel, Corentin Tallec, Florent Altch ´e, Yilun Du, Yaroslav Ganin, Arthur Mensch, Will Grathwohl, Niko- lay Savinov, Sander Dieleman, Laurent Sifre, et al. Self- conditioned embedding diffusion for text generation.arXiv preprint arXiv:2211.04236, 2022. 7
-
[38]
Score-based continuous-time discrete diffusion models
Haoran Sun, Lijun Yu, Bo Dai, Dale Schuurmans, and Han- jun Dai. Score-based continuous-time discrete diffusion models.arXiv preprint arXiv:2211.16750, 2022. 7
-
[39]
Philippe Tillet, H. T. Kung, and David Cox. Triton: an in- termediate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN In- ternational Workshop on Machine Learning and Program- ming Languages, page 10–19, New York, NY , USA, 2019. Association for Computing Machinery. 3
work page 2019
-
[40]
Wan: Open and advanced large-scale video generative models, 2025
Team Wan, Ang Wang, and Baole Ai etal. Wan: Open and advanced large-scale video generative models, 2025. 6
work page 2025
-
[41]
MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding
Fei Wang, Xingyu Fu, James Y Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, et al. Muirbench: A comprehensive bench- mark for robust multi-image understanding.arXiv preprint arXiv:2406.09411, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding, 2025. 6
work page 2025
-
[43]
Ar-diffusion: Auto-regressive diffusion model for text generation, 2023
Tong Wu, Zhihao Fan, Xiao Liu, Yeyun Gong, Yelong Shen, Jian Jiao, Hai-Tao Zheng, Juntao Li, Zhongyu Wei, Jian Guo, Nan Duan, and Weizhu Chen. Ar-diffusion: Auto-regressive diffusion model for text generation, 2023. 7
work page 2023
-
[44]
x.ai. Grok-1.5 vision preview. 2024. https://x.ai/news/grok- 1.5v/. 6
work page 2024
-
[45]
Sparse videogen: Accelerating video diffusion transformers with spatial-temporal sparsity, 2025
Haocheng Xi, Shuo Yang, Yilong Zhao, Chenfeng Xu, Muyang Li, Xiuyu Li, Yujun Lin, Han Cai, Jintao Zhang, Dacheng Li, Jianfei Chen, Ion Stoica, Kurt Keutzer, and Song Han. Sparse videogen: Accelerating video diffusion transformers with spatial-temporal sparsity, 2025. 7
work page 2025
-
[46]
Efficient streaming language models with attention sinks, 2024
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks, 2024. 8
work page 2024
-
[47]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InICLR, 2024. 1
work page 2024
-
[48]
Xattention: Block sparse attention with an- tidiagonal scoring, 2025
Ruyi Xu, Guangxuan Xiao, Haofeng Huang, Junxian Guo, and Song Han. Xattention: Block sparse attention with an- tidiagonal scoring, 2025. 1, 2, 8
work page 2025
-
[49]
Kaiwen Xue, Yuhao Zhou, Shen Nie, Xu Min, Xiaolu Zhang, Jun Zhou, and Chongxuan Li. Unifying bayesian flow net- works and diffusion models through stochastic differential equations.arXiv preprint arXiv:2404.15766, 2024. 7
-
[50]
Shuo Yang, Haocheng Xi, Yilong Zhao, Muyang Li, Jintao Zhang, Han Cai, Yujun Lin, Xiuyu Li, Chenfeng Xu, Kelly Peng, Jianfei Chen, Song Han, Kurt Keutzer, and Ion Stoica. Sparse videogen2: Accelerate video generation with sparse attention via semantic-aware permutation, 2025. 6
work page 2025
-
[51]
Diffusion language models can perform many tasks with scaling and instruction-finetuning
Jiasheng Ye, Zaixiang Zheng, Yu Bao, Lihua Qian, and Quanquan Gu. Diffusion language models can perform many tasks with scaling and instruction-finetuning.arXiv preprint arXiv:2308.12219, 2023. 7
-
[52]
Jiasheng Ye, Zaixiang Zheng, Yu Bao, Lihua Qian, and Mingxuan Wang. Dinoiser: Diffused conditional se- quence learning by manipulating noises.arXiv preprint arXiv:2302.10025, 2023. 7
-
[53]
Zihao Ye, Ruihang Lai, Roy Lu, Chien-Yu Lin, Size Zheng, Lequn Chen, Tianqi Chen, and Luis Ceze. Cascade infer- ence: Memory bandwidth efficient shared prefix batch de- coding.https://flashinfer.ai/2024/01/08/ cascade-inference.html, 2024. Accessed on 2024- 02-01. 6
work page 2024
-
[54]
Llada-v: Large language diffusion models with visual instruction tuning,
Zebin You, Shen Nie, Xiaolu Zhang, Jun Hu, Jun Zhou, Zhiwu Lu, Ji-Rong Wen, and Chongxuan Li. Llada-v: Large language diffusion models with visual instruction tuning,
-
[55]
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Y . X. Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wenfeng Liang, and Wangding Zeng. Native sparse atten- tion: Hardware-aligned and natively trainable sparse atten- tion, 2025. 7
work page 2025
-
[56]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for ex- pert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for ex- pert agi. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9556– 9567, 2024. 6
work page 2024
-
[57]
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, et al. Mmmu-pro: A more robust multi- discipline multimodal understanding benchmark.arXiv preprint arXiv:2409.02813, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences.Advances in Neu- ral Information Processing Systems, 33, 2020. 8
work page 2020
-
[59]
Fast video gen- eration with sliding tile attention, 2025
Peiyuan Zhang, Yongqi Chen, Runlong Su, Hangliang Ding, Ion Stoica, Zhenghong Liu, and Hao Zhang. Fast video gen- eration with sliding tile attention, 2025. 7
work page 2025
-
[60]
Ruixiang Zhang, Shuangfei Zhai, Yizhe Zhang, James Thornton, Zijing Ou, Joshua Susskind, and Navdeep Jaitly. Target concrete score matching: A holistic framework for discrete diffusion.arXiv preprint arXiv:2504.16431, 2025. 7
-
[61]
Planner: Generating diversified paragraph via latent language diffusion model
Yizhe Zhang, Jiatao Gu, Zhuofeng Wu, Shuangfei Zhai, Joshua Susskind, and Navdeep Jaitly. Planner: Generating diversified paragraph via latent language diffusion model. Advances in Neural Information Processing Systems, 36: 80178–80190, 2023. 7
work page 2023
-
[62]
H 2o: Heavy-hitter oracle for efficient generative in- ference of large language models, 2023
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R´e, Clark Barrett, Zhangyang Wang, and Beidi Chen. H 2o: Heavy-hitter oracle for efficient generative in- ference of large language models, 2023. 8
work page 2023
-
[63]
Kaiwen Zheng, Yongxin Chen, Hanzi Mao, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling, 2024. 7
work page 2024
-
[64]
A reparameterized discrete diffusion model for text generation.arXiv preprint arXiv:2302.05737, 2023
Lin Zheng, Jianbo Yuan, Lei Yu, and Lingpeng Kong. A reparameterized discrete diffusion model for text generation. ArXiv, abs/2302.05737, 2023. 7
-
[65]
MLVU: Benchmarking Multi-task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: A comprehensive benchmark for multi-task long video understanding.arXiv preprint arXiv:2406.04264,
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
Llada 1.5: Variance- reduced preference optimization for large language diffusion models, 2025
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Llada 1.5: Variance- reduced preference optimization for large language diffusion models, 2025. 6
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.