Fast 4D Mesh Generation by Spatio-Temporal Attention Chains
Pith reviewed 2026-05-20 06:47 UTC · model grok-4.3
The pith
Spatio-Temporal Attention Chains generate accurate 4D meshes from video in 9 seconds by propagating latent correspondences without explicit matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that temporal correspondences emerge inside a 4D backbone long before its generated meshes become visually accurate. The Spatio-Temporal Attention Chain exploits this by mapping vertices from an anchor mesh to latent tokens, following temporal correspondences in latent space, and recovering frame-specific vertices through latent-to-vertex attention. This design avoids expensive explicit matching while preserving anchor mesh details, thereby improving dynamic mesh geometry and temporal consistency.
What carries the argument
Spatio-Temporal Attention Chain, which propagates vertex information across space and time by mapping anchor vertices to latent tokens, tracking correspondences in latent space, and recovering per-frame vertices via attention.
If this is right
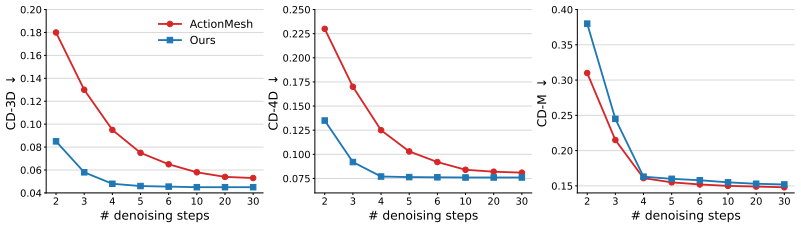
- Generates a 4D mesh in 9 seconds, achieving a 13 times speedup over prior methods.
- Processes videos up to 16 times longer without degrading mesh quality.
- Delivers competitive zero-shot performance on 2D object tracking and 4D tracking tasks.
- Enables reliable camera estimation, a capability absent from previous 4D mesh generators.
Where Pith is reading between the lines
- The reliance on early latent structure suggests the chain could be applied to other video-based 3D generative models where internal representations form before final outputs refine.
- Speedups of this magnitude could open real-time dynamic reconstruction uses in robotics or augmented reality that current methods cannot support.
- The separation of correspondence finding from mesh refinement points to a broader pattern where latent-space propagation replaces explicit feature matching in video tasks.
Load-bearing premise
Temporal correspondences become reliable in the latent space of the 4D backbone before the generated meshes achieve visual accuracy.
What would settle it
Extract attention-based correspondences from early latent states of the 4D backbone on videos with ground-truth tracks and check whether their accuracy matches or exceeds that of correspondences from final visually accurate meshes.
Figures







read the original abstract
4D mesh generation has recently emerged as a powerful paradigm for recovering dynamic 3D structure from videos, but existing methods remain slow, computationally expensive, and difficult to scale to longer sequences. We introduce a training-free approach that accelerates 4D mesh generation while improving temporal correspondence quality. Our key observation is that temporal correspondences emerge inside a 4D backbone long before its generated meshes become visually accurate. We exploit this with a general framework we call Spatio-Temporal Attention Chain which propagates information across space and time. Starting from vertices on an anchor mesh, the chain maps vertices to latent tokens. It then follows temporal correspondences in latent space, and recovers frame-specific vertices through latent-to-vertex attention. This design avoids expensive explicit matching while preserving anchor mesh details and thereby improving dynamic mesh geometry and temporal consistency. Compared to state-of-the-art, our method generates a 4D mesh in 9 seconds, achieving a $13\times$ speedup while producing higher-quality results. Moreover, our approach scales to videos up to $16\times$ longer without degrading mesh quality. Beyond generation, the improved correspondences enable competitive zero-shot performance on two downstream tasks: 2D object tracking and 4D tracking. We further show that our framework enables reliable camera estimation, a capability not supported by prior 4D mesh generation methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a training-free Spatio-Temporal Attention Chain for fast 4D mesh generation from videos. It exploits the observation that temporal correspondences emerge in the latent space of a 4D backbone well before output meshes achieve visual accuracy. The chain maps anchor-mesh vertices to latent tokens, follows temporal correspondences in latent space, and recovers per-frame vertices via latent-to-vertex attention. Claims include generating a 4D mesh in 9 seconds (13× speedup over SOTA), higher quality, scalability to 16× longer videos without quality loss, and competitive zero-shot results on 2D/4D tracking plus camera estimation.
Significance. If the timing observation is validated and the reported speed/quality gains hold under rigorous testing, the work offers a practical route to scalable 4D reconstruction without retraining. The training-free design and claimed scaling behavior are clear strengths that could broaden applicability in video-based dynamic 3D tasks.
major comments (1)
- [Abstract / Key Observation] Abstract / Key Observation: The Spatio-Temporal Attention Chain design rests on the claim that reliable temporal correspondences appear in the 4D backbone's latent space long before the generated meshes become geometrically accurate. No layer-wise or depth-wise measurements (e.g., correspondence endpoint error versus Chamfer distance or normal consistency across successive layers) are supplied to confirm this timing. Without such evidence the chain risks propagating noisy early correspondences, which would undermine both the claimed speedup and the quality improvements.
minor comments (2)
- [Abstract] The abstract asserts a 13× speedup and higher-quality results relative to state-of-the-art but does not name the specific baseline methods, datasets, or evaluation metrics used for these comparisons.
- [Abstract] Implementation details such as the exact 4D backbone architecture, the number of layers traversed by the attention chain, and how anchor vertices are chosen would clarify reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point by point below and commit to revisions that will strengthen the validation of our key observation.
read point-by-point responses
-
Referee: [Abstract / Key Observation] Abstract / Key Observation: The Spatio-Temporal Attention Chain design rests on the claim that reliable temporal correspondences appear in the 4D backbone's latent space long before the generated meshes become geometrically accurate. No layer-wise or depth-wise measurements (e.g., correspondence endpoint error versus Chamfer distance or normal consistency across successive layers) are supplied to confirm this timing. Without such evidence the chain risks propagating noisy early correspondences, which would undermine both the claimed speedup and the quality improvements.
Authors: We agree that explicit layer-wise or depth-wise measurements would provide stronger direct support for the timing observation. The manuscript currently motivates the Spatio-Temporal Attention Chain from this observation and validates the overall approach through end-to-end speed, quality, and scaling results, but does not include the requested per-layer correspondence endpoint error versus geometric accuracy comparisons. To address this, we will add the suggested analysis in the revised manuscript, including quantitative plots of correspondence accuracy at successive layers of the 4D backbone alongside Chamfer distance and normal consistency metrics. This will confirm that reliable correspondences emerge early while geometric refinement occurs later. revision: yes
Circularity Check
No significant circularity; derivation relies on empirical observation from external backbones
full rationale
The paper introduces a training-free Spatio-Temporal Attention Chain framework justified by the stated observation that temporal correspondences appear early in 4D backbones. No equations, fitted parameters, or self-citations are shown to reduce the central claims to inputs by construction. The speedup, scaling, and downstream task results are presented as empirical outcomes rather than tautological redefinitions. The method description maps vertices to latents and follows correspondences without invoking self-referential definitions or renaming known results as novel derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Temporal correspondences emerge inside a 4D backbone long before its generated meshes become visually accurate.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We exploit this with a general framework we call Spatio-Temporal Attention Chain which propagates information across space and time. Starting from vertices on an anchor mesh, the chain maps vertices to latent tokens. It then follows temporal correspondences in latent space, and recovers frame-specific vertices through latent-to-vertex attention.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
each attention row is a probability distribution over latent tokens, so multiplying attention maps gives the probability of moving from one representation to the next
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
S. Abnar and W. Zuidema. Quantifying attention flow in transformers. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4190–4197. Association for Computational Linguistics, July 2020
work page 2020
- [2]
- [3]
-
[4]
R. C. Bolles and M. A. Fischler. A ransac-based approach to model fitting and its application to finding cylinders in range data. InIjcai, volume 1981, pages 637–643, 1981
work page 1981
-
[5]
M. Cao, X. Wang, Z. Qi, Y . Shan, X. Qie, and Y . Zheng. Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. InProceedings of the IEEE/CVF international conference on computer vision, pages 22560–22570, 2023
work page 2023
-
[6]
W. Cao, C. Luo, B. Zhang, M. Nießner, and J. Tang. Motion2vecsets: 4d latent vector set diffusion for non-rigid shape reconstruction and tracking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20496–20506, 2024
work page 2024
- [7]
-
[8]
J. Chen, B. Zhang, X. Tang, and P. Wonka. V2m4: 4d mesh animation reconstruction from a single monocular video. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11643–11653, 2025
work page 2025
-
[9]
R. Chen, J. Zhang, Y . Liang, G. Luo, W. Li, J. Liu, X. Li, X. Long, J. Feng, and P. Tan. Dora: Sampling and benchmarking for 3d shape variational auto-encoders. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 16251–16261, June 2025
work page 2025
-
[10]
X. Chen, Y . Chen, Y . Xiu, A. Geiger, and A. Chen. Easi3r: Estimating disentangled motion from dust3r without training. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9158–9168, 2025
work page 2025
-
[11]
S. Cho, J. Huang, J. Nam, H. An, S. Kim, and J.-Y . Lee. Local all-pair correspondence for point tracking. InEuropean conference on computer vision, pages 306–325. Springer, 2024
work page 2024
-
[12]
C. Doersch, A. Gupta, L. Markeeva, A. Recasens, L. Smaira, Y . Aytar, J. Carreira, A. Zisserman, and Y . Yang. Tap-vid: A benchmark for tracking any point in a video.Advances in Neural Information Processing Systems, 35:13610–13626, 2022
work page 2022
-
[13]
C. Doersch, P. Luc, Y . Yang, D. Gokay, S. Koppula, A. Gupta, J. Heyward, I. Rocco, R. Goroshin, J. Carreira, et al. Bootstap: Bootstrapped training for tracking-any-point. InProceedings of the Asian Conference on Computer Vision, pages 3257–3274, 2024
work page 2024
-
[14]
C. Doersch, Y . Yang, M. Vecerik, D. Gokay, A. Gupta, Y . Aytar, J. Carreira, and A. Zisserman. Tapir: Tracking any point with per-frame initialization and temporal refinement. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10061–10072, 2023
work page 2023
-
[15]
N. S. Dutt, S. Muralikrishnan, and N. J. Mitra. Diffusion 3d features (diff3f): Decorating untextured shapes with distilled semantic features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4494–4504, June 2024
work page 2024
-
[16]
Y . Erel, O. Dünkel, R. Dabral, V . Golyanik, C. Theobalt, and A. H. Bermano. Attention (as discrete-time markov) chains. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[17]
H. Feng, J. Zhang, Q. Wang, Y . Ye, P. Yu, M. J. Black, T. Darrell, and A. Kanazawa. St4rtrack: Simultaneous 4d reconstruction and tracking in the world. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8503–8513, 2025
work page 2025
-
[18]
S. Fu, N. Tamir, S. Sundaram, L. Chai, R. Zhang, T. Dekel, and P. Isola. Dreamsim: Learning new dimensions of human visual similarity using synthetic data. InAdvances in Neural Information Processing Systems, volume 36, pages 50742–50768, 2023. 10
work page 2023
-
[19]
Z. Guo, J. Xiang, K. Ma, W. Zhou, H. Li, and R. Zhang. Make-it-animatable: An efficient framework for authoring animation-ready 3d characters. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10783–10792, 2025
work page 2025
-
[20]
A. W. Harley, Z. Fang, and K. Fragkiadaki. Particle video revisited: Tracking through occlusions using point trajectories. InEuropean Conference on Computer Vision, pages 59–75. Springer, 2022
work page 2022
-
[21]
A. W. Harley, Y . You, X. Sun, Y . Zheng, N. Raghuraman, Y . Gu, S. Liang, W.-H. Chu, A. Dave, S. You, et al. Alltracker: Efficient dense point tracking at high resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5253–5262, 2025
work page 2025
-
[22]
Prompt-to-Prompt Image Editing with Cross Attention Control
A. Hertz, R. Mokady, J. Tenenbaum, K. Aberman, Y . Pritch, and D. Cohen-Or. Prompt-to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Y . Hong, K. Zhang, J. Gu, S. Bi, Y . Zhou, D. Liu, F. Liu, K. Sunkavalli, T. Bui, and H. Tan. Lrm: Large reconstruction model for single image to 3d.arXiv preprint arXiv:2311.04400, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
H. Jeong, C.-H. P. Huang, J. C. Ye, N. J. Mitra, and D. Ceylan. Track4gen: Teaching video diffusion models to track points improves video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
- [25]
- [26]
- [27]
-
[28]
L. Jin, R. Tucker, Z. Li, D. Fouhey, N. Snavely, and A. Holynski. Stereo4d: Learning how things move in 3d from internet stereo videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10497–10509, 2025
work page 2025
- [29]
- [30]
- [31]
-
[32]
J. Karhade, N. Keetha, Y . Zhang, T. Gupta, A. Sharma, S. Scherer, and D. Ramanan. Any4d: Unified feed-forward metric 4d reconstruction.arXiv preprint arXiv:2512.10935, 2025
- [33]
-
[34]
M. Kwon, J. Choi, J. Park, S. Jeon, J. Jang, J. Seo, M.-S. Kwak, J.-H. Kim, and S. Kim. Cameo: Correspondence-attention alignment for multi-view diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
work page 2026
- [35]
-
[36]
G. Le Moing, J. Ponce, and C. Schmid. Dense optical tracking: Connecting the dots. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19187–19197, 2024
work page 2024
-
[37]
V . Lepetit, F. Moreno-Noguer, and P. Fua. Epnp: Efficient perspective-n-point camera pose estimation. Int. J. Comput. Vis, 81(2):155–166, 2009
work page 2009
-
[38]
W. Li, J. Liu, H. Yan, R. Chen, Y . Liang, X. Chen, P. Tan, and X. Long. Craftsman3d: High-fidelity mesh generation with 3d native diffusion and interactive geometry refiner. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5307–5317, 2025. 11
work page 2025
- [39]
- [40]
-
[41]
TripoSG: High-Fidelity 3D Shape Synthesis using Large-Scale Rectified Flow Models
Y . Li, Z.-X. Zou, Z. Liu, D. Wang, Y . Liang, Z. Yu, X. Liu, Y .-C. Guo, D. Liang, W. Ouyang, et al. Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models.arXiv preprint arXiv:2502.06608, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Z. Li, Y . Chen, and P. Liu. Dreammesh4d: Video-to-4d generation with sparse-controlled gaussian-mesh hybrid representation.Advances in Neural Information Processing Systems, 37:21377–21400, 2024
work page 2024
-
[43]
Z. Li, R. Tucker, F. Cole, Q. Wang, L. Jin, V . Ye, A. Kanazawa, A. Holynski, and N. Snavely. Megasam: Accurate, fast and robust structure and motion from casual dynamic videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10486–10496, 2025
work page 2025
- [44]
-
[45]
H. Lin, S. Chen, J. H. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
I. Liu, Z. Xu, Y . Wang, H. Tan, Z. Xu, X. Wang, H. Su, and Z. Shi. Riganything: Template-free autoregressive rigging for diverse 3d assets.ACM Transactions on Graphics (TOG), 44(4):1–12, 2025
work page 2025
- [47]
-
[48]
R. Lu, Y . Chen, Y . Liu, J. Tang, J. Ni, D. Wan, G. Zeng, and S. Huang. Taco: Taming diffusion for in-the- wild video amodal completion.Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025
work page 2025
-
[49]
Y . Luo, S. Zhou, Y . Lan, X. Pan, and C. C. Loy. 4rc: 4d reconstruction via conditional querying anytime and anywhere.arXiv preprint arXiv:2602.10094, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
S. Muralikrishnan, N. S. Dutt, and N. J. Mitra. Smf: Template-free and rig-free animation transfer using kinetic codes.ACM Transactions on Graphics (TOG), 44(6), 2025
work page 2025
-
[51]
J. Nam, S. Son, D. Chung, J. Kim, S. Jin, J. Hur, and S. Kim. Emergent temporal correspondences from video diffusion transformers. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[52]
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . B. Huang, S.-W. Li, I. Misra, M. G. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jégou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features w...
work page 2024
-
[53]
A. Pondaven, A. Siarohin, S. Tulyakov, P. Torr, and F. Pizzati. Video motion transfer with diffusion transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[54]
The 2017 DAVIS Challenge on Video Object Segmentation
J. Pont-Tuset, F. Perazzi, S. Caelles, P. Arbeláez, A. Sorkine-Hornung, and L. Van Gool. The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[55]
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InICML, 2021
work page 2021
- [56]
-
[57]
J. Ren, K. Xie, A. Mirzaei, H. Liang, X. Zeng, K. Kreis, Z. Liu, A. Torralba, S. Fidler, S. W. Kim, et al. L4gm: Large 4d gaussian reconstruction model.Advances in Neural Information Processing Systems, 37:56828–56858, 2024. 12
work page 2024
-
[58]
R. Sabathier, N. J. Mitra, and D. Novotny. Lim: Large interpolator model for dynamic reconstruction. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 6154–6164, 2025
work page 2025
-
[59]
R. Sabathier, D. Novotny, N. J. Mitra, and T. Monnier. Actionmesh: Animated 3d mesh generation with temporal 3d diffusion.arXiv preprint arXiv:2601.16148, 2026
- [60]
- [61]
-
[62]
A. Shrivastava, S. Mehta, D. Geng, and A. Owens. Point prompting: Counterfactual tracking with video diffusion models. InInternational Conference on Learning Representations, 2026
work page 2026
-
[63]
Y . Siddiqui, T. Monnier, F. Kokkinos, M. Kariya, Y . Kleiman, E. Garreau, O. Gafni, N. Neverova, A. Vedaldi, R. Shapovalov, et al. Meta 3d assetgen: Text-to-mesh generation with high-quality geometry, texture, and pbr materials.Advances in Neural Information Processing Systems, 37:9532–9564, 2024
work page 2024
-
[64]
C. Song, J. Zhang, X. Li, F. Yang, Y . Chen, Z. Xu, J. H. Liew, X. Guo, F. Liu, J. Feng, et al. Magicarticulate: Make your 3d models articulation-ready. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15998–16007, 2025
work page 2025
-
[65]
O. Sorkine and M. Alexa. As-rigid-as-possible surface modeling. InProceedings of the Fifth Eurographics Symposium on Geometry Processing, 2007
work page 2007
- [66]
-
[67]
R. W. Sumner, J. Schmid, and M. Pauly. Embedded deformation for shape manipulation. InACM siggraph 2007 papers. 2007
work page 2007
-
[68]
J. Tang, Z. Chen, X. Chen, T. Wang, G. Zeng, and Z. Liu. Lgm: Large multi-view gaussian model for high-resolution 3d content creation. InEuropean Conference on Computer Vision, pages 1–18. Springer, 2024
work page 2024
-
[69]
L. Tang, M. Jia, Q. Wang, C. P. Phoo, and B. Hariharan. Emergent correspondence from image diffusion. Advances in neural information processing systems, 36:1363–1389, 2023
work page 2023
-
[70]
T. H. Team. Hunyuan3d 2.5: Towards high-fidelity 3d assets generation with ultimate details, 2025
work page 2025
-
[71]
G. Terzakis and M. Lourakis. A consistently fast and globally optimal solution to the perspective-n-point problem. InEuropean Conference on Computer Vision, pages 478–494. Springer, 2020
work page 2020
- [72]
-
[73]
N. Tumanyan, M. Geyer, S. Bagon, and T. Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1921–1930, June 2023
work page 1921
-
[74]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
work page 2025
-
[75]
Q. Wang, Y .-Y . Chang, R. Cai, Z. Li, B. Hariharan, A. Holynski, and N. Snavely. Tracking everything everywhere all at once. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19795–19806, 2023
work page 2023
-
[76]
Q. Wang, Y . Zhang, A. Holynski, A. A. Efros, and A. Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025
work page 2025
-
[77]
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024. 13
work page 2024
-
[78]
Y . Wang, X. Wang, Z. Chen, Z. Wang, F. Sun, and J. Zhu. Vidu4d: Single generated video to high-fidelity 4d reconstruction with dynamic gaussian surfels.Advances in Neural Information Processing Systems, 37:131316–131343, 2024
work page 2024
-
[79]
R. Wu, R. Gao, B. Poole, A. Trevithick, C. Zheng, J. T. Barron, and A. Holynski. Cat4d: Create anything in 4d with multi-view video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26057–26068, 2025
work page 2025
-
[80]
Z. Wu, C. Yu, Y . Jiang, C. Cao, F. Wang, and X. Bai. Sc4d: Sparse-controlled video-to-4d generation and motion transfer. InEuropean Conference on Computer Vision, pages 361–379. Springer, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.