Chunking German Legal Code
Pith reviewed 2026-05-20 06:27 UTC · model grok-4.3
The pith
Chunking German legal texts by their natural sections and subsections yields the best recall in retrieval systems compared to more elaborate methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Chunking strategies aligned with the inherent legal structure, particularly section and subsection based retrieval, achieve the highest recall on a legal question-answering dataset with section-level gold labels, while more complex approaches that override this structure perform worse and incur higher computational costs.
What carries the argument
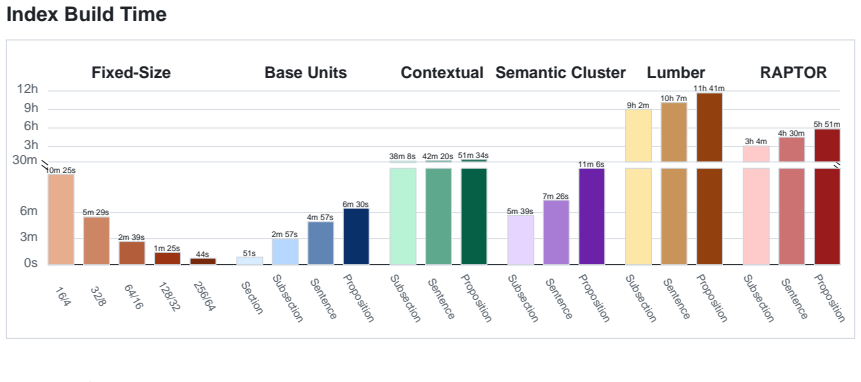
Direct comparison of segmentation approaches including structural units, fixed-size windows, contextual chunking, semantic clustering, Lumber-style chunking, and RAPTOR hierarchical retrieval, measured by recall against section-level gold labels along with latency, index build time, and storage.
If this is right
- Structural chunking by sections and subsections delivers higher recall than semantic or hierarchical overrides.
- Simpler structure-preserving methods reduce query latency, index build time, and storage needs relative to LLM-intensive techniques.
- Preserving the native hierarchy of statutory texts improves retrieval effectiveness in legal domains.
- A trade-off exists in which added semantic processing raises cost without corresponding gains in recall for this corpus.
Where Pith is reading between the lines
- Legal retrieval tasks may favor native textual hierarchy over general-purpose chunking algorithms used in other domains.
- The same structural preference could apply to other highly organized regulatory or technical documents.
- Practical systems might default to section-level chunking before adopting more expensive semantic enrichment steps.
Load-bearing premise
A question-answering dataset with section-level gold labels serves as an adequate stand-in for real-world legal retrieval success without additional checks for precision or user satisfaction.
What would settle it
An experiment in which RAPTOR or another complex method produces measurably higher recall than section-based chunking on the same German Civil Code dataset or a comparable legal corpus.
Figures




read the original abstract
This paper investigates chunking strategies for retrieval-augmented generation on German statutory law, using the German Civil Code as a structured benchmark corpus. We implement and compare a range of segmentation approaches, including structural units (sections, subsections, sentences, propositions), fixed-size windows, contextual chunking, semantic clustering, Lumber-style chunking, and RAPTOR-based hierarchical retrieval. All methods are evaluated on a legal question-answering dataset with section-level gold labels, measuring recall, query latency, index build time, and storage requirements. Results show that chunking strategies aligned with the inherent legal structure - particularly section and subsection - based retrieval-achieve the highest recall, while more complex approaches that override this structure perform worse. These simpler methods also offer favorable computational efficiency compared to LLM-intensive techniques such as contextual chunking, RAPTOR, and Lumber. The findings highlight a key trade-off between semantic enrichment and operational cost, and demonstrate that preserving domain-specific structure is critical for effective legal information retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically compares multiple chunking strategies for retrieval-augmented generation on the German Civil Code as a structured legal corpus. Methods evaluated include structural segmentation (sections, subsections, sentences, propositions), fixed-size windows, contextual chunking, semantic clustering, Lumber-style chunking, and RAPTOR hierarchical retrieval. All are tested on a legal question-answering dataset with section-level gold labels, reporting recall, query latency, index build time, and storage. The central claim is that chunking aligned with the document's inherent legal structure (particularly sections and subsections) yields the highest recall and favorable efficiency, while more complex overrides of this structure underperform.
Significance. If the results hold after addressing evaluation concerns, the work offers practical value for legal-domain RAG systems by demonstrating that preserving statutory structure can outperform LLM-intensive semantic methods while reducing computational overhead. The systematic benchmarking across a range of approaches, including less common ones like Lumber and RAPTOR, on a real statutory text provides a useful reference point for practitioners balancing retrieval quality and cost.
major comments (1)
- [Evaluation and Results] The evaluation measures recall against section-level gold labels in the QA dataset. This creates a potential alignment artifact: methods that retrieve whole sections or subsections receive direct matches by construction, whereas sentence-level, proposition-level, semantic, RAPTOR, or Lumber chunks must either be mapped back or fail to align with the exact gold unit. This setup is load-bearing for the central claim that structural chunking is superior for legal retrieval, and the manuscript should report complementary metrics such as precision, answer coverage, or end-to-end QA accuracy to rule out the confound.
minor comments (1)
- [Abstract and Experiments] The abstract and results summary omit key experimental details such as the number of questions in the QA dataset, embedding model choices, prompt templates for LLM-based chunking methods, and any statistical tests on recall differences. Adding these would improve reproducibility without altering the core claims.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for highlighting an important aspect of our evaluation design. We address the major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation and Results] The evaluation measures recall against section-level gold labels in the QA dataset. This creates a potential alignment artifact: methods that retrieve whole sections or subsections receive direct matches by construction, whereas sentence-level, proposition-level, semantic, RAPTOR, or Lumber chunks must either be mapped back or fail to align with the exact gold unit. This setup is load-bearing for the central claim that structural chunking is superior for legal retrieval, and the manuscript should report complementary metrics such as precision, answer coverage, or end-to-end QA accuracy to rule out the confound.
Authors: We acknowledge the referee's concern about a possible alignment artifact arising from section-level gold labels. Our choice of this metric is grounded in the domain: statutory law QA typically requires retrieving the exact legal provision (section or subsection) that contains the answer, as this is the unit legal practitioners consult and cite. In our implementation, finer-grained methods (sentences, propositions, semantic clusters, RAPTOR, Lumber) were mapped back to their containing sections for fair comparison, and we report recall at the section level to reflect real-world utility. That said, we agree that complementary metrics would make the results more robust. In the revised manuscript we will add precision@5, answer coverage (fraction of gold sections covered by retrieved chunks), and an end-to-end QA accuracy evaluation in which retrieved chunks are fed to an LLM to generate answers that are then judged against gold answers. These additions will help isolate any confound and further support the central claim. revision: yes
Circularity Check
No circularity detected in empirical chunking comparison
full rationale
The paper conducts a direct empirical comparison of multiple chunking strategies evaluated via recall (and other metrics) against an external legal QA dataset that supplies section-level gold labels. No mathematical derivations, equations, fitted parameters, or self-referential predictions appear in the abstract or described methodology. Results are reported as measured experimental outcomes rather than any reduction to inputs by construction. The analysis therefore remains self-contained with no load-bearing steps that collapse to self-definition, self-citation chains, or renamed known results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The German Civil Code constitutes a structured benchmark corpus suitable for testing legal chunking strategies.
Reference graph
Works this paper leans on
-
[1]
Generative AI in Professional Services Report, Technical Report, Thomson Reuters Institute, 2025. URL: https://www.thomsonreuters.com/content/dam/ewp-m/documents/thomsonreuters/en/pdf/ reports/2025-generative-ai-in-professional-services-report-tr5433489-rgb.pdf
work page 2025
-
[2]
Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, M. Wang, H. Wang, Retrieval-augmented generation for large language models: A survey, 2024. URL: https://arxiv.org/abs/2312.10997. arXiv:2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, P. Liang, Lost in the middle: How language models use long contexts, Transactions of the Association for Computational Linguistics 12 (2024) 157–173. doi:10.1162/tacl_a_00638
-
[4]
M. Büttner, I. Habernal, Answering legal questions from laymen in German civil law system, in: Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 2015–2027. doi:10.18653/v1/2024.eacl-long. 122
-
[5]
L. James, AI data centers are swallowing the world’s memory and storage supply, setting the stage for a pricing apocalypse that could last a decade, https://www.tomshardware.com/pc-components/ storage/perfect-storm-of-demand-and-supply-driving-up-storage-costs, 2025. Accessed: 2026-04- 23
work page 2025
-
[6]
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, S. Riedel, D. Kiela, Retrieval-augmented generation for knowledge-intensive nlp tasks, in: Advances in Neural Information Processing Systems, volume 33, Curran Asso- ciates, Inc., 2020, pp. 9459–9474. URL: https://proceedings.neurips.cc/pape...
work page 2020
- [7]
-
[8]
T. Chen, H. Wang, S. Chen, W. Yu, K. Ma, X. Zhao, H. Zhang, D. Yu, Dense X retrieval: What retrieval granularity should we use?, in: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Miami, Florida, USA, 2024, pp. 15159–15177. doi:10.18653/v1/2024.emnlp-main.845
-
[9]
Y. Liu, K. Hashimoto, Y. Zhou, S. Yavuz, C. Xiong, P. Yu, Dense hierarchical retrieval for open- domain question answering, in: Findings of the Association for Computational Linguistics: EMNLP 2021, Association for Computational Linguistics, 2021, pp. 188–200. doi:10.18653/v1/ 2021.findings-emnlp.19
-
[10]
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
P. Sarthi, S. Abdullah, A. Tuli, S. Khanna, A. Goldie, C. D. Manning, Raptor: Recursive abstractive processing for tree-organized retrieval, 2024. URL: https://arxiv.org/abs/2401.18059
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Anthropic, Contextual retrieval, https://www.anthropic.com/engineering/contextual-retrieval,
-
[12]
Accessed: 2026-04-08
work page 2026
-
[13]
J. A. Hartigan, M. A. Wong, A k-means clustering algorithm, Journal of the Royal Statistical Society: Series C (Applied Statistics) 28 (1979) 100–108. doi:10.2307/2346830
-
[14]
Journal of the American Statistical Association 32, 675- 701,10.1080/01621459.1937.10503522
M. Friedman, The use of ranks to avoid the assumption of normality implicit in the analysis of variance, Journal of the American Statistical Association 32 (1937) 675–701. doi: 10.1080/ 01621459.1937.10503522
-
[15]
A simple sequentially rejective multiple test procedure,
S. Holm, A simple sequentially rejective multiple test procedure, Scandinavian Journal of Statistics 6 (1979) 65–70. URL: http://www.jstor.org/stable/4615733
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.