OpenHealth Lake: Designing and testing a data lakehouse platform for health applications
Pith reviewed 2026-05-20 03:40 UTC · model grok-4.3
The pith
OpenHealth Lake prototype delivers a usable data lakehouse for health data sharing across technical skill levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OpenHealth Lake is a data management prototype platform based on a data lakehouse architecture, data federation, and the FAIR principles. Designed using open-source tools and guided by identified system requirements, it comprises a user-friendly website, an open API, and Python and R packages. A user study confirmed its usability and usefulness for participants with varying technical backgrounds, showcasing adaptability, scalability, and reproducibility for any organization.
What carries the argument
OpenHealth Lake prototype, which integrates data lakehouse architecture, data federation, and FAIR principles to support secure storage, sharing, and governance of heterogeneous health datasets through multiple access methods.
If this is right
- The platform enables efficient data exchange and governance within collaborative global health initiatives.
- Users with varying technical backgrounds can interact via website, API, or Python and R packages.
- Organizations can customize the system to match their specific requirements and resources including cloud or self-hosted storage.
- The lakehouse design supports adaptability, scalability, and reproducibility across different health data settings.
Where Pith is reading between the lines
- Similar lakehouse patterns could be tested in other data-heavy domains such as environmental monitoring or genomics consortia.
- Adding built-in analytics layers might let teams move directly from storage to insight without external tools.
- Long-term monitoring of adoption rates in actual projects would reveal whether the prototype sustains use beyond initial testing.
Load-bearing premise
The system requirements identified in previously published studies and complemented by insights from the existing literature are sufficient and accurate to guide the design of a platform that meets the needs of collaborative global health initiatives.
What would settle it
A follow-up deployment in a real global health collaboration where users report persistent difficulties with data exchange or governance would show the requirements were insufficient.
Figures








read the original abstract
Data management can be a complex challenge in fields such as bioinformatics and health sciences, which continuously generate extensive heterogeneous datasets. In the context of collaborative global health initiatives, secure storage and sharing of data are crucial to support impactful research. However, the absence of a unified data management platform complicates efficient data exchange and governance within these initiatives. In this paper, we introduce the design process of OpenHealth Lake, a data management prototype platform based on a data lakehouse architecture, data federation, and the FAIR principles. The platform is designed using open-source tools, guided by system requirements identified in previously published studies and complemented by insights from the existing literature. The current prototype platform comprises a user-friendly website, an open API, Python and R packages, allowing users to interact with the platform in multiple ways. Through a user study that included participants with varying technical backgrounds, we showed that our proposed data management prototype is both usable and useful. Our prototype design showcases the adaptability, scalability, and reproducibility of a lakehouse system that can be used by any organisation. It is designed as a flexible and complementary approach that allows organisations to customise data management systems to their specific requirements and resources, including cloud-based or self-hosted storage choices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the design process and prototype implementation of OpenHealth Lake, a data lakehouse platform for health applications in collaborative global health initiatives. It is constructed using open-source tools following a data lakehouse architecture with data federation and FAIR principles, guided by system requirements from prior published studies supplemented by literature insights. The prototype includes a user-friendly website, an open API, and Python and R packages. A user study with participants of varying technical backgrounds is reported to demonstrate that the platform is both usable and useful, with claims of adaptability, scalability, and reproducibility for organizational customization including cloud or self-hosted options.
Significance. If the user study and requirement validation provide robust, detailed evidence, the work could offer a practical contribution by demonstrating a flexible, open-source lakehouse approach tailored to heterogeneous health data management and governance needs. It explicitly credits the use of established open-source components and multi-language access methods, which supports reproducibility and adoption. However, the current lack of concrete evaluation details limits assessment of whether it meaningfully advances beyond existing data lakehouse applications in the health domain.
major comments (2)
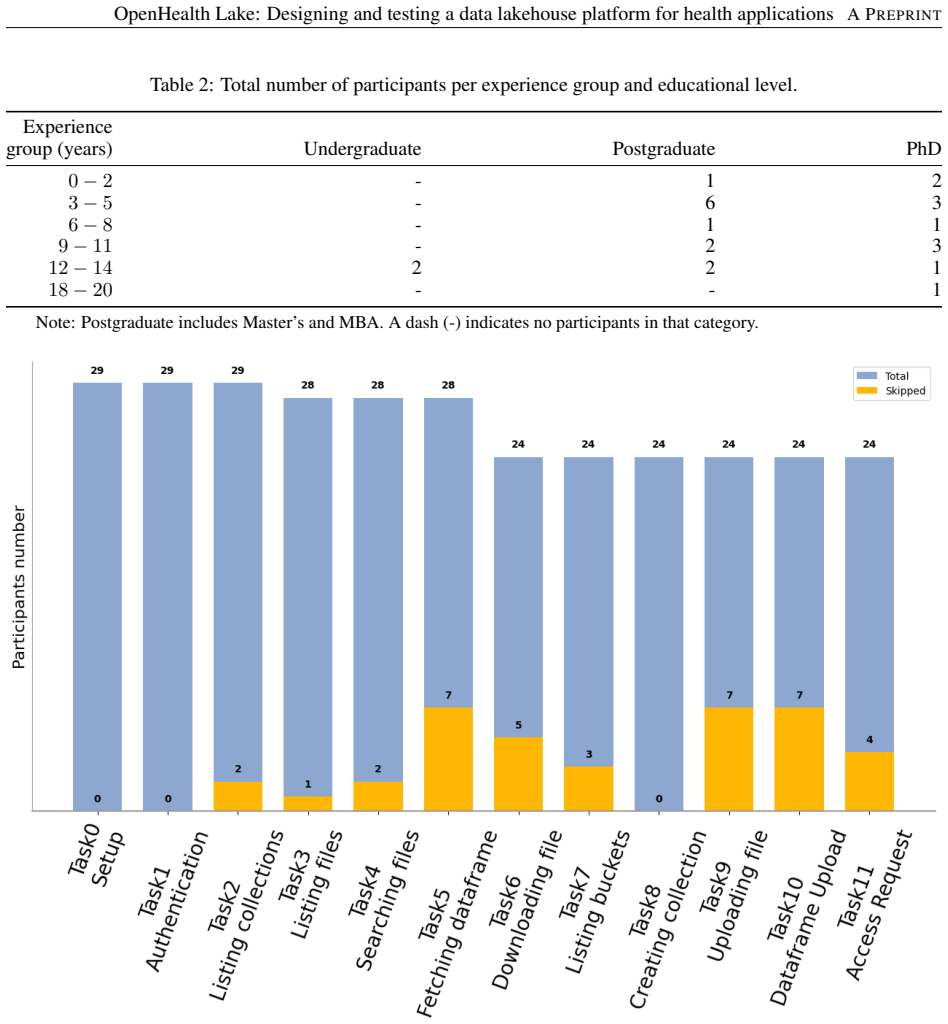
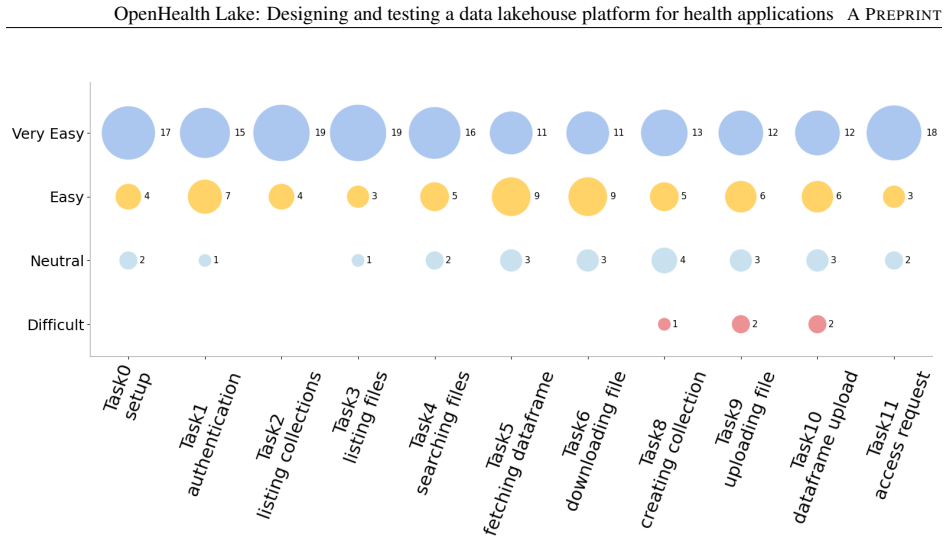
- User Study section: the central claim that the prototype is usable and useful rests on this study, yet no details are provided on participant count, recruitment, specific tasks or scenarios tested (e.g., data sharing workflows or privacy controls), metrics (such as SUS scores or completion rates), or any statistical analysis. This absence prevents evaluation of the evidence strength and leaves the headline result unsupported in its current form.
- Design Process section: system requirements are stated to derive from previously published studies and literature, but there is no explicit mapping (e.g., table or subsection) linking each requirement to corresponding prototype features, nor any validation step testing the resulting platform against fresh domain-specific scenarios such as cross-border governance or multi-stakeholder privacy constraints. Without this, the design choices cannot be confirmed as sufficient for the targeted collaborative global health use cases.
minor comments (1)
- Abstract: key quantitative or qualitative outcomes from the user study (e.g., average ratings or main feedback themes) are omitted, which would strengthen the summary of results.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights opportunities to strengthen the presentation of our user study and design validation. We will revise the manuscript accordingly to provide greater transparency and evidence for our claims.
read point-by-point responses
-
Referee: User Study section: the central claim that the prototype is usable and useful rests on this study, yet no details are provided on participant count, recruitment, specific tasks or scenarios tested (e.g., data sharing workflows or privacy controls), metrics (such as SUS scores or completion rates), or any statistical analysis. This absence prevents evaluation of the evidence strength and leaves the headline result unsupported in its current form.
Authors: We agree that additional methodological details are needed to allow readers to assess the strength of the usability claims. In the revised manuscript, we will expand the User Study section to report the exact participant count, recruitment approach (via targeted invitations to health informatics and global health networks), the specific tasks and scenarios evaluated (including data ingestion, federated querying, sharing workflows, and privacy control interactions), the quantitative metrics collected (System Usability Scale scores, task completion rates, and time-on-task), and the statistical methods applied to the results. These additions will directly support the claims of usability and usefulness while maintaining the original study design. revision: yes
-
Referee: Design Process section: system requirements are stated to derive from previously published studies and literature, but there is no explicit mapping (e.g., table or subsection) linking each requirement to corresponding prototype features, nor any validation step testing the resulting platform against fresh domain-specific scenarios such as cross-border governance or multi-stakeholder privacy constraints. Without this, the design choices cannot be confirmed as sufficient for the targeted collaborative global health use cases.
Authors: We accept that an explicit traceability between requirements and features would improve the rigor of the design narrative. The revised Design Process section will include a new table (or dedicated subsection) that maps each stated requirement to the corresponding OpenHealth Lake features (e.g., data federation for cross-border access, FAIR-compliant metadata for governance). We will also add a short validation discussion that illustrates how the implemented architecture addresses representative scenarios such as multi-stakeholder privacy constraints and cross-border data governance, leveraging the existing data lakehouse and federation components. This will demonstrate sufficiency for the intended use cases without altering the core design. revision: yes
Circularity Check
No significant circularity; evaluation rests on independent user study
full rationale
The paper describes a design process for OpenHealth Lake guided by requirements drawn from previously published studies plus literature, then evaluates the resulting prototype via a separate user study with participants of varying technical backgrounds. The central claim (usability and usefulness) is supported by this external user-study feedback rather than by any self-referential fitting, redefinition, or reduction of the evaluation metrics to the design inputs. No equations, fitted parameters, or uniqueness theorems appear; self-citations of prior requirements work do not bear the load of the reported results, which remain independently testable. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Data management can be a complex challenge in fields such as bioinformatics and health sciences, which continuously generate extensive heterogeneous datasets.
- domain assumption The absence of a unified data management platform complicates efficient data exchange and governance within collaborative global health initiatives.
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
-
[4]
International Journal of Information Technology , pages=
A systematic review of software usability studies , author=. International Journal of Information Technology , pages=. 2017 , publisher=
work page 2017
-
[5]
Haas, L. M. and Lin, E. T. and Roth, M. A. , journal=. Data integration through database federation , year=
-
[6]
BioMart: a data federation framework for large collaborative projects , author=. Database , volume=. 2011 , publisher=
work page 2011
-
[7]
The R language: an engine for bioinformatics and data science , author=. Life , volume=. 2022 , publisher=
work page 2022
- [8]
- [9]
- [10]
-
[11]
and Zulkernine, Farhana , booktitle=
Harby, Ahmed A. and Zulkernine, Farhana , booktitle=. From Data Warehouse to Lakehouse: A Comparative Review , year=
-
[12]
Lakehouse: a new generation of open platforms that unify data warehousing and advanced analytics , author=. Proceedings of CIDR , volume=
- [13]
- [14]
-
[15]
The lakehouse: State of the art on concepts and technologies , author=. SN Computer Science , volume=. 2024 , publisher=
work page 2024
-
[16]
Proceedings of the 34th GI-Workshop on Foundations of Databases , year=
The Data Platform Evolution: From Data Warehouses over Data Lakes to Lakehouses , author=. Proceedings of the 34th GI-Workshop on Foundations of Databases , year=
-
[17]
Scientific Data, 3 (1), Article 160018 , author=
The FAIR guiding principles for scientific data management and stewardship. Scientific Data, 3 (1), Article 160018 , author=
-
[18]
Journal of biomedical informatics , volume=
‘Big data’, Hadoop and cloud computing in genomics , author=. Journal of biomedical informatics , volume=. 2013 , publisher=
work page 2013
-
[19]
South African journal of science , volume=
Managing and assembling population-scale data streams, tools and workflows to plan for future pandemics within the INFORM-Africa Consortium , author=. South African journal of science , volume=
-
[20]
Journal of Data, Information and Management , volume=
The evolution of data storage architectures: examining the secure value of the Data Lakehouse , author=. Journal of Data, Information and Management , volume=. 2024 , publisher=
work page 2024
-
[21]
International Conference on Big Data Analytics and Knowledge Discovery , pages=
Benchmarking data lakes featuring structured and unstructured data with dlbench , author=. International Conference on Big Data Analytics and Knowledge Discovery , pages=. 2021 , organization=
work page 2021
-
[22]
Bioinformatics Advances , volume =
Silva, Danilo and Moir, Monika and Dunaiski, Marcel and Blanco, Natalia and Murtala-Ibrahim, Fati and Baxter, Cheryl and de Oliveira, Tulio and Xavier, Joicymara S and The INFORM Africa Research Study Group , title =. Bioinformatics Advances , volume =
-
[23]
Introducing the FAIR Principles for research software , author=. Scientific Data , volume=. 2022 , publisher=
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.