GROW: Aligning GRPO with State-Action Modeling for Open-World VLM Agents
Pith reviewed 2026-05-22 09:02 UTC · model grok-4.3
The pith
GROW adapts GRPO for multi-turn VLM agents by decomposing trajectories into state-action samples for advantage computation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
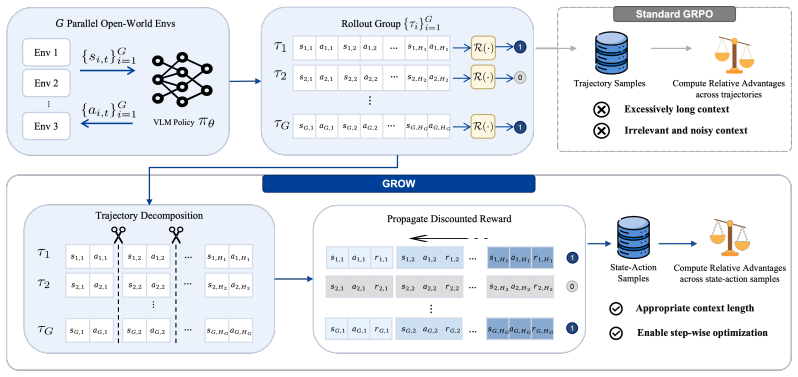
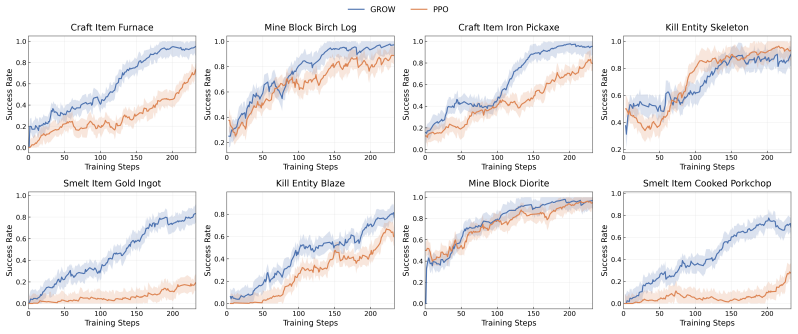
GROW decomposes collected trajectories into state-action samples and computes advantages between these samples rather than treating a full trajectory as a single entity. A surrogate analysis indicates that even though the grouped samples are conditioned on different local states rather than an identical prompt context, the objective can preserve the core relative policy optimization signal of GRPO under simplifying assumptions. Experiments on more than 800 Minecraft tasks show that this framework achieves state-of-the-art performance for open-world VLM agents.
What carries the argument
Decomposition of full trajectories into state-action samples followed by inter-sample advantage computation, which aligns the GRPO objective with state-action modeling for multi-turn agents.
Load-bearing premise
That samples drawn from different local states can still carry the same relative policy optimization signal as samples sharing an identical prompt context, provided the paper's simplifying assumptions remain valid.
What would settle it
An experiment that applies GROW to a long-horizon task where the local states differ substantially from any shared prompt context and measures whether the learned policy diverges from what standard GRPO would produce or loses its reported performance gains.
Figures




read the original abstract
Recently, vision-language model (VLM) agents have shown promising progress in open-world tasks, where successful task completion often requires multiple turns of visual perception and action execution. However, existing methods still rely primarily on Supervised Fine-Tuning (SFT) with expert demonstrations, while the advanced reinforcement learning (RL) algorithm, specifically Group Relative Policy Optimization (GRPO), has not been effectively employed for multi-turn RL in these tasks because standard GRPO requires full trajectories as training samples which leads to excessively long context and noise. To address this issue, we propose GROW, a RL framework for open-world VLM agents that decomposes collected trajectories into state-action samples, and computes advantages between these samples rather than treating a full trajectory as a single entity. We further provide a surrogate analysis indicating that, even though the grouped samples are conditioned on different local states rather than an identical prompt context, the objective can preserve the core relative policy optimization signal of GRPO under simplifying assumptions. Experiments on more than 800 Minecraft tasks show that our method achieves state-of-the-art (SOTA) performance, demonstrating the effectiveness of our proposed RL framework for open-world VLM agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents GROW, a reinforcement learning framework for vision-language model (VLM) agents in open-world tasks such as Minecraft. It modifies Group Relative Policy Optimization (GRPO) by decomposing full trajectories into state-action samples and computing advantages across these samples rather than treating entire trajectories as single entities. This is intended to avoid excessively long contexts and noise. A surrogate analysis argues that the modified objective preserves the core relative policy optimization signal of GRPO under simplifying assumptions even when samples are conditioned on different local states. Experiments report state-of-the-art performance on more than 800 Minecraft tasks.
Significance. If the surrogate analysis is valid and the performance gains are robust, the work offers a practical route to applying relative policy optimization methods to multi-turn VLM agents, potentially improving sample efficiency and stability in long-horizon open-world settings by reducing reliance on full-trajectory training.
major comments (2)
- [Surrogate Analysis] Surrogate Analysis section: The claim that the objective preserves the core GRPO relative policy optimization signal rests on simplifying assumptions (identical prompt context replaced by different local states plus bounded variance in advantage estimates). In open-world Minecraft, where visual states differ sharply across steps, it is unclear whether the advantage estimator maintains the original relative ranking property; the manuscript does not provide a derivation showing invariance or empirical checks that the signal is recovered outside the assumed regime. This is load-bearing for the theoretical justification of the central method.
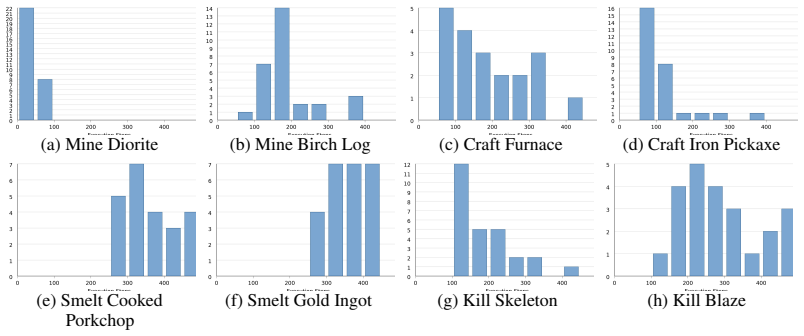
- [Experiments] Experiments section: The SOTA claim on more than 800 tasks is presented without quantitative details on baseline methods, exact success-rate metrics, number of independent runs, or statistical significance tests. Without these, it is difficult to assess whether the reported gains are attributable to the state-action decomposition or to other factors such as task selection or implementation details.
minor comments (2)
- [Abstract] Abstract: The phrase 'surrogate analysis' is used without a one-sentence qualifier on the nature of the assumptions; adding this would improve readability for readers unfamiliar with the GRPO derivation.
- [Preliminaries] Notation: Define the state-action decomposition operator and the cross-sample advantage estimator explicitly in the preliminaries to ensure consistent interpretation across the method and analysis sections.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of the surrogate analysis and experimental reporting that we address point by point below. We have prepared revisions to strengthen the theoretical justification and provide the requested quantitative details.
read point-by-point responses
-
Referee: [Surrogate Analysis] Surrogate Analysis section: The claim that the objective preserves the core GRPO relative policy optimization signal rests on simplifying assumptions (identical prompt context replaced by different local states plus bounded variance in advantage estimates). In open-world Minecraft, where visual states differ sharply across steps, it is unclear whether the advantage estimator maintains the original relative ranking property; the manuscript does not provide a derivation showing invariance or empirical checks that the signal is recovered outside the assumed regime. This is load-bearing for the theoretical justification of the central method.
Authors: We agree that the surrogate analysis relies on simplifying assumptions and that additional support is needed to establish robustness outside this regime. In the original manuscript we show that, under the stated assumptions of bounded advantage variance and local-state conditioning, the relative ordering of advantages is preserved because the group-wise normalization remains monotonic with respect to the original GRPO signal. To address the referee’s concern, we will expand the appendix with a more explicit step-by-step derivation of the invariance property and add empirical checks that compare advantage rankings obtained from full-trajectory GRPO versus our state-action decomposition on a held-out subset of Minecraft tasks. These additions will clarify the conditions under which the core relative policy optimization signal is retained. revision: yes
-
Referee: [Experiments] Experiments section: The SOTA claim on more than 800 tasks is presented without quantitative details on baseline methods, exact success-rate metrics, number of independent runs, or statistical significance tests. Without these, it is difficult to assess whether the reported gains are attributable to the state-action decomposition or to other factors such as task selection or implementation details.
Authors: The referee correctly notes that the current experimental section lacks the quantitative details necessary for rigorous evaluation. In the revised manuscript we will add comprehensive tables that report per-task success rates for GROW and all baselines, the exact number of independent runs (five random seeds), and the results of statistical significance tests (paired t-tests with p-values). We will also include an ablation isolating the contribution of the state-action decomposition from other implementation choices. These changes will make the source of the reported gains transparent. revision: yes
Circularity Check
No significant circularity; surrogate analysis is an independent derivation under stated assumptions
full rationale
The paper's core contribution is a decomposition of trajectories into state-action pairs for advantage computation, followed by a surrogate analysis that derives preservation of the GRPO relative signal under explicit simplifying assumptions (different local states replacing identical prompt context). This analysis does not reduce the objective to its inputs by construction, nor does it rely on self-citation chains, fitted parameters renamed as predictions, or smuggled ansatzes. The derivation remains self-contained because the surrogate step is a separate mathematical argument whose validity can be checked against the stated assumptions without looping back to the empirical results or prior author work as load-bearing justification. No equations or sections exhibit the specific reductions required for circularity flags.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Even though grouped samples are conditioned on different local states rather than an identical prompt context, the objective preserves the core relative policy optimization signal of GRPO under simplifying assumptions.
Reference graph
Works this paper leans on
-
[1]
Qihang Ai, Pi Bu, Yue Cao, Yingyao Wang, Jihao Gu, Jingxuan Xing, Zekun Zhu, Wei Jiang, Zhicheng Zheng, Jun Song, Yuning Jiang, and Bo Zheng. Inquiremobile: Teaching vlm-based mobile agent to request human assistance via reinforcement fine-tuning.CoRR, abs/2508.19679, August 2025. URLhttps://doi.org/10.48550/arXiv.2508.19679
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.19679 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,
-
[3]
URLhttps://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Bowen Baker, Ilge Akkaya, Peter Zhokov, Joost Huizinga, Jie Tang, Adrien Ecoffet, Brandon Houghton, Raul Sampedro, and Jeff Clune. Video pretraining (vpt): Learning to act by watching unlabeled online videos.Advances in Neural Information Processing Systems, 35:24639–24654, 2022
work page 2022
-
[5]
Shaofei Cai, Zhancun Mu, Haiwen Xia, Bowei Zhang, Anji Liu, and Yitao Liang. Scalable multi-task reinforcement learning for generalizable spatial intelligence in visuomotor agents. arXiv preprint arXiv:2507.23698, 2025
-
[6]
Freeman, Frédo Durand, Eli Shechtman, and Xun Huang
Shaofei Cai, Zihao Wang, Kewei Lian, Zhancun Mu, Xiaojian Ma, Anji Liu, and Yitao Liang. Rocket-1: Mastering open-world interaction with visual-temporal context prompting. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12122– 12131, 2025. doi: 10.1109/CVPR52734.2025.01132
-
[7]
Rocket-1: Mastering open-world interaction with visual-temporal context prompting
Shaofei Cai, Zihao Wang, Kewei Lian, Zhancun Mu, Xiaojian Ma, Anji Liu, and Yitao Liang. Rocket-1: Mastering open-world interaction with visual-temporal context prompting. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 12122–12131, 2025
work page 2025
-
[8]
Liu, Ram Vasudevan, and Maani Ghaffari
Yue Hu, Avery Xi, Qixin Xiao, Seth Isaacson, Henry X. Liu, Ram Vasudevan, and Maani Ghaffari. Longnav-r1: Horizon-adaptive multi-turn rl for long-horizon vla navigation, 2026. URLhttps://arxiv.org/abs/2602.12351
-
[9]
Compassnav: Steering from path imitation to decision understanding in navigation
LinFeng Li, Jian Zhao, Yuan Xie, Xin Tan, and Xuelong Li. Compassnav: Steering from path imitation to decision understanding in navigation. InThe F ourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=eqcDckWHik
work page 2026
-
[10]
Muyao Li, Zihao Wang, Kaichen He, Xiaojian Ma, and Yitao Liang. JARVIS-VLA: Post- training large-scale vision language models to play visual games with keyboards and mouse. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Findings of the Association for Computational Linguistics: ACL 2025, pages 17878–17899, Vienna,...
-
[11]
Coloragent: Building a robust, personalized, and interactive os agent, 2025
Ning Li, Qiqiang Lin, Zheng Wu, Xiaoyun Mo, Weiming Zhang, Yin Zhao, Xiangmou Qu, Jiamu Zhou, Jun Wang, Congmin Zheng, Yuanyi Song, Hongjiang Chen, Heyuan Huang, Jihong Wang, Jiaxin Yin, Jingwei Yu, Junwei Liao, Qiuying Peng, Xingyu Lou, Jun Wang, Weiwen Liu, Zhuosheng Zhang, and Weinan Zhang. Coloragent: Building a robust, personalized, and interactive o...
-
[12]
Shalev Lifshitz, Keiran Paster, Harris Chan, Jimmy Ba, and Sheila McIlraith. Steve-1: A generative model for text-to-behavior in minecraft.Advances in Neural Information Processing Systems, 36:69900–69929, 2023
work page 2023
-
[13]
Mcu: A task-centric framework for open-ended agent evaluation in minecraft
Haowei Lin, Zihao Wang, Jianzhu Ma, and Yitao Liang. Mcu: A task-centric framework for open-ended agent evaluation in minecraft.arXiv preprint arXiv:2310.08367, 2023
-
[14]
NaviMaster: Learning a Unified Policy for GUI and Embodied Navigation Tasks
Zhihao Luo, Wentao Yan, Jingyu Gong, Min Wang, Zhizhong Zhang, Xuhong Wang, Yuan Xie, and Xin Tan. Navimaster: Learning a unified policy for gui and embodied navigation tasks. arXiv preprint arXiv:2508.02046, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Interactive language: Talking to robots in real time,
Corey Lynch, Ayzaan Wahid, Jonathan Tompson, Tianli Ding, James Betker, Robert Baruch, Travis Armstrong, and Pete Florence. Interactive language: Talking to robots in real time, 2022. URLhttps://arxiv.org/abs/2210.06407
-
[16]
Nitrogen: An open foundation model for generalist gaming agents,
Loïc Magne, Anas Awadalla, Guanzhi Wang, Yinzhen Xu, Joshua Belofsky, Fengyuan Hu, Joohwan Kim, Ludwig Schmidt, Georgia Gkioxari, Jan Kautz, Yisong Yue, Yejin Choi, Yuke Zhu, and Linxi "Jim" Fan. Nitrogen: An open foundation model for generalist gaming agents,
- [17]
-
[18]
Gameworld: Towards standardized and verifiable evaluation of multimodal game agents, 2026
Mingyu Ouyang, Siyuan Hu, Kevin Qinghong Lin, Hwee Tou Ng, and Mike Zheng Shou. Gameworld: Towards standardized and verifiable evaluation of multimodal game agents, 2026. URLhttps://api.semanticscholar.org/CorpusID:287255688
work page 2026
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Yucheng Shi, Wenhao Yu, Zaitang Li, Yonglin Wang, Hongming Zhang, Ninghao Liu, Haitao Mi, and Dong Yu. Mobilegui-rl: Advancing mobile gui agent through reinforcement learning in online environment, 2025. URLhttps://arxiv.org/abs/2507.05720
-
[22]
Weihao Tan, Xiangyang Li, Yunhao Fang, Heyuan Yao, Shi Yan, Hao Luo, Tenglong Ao, Huihui Li, Hongbin Ren, Bairen Yi, Yujia Qin, Bo An, Libin Liu, and Guang Shi. Lumine: An open recipe for building generalist agents in 3d open worlds, 2025. URL https://arxiv.org/ abs/2511.08892
-
[23]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution, 2024. URLhttps://arxiv.org/ abs/2409.12191
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Zihao Wang, Muyao Li, Kaichen He, Xiangyu Wang, Zhancun Mu, Anji Liu, and Yitao Liang. Openha: A series of open-source hierarchical agentic models in minecraft.arXiv preprint arXiv:2509.13347, 2025
-
[25]
Zihao Wang, Xujing Li, Yining Ye, Junjie Fang, Haoming Wang, Longxiang Liu, Shihao Liang, Junting Lu, Zhiyong Wu, Jiazhan Feng, et al. Game-tars: Pretrained foundation models for scalable generalist multimodal game agents.arXiv preprint arXiv:2510.23691, 2025
-
[26]
Agentgym: Evaluating and training large language model-based agents across diverse environments
Zhiheng Xi, Yiwen Ding, Wenxiang Chen, Boyang Hong, Honglin Guo, Junzhe Wang, Xin Guo, Dingwen Yang, Chenyang Liao, Wei He, Songyang Gao, Luyao Chen, Rui Zheng, Yicheng Zou, Tao Gui, Qi Zhang, Xipeng Qiu, Xuanjing Huang, Zuxuan Wu, and Yu-Gang Jiang. Agentgym: Evaluating and training large language model-based agents across diverse environments. InAnnual ...
work page 2025
-
[27]
Shuhao Ye, Sitong Mao, Yuxiang Cui, Xuan Yu, Shichao Zhai, Wen Chen, Shunbo Zhou, Rong Xiong, and Yue Wang. Etp-r1: Evolving topological planning with reinforcement fine-tuning for vision-language navigation in continuous environments, 2025. URL https: //arxiv.org/abs/2512.20940
-
[28]
Hanchen Zhang, Xiao Liu, Bowen Lv, Xueqiao Sun, Bohao Jing, Iat Long Iong, Zhenyu Hou, Zehan Qi, Hanyu Lai, Yifan Xu, et al. Agentrl: Scaling agentic reinforcement learning with a multi-turn, multi-task framework.arXiv preprint arXiv:2510.04206, 2025
-
[29]
Activevln: Towards active exploration via multi-turn rl in vision-and-language navigation, 2025
Zekai Zhang, Weiye Zhu, Hewei Pan, Xiangchen Wang, Rongtao Xu, Xing Sun, and Feng Zheng. Activevln: Towards active exploration via multi-turn rl in vision-and-language navigation, 2025. URLhttps://arxiv.org/abs/2509.12618
-
[30]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. Llamafactory: Unified efficient fine-tuning of 100+ language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 3: System Demonstrations), Bangkok, Thailand, 2024. Association for Computational Linguis...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Zheyuan Zhou, Liang Du, Zixun Sun, Xiaoyu Zhou, Ruimin Ye, Qihao Chen, Yinda Chen, and Lemiao Qiu. Main-vla: Modeling abstraction of intention and environment for vision-language- action models.arXiv preprint arXiv:2602.02212, 2026. 12 A Environment and Action Space Observation Space.Our model operates under a strict pixel-only constraint, perceiving the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.