SDM: A Powerful Tool for Evaluating Model Robustness
Pith reviewed 2026-05-21 07:46 UTC · model grok-4.3
The pith
SDM improves adversarial attack performance and efficiency by reconstructing the objective to maximize probability differences between labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
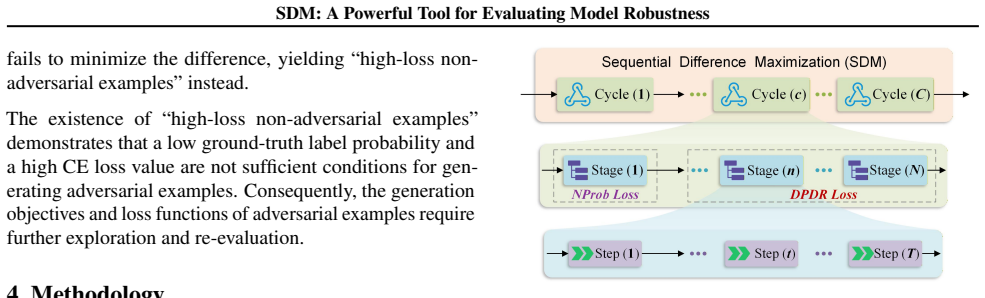
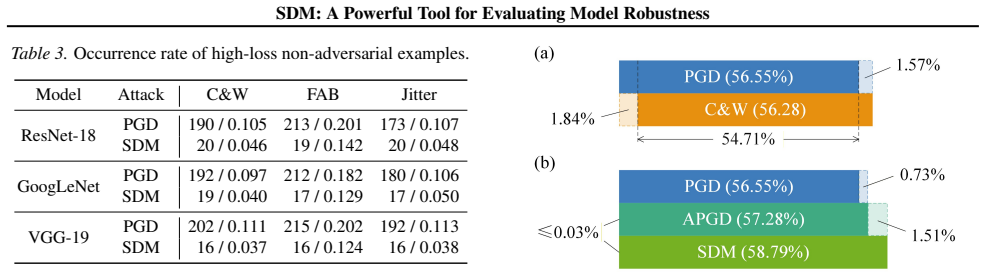
The paper establishes that the high-loss non-adversarial examples issue stems from inappropriate objectives, and that reformulating the objective to maximize the difference between the non-ground-truth label probability upper bound and the ground-truth label probability, pursued via the Sequential Difference Maximization method in a cycle-stage-step framework with negative probability loss and Directional Probability Difference Ratio loss, produces adversarial examples with stronger attack performance and superior cost-effectiveness compared to previous methods.
What carries the argument
The Sequential Difference Maximization (SDM) method, which implements a three-layer 'cycle-stage-step' optimization framework using negative probability loss in the initial stage and Directional Probability Difference Ratio (DPDR) loss in subsequent stages to approach the ideal adversarial objective.
If this is right
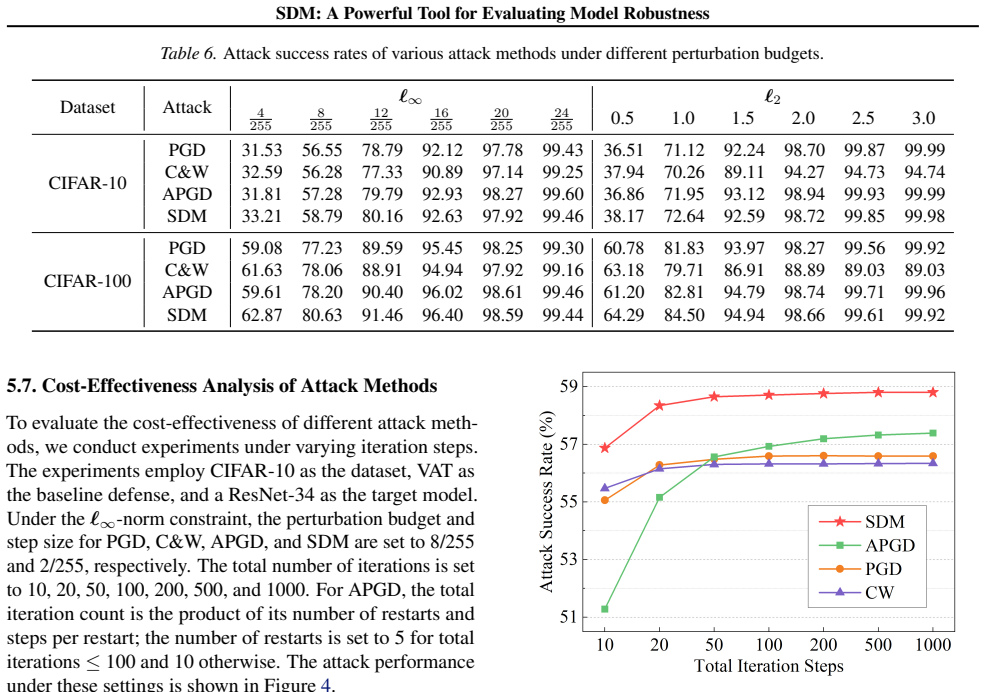
- SDM achieves stronger attack performance than previous state-of-the-art methods such as APGD.
- SDM exhibits superior cost-effectiveness in generating adversarial examples.
- The reconstructed objective directly addresses the high-loss non-adversarial examples problem.
- Models can be evaluated for robustness more reliably using these improved attacks.
Where Pith is reading between the lines
- Adopting SDM as a standard evaluation tool could lead to the discovery of previously undetected vulnerabilities in deployed computer vision models.
- Similar sequential optimization strategies might be applied to other adversarial or optimization problems in machine learning to improve efficiency.
- Further experiments on diverse datasets beyond those tested could validate the generalizability of the performance gains.
Load-bearing premise
That the high-loss non-adversarial examples problem is the main cause of poor performance in prior methods and that the new reconstructed objective solves it without introducing significant new drawbacks.
What would settle it
Running SDM and prior methods like APGD on the same set of models and datasets, measuring attack success rate and computational cost, and finding that SDM does not outperform would falsify the superiority claims.
Figures



read the original abstract
Gradient-based attacks are important methods for evaluating model robustness. However, since the proposal of APGD, it has been difficult for such methods to achieve significant breakthroughs. To achieve such an effect, we first analyze the issue of "high-loss non-adversarial examples" that degrades attack performance in previous methods, and prove that this issue arises from inappropriate objectives for adversarial example generation. Subsequently, we reconstruct the objective as "maximizing the difference between the non-ground-truth label probability upper bound and the ground-truth label probability", and proposes a novel and powerful gradient-based attack method named Sequential Difference Maximization (SDM). SDM establishes a three-layer optimization framework of "cycle-stage-step". It adopts the negative probability loss function and the Directional Probability Difference Ratio (DPDR) loss function in the initial and subsequent optimization stages, respectively, and approaches the ideal objective of adversarial example generation via stage-wise sequential optimization. Experiments demonstrate that compared with previous state-of-the-art methods, SDM not only achieves stronger attack performance but also exhibits superior cost-effectiveness. The code is available at https://github.com/X-L-Liu/ICML-SDM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that gradient-based adversarial attacks have stagnated since APGD due to the 'high-loss non-adversarial examples' problem, which it attributes to and proves arises from inappropriate objectives. It reconstructs the objective as maximizing the difference between the non-ground-truth label probability upper bound and the ground-truth label probability. The proposed Sequential Difference Maximization (SDM) uses a three-layer 'cycle-stage-step' optimization framework, applying negative probability loss in the initial stage and the Directional Probability Difference Ratio (DPDR) loss in subsequent stages to approach the ideal objective. Experiments show SDM achieves stronger attack performance and superior cost-effectiveness versus prior SOTA methods.
Significance. If the central empirical claims hold after addressing attribution issues, this would be a solid incremental advance in adversarial attack design for robustness evaluation. The explicit objective reconstruction and staged framework offer a structured alternative to prior methods, and the public code release supports reproducibility.
major comments (1)
- [Experiments] Experiments section: The paper reports that SDM outperforms previous SOTA in attack strength and cost-effectiveness, but the comparisons omit ablations isolating the three-layer 'cycle-stage-step' framework from the new objective and loss functions. No results are provided for non-staged variants (e.g., single-stage DPDR loss or single-stage negative probability loss) under identical iteration budgets and models. This makes it difficult to attribute the performance gains specifically to the reconstructed objective rather than the added staging machinery, directly affecting support for the central claim of stronger attack performance.
minor comments (2)
- [Abstract] The abstract states that a proof is provided for the origin of the high-loss issue but does not reference the specific section containing the proof or derivation, which would aid readers in locating the technical details.
- [Methods] The definition and motivation for the Directional Probability Difference Ratio (DPDR) loss function could include an explicit equation or pseudocode in the methods section to clarify its relation to the reconstructed objective.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We appreciate the suggestion to strengthen the attribution of performance gains through additional ablations and address the point below.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The paper reports that SDM outperforms previous SOTA in attack strength and cost-effectiveness, but the comparisons omit ablations isolating the three-layer 'cycle-stage-step' framework from the new objective and loss functions. No results are provided for non-staged variants (e.g., single-stage DPDR loss or single-stage negative probability loss) under identical iteration budgets and models. This makes it difficult to attribute the performance gains specifically to the reconstructed objective rather than the added staging machinery, directly affecting support for the central claim of stronger attack performance.
Authors: We agree that explicit ablations would help isolate the contribution of the staged optimization from the reconstructed objective and loss functions. The 'cycle-stage-step' framework is central to SDM because it enables sequential refinement: the initial stage uses negative probability loss to escape poor local optima, while subsequent stages apply DPDR loss to approach the ideal objective of maximizing the probability difference. A purely single-stage approach would not implement this progressive strategy. To directly address the concern, we will add results for single-stage DPDR and single-stage negative probability loss variants (using identical iteration budgets, models, and evaluation protocols) in the revised manuscript. These ablations will clarify the role of staging in the observed gains. revision: yes
Circularity Check
No circularity: objective reconstruction and staged framework are independent proposals
full rationale
The paper identifies a performance issue in prior gradient-based attacks, attributes it to objective choice via analysis, then explicitly reconstructs a new target objective and introduces a three-layer cycle-stage-step optimizer with negative probability loss followed by DPDR loss. These elements are presented as novel design choices rather than quantities derived from or fitted to prior results within the paper. No self-citation chain, uniqueness theorem, or renaming of known patterns is invoked to justify the central construction. Empirical superiority claims rest on direct comparisons under the new framework, not on any reduction of outputs to inputs by construction. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Stage transition thresholds and step counts
axioms (1)
- domain assumption Gradient information remains informative for maximizing the probability-difference objective across stages
invented entities (1)
-
Directional Probability Difference Ratio (DPDR) loss function
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reconstruct the objective as 'maximizing the difference between the non-ground-truth label probability upper bound and the ground-truth label probability'
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and orbit embedding unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-layer optimization framework of 'cycle-stage-step'
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Costas Neocleous and Christos N. Schizas , editor =. On the Claim for the Existence of "Adversarial Examples" in Deep Learning Neural Networks , booktitle =. 2014 , url =. doi:10.5220/0005152503060309 , timestamp =
-
[2]
Goodfellow and Jonathon Shlens and Christian Szegedy , editor =
Ian J. Goodfellow and Jonathon Shlens and Christian Szegedy , editor =. Explaining and Harnessing Adversarial Examples , booktitle =. 2015 , url =
work page 2015
-
[3]
Advances in Adversarial Attacks and Defenses in Computer Vision:
Naveed Akhtar and Ajmal Mian and Navid Kardan and Mubarak Shah , author =. Advances in Adversarial Attacks and Defenses in Computer Vision:. 2021 , url =. doi:10.1109/ACCESS.2021.3127960 , timestamp =
-
[4]
Jiangfan Liu and Yishan Li and Yanming Guo and Yu Liu and Jun Tang and Ying Nie , title =. Artif. Intell. Rev. , volume =. 2024 , url =. doi:10.1007/S10462-024-10841-Z , timestamp =
-
[5]
Proceedings of the 37th International Conference on Machine Learning,
Francesco Croce and Matthias Hein , title =. Proceedings of the 37th International Conference on Machine Learning,. 2020 , url =
work page 2020
-
[6]
Nicholas Carlini and David A. Wagner , title =. 2017. 2017 , url =. doi:10.1109/SP.2017.49 , timestamp =
-
[7]
Seyed. DeepFool:. 2016. 2016 , url =. doi:10.1109/CVPR.2016.282 , timestamp =
-
[8]
6th International Conference on Learning Representations,
Aleksander Madry and Aleksandar Makelov and Ludwig Schmidt and Dimitris Tsipras and Adrian Vladu , title =. 6th International Conference on Learning Representations,. 2018 , url =
work page 2018
-
[9]
Bakary Badjie and Jos. Adversarial Attacks and Countermeasures on Image Classification-based Deep Learning Models in Autonomous Driving Systems:. 2025 , url =. doi:10.1145/3691625 , timestamp =
-
[10]
Goodfellow and Rob Fergus , editor =
Christian Szegedy and Wojciech Zaremba and Ilya Sutskever and Joan Bruna and Dumitru Erhan and Ian J. Goodfellow and Rob Fergus , editor =. Intriguing properties of neural networks , booktitle =. 2014 , url =
work page 2014
-
[11]
Goodfellow and Samy Bengio , title =
Alexey Kurakin and Ian J. Goodfellow and Samy Bengio , title =. 5th International Conference on Learning Representations,. 2017 , url =
work page 2017
-
[12]
Wide Residual Networks , booktitle =
Sergey Zagoruyko and Nikos Komodakis , editor =. Wide Residual Networks , booktitle =. 2016 , url =
work page 2016
-
[13]
Learning Multiple Layers of Features from Tiny Images , author=. 2009 , month=apr, url=
work page 2009
-
[14]
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun , title =. 2016. 2016 , url =. doi:10.1109/CVPR.2016.90 , timestamp =
-
[15]
8th International Conference on Learning Representations,
Yisen Wang and Difan Zou and Jinfeng Yi and James Bailey and Xingjun Ma and Quanquan Gu , title =. 8th International Conference on Learning Representations,. 2020 , url =
work page 2020
-
[16]
Xiangyu Yin and Wenjie Ruan , title =. 2024 , url =. doi:10.1109/CVPR52733.2024.02317 , timestamp =
-
[17]
Reducing Excessive Margin to Achieve a Better Accuracy vs
Rahul Rade and Seyed. Reducing Excessive Margin to Achieve a Better Accuracy vs. Robustness Trade-off , booktitle =. 2022 , url =
work page 2022
-
[18]
Proceedings of the Thirty-Second
Pin. Proceedings of the Thirty-Second. 2018 , url =. doi:10.1609/AAAI.V32I1.11302 , timestamp =
-
[19]
Matching Networks for One Shot Learning , booktitle =
Oriol Vinyals and Charles Blundell and Tim Lillicrap and Koray Kavukcuoglu and Daan Wierstra , editor =. Matching Networks for One Shot Learning , booktitle =. 2016 , url =
work page 2016
-
[20]
Bartoldson and James Diffenderfer and Konstantinos Parasyris and Bhavya Kailkhura , title =
Brian R. Bartoldson and James Diffenderfer and Konstantinos Parasyris and Bhavya Kailkhura , title =. Forty-first International Conference on Machine Learning,. 2024 , url =
work page 2024
-
[21]
Maksym Andriushchenko and Francesco Croce and Nicolas Flammarion and Matthias Hein , editor =. Square Attack:. Computer Vision -. 2020 , url =. doi:10.1007/978-3-030-58592-1\_29 , timestamp =
-
[22]
Yiyun Zhou and Meng Han and Liyuan Liu and Jing He and Xi Gao , title =. 16th. 2019 , url =. doi:10.1109/MASSW.2019.00012 , timestamp =
-
[23]
Survey of computer vision algorithms and applications for unmanned aerial vehicles , journal =
Abdulla Al. Survey of computer vision algorithms and applications for unmanned aerial vehicles , journal =. 2018 , url =. doi:10.1016/J.ESWA.2017.09.033 , timestamp =
-
[24]
Francesco Croce and Maksym Andriushchenko and Vikash Sehwag and Edoardo Debenedetti and Nicolas Flammarion and Mung Chiang and Prateek Mittal and Matthias Hein , title =. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual , year =
work page 2021
-
[25]
A state transition-based method for influence evaluation in networks , journal =. 2026 , issn =. doi:https://doi.org/10.1016/j.chaos.2025.117713 , url =
-
[26]
Jia Deng and Wei Dong and Richard Socher and Li. ImageNet:. 2009. 2009 , url =. doi:10.1109/CVPR.2009.5206848 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.