Clove: Object-Level CXL Memory Management in Managed Runtimes
Pith reviewed 2026-05-21 06:56 UTC · model grok-4.3
The pith
Managed runtimes can be extended with hotness tracking and relocation to support object-level CXL memory management.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Clove extends existing managed runtimes to support object-level CXL management by combining profile-guided object hotness tracking with object relocation techniques and policies. The JVM prototype shows this enables high utilization of fast-tier memory while bounding runtime overhead, reducing application slowdown by 22-84% compared to page-based systems.
What carries the argument
Profile-guided object hotness tracking combined with object relocation techniques and policies inside the managed runtime.
If this is right
- High utilization of fast-tier memory becomes achievable for managed-language applications.
- Runtime overhead stays bounded despite the addition of tracking and relocation.
- Application slowdown drops by 22-84% relative to page-based CXL systems.
- Object-level management works for managed languages without needing bespoke runtimes or compiler changes.
Where Pith is reading between the lines
- Similar extensions could be applied to other managed runtimes beyond the JVM prototype.
- Tighter integration with the garbage collector might further reduce relocation costs.
- This software path could make CXL tiered memory viable for a wider range of existing applications.
Load-bearing premise
The overhead of adding hotness tracking and object relocation policies to an existing managed runtime remains low enough to be practical under CXL's tight performance budget, without requiring major changes to the runtime's core object model or garbage collector.
What would settle it
A measurement on the JVM prototype where the combined cost of hotness tracking plus object relocation exceeds the latency benefit of fast-tier memory, producing no net reduction in slowdown versus page-based placement.
Figures









read the original abstract
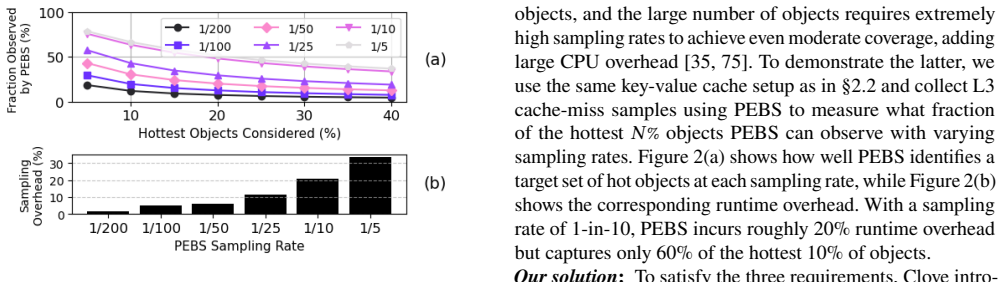
Object-level management of tiered memory has been studied to address the inefficiencies in page-based systems. However, object-level management for CXL-tiered memory remains underexplored due to CXL's tight performance budget and load/store interface. As a result, existing approaches remain limited in scope, primarily targeting unmanaged-language applications with bespoke runtimes or compiler support. This paper identifies and explores a new design point for object-level CXL management: managed languages and their runtimes. The key observation is that existing managed runtimes already provide highly optimized mechanisms for problems closely related to object-level management, including object relocation and dynamic code generation. However, they still lack the features needed for tiered memory management, such as hotness tracking and relocation policies, and thus must be carefully extended to fully realize this direction. We present Clove, a system that extends existing managed runtimes to support object-level CXL management for managed-language applications. Clove combines profile-guided object hotness tracking with object relocation techniques and policies. Our JVM prototype demonstrates that this extension enables high utilization of fast-tier memory while bounding runtime overhead, reducing application slowdown by 22-84% compared to page-based systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Clove, a system extending managed runtimes (with a JVM prototype) for object-level CXL memory management. It observes that existing runtimes already support object relocation and dynamic code generation but lack hotness tracking and tiered-memory relocation policies. Clove adds profile-guided hotness tracking combined with relocation techniques and policies; the prototype is claimed to achieve high fast-tier utilization while bounding overhead, yielding 22-84% reduction in application slowdown versus page-based baselines.
Significance. If the quantitative claims hold under full experimental scrutiny, the work would be significant for systems research on heterogeneous memory. It identifies a practical design point that reuses mature runtime mechanisms rather than requiring new compiler support or bespoke runtimes, potentially enabling managed-language applications to exploit CXL tiers more efficiently than page-granularity approaches. The emphasis on keeping changes localized to hotness tracking and policy layers is a constructive contribution, though its value depends on demonstrating that added costs remain tolerable given CXL latency.
major comments (2)
- Abstract: The central claim that the JVM prototype reduces slowdown by 22-84% while bounding runtime overhead is load-bearing for the paper's contribution, yet the text provides no workload descriptions, baseline configurations (e.g., specific page-based CXL systems), sampling rates for hotness tracking, or breakdown of relocation costs. Without these, it is impossible to verify whether the measured net benefit already incorporates the overhead of object hotness tracking and pointer updates or whether those costs were under-counted.
- Design/Implementation (hotness tracking and relocation policy sections): The assertion that existing relocation mechanisms can be reused without major core-model changes does not automatically guarantee that aggregate overhead stays inside CXL's tight performance budget. Explicit measurements of the incremental latency from profile-guided tracking, reference patching during relocation, and any additional GC work on remote objects are required; if these costs compound with CXL's inherent latency, the practical advantage over page-based systems could shrink substantially.
minor comments (2)
- Abstract: Consider adding one sentence clarifying the specific JVM (e.g., OpenJDK version or modification points) to help readers assess how localized the changes truly are.
- Throughout: Ensure that any figures showing utilization or slowdown include error bars or multiple runs to convey variability, especially given CXL's sensitivity to access patterns.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify areas where additional clarity on experimental parameters and overhead accounting would strengthen the presentation. We have revised the manuscript to incorporate more explicit details in the abstract and to expand the discussion and measurements of incremental costs in the design and evaluation sections.
read point-by-point responses
-
Referee: [—] Abstract: The central claim that the JVM prototype reduces slowdown by 22-84% while bounding runtime overhead is load-bearing for the paper's contribution, yet the text provides no workload descriptions, baseline configurations (e.g., specific page-based CXL systems), sampling rates for hotness tracking, or breakdown of relocation costs. Without these, it is impossible to verify whether the measured net benefit already incorporates the overhead of object hotness tracking and pointer updates or whether those costs were under-counted.
Authors: We agree that the abstract would be improved by including concise references to these parameters. The full manuscript already details the workloads (DaCapo and SPECjvm suites) and page-based baseline (Linux memory tiering over CXL) in Section 5, along with a 10 ms periodic sampling rate for hotness tracking and relocation cost breakdowns in Section 6.2 and Figure 7. To address the concern directly, we have expanded the abstract to note that the reported slowdown reductions are end-to-end figures that include hotness tracking and pointer-update overheads. A short parenthetical on sampling and baseline has also been added. revision: yes
-
Referee: [—] Design/Implementation (hotness tracking and relocation policy sections): The assertion that existing relocation mechanisms can be reused without major core-model changes does not automatically guarantee that aggregate overhead stays inside CXL's tight performance budget. Explicit measurements of the incremental latency from profile-guided tracking, reference patching during relocation, and any additional GC work on remote objects are required; if these costs compound with CXL's inherent latency, the practical advantage over page-based systems could shrink substantially.
Authors: We accept that an explicit accounting of incremental costs is necessary. Our prototype measurements (now highlighted in a new paragraph in Section 4.3 and expanded in Section 6.3) show profile-guided tracking contributing 1.2–2.8 % overhead, reference patching averaging 0.4 ms per batch, and additional remote-object GC work kept below 0.8 % through policy filtering. These figures are already folded into the end-to-end slowdown numbers; the 22–84 % net improvement versus the page-based baseline therefore reflects the combined effect. We have added a dedicated overhead breakdown table to make the accounting transparent. revision: yes
Circularity Check
No circularity: empirical implementation results, not derived predictions
full rationale
The paper describes a systems implementation (Clove) that extends managed runtimes with profile-guided hotness tracking and object relocation policies for CXL-tiered memory. Its central claims rest on prototype measurements showing 22-84% slowdown reduction versus page-based baselines. No equations, fitted parameters, uniqueness theorems, or first-principles derivations are present that could reduce to self-citations or inputs by construction. The evaluation uses external benchmarks and reports measured overheads directly, rendering the result self-contained without any load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Clove combines profile-guided object hotness tracking with object relocation techniques and policies.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our JVM prototype demonstrates that this extension enables high utilization of fast-tier memory while bounding runtime overhead
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Neha Agarwal and Thomas F Wenisch. 2017. Thermostat: Application- transparent page management for two-tiered main memory. InProceed- ings of the Twenty-Second International Conference on Architectural SupportforProgrammingLanguagesandOperatingSystems.631–644
work page 2017
-
[2]
ACM SIGPLAN Notices53, 4 (2018), 62–77
Shoaib Akram, Jennifer B Sartor, Kathryn S McKinley, and Lieven Eeckhout.2018.Write-rationinggarbagecollectionforhybridmemories. ACM SIGPLAN Notices53, 4 (2018), 62–77
work page 2018
-
[3]
Hasan Al Maruf and Mosharaf Chowdhury. 2020. Effectively prefetch- ing remote memory with leap. In2020 USENIX Annual Technical Conference (USENIX ATC 20). 843–857
work page 2020
-
[4]
Emmanuel Amaro, Christopher Branner-Augmon, Zhihong Luo, Amy Ousterhout, Marcos K Aguilera, Aurojit Panda, Sylvia Ratnasamy, and Scott Shenker. 2020. Can far memory improve job throughput?. InProceedings of the Fifteenth European Conference on Computer Systems. 1–16
work page 2020
-
[5]
Emmanuel Amaro, Stephanie Wang, Aurojit Panda, and Marcos K Aguilera. 2023. Logical Memory Pools: Flexible and Local Disaggre- gated Memory. InProceedings of the 22nd ACM Workshop on Hot Topics in Networks. 25–32
work page 2023
-
[6]
Berk Atikoglu, Yuehai Xu, Eitan Frachtenberg, Song Jiang, and Mike Paleczny. 2012. Workload analysis of a large-scale key-value store. In Proceedings of the 12th ACM SIGMETRICS/PERFORMANCE joint international conference on Measurement and Modeling of Computer Systems. 53–64
work page 2012
-
[7]
Vinay Banakar, Suli Yang, Kan Wu, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau, and Kimberly Keeton. 2026. OBASE: Object-Based Address-Space Engineering to Improve Memory Tiering. arXiv:2603.00378 [cs.OS]
-
[8]
Scott Beamer, Krste Asanović, and David Patterson. 2015. The GAP benchmark suite.arXiv preprint arXiv:1508.03619(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[9]
Irina Calciu, M Talha Imran, Ivan Puddu, Sanidhya Kashyap, Hasan Al Maruf, Onur Mutlu, and Aasheesh Kolli. 2021. Rethinking software runtimes for disaggregated memory. InProceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems. 79–92
work page 2021
-
[10]
Dehao Chen, David Xinliang Li, and Tipp Moseley. 2016. AutoFDO: Automatic feedback-directed optimization for warehouse-scale applica- tions. InProceedings of the 2016 International Symposium on Code Generation and Optimization. 12–23
work page 2016
-
[11]
Brian F Cooper, Adam Silberstein, Erwin Tam, Raghu Ramakrishnan, and Russell Sears. 2010. Benchmarking cloud serving systems with YCSB. InProceedings of the 1st ACM symposium on Cloud computing. 143–154
work page 2010
-
[12]
cosmossjigu.2024. MEMTIS:EfficientMemoryTieringwithDynamic Page Classification and Page Size Determination.https://github.com/ cosmoss-jigu/memtis. [Accessed 09-12-2024]
work page 2024
-
[13]
Paul Drongowski, Lei Yu, Frank Swehosky, Suravee Suthikulpanit, and Robert Richter. 2010. Incorporating instruction-based sampling into AMD CodeAnalyst. In2010 IEEE International Symposium on PerformanceAnalysisofSystems&Software(ISPASS).IEEE,119–120
work page 2010
-
[14]
The design and operation of{CloudLab}
Dmitry Duplyakin, Robert Ricci, Aleksander Maricq, Gary Wong, JonathonDuerig,EricEide,LeighStoller,MikeHibler,DavidJohnson, Kirk Webb, et al.2019. The design and operation of{CloudLab}. In 2019 USENIX annual technical conference (USENIX ATC 19). 1–14
work page 2019
-
[15]
Towards an adaptable systems architecture for memory tiering at warehouse-scale
PadmapriyaDuraisamy,WeiXu,ScottHare,RaviRajwar,DavidCuller, Zhiyi Xu, Jianing Fan, Christopher Kennelly, Bill McCloskey, Danijela Mijailovic, et al.2023. Towards an adaptable systems architecture for memory tiering at warehouse-scale. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Sy...
work page 2023
-
[16]
Ehcache. 2024. Ehcache.https://www.ehcache.org/. [Accessed 09-12-2024]
work page 2024
-
[17]
Juncheng Gu, Youngmoon Lee, Yiwen Zhang, Mosharaf Chowdhury, and Kang G Shin. 2017. Efficient memory disaggregation with infin- iswap. In14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17). 649–667
work page 2017
-
[18]
Zhiyuan Guo, Zijian He, and Yiying Zhang. 2023. Mira: A program- behavior-guided far memory system. InProceedings of the 29th Sym- posium on Operating Systems Principles. 692–708
work page 2023
-
[19]
H2. 2025. H2 Database Engine — h2database.com.https://www. h2database.com/html/main.html. [Accessed 17-08-2025]
work page 2025
-
[20]
Peter Hassan, Michael Wagner, Filip Pizlo, and Toon Verwaest. 2019. Trash Talk: The Orinoco Garbage Collector.https://v8.dev/blog/trash- talk. V8 Blog. Describes V8’s generational heap, major mark-compact GC, scavenger, object evacuation, and compacting/moving collection. Accessed 2026-04-29
work page 2019
-
[21]
Red Hat. 2025. Huge Pages and Transparent Huge Pages. https://docs.redhat.com/en/documentation/red_hat_enterprise_ linux/6/html/performance_tuning_guide/s-memory-transhuge. [Accessed 03-12-2024]
work page 2025
-
[22]
2011.Computer architecture: a quantitative approach
John L Hennessy and David A Patterson. 2011.Computer architecture: a quantitative approach. Elsevier
work page 2011
- [23]
-
[24]
Intel. 2024. Timed Process Event-Based Sampling (TPEBS). https://www.intel.com/content/www/us/en/developer/articles/ technical/timed-process-event-based-sampling-tpebs.html. [Ac- cessed 03-12-2024]
work page 2024
-
[25]
Saba Jamilan, Tanvir Ahmed Khan, Grant Ayers, Baris Kasikci, and Heiner Litz. 2022. Apt-get: Profile-guided timely software prefetching. InProceedings of the Seventeenth European Conference on Computer Systems. 747–764
work page 2022
-
[26]
JGraphT.2023. JGraphT.https://jgrapht.org/. [Accessed10-12-2024]
work page 2023
-
[27]
Stefan Karlsson. 2024. JEP 439: Generational ZGC.https://openjdk. org/jeps/439. [Accessed 10-12-2024]
work page 2024
-
[28]
kevin981. 2025. Artifact repository for HybridTier (ASPLOS 25). https://github.com/kevins981/hybridtier-asplos25-artifact. [Accessed 08-19-2025]
work page 2025
-
[29]
Jonghyeon Kim, Wonkyo Choe, and Jeongseob Ahn. 2021. Exploring the design space of page management for{Multi-Tiered} memory systems. In2021USENIX Annual TechnicalConference (USENIX ATC 21). 715–728
work page 2021
-
[30]
Apostolos Kokolis, Dimitrios Skarlatos, and Josep Torrellas. 2019. Pageseer: Using page walks to trigger page swaps in hybrid memory systems. In2019 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 596–608
work page 2019
-
[31]
Jagadish B Kotra, Haibo Zhang, Alaa R Alameldeen, Chris Wilker- son, and Mahmut T Kandemir. 2018. Chameleon: A dynamically reconfigurable heterogeneous memory system. In2018 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 533–545
work page 2018
-
[32]
Jennifer Lam, Jeffrey Helt, Wyatt Lloyd, and Haonan Lu. 2024. Ac- celerating Skewed Workloads With Performance Multipliers in the {TurboDB} Distributed Database. In21st USENIX Symposium on Net- worked Systems Design and Implementation (NSDI 24). 1213–1228
work page 2024
-
[33]
Donghee Lee, Jongmoo Choi, Jong-Hun Kim, Sam H Noh, Sang Lyul Min, Yookun Cho, and Chong Sang Kim. 1999. On the existence of a spectrum of policies that subsumes the least recently used (LRU) and least frequently used (LFU) policies. InProceedings of the 1999 ACM SIGMETRICS international conference on Measurement and modeling of computer systems. 134–143
work page 1999
-
[34]
Taehyung Lee, Sumit Kumar Monga, Changwoo Min, and Young Ik Eom. 2023. Memtis: Efficient memory tiering with dynamic page 13 classification and page size determination. InProceedings of the 29th Symposium on Operating Systems Principles. 17–34
work page 2023
-
[35]
JohnnyCache:theEndof {DRAM} Cache Conflicts (in Tiered Main Memory Systems)
BaptisteLepersandWillyZwaenepoel.2023. JohnnyCache:theEndof {DRAM} Cache Conflicts (in Tiered Main Memory Systems). In17th USENIXSymposiumonOperatingSystemsDesignandImplementation (OSDI 23). 519–534
work page 2023
-
[36]
Scott T Leutenegger and Daniel Dias. 1993. A modeling study of the TPC-C benchmark.ACM Sigmod Record22, 2 (1993), 22–31
work page 1993
-
[37]
HuaichengLi,DanielSBerger,LisaHsu,DanielErnst,PanteaZardoshti, Stanko Novakovic, Monish Shah, Samir Rajadnya, Scott Lee, Ishwar Agarwal, et al. 2023. Pond: Cxl-based memory pooling systems for cloud platforms. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 574–587
work page 2023
- [38]
-
[39]
Zhihong Luo, Sam Son, Sylvia Ratnasamy, and Scott Shenker. 2024. Harvestingmemory-bound {CPU}stallcyclesinsoftwarewith {MSH}. In18th USENIX Symposium on Operating Systems Design and Imple- mentation (OSDI 24). 57–75
work page 2024
-
[40]
Adnan Maruf, Ashikee Ghosh, Janki Bhimani, Daniel Campello, Andy Rudoff, and Raju Rangaswami. 2022. Multi-clock: Dynamic tiering for hybrid memory systems. In2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA’22)
work page 2022
-
[41]
Hasan Al Maruf, Hao Wang, Abhishek Dhanotia, Johannes Weiner, Niket Agarwal, Pallab Bhattacharya, Chris Petersen, Mosharaf Chowd- hury, Shobhit Kanaujia, and Prakash Chauhan. 2023. Tpp: Transparent page placement for cxl-enabled tiered-memory. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Ope...
work page 2023
-
[42]
2003.{ARC}: A{Self- Tuning}, low overhead replacement cache
Nimrod Megiddo and Dharmendra S Modha. 2003.{ARC}: A{Self- Tuning}, low overhead replacement cache. In2nd USENIX Conference on File and Storage Technologies (FAST 03)
work page 2003
-
[43]
DimitriosMichail,JorisKinable,BarakNaveh,andJohnVSichi.2020. Jgrapht—a java library for graph data structures and algorithms.ACM Transactions on Mathematical Software (TOMS)46, 2 (2020), 1–29
work page 2020
-
[44]
Microsoft. 2024. Managed Execution Process.https://learn.microsoft. com/en-us/dotnet/standard/managed-execution-process. Microsoft Learn. Documents CIL-to-native-code compilation by the .NET JIT compiler. Accessed 2026-04-29
work page 2024
-
[45]
Microsoft. 2025. Fundamentals of Garbage Collection. https://learn.microsoft.com/en-us/dotnet/standard/garbage- collection/fundamentals. Microsoft Learn. Documents the CLR managed heap, generational GC, compaction of reachable objects, pointer correction, and object movement. Accessed 2026-04-29
work page 2025
-
[46]
Mozilla. [n.d.]. SpiderMonkey Garbage Collector.https://firefox- source-docs.mozilla.org/js/gc.html. Firefox Source Docs. Describes SpiderMonkey’s GC as precise, incremental, generational, partially concurrent, parallel, and compacting. Accessed 2026-04-29
work page 2026
-
[47]
Dat Nguyen and Khanh Nguyen. 2024. Polar: A Managed Runtime with Hotness-Segregated Heap for Far Memory. InProceedings of the 15th ACM SIGOPS Asia-Pacific Workshop on Systems. 15–22
work page 2024
-
[48]
OpenJDK. 2023. JDK 21.https://openjdk.org/projects/jdk/21/. [Ac- cessed 19-08-2025]
work page 2023
-
[49]
Oracle. 2024. HotSpot Virtual Machine Garbage Collection Tuning Guide.https://docs.oracle.com/en/java/javase/21/gctuning/garbage- first-g1-garbage-collector1.html. [Accessed 10-12-2024]
work page 2024
-
[50]
Oracle. 2025. Java Support for Large Memory Pages.https://www. oracle.com/java/technologies/javase/largememory-pages.html. [Ac- cessed 03-12-2024]
work page 2025
-
[51]
Michael Paleczny, Christopher Vick, and Cliff Click. 2001. The java {HotSpot™} server compiler. InJava (TM) Virtual Machine Research and Technology Symposium (JVM 01)
work page 2001
-
[52]
Andreas Prodromou, Mitesh Meswani, Nuwan Jayasena, Gabriel Loh, and Dean M Tullsen. 2017. Mempod: A clustered architecture for efficient and scalable migration in flat address space multi-level mem- ories. In2017 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 433–444
work page 2017
-
[53]
Amanda Raybuck, Tim Stamler, Wei Zhang, Mattan Erez, and Simon Peter. 2021. Hemem: Scalable tiered memory management for big data applications and real nvm. InProceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles. 392–407
work page 2021
-
[54]
Jie Ren, Dong Xu, Junhee Ryu, Kwangsik Shin, Daewoo Kim, and Dong Li. 2024. MTM: Rethinking memory profiling and migration for multi-tiered large memory. InProceedings of the Nineteenth European Conference on Computer Systems. 803–817
work page 2024
-
[55]
2020.{AIFM}:{High-Performance},{Application-Integrated} far memory
Zhenyuan Ruan, Malte Schwarzkopf, Marcos K Aguilera, and Adam Belay. 2020.{AIFM}:{High-Performance},{Application-Integrated} far memory. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). 315–332
work page 2020
-
[56]
JeeHoRyoo,MiteshRMeswani,AndreasProdromou,andLizyKJohn
-
[57]
In2017 IEEE International Symposium on High Performance Computer Architecture (HPCA)
SILC-FM: Subblocked interleaved cache-like flat memory orga- nization. In2017 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 349–360
-
[58]
Samsung.2022.SamsungElectronicsIntroducesIndustry’sFirst512GB CXL Memory Module.https://news.samsung.com/global/samsung- electronics-introduces-industrys-first-512gb-cxl-memory-module. [Accessed 18-08-2025]
work page 2022
-
[59]
Jaewoong Sim, Alaa R Alameldeen, Zeshan Chishti, Chris Wilkerson, andHyesoonKim.2014. Transparenthardwaremanagementofstacked dramaspartofmemory.In201447thAnnualIEEE/ACMInternational Symposium on Microarchitecture. IEEE, 13–24
work page 2014
-
[60]
Kevin Song, Jiacheng Yang, Zixuan Wang, Jishen Zhao, Sihang Liu, and Gennady Pekhimenko. 2025. HybridTier: an Adaptive and Light- weight CXL-Memory Tiering System. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3. 112–128
work page 2025
-
[61]
Yan Sun, Yifan Yuan, Zeduo Yu, Reese Kuper, Chihun Song, Jinghan Huang, Houxiang Ji, Siddharth Agarwal, Jiaqi Lou, Ipoom Jeong, et al
-
[62]
InProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture
Demystifying cxl memory with genuine cxl-ready systems and devices. InProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture. 105–121
-
[63]
Leszek Swirski. 2023. Maglev: V8’s Fastest Optimizing JIT.https: //v8.dev/blog/maglev. V8 Blog. Describes V8’s Ignition interpreter, Sparkplug baseline JIT, TurboFan optimizer, and Maglev optimizing JIT. Accessed 2026-04-29
work page 2023
-
[64]
Linpeng Tang, Qi Huang, Amit Puntambekar, Ymir Vigfusson, Wyatt Lloyd, and Kai Li. 2017. Popularity prediction of facebook videos for higherqualitystreaming.In2017USENIXAnnualTechnicalConference (USENIX ATC 17). 111–123
work page 2017
-
[65]
TrackFM:Far-outcompilersupportforafarmemory world
Brian R Tauro, Brian Suchy, Simone Campanoni, Peter Dinda, and KyleCHale.2024. TrackFM:Far-outcompilersupportforafarmemory world. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1. 401–419
work page 2024
-
[66]
Sergey Tepliakov. 2017. Managed Object Internals, Part 2: Object Header Layout and the Cost of Locking. https://devblogs.microsoft.com/premier-developer/managed-object- internals-part-2-object-header-layout-and-the-cost-of-locking/. MicrosoftDeveloperBlogs.DescribesCLRobjectheaders,hashcodes, lock-related data, and sync-block indices. Accessed 2026-04-29
work page 2017
-
[67]
The PyPy Project. 2026. Garbage Collector Documentation and Con- figuration.https://doc.pypy.org/gc_info.html. PyPy documentation. Describes PyPy’s default incminimark GC as an incremental, genera- tional moving collector. Accessed 2026-04-29. 14
work page 2026
-
[68]
The PyPy Project. 2026. PyPy.https://www.pypy.org/. Official PyPy website. Describes PyPy’s speed as due to its Just-in-Time compiler. Accessed 2026-04-29
work page 2026
-
[69]
TPC. 2025. TPC-C Homepage.https://www.tpc.org/tpcc/. [Accessed 19-08-2025]
work page 2025
-
[70]
Twitter. 2020. A collection of Twitter’s anonymized production cache traces.https://github.com/twitter/cache-trace. [Accessed 11-04- 2025]
work page 2020
-
[71]
Rik van Riel and Vinod Chegu. 2014. Automatic NUMA balancing. Red Hat Summit. [Accessed 18-08-2025]
work page 2014
-
[72]
Midhul Vuppalapati and Rachit Agarwal. 2024. Tiered Memory Man- agement: Access Latency is the Key!. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles. 79–94
work page 2024
-
[73]
Panthera: Holistic memory management for big data processing over hybrid memories
Chenxi Wang, Huimin Cui, Ting Cao, John Zigman, Haris Volos, Onur Mutlu,FangLv,XiaobingFeng,andGuoqingHarryXu.2019. Panthera: Holistic memory management for big data processing over hybrid memories. InProceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation. 347–362
work page 2019
-
[74]
Chenxi Wang, Haoran Ma, Shi Liu, Yuanqi Li, Zhenyuan Ruan, Khanh Nguyen, Michael D Bond, Ravi Netravali, Miryung Kim, and Guo- qing Harry Xu. 2020. Semeru: A{Memory-Disaggregated} managed runtime. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). 261–280
work page 2020
-
[75]
Chenxi Wang, Haoran Ma, Shi Liu, Yifan Qiao, Jonathan Eyolf- son, Christian Navasca, Shan Lu, and Guoqing Harry Xu. 2022. {MemLiner}: Lining up Tracing and Application for a{Far-Memory- Friendly} Runtime. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). 35–53
work page 2022
-
[76]
Xiaoyuan Wang, Haikun Liu, Xiaofei Liao, Ji Chen, Hai Jin, Yu Zhang, Long Zheng, Bingsheng He, and Song Jiang. 2019. Supporting superpages and lightweight page migration in hybrid memory systems. ACM Transactions on Architecture and Code Optimization (TACO)16, 2 (2019), 1–26
work page 2019
-
[77]
Nomad: {Non-Exclusive} MemoryTiering via Transactional Page Migration
Lingfeng Xiang, Zhen Lin, Weishu Deng, Hui Lu, Jia Rao, Yifan Yuan,andRenWang.2024. Nomad: {Non-Exclusive} MemoryTiering via Transactional Page Migration. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 19–35
work page 2024
-
[78]
Dong Xu, Junhee Ryu, Kwangsik Shin, Pengfei Su, and Dong Li. 2024. {FlexMem}: Adaptive page profiling and migration for tiered memory. In2024 USENIX Annual Technical Conference (USENIX ATC 24). 817–833
work page 2024
-
[79]
ZiYan,DanielLustig,DavidNellans,andAbhishekBhattacharjee.2019. Nimblepagemanagementfortieredmemorysystems.InProceedingsof the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems. 331–345
work page 2019
-
[80]
Albert Mingkun Yang, Erik Österlund, and Tobias Wrigstad. 2020. Improving program locality in the GC using hotness. InProceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation. 301–313
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.