Direct Translation between Sign Languages
Pith reviewed 2026-05-21 05:50 UTC · model grok-4.3
The pith
A unified model trained on synthetic sign-sign pairs translates directly between sign languages more accurately and faster than routing through text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
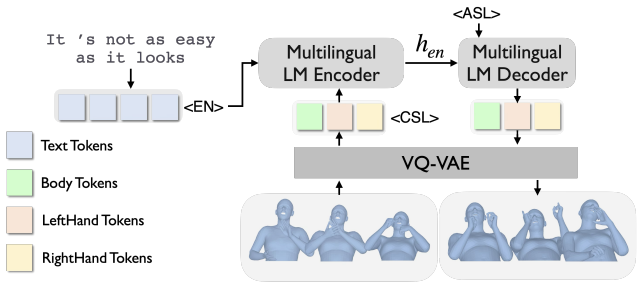
Using back-translation to create synthetic sign-sign pairs from unaligned sign language corpora, a single MBART-based model jointly trained for text-to-sign and sign-to-sign translation outperforms a cascaded sign-to-text-to-sign baseline, with 20 percent lower DTW-aligned MPJPE on geometric metrics, 50 percent higher BLEU-4 after back-translation to sentences, and roughly 2.3 times faster inference, with similar gains observed on a small existing cross-lingual sign set.
What carries the argument
Synthetic sign-sign pairs produced by back-translation from separate sign-text corpora, used to jointly train a single model for direct sign-to-sign mapping.
If this is right
- The direct method records 20 percent lower DTW-aligned MPJPE than the cascade on geometric sign error.
- After translating model outputs back to text, it reaches 50 percent higher BLEU-4 than the cascaded route.
- Inference runs approximately 2.3 times faster than the three-stage cascade.
- Comparable accuracy and speed gains appear on a small existing set of real cross-lingual sign data.
Where Pith is reading between the lines
- If the synthetic-pair approach scales, it could support direct translation for additional sign language pairs that lack parallel data.
- Direct modeling may retain visual features such as facial expression and spatial grammar that text intermediaries discard.
- Applying the same back-translation recipe to larger unaligned corpora could test whether performance keeps improving with more synthetic data.
Load-bearing premise
The synthetic sign-sign pairs created by back-translation are close enough in visual form and meaning to real parallel data that joint training improves results without hiding systematic mismatches the chosen metrics cannot detect.
What would settle it
Evaluating the direct model against the cascade on a sizable collection of human-collected, time-aligned parallel sign utterances between two sign languages and finding no consistent advantage for the direct method.
Figures



read the original abstract
The field of sign language translation has witnessed significant progress in the translation between sign and spoken languages, but the translation between sign languages remains largely unexplored and out of reach. The latter can help 1.5 billion deaf and hard-of-hearing (DHH) people worldwide communicate across language barriers without relying on hearing interpreters or written-language fluency. The cascade approach composing separate sign-to-text, text-to-text, and text-to-sign systems suffers from error propagation and extra latency as well as the loss of information unique in the visual modality. We aim to develop direct sign-to-sign translation. However, a large-scale open-domain parallel corpus has not been curated between sign languages. To enable direct translation between sign language utterances, we use back-translation to produce synthetic sign-sign pairs from unaligned individual language utterance-sign corpora. Using this data, we jointly train a single MBART-based model for both text->sign (T2S) and sign->sign (S2S). On synthetically generated paired sets between American Sign Language (ASL), Chinese Sign Language (CSL), and German Sign Language (DGS), our direct S2S method outperforms the cascaded baseline on geometric sign error metrics (20% lower DTW-aligned MPJPE) and language matching metrics after predicted sign utterances are translated back to sentences (50% high BLEU-4) while achieving a roughly 2.3* speedup. On a small set of pre-existing cross-lingual sign data, we find similar improvements for our proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes direct sign-to-sign (S2S) translation between ASL, CSL, and DGS by using back-translation on unaligned sign-text corpora to synthesize parallel sign-sign pairs, then jointly training a single MBART-based model for both text-to-sign (T2S) and S2S tasks. It reports that this direct approach outperforms a cascaded sign-to-text + text-to-text + text-to-sign baseline on synthetic pairs with 20% lower DTW-aligned MPJPE, 50% higher BLEU-4 (after back-translating predictions to text), and 2.3× speedup, with similar trends on a small pre-existing cross-lingual sign dataset.
Significance. If the synthetic pairs faithfully preserve both geometric sign content and linguistic intent without systematic artifacts, the work could enable practical direct sign-language translation that avoids cascade error propagation, extra latency, and loss of visual-modality information, directly benefiting cross-lingual communication for DHH populations. The joint MBART training and reported speed-up are attractive engineering contributions, but the significance is conditional on independent verification that performance gains are not artifacts of the back-translation process.
major comments (3)
- [Abstract] Abstract: the language-matching claim (50% higher BLEU-4) is obtained by translating predicted sign utterances back to text before scoring. This re-introduces the text modality the method is designed to bypass and creates partial circularity in the metric, even though the geometric DTW-aligned MPJPE remains independent.
- [Synthetic data generation] Synthetic data generation (described in the abstract and method): no validation of back-translation quality is reported (e.g., human semantic-equivalence ratings or geometric consistency checks on the generated sign-sign pairs themselves). Without such checks, the 20% MPJPE reduction and BLEU gains could arise from artifacts or simplifications in the synthetic pairs that the joint T2S+S2S model exploits while the cascade does not.
- [Experiments] Experiments section: results are presented without error bars, statistical significance tests, or ablations on the synthetic-data generation process (including the back-translation sampling temperature listed as a free parameter). This leaves the robustness of the central outperformance claim difficult to assess.
minor comments (2)
- [Abstract] Abstract: '50% high BLEU-4' appears to be a typo and should read '50% higher BLEU-4'.
- [Abstract] Abstract: '2.3* speedup' should be written as '2.3× speedup' for typographic clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address each of the major comments point by point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the language-matching claim (50% higher BLEU-4) is obtained by translating predicted sign utterances back to text before scoring. This re-introduces the text modality the method is designed to bypass and creates partial circularity in the metric, even though the geometric DTW-aligned MPJPE remains independent.
Authors: We concur that relying on back-translation to text for the BLEU-4 score does reintroduce the text modality and introduces a degree of circularity in that particular metric. The geometric evaluation via DTW-aligned MPJPE is independent of text and demonstrates a clear 20% improvement for the direct method. In the revised manuscript, we will update the abstract to emphasize the geometric metric as the primary result and provide additional clarification on the evaluation procedure for language matching. We view this as a partial revision to better frame the claims. revision: partial
-
Referee: [Synthetic data generation] Synthetic data generation (described in the abstract and method): no validation of back-translation quality is reported (e.g., human semantic-equivalence ratings or geometric consistency checks on the generated sign-sign pairs themselves). Without such checks, the 20% MPJPE reduction and BLEU gains could arise from artifacts or simplifications in the synthetic pairs that the joint T2S+S2S model exploits while the cascade does not.
Authors: The referee is correct that we did not report any validation of the synthetic sign-sign pairs, such as human ratings for semantic equivalence or checks for geometric consistency. This omission means we cannot fully exclude the possibility that the performance gains are due to artifacts in the synthetic data. We will revise the manuscript to include a limitations section discussing this issue and add qualitative examples of the generated pairs along with any available consistency metrics. However, comprehensive human evaluations are resource-intensive and not included in this revision. revision: partial
-
Referee: [Experiments] Experiments section: results are presented without error bars, statistical significance tests, or ablations on the synthetic-data generation process (including the back-translation sampling temperature listed as a free parameter). This leaves the robustness of the central outperformance claim difficult to assess.
Authors: We agree that the lack of error bars, statistical tests, and ablations on parameters like the back-translation sampling temperature weakens the assessment of result robustness. We will incorporate error bars from multiple training runs, conduct statistical significance tests where appropriate, and add ablations varying the sampling temperature to the experiments section. These changes will be made in the revised version. revision: yes
- Comprehensive human semantic-equivalence ratings for the synthetic sign-sign pairs would require recruiting qualified sign language interpreters or native signers for annotation, which is not feasible within the timeline and resources available for this revision.
Circularity Check
No circularity detected in empirical sign-to-sign translation method
full rationale
The paper presents an applied empirical pipeline: back-translation generates synthetic sign-sign pairs from unaligned sign-text corpora, a single MBART model is jointly trained for T2S and S2S, and performance is measured via independent geometric metrics (DTW-aligned MPJPE) plus BLEU after an auxiliary sign-to-text step. No mathematical derivation, first-principles result, or equation chain is claimed that reduces to its own inputs by construction. No parameters are fitted on a subset and then relabeled as predictions, no self-citation load-bearing uniqueness theorems appear, and no ansatz is smuggled via prior work. The evaluation choices and data-generation technique are standard in machine translation and do not create self-definitional or tautological equivalences; results are reported as experimental outcomes on held-out synthetic and pre-existing sets.
Axiom & Free-Parameter Ledger
free parameters (1)
- back-translation sampling temperature
axioms (1)
- domain assumption Back-translation from unaligned sign-text corpora produces pairs whose visual content is faithful enough for downstream training.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use back-translation to produce synthetic sign-sign pairs from unaligned individual language utterance-sign corpora... jointly train a single MBART-based model for both T2S and S2S
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
On synthetically generated paired sets... 20% lower DTW-aligned MPJPE... 50% higher BLEU-4
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Neural sign language translation
Necati Cihan Camgöz, Simon Hadfield, Oscar Koller, Hermann Ney, and Richard Bowden. Neural sign language translation. InCVPR, pages 7784–7793, 2018
work page 2018
-
[2]
Sign language transformers: Joint end-to-end sign language recognition and translation
Necati Cihan Camgöz, Oscar Koller, Simon Hadfield, and Richard Bowden. Sign language transformers: Joint end-to-end sign language recognition and translation. InCVPR, pages 10023–10033, 2020
work page 2020
-
[3]
No Language Left Behind: Scaling Human-Centered Machine Translation
Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, et al. No language left behind: Scaling human-centered machine translation.arXiv:2207.04672, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Mathieu De Coster, Dimitar Shterionov, Mieke Van Herreweghe, and Joni Dambre. Machine translation from signed to spoken languages: State of the art and challenges.Universal Access in the Information Society, pages 1–27, 2023
work page 2023
-
[5]
How2Sign: A large-scale multimodal dataset for continuous american sign language
Amanda Duarte, Shruti Palaskar, Lucas Ventura, Deepti Ghadiyaram, Kenneth DeHaan, Florian Metze, Jordi Torres, and Xavier Giró-i Nieto. How2Sign: A large-scale multimodal dataset for continuous american sign language. InCVPR, 2021
work page 2021
-
[6]
Understanding back-translation at scale
Sergey Edunov, Myle Ott, Michael Auli, and David Grangier. Understanding back-translation at scale. In EMNLP, 2018
work page 2018
-
[7]
TranslateGemma technical report.arXiv:2601.09012, 2026
Mara Finkelstein, Isaac Caswell, Tobias Domhan, Jan-Thorsten Peter, Juraj Juraska, Parker Riley, Daniel Deutsch, Cole Dilanni, Colin Cherry, Eleftheria Briakou, Elizabeth Nielsen, Jiaming Luo, Sweta Agrawal, Wenda Xu, Erin Kats, Stephane Jaskiewicz, Markus Freitag, and David Vilar. TranslateGemma technical report.arXiv:2601.09012, 2026
-
[8]
Alex Graves, Santiago Fernández, Faustino Gomez, and Jürgen Schmidhuber. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. InICML, pages 369–376, 2006
work page 2006
-
[9]
Shester Gueuwou, Sophie Siake, Colin Leong, and Mathias Müller. JWSign: A highly multilingual corpus of bible translations for more diversity in sign language processing. InFindings of EMNLP, pages 9907–9927, 2023
work page 2023
-
[10]
Mert Inan, Yang Zhong, Vidya Ganesh, and Malihe Alikhani. How to align multiple signed language corpora for better sign-to-sign translations? InProceedings of NAACL-HLT (Long Papers), pages 4003– 4016, 2025. doi: 10.18653/v1/2025.naacl-long.202
-
[11]
Direct speech-to-speech translation with a sequence-to-sequence model.Interspeech, 2019
Ye Jia, Ron J Weiss, Fadi Biadsy, Wolfgang Macherey, Melvin Johnson, Zhifeng Chen, and Yonghui Wu. Direct speech-to-speech translation with a sequence-to-sequence model.Interspeech, 2019
work page 2019
-
[12]
Translatotron 2: High-quality direct speech-to-speech translation with voice preservation.ICML, 2022
Ye Jia, Michelle Tadmor Ramanovich, Tal Remez, and Roi Pomerantz. Translatotron 2: High-quality direct speech-to-speech translation with voice preservation.ICML, 2022
work page 2022
-
[13]
Machine translation between spoken languages and signed languages represented in SignWriting
Zifan Jiang, Amit Moryossef, Mathias Müller, and Sarah Ebling. Machine translation between spoken languages and signed languages represented in SignWriting. InFindings of EACL, pages 1706–1724, 2023
work page 2023
-
[14]
Meaningful pose-based sign language evaluation
Zifan Jiang, Colin Leong, Amit Moryossef, Oliver Cory, Maksym Ivashechkin, Neha Tarigopula, Biao Zhang, Anne Göhring, Annette Rios, Rico Sennrich, and Sarah Ebling. Meaningful pose-based sign language evaluation. InProceedings of the Tenth Conference on Machine Translation (WMT), pages 64–80, 2025
work page 2025
-
[15]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InICLR, 2015
work page 2015
-
[16]
Gloss-free end-to-end sign language translation
Kezhou Lin, Xiaohan Wang, Linchao Zhu, Ke Sun, Bang Zhang, and Yi Yang. Gloss-free end-to-end sign language translation. InACL, pages 12904–12916, 2023
work page 2023
-
[17]
Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. Multilingual denoising pre-training for neural machine translation.Transactions of the Association for Computational Linguistics, 8:726–742, 2020. 10
work page 2020
-
[18]
Data augmentation for sign language gloss translation
Amit Moryossef, Kayo Yin, Graham Neubig, and Yoav Goldberg. Data augmentation for sign language gloss translation. InWorkshop on Automatic Translation for Signed and Spoken Languages (AT4SSL), pages 1–11, 2021
work page 2021
-
[19]
Findings of the second WMT shared task on sign language translation (WMT-SLT23)
Mathias Müller, Malihe Alikhani, Eleftherios Avramidis, Richard Bowden, Annelies Braffort, Necati Cihan Camgöz, Sarah Ebling, Cristina España-Bonet, Anne Göhring, Roman Grundkiewicz, Mert Inan, Zifan Jiang, Oscar Koller, Amit Moryossef, Annette Rios, Dimitar Shterionov, Sandra Sidler-Miserez, Katja Tissi, and Davy Van Landuyt. Findings of the second WMT s...
work page 2023
-
[20]
BLEU: A method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. BLEU: A method for automatic evaluation of machine translation. InACL, 2002
work page 2002
-
[21]
A call for clarity in reporting BLEU scores
Matt Post. A call for clarity in reporting BLEU scores. InConference on Machine Translation, 2018
work page 2018
-
[22]
Qwen Team. Qwen3 technical report.arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. InEMNLP, 2019
work page 2019
-
[24]
AudioPaLM: A Large Language Model That Can Speak and Listen
Paul K. Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, et al. AudioPaLM: A large language model that can speak and listen.arXiv:2306.12925, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Progressive transformers for end-to-end sign language production
Ben Saunders, Necati Cihan Camgöz, and Richard Bowden. Progressive transformers for end-to-end sign language production. InECCV, pages 687–705, 2020
work page 2020
-
[26]
Mixed SIGNals: Sign language production via a mixture of motion primitives
Ben Saunders, Necati Cihan Camgöz, and Richard Bowden. Mixed SIGNals: Sign language production via a mixture of motion primitives. InICCV, pages 1919–1929, 2021
work page 1919
-
[27]
Improving neural machine translation models with monolingual data
Rico Sennrich, Barry Haddow, and Alexandra Birch. Improving neural machine translation models with monolingual data. InACL, 2016
work page 2016
-
[28]
Sign language production using neural machine translation and generative adversarial networks
Stephanie Stoll, Necati Cihan Camgöz, Simon Hadfield, and Richard Bowden. Sign language production using neural machine translation and generative adversarial networks. InBMVC, 2018
work page 2018
-
[29]
Neural discrete representation learning
Aäron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. In NeurIPS, 2017
work page 2017
-
[30]
MLSLT: Towards multilingual sign language translation
Aoxiong Yin, Zhou Zhao, Weike Jin, Meng Zhang, Xingshan Zeng, and Xiaofei He. MLSLT: Towards multilingual sign language translation. InCVPR, pages 5109–5119, 2022
work page 2022
-
[31]
Better sign language translation with STMC-transformer
Kayo Yin and Jesse Read. Better sign language translation with STMC-transformer. InCOLING, pages 5975–5989, 2020
work page 2020
-
[32]
Including signed languages in natural language processing
Kayo Yin, Amit Moryossef, Julie Hochgesang, Yoav Goldberg, and Malihe Alikhani. Including signed languages in natural language processing. InACL-IJCNLP, pages 7347–7360, 2021
work page 2021
-
[33]
Neural sign language synthesis: Words are our glosses
Jan Zelinka and Jakub Kanis. Neural sign language synthesis: Words are our glosses. InWACV, pages 3384–3392, 2020
work page 2020
-
[34]
Improving sign language translation with monolingual data by sign back-translation
Hao Zhou, Wengang Zhou, Weizhen Qi, Junfu Pu, and Houqiang Li. Improving sign language translation with monolingual data by sign back-translation. InCVPR, pages 1316–1325, 2021
work page 2021
-
[35]
Signs as tokens: A retrieval-enhanced multilingual sign language generator
Ronglai Zuo, Rolandos Alexandros Potamias, Evangelos Ververas, Jiankang Deng, and Stefanos Zafeiriou. Signs as tokens: A retrieval-enhanced multilingual sign language generator. InICCV, 2025. 11
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.