Self-Training Doesn't Flatten Language -- It Restructures It: Surface Markers Amplify While Deep Syntax Dies
Pith reviewed 2026-05-21 05:42 UTC · model grok-4.3
The pith
Self-training on model outputs restructures language by syntactic depth rather than flattening it uniformly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
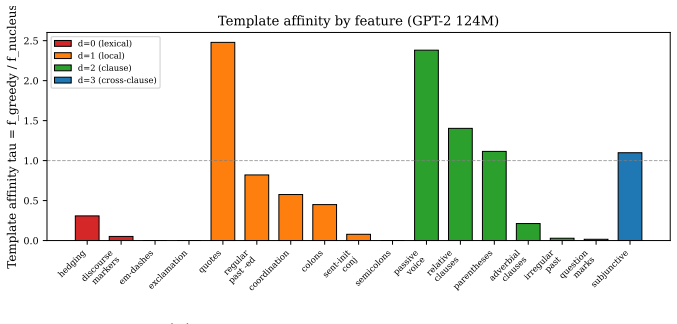
The Structural Depth Hypothesis states that the per-generation decay rate of a linguistic feature during successive self-training is predicted primarily by its structural depth—the number of nested syntactic dependencies it requires—and only secondarily by its generation-zero output frequency. Tracking 17 features over eleven generations in five models from three architecture families yields a pooled Spearman rho of 0.540 for depth versus 0.225 for frequency, while a matched human-text fine-tuning control yields rho near zero.
What carries the argument
The Structural Depth Hypothesis, which predicts feature decay rates in self-training from the count of nested syntactic dependencies a feature requires.
If this is right
- Aggregate complexity proxies such as dependency tree depth, type-token ratio, and word length all rise even as clause structure collapses.
- The resulting text carries rising superficial complexity alongside eroding deep syntax.
- Training-data curation must account for this depth-driven restructuring to preserve syntactic variety.
- LLM-text detection methods may need adjustment to track depth-specific markers rather than overall complexity.
Where Pith is reading between the lines
- If the pattern holds, repeated self-training cycles could gradually erode a model's capacity for complex clause embedding in ways simple diversity metrics miss.
- The depth-based decay might appear in other iterative regimes such as reinforcement learning from model feedback, suggesting a broader test across training loops.
- Explicit interventions during self-training could be designed to protect high-depth structures and slow the observed collapse.
Load-bearing premise
That the 17 linguistic features can be reliably assigned structural depth values based on nested syntactic dependencies in a manner independent of the self-training process.
What would settle it
Finding that frequency predicts per-generation decay rates at least as strongly as structural depth in a replication with additional models or a broader feature set would undermine the primary role assigned to depth.
Figures






read the original abstract
Successive self-training on a language model's own outputs is widely characterized as a process of flattening: diversity drops, distributions narrow, and the text becomes "more like itself." We provide evidence that this characterization is incomplete. Across eleven generations of self-training on five models (GPT-2 124M, Pythia-410M, Pythia-1.4B, OPT-1.3B, Pythia-2.8B), language is not flattened uniformly -- it is restructured. Surface markers (discourse connectives, hedges, em-dashes) rise, while mid- and deep-syntactic structures (questions, parentheticals, passives, subjunctives) collapse. We formalize this asymmetric collapse as the Structural Depth Hypothesis (SDH): the per-generation decay rate of a linguistic feature is predicted primarily by its structural depth -- the number of nested syntactic dependencies it requires -- and only secondarily by its generation-zero output frequency. Pooling 17-feature panels from five models spanning three architecture families (N=85), the pooled Spearman correlation is rho=0.540 (p < 10^{-6}; cluster-bootstrap 95% CI [0.434, 0.634]), while frequency is a substantially weaker predictor (rho=0.225). A matched human-text fine-tuning control yields rho=0.039 (p=0.88), confirming the gradient is self-training-specific. We further document a Superficial Complexity Paradox: aggregate complexity proxies (dep-tree depth, TTR, word length) all rise as the underlying clause structure dies, with direct implications for training-data curation and LLM-text detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that successive self-training on language models does not produce uniform flattening but instead restructures linguistic output: surface markers (e.g., discourse connectives, hedges) increase while mid- and deep-syntactic structures (questions, passives, subjunctives) decay. This is formalized as the Structural Depth Hypothesis (SDH), which posits that per-generation decay rates are predicted primarily by a feature's structural depth (number of nested syntactic dependencies) and only secondarily by its generation-zero frequency. Evidence consists of pooled Spearman correlations across 17 features and five models (N=85) yielding rho=0.540 for depth versus rho=0.225 for frequency, with a human-text fine-tuning control showing rho=0.039; aggregate complexity proxies are also shown to rise despite underlying structural collapse.
Significance. If the SDH holds, the work offers a more precise account of self-training dynamics than the prevailing flattening narrative, with concrete implications for training-data curation and LLM-generated text detection. Strengths include the multi-model, multi-architecture replication, use of cluster-bootstrap confidence intervals, and an external human control that isolates self-training-specific effects. The result supplies falsifiable predictions about which features will decay under continued self-training.
major comments (2)
- [Methods / Feature Definition] The manuscript provides no explicit list of the 17 linguistic features nor the pre-specified rule set used to assign structural depth values (number of nested syntactic dependencies) to each. This assignment is load-bearing for the SDH claim and the reported rho=0.540 versus rho=0.225 contrast; without documented criteria, inter-annotator agreement, or evidence that assignments were made independently of observed decay trajectories, the correlation risks circularity.
- [Results / Correlation Analysis] It is unclear whether feature selection or depth labeling occurred before or after inspecting per-generation decay rates. The abstract and results report a pooled analysis but do not describe pre-registration, blinding, or a hold-out procedure that would demonstrate the depth predictor was not tuned to the same data used to compute the correlations.
minor comments (2)
- [Abstract / Results] The abstract states eleven generations of self-training but the correlation analysis pools 17-feature panels without clarifying how many generations enter each per-feature decay-rate calculation or whether early-generation instability was excluded.
- [Discussion] The Superficial Complexity Paradox is introduced but the precise definitions of the aggregate proxies (dep-tree depth, TTR, word length) and their measurement across generations could be stated more explicitly to allow replication.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and detailed review, which has helped us strengthen the clarity and rigor of our presentation of the Structural Depth Hypothesis. Below we respond point-by-point to the major comments. We have revised the manuscript to address the concerns where possible.
read point-by-point responses
-
Referee: [Methods / Feature Definition] The manuscript provides no explicit list of the 17 linguistic features nor the pre-specified rule set used to assign structural depth values (number of nested syntactic dependencies) to each. This assignment is load-bearing for the SDH claim and the reported rho=0.540 versus rho=0.225 contrast; without documented criteria, inter-annotator agreement, or evidence that assignments were made independently of observed decay trajectories, the correlation risks circularity.
Authors: We agree that the absence of an explicit feature list and depth-assignment protocol is a significant omission that weakens the transparency of the SDH claim. The depth values were in fact assigned a priori using a syntactic-dependency criterion (counting the maximum number of nested clausal and phrasal dependencies required to realize the construction, drawing on standard treebank annotation guidelines) before any decay-rate analysis was performed. We have added a new Appendix A that lists all 17 features with precise extraction rules, the depth rubric with worked examples for each, and a brief justification for each depth score grounded in syntactic theory rather than observed frequencies or decay. We also note that formal inter-annotator agreement was not computed; this is now acknowledged as a limitation in the revised Methods. revision: yes
-
Referee: [Results / Correlation Analysis] It is unclear whether feature selection or depth labeling occurred before or after inspecting per-generation decay rates. The abstract and results report a pooled analysis but do not describe pre-registration, blinding, or a hold-out procedure that would demonstrate the depth predictor was not tuned to the same data used to compute the correlations.
Authors: Feature selection was guided by prior literature on syntactic complexity and was finalized before the self-training runs and decay measurements began. Depth labeling followed the same pre-specified syntactic rubric. However, the study was not pre-registered and no blinding or hold-out validation of the depth predictor was performed. We have inserted a new paragraph in the Methods section that explicitly states the chronological order of decisions and acknowledges the lack of pre-registration. As an additional safeguard, we now report a supplementary analysis restricted to a theoretically motivated subset of six features whose depth assignments were made without reference to any empirical decay data; the depth–decay correlation remains significant in this reduced set. revision: partial
Circularity Check
No circularity: empirical correlations rest on independent linguistic depth assignments and external controls.
full rationale
The paper's central claim is the Structural Depth Hypothesis, supported by pooled Spearman correlations (rho=0.540 for depth vs. rho=0.225 for frequency) computed across observed decay rates of 17 features in self-training trajectories from five models, plus a matched human-text fine-tuning control. These are statistical results on measured quantities rather than a derivation that reduces by construction to its inputs. Depth is defined via the number of nested syntactic dependencies as a pre-specified linguistic criterion, with no equations or steps shown that equate the predictor to the outcome or rename a fitted parameter as a prediction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way that would make the result equivalent to the input data by definition. The analysis is therefore self-contained against the reported empirical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linguistic features can be classified by structural depth according to the number of nested syntactic dependencies they require.
Reference graph
Works this paper leans on
- [1]
-
[2]
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O'Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, and 1 others. 2023. Pythia: A suite for analyzing large language models across training and scaling
work page 2023
- [3]
-
[4]
Elvis Dohmatob, Yunzhen Feng, Pin-Yu Yang, Fran c ois Charton, and Julia Kempe. 2024. A tale of tails: Model collapse as a change of scaling laws. In International Conference on Machine Learning (ICML)
work page 2024
-
[5]
Bruce Fraser. 1999. What are discourse markers? Journal of Pragmatics, 31(7):931--952
work page 1999
-
[6]
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, and 1 others. 2020. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[7]
Matthias Gerstgrasser, Rylan Schaeffer, Apratim Dey, Rafael Rafailov, Henry Sleight, John Hughes, Tomasz Korbak, Rajashree Agrawal, Dhruv Nie, Mankun Tan, and 1 others. 2024. Is model collapse inevitable? breaking the curse of recursion by accumulating real and synthetic data. In International Conference on Machine Learning (ICML)
work page 2024
-
[8]
Edward Gibson. 2000. The dependency locality theory: A distance-based theory of linguistic complexity. Image, Language, Brain, pages 95--126
work page 2000
-
[9]
Alla Grigoreva, Catherine Stinson, and Derek Muise. 2025. Analysis of linguistic effects of self-consuming training. In IEEE International Conference on Foundation and Large Language Models (FLLM)
work page 2025
-
[10]
Yanzhu Guo, Guokan Shang, Michalis Vazirgiannis, and Chlo \'e Clavel. 2024. The curious decline of linguistic diversity: Training language models on generated text. In Findings of the Association for Computational Linguistics: NAACL
work page 2024
-
[11]
John Hale. 2001. A probabilistic earley parser as a psycholinguistic model. In Proceedings of NAACL, pages 159--166
work page 2001
- [12]
-
[13]
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The curious case of neural text degeneration. In International Conference on Learning Representations
work page 2020
-
[14]
Tom Juzek and Adrian Ward. 2025. Why does chatgpt ``delve'' so much? exploring the sources of lexical overrepresentation in large language models. In COLING
work page 2025
-
[15]
Dmitry Kobak, Rita Gonz \'a lez-M \'a rquez, Em o ke- \'A gnes Horv \'a t, and Jan Lause. 2025. Delving into llm-assisted writing in biomedical publications through excess vocabulary. Science Advances
work page 2025
-
[16]
Roger Levy. 2008. Expectation-based syntactic comprehension. Cognition, 106(3):1126--1177
work page 2008
-
[17]
Weixin Liang and 1 others. 2024. Monitoring ai-modified content at scale: A case study on the impact of chatgpt on ai conference peer reviews. In International Conference on Machine Learning (ICML)
work page 2024
-
[18]
Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D Manning, and Chelsea Finn. 2023. Detectgpt: Zero-shot machine-generated text detection using probability curvature. In International Conference on Machine Learning (ICML)
work page 2023
-
[19]
Vishakh Padmakumar and He He. 2024. Does writing with language models reduce content diversity? In International Conference on Learning Representations (ICLR)
work page 2024
-
[20]
Jared C. Peterson and Paul Christiano. 2025. Knowledge collapse in language models. arXiv preprint arXiv:2509.04796
-
[21]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners
work page 2019
- [22]
-
[23]
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. 2024. Ai models collapse when trained on recursively generated data. Nature, 631:755--759
work page 2024
- [24]
- [25]
-
[26]
Eva Vanmassenhove. 2025. Losing our tail, again: (un)natural selection & multilingual llms. arXiv preprint arXiv:2507.03933
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Sean Welleck, Ilia Kulikov, Stephen Roller, Emily Dinan, Kyunghyun Cho, and Jason Weston. 2020. Neural text generation with unlikelihood training. In International Conference on Learning Representations
work page 2020
-
[28]
Yiwei Wu and 1 others. 2024. A corpus-based multidimensional analysis of linguistic features between human and chatgpt text. Applied Linguistics
work page 2024
- [29]
-
[30]
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, and 1 others. 2022. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.