ELSA: An ELastic SNN Inference Architecture for Efficient Neuromorphic Computing
Pith reviewed 2026-05-21 02:18 UTC · model grok-4.3
The pith
ELSA realizes true elastic inference in spiking neural networks by forwarding each spine or token immediately in a fine-grained pipeline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
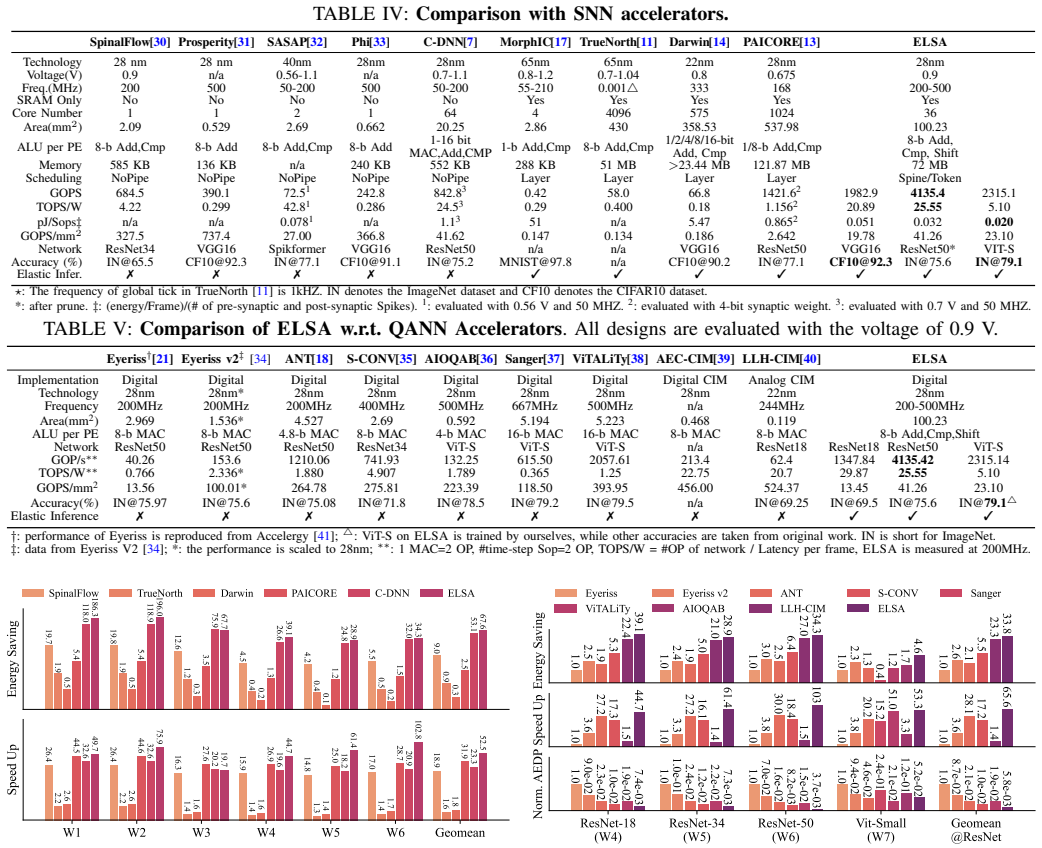
The paper claims that a near-SRAM dataflow architecture equipped with a fine-grained spine/token-wise pipeline realizes true elastic inference by forwarding each spine or token immediately upon production, forming a continuous streaming pipeline that cuts latency to the first response; bundled address-event representation and mini-batch spiking Gustavson-product optimizations further reduce communication and memory costs, yielding 3.4× speedup and 13.6× energy-efficiency improvement over the SOTA QANN accelerator ANT together with 2.9× speedup and 22.1× energy-efficiency improvement over the SOTA SNN accelerator PAICORE for a 4-bit ResNet-50 at unchanged accuracy.
What carries the argument
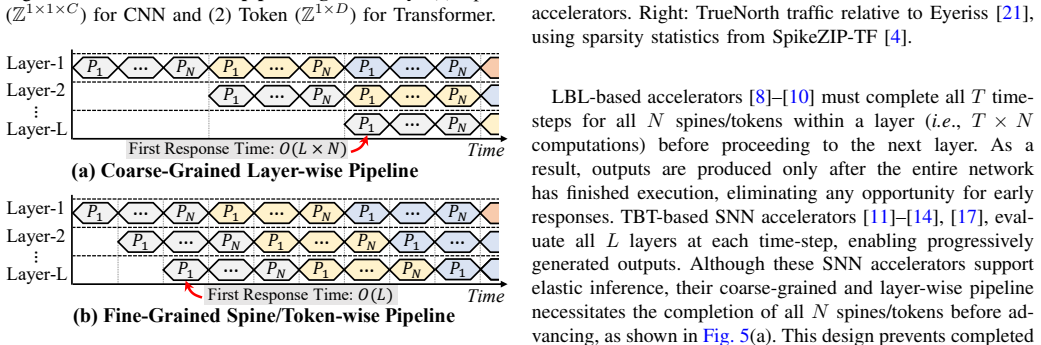
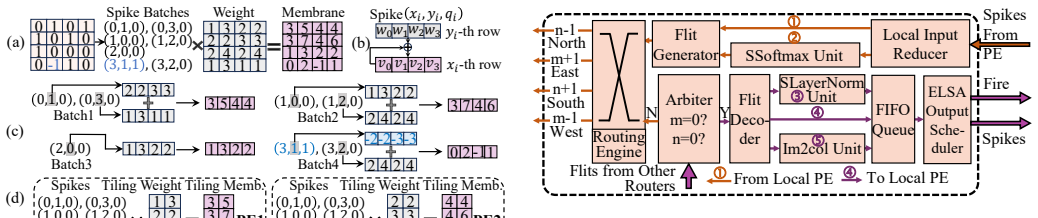
Fine-grained spine/token-wise pipeline inside a near-SRAM dataflow architecture that enables immediate forwarding of partial results to capture elastic inference.
If this is right
- SNNs produce usable outputs at the earliest possible moment rather than only after every layer finishes.
- Neuromorphic accelerators can exceed both quantized ANN accelerators and earlier SNN accelerators in latency and energy efficiency.
- Event-driven computation becomes practical without accuracy loss when mapping and scheduling match the fine-grained pipeline.
- Bundled AER and sparse Gustavson-product techniques cut NoC traffic and memory accesses while keeping the streaming flow intact.
Where Pith is reading between the lines
- Real-time neuromorphic systems could react to changing inputs at the moment the first reliable spikes appear rather than after fixed latency.
- The same immediate-forwarding principle might be applied to other sparse, event-driven models to shorten decision latency in edge devices.
- Dynamic depth adjustment becomes feasible if the pipeline naturally stops once confidence reaches a threshold.
Load-bearing premise
A fine-grained spine or token-wise pipeline can be built in hardware with negligible synchronization and communication overhead while still preserving the elastic property and accuracy.
What would settle it
Hardware measurements that compare actual time-to-first-output and total energy of an ELSA-style spine-wise pipeline against a conventional layer-wise or coarse time-step pipeline on the same SNN workload.
Figures
















read the original abstract
Spiking neural networks (SNNs) exploit event-driven and addition-only computation to substantially improve efficiency for intelligent computation. A key temporal property of SNNs, elastic inference, allows outputs to emerge progressively, enabling responses to salient inputs much earlier than full evaluation. However, existing SNN-specific accelerators cannot capitalize on this property. Layer-by-layer designs emit outputs only after all layers are complete, while time-step-by-time-step designs rely on coarse-grained, layer-wise pipelines that require synchronizing all spines/tokens within a layer. This barrier prevents results from being forwarded immediately, delaying the earliest possible response and forfeiting the benefits of elastic inference. To address these challenges, we propose ELSA, a near-SRAM dataflow architecture that realizes true elastic inference through a fine-grained spine/token-wise pipeline and hardware optimizations tailored to SNNs. ELSA forwards each spine/token immediately upon production, forming a continuous streaming pipeline that substantially reduces the latency to the first response. To enhance this lightweight execution, ELSA introduces a bundled address event representation protocol to lower communication traffic of network-on-chip (NoC), and leverages mini-batch spiking Gustavson-product to cut memory access and exploit inherent sparsity. Combined with mapping and scheduling optimizations, ELSA achieves efficient, event-driven computation without compromising accuracy. Experiments show that SNNs can outperform quantized artificial neural networks (QANNs) while maintaining on-par accuracy. For a 4-bit ResNet-50, ELSA achieves 3.4$\times$ speedup and 13.6$\times$ higher energy efficiency over the SOTA QANN accelerator (ANT), and 2.9$\times$ speedup and 22.1$\times$ energy efficiency gains over the SOTA SNN accelerator (PAICORE).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ELSA, an ELastic SNN Inference Architecture that uses a near-SRAM dataflow with a fine-grained spine/token-wise pipeline to enable immediate result forwarding for elastic inference in spiking neural networks. It introduces a bundled AER protocol to reduce NoC traffic and a mini-batch spiking Gustavson-product to optimize memory access and exploit sparsity. The central experimental claim is that for a 4-bit ResNet-50, ELSA provides 3.4× speedup and 13.6× energy efficiency improvement over the QANN accelerator ANT, and 2.9× speedup and 22.1× energy efficiency over the SNN accelerator PAICORE.
Significance. If the performance numbers are validated with detailed hardware modeling, this work could be significant for neuromorphic computing by demonstrating how to exploit elastic inference in hardware, potentially allowing SNNs to outperform QANNs in efficiency while maintaining accuracy. The approach addresses a key limitation in existing accelerators.
major comments (2)
- [Abstract and Experimental Results] The abstract reports specific speedup and energy efficiency numbers (3.4× and 13.6× over ANT; 2.9× and 22.1× over PAICORE) for 4-bit ResNet-50, but the manuscript provides no details on simulation methodology, error bars, dataset splits, or verification steps. This weakens the support for the central performance claims and the assertion that the fine-grained pipeline delivers these gains without hidden synchronization costs.
- [Architecture Design] The fine-grained spine/token-wise pipeline is presented as enabling immediate forwarding with negligible overhead, yet there is no cycle-accurate breakdown of inter-spine synchronization stalls, token reordering buffers, or NoC hop latency under this schedule. If these costs scale, the latency to first response and thus the elastic-inference advantage would be reduced, directly impacting the headline comparisons.
minor comments (1)
- [Abstract] Consider adding a short statement on the accuracy maintenance or datasets used to support the 'without compromising accuracy' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to provide the requested details and analysis.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] The abstract reports specific speedup and energy efficiency numbers (3.4× and 13.6× over ANT; 2.9× and 22.1× over PAICORE) for 4-bit ResNet-50, but the manuscript provides no details on simulation methodology, error bars, dataset splits, or verification steps. This weakens the support for the central performance claims and the assertion that the fine-grained pipeline delivers these gains without hidden synchronization costs.
Authors: We agree that the manuscript would benefit from expanded details on the experimental methodology to better support the reported performance numbers. In the revised version, we will add a dedicated subsection describing the cycle-accurate simulation framework (derived from our RTL implementation), the ImageNet dataset splits and preprocessing used for ResNet-50, verification steps including cross-validation against software models, and error bars from repeated runs. We will also include additional analysis quantifying synchronization overheads in the fine-grained pipeline to confirm that they do not materially affect the elastic-inference latency gains. revision: yes
-
Referee: [Architecture Design] The fine-grained spine/token-wise pipeline is presented as enabling immediate forwarding with negligible overhead, yet there is no cycle-accurate breakdown of inter-spine synchronization stalls, token reordering buffers, or NoC hop latency under this schedule. If these costs scale, the latency to first response and thus the elastic-inference advantage would be reduced, directly impacting the headline comparisons.
Authors: We acknowledge the value of a more detailed cycle-accurate breakdown to substantiate the negligible-overhead claim. We will revise the architecture section to incorporate simulation results that break down inter-spine synchronization stalls, token reordering buffer occupancy and latency, and per-hop NoC costs under the spine/token-wise schedule. Our existing modeling indicates these components remain small relative to the overall pipeline benefits thanks to the bundled AER protocol and immediate forwarding, but the added data will allow readers to assess scalability directly. revision: yes
Circularity Check
No circularity: claims rest on proposed architecture and external benchmarks
full rationale
The manuscript presents an architectural proposal for a near-SRAM dataflow SNN accelerator (ELSA) that enables fine-grained spine/token-wise pipelining to realize elastic inference. All headline performance numbers (3.4× speedup, 13.6× energy efficiency vs. ANT; 2.9× and 22.1× vs. PAICORE) are stated as outcomes of hardware mapping, scheduling, and experimental evaluation rather than any closed-form derivation or fitted prediction. No equations, uniqueness theorems, or self-citations appear in the provided text that would reduce a claimed result to its own inputs by construction. The work is therefore self-contained against external benchmarks and implementation measurements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SNNs possess an elastic inference property that allows outputs to emerge progressively before full evaluation
Reference graph
Works this paper leans on
-
[1]
Optimal ann- snn conversion for high-accuracy and ultra-low-latency spiking neural networks,
T. Bu, W. Fang, J. Ding, P. Dai, Z. Yu, and T. Huang, “Optimal ann- snn conversion for high-accuracy and ultra-low-latency spiking neural networks,”arXiv preprint arXiv:2303.04347, 2023
-
[2]
Fast-snn: Fast spiking neural network by converting quantized ann,
Y . Hu, Q. Zheng, X. Jiang, and G. Pan, “Fast-snn: Fast spiking neural network by converting quantized ann,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
work page 2023
-
[3]
Spikformer: When spiking neural network meets transformer
Z. Zhou, Y . Zhu, C. He, Y . Wang, S. Yan, Y . Tian, and L. Yuan, “Spikformer: When spiking neural network meets transformer,”arXiv preprint arXiv:2209.15425, 2022
-
[4]
Spikezip- tf: Conversion is all you need for transformer-based snn,
K. You, Z. Xu, C. Nie, Z. Deng, X. Wang, Q. Guo, and Z. He, “Spikezip- tf: Conversion is all you need for transformer-based snn,” inForty-first International Conference on Machine Learning (ICML), 2024
work page 2024
-
[5]
Towards spike-based machine intelligence with neuromorphic computing,
K. Roy, A. Jaiswal, and P. Panda, “Towards spike-based machine intelligence with neuromorphic computing,”Nature, vol. 575, no. 7784, pp. 607–617, 2019
work page 2019
-
[6]
An energy-efficient unstructured sparsity-aware deep snn accelerator with 3-d computation array,
C. Fang, Z. Shen, Z. Wang, C. Wang, S. Zhao, F. Tian, J. Yang, and M. Sawan, “An energy-efficient unstructured sparsity-aware deep snn accelerator with 3-d computation array,”IEEE Journal of Solid-State Circuits, 2024
work page 2024
-
[7]
S. Kim, S. Kim, S. Hong, S. Kim, D. Han, J. Choi, and H.-J. Yoo, “C- dnn: An energy-efficient complementary deep-neural-network processor with heterogeneous cnn/snn core architecture,”IEEE Journal of Solid- State Circuits, vol. 59, no. 1, pp. 157–172, 2024
work page 2024
-
[8]
Sato: spiking neural network acceleration via temporal- oriented dataflow and architecture,
F. Liu, W. Zhao, Z. Wang, Y . Chen, T. Yang, Z. He, X. Yang, and L. Jiang, “Sato: spiking neural network acceleration via temporal- oriented dataflow and architecture,” inProceedings of the 59th ACM/IEEE Design Automation Conference, 2022, pp. 1105–1110
work page 2022
-
[9]
Loas: Fully temporal- parallel dataflow for dual-sparse spiking neural networks,
R. Yin, Y . Kim, D. Wu, and P. Panda, “Loas: Fully temporal- parallel dataflow for dual-sparse spiking neural networks,” in2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2024, pp. 1107–1121
work page 2024
-
[10]
Parallel time batching: Systolic- array acceleration of sparse spiking neural computation,
J.-J. Lee, W. Zhang, and P. Li, “Parallel time batching: Systolic- array acceleration of sparse spiking neural computation,” in2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2022, pp. 317–330
work page 2022
-
[11]
Truenorth: Design and tool flow of a 65 mw 1 million neuron programmable neurosynaptic chip,
F. Akopyan, J. Sawada, A. Cassidy, R. Alvarez-Icaza, J. Arthur, P. Merolla, N. Imam, Y . Nakamura, P. Datta, and G.-J. Nam, “Truenorth: Design and tool flow of a 65 mw 1 million neuron programmable neurosynaptic chip,”IEEE transactions on computer-aided design of integrated circuits and systems, vol. 34, no. 10, pp. 1537–1557, 2015
work page 2015
-
[12]
Loihi: A neuromorphic manycore processor with on-chip learning,
M. Davies, N. Srinivasa, T.-H. Lin, G. Chinya, Y . Cao, S. H. Choday, G. Dimou, P. Joshi, N. Imam, and S. Jain, “Loihi: A neuromorphic manycore processor with on-chip learning,”Ieee Micro, vol. 38, no. 1, pp. 82–99, 2018
work page 2018
-
[13]
Y . Zhong, Y . Kuang, K. Liu, Z. Wang, S. Feng, G. Chen, Y . Yang, X. Cui, Q. Wang, J. Cao, S. Jia, Y . Liang, G. Sun, X. Cui, R. Huang, and Y . Wang, “Paicore: A 1.9-million-neuron 5.181-tsops/w digital neuromorphic processor with unified snn-ann and on-chip learning paradigm,”IEEE Journal of Solid-State Circuits, vol. 60, no. 2, pp. 651–671, 2025
work page 2025
-
[14]
Darwin3: A large-scale neuromorphic chip with a novel isa and on-chip learning,
D. Ma, X. Jin, S. Sun, Y . Li, X. Wu, Y . Hu, F. Yang, H. Tang, X. Zhu, P. Lin, and G. Pan, “Darwin3: A large-scale neuromorphic chip with a novel isa and on-chip learning,” 2023. [Online]. Available: https://arxiv.org/abs/2312.17582
-
[15]
Speed of processing in the human visual system,
S. Thorpe, D. Fize, and C. Marlot, “Speed of processing in the human visual system,”nature, vol. 381, no. 6582, pp. 520–522, 1996
work page 1996
-
[16]
3d object detection for autonomous driving: A survey,
J. Mao, S. Shi, X. Wang, and H. Li, “3d object detection for autonomous driving: A survey,”Pattern Recognition, vol. 130, p. 108796, 2022
work page 2022
-
[17]
C. Frenkel, J.-D. Legat, and D. Bol, “Morphic: A 65-nm 738k- synapse/mm2 quad-core binary-weight digital neuromorphic processor with stochastic spike-driven online learning,”IEEE Transactions on Biomedical Circuits and Systems, vol. 13, no. 5, pp. 999–1010, 2019
work page 2019
-
[18]
Ant: Exploiting adaptive numerical data type for low-bit deep neural network quantization,
C. Guo, C. Zhang, J. Leng, Z. Liu, F. Yang, Y . Liu, M. Guo, and Y . Zhu, “Ant: Exploiting adaptive numerical data type for low-bit deep neural network quantization,” in2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO), 2022, pp. 1414–1433
work page 2022
-
[19]
R. Mao, L. Tang, X. Yuan, Y . Liu, and J. Zhou, “Stellar: Energy- efficient and low-latency snn algorithm and hardware co-design with spatiotemporal computation,” in2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2024, pp. 172–185
work page 2024
-
[20]
B. Han, G. Srinivasan, and K. Roy, “Rmp-snn: Residual membrane potential neuron for enabling deeper high-accuracy and low-latency spiking neural network,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 13 558–13 567
work page 2020
-
[21]
Eyeriss: An energy- efficient reconfigurable accelerator for deep convolutional neural net- works,
Y .-H. Chen, T. Krishna, J. S. Emer, and V . Sze, “Eyeriss: An energy- efficient reconfigurable accelerator for deep convolutional neural net- works,”IEEE Journal of Solid-State Circuits, vol. 52, no. 1, pp. 127– 138, 2017
work page 2017
-
[22]
G. Zhang, N. Attaluri, J. S. Emer, and D. Sanchez, “Gamma: leveraging gustavson’s algorithm to accelerate sparse matrix multiplication,” inProceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 687–701....
-
[23]
Simulation and analysis of network on chip architectures: ring, spidergon and 2d mesh,
L. Bononi and N. Concer, “Simulation and analysis of network on chip architectures: ring, spidergon and 2d mesh,” inProceedings of the Design Automation & Test in Europe Conference, vol. 2. IEEE, 2006, pp. 6–pp
work page 2006
-
[24]
Swifttron: An efficient hardware accelerator for quan- tized transformers,
A. Marchisio, D. Dura, M. Capra, M. Martina, G. Masera, and M. Shafique, “Swifttron: An efficient hardware accelerator for quan- tized transformers,” in2023 International Joint Conference on Neural Networks (IJCNN). IEEE, 2023, pp. 1–9
work page 2023
-
[25]
Y . Rong, X. Zhang, and J. Lin, “Modified hilbert curve for rectangles and cuboids and its application in entropy coding for image and video compression,”Entropy, vol. 23, no. 7, 2021. [Online]. Available: https://www.mdpi.com/1099-4300/23/7/836
work page 2021
-
[26]
Mapping very large scale spiking neuron network to neuromorphic hardware,
O. Jin, Q. Xing, Y . Li, S. Deng, S. He, and G. Pan, “Mapping very large scale spiking neuron network to neuromorphic hardware,” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ser. ASPLOS 2023. New York, NY , USA: Association for Computing Machinery, 2023, p. 419–4...
-
[27]
Dramsim3: A cycle-accurate, thermal-capable dram simulator,
S. Li, Z. Yang, D. Reddy, A. Srivastava, and B. Jacob, “Dramsim3: A cycle-accurate, thermal-capable dram simulator,”IEEE Computer Architecture Letters, vol. 19, no. 2, pp. 106–109, 2020
work page 2020
-
[28]
Highlights of the high-bandwidth memory (hbm) stan- dard,
M. O’Connor, “Highlights of the high-bandwidth memory (hbm) stan- dard,” inMemory forum workshop, vol. 3, 2014
work page 2014
-
[29]
C. Sun, C.-H. O. Chen, G. Kurian, L. Wei, J. Miller, A. Agarwal, L.-S. Peh, and V . Stojanovic, “Dsent - a tool connecting emerging photonics with electronics for opto-electronic networks-on-chip modeling,” in2012 IEEE/ACM Sixth International Symposium on Networks-on-Chip, 2012, pp. 201–210
work page 2012
-
[30]
Spinalflow: An architecture and dataflow tailored for spiking neural networks,
S. Narayanan, K. Taht, R. Balasubramonian, E. Giacomin, and P.- E. Gaillardon, “Spinalflow: An architecture and dataflow tailored for spiking neural networks,” in2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020, pp. 349– 362
work page 2020
-
[31]
Prosperity: Accelerating spiking neural networks via product sparsity,
C. Wei, C. Guo, F. Cheng, S. Li, H. F. Yang, H. H. Li, and Y . Chen, “Prosperity: Accelerating spiking neural networks via product sparsity,”
-
[32]
Available: https://arxiv.org/abs/2503.03379
[Online]. Available: https://arxiv.org/abs/2503.03379
-
[33]
C. Fang, Z. Shen, S. Zhao, C. Wang, F. Tian, J. Yang, and M. Sawan, “A 0.078 pj/sop unstructured sparsity-aware spiking attention/convolution processor with 3d compute array,” in2024 IEEE Custom Integrated Circuits Conference (CICC), 2024, pp. 1–2
work page 2024
-
[34]
Phi: Leveraging pattern-based hierarchical sparsity for high-efficiency spiking neural networks,
C. Wei, B. Duan, C. Guo, J. Zhang, Q. Song, H. H. Li, and Y . Chen, “Phi: Leveraging pattern-based hierarchical sparsity for high-efficiency spiking neural networks,” 2025. [Online]. Available: https://arxiv.org/abs/2505.10909
-
[35]
Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices,
Y .-H. Chen, T.-J. Yang, J. Emer, and V . Sze, “Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices,”IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 9, no. 2, pp. 292–308, 2019
work page 2019
-
[36]
W. Sun, X. Feng, C. Tang, S. Fan, Y . Yang, J. Yue, H. Yang, and Y . Liu, “A 28nm 2d/3d unified sparse convolution accelerator with block-wise neighbor searcher for large-scaled voxel-based point cloud network,” in 2023 IEEE International Solid-State Circuits Conference (ISSCC), 2023, pp. 328–330
work page 2023
-
[37]
A 28nm 343.5fps/w vision transformer accelerator with integer-only quantized attention block,
C.-C. Lin, W. Lu, P.-T. Huang, and H.-M. Chen, “A 28nm 343.5fps/w vision transformer accelerator with integer-only quantized attention block,” in2024 IEEE 6th International Conference on AI Circuits and Systems (AICAS), 2024, pp. 80–84. 15
work page 2024
-
[38]
Sanger: A co-design framework for enabling sparse attention using reconfigurable architecture,
L. Lu, Y . Jin, H. Bi, Z. Luo, P. Li, T. Wang, and Y . Liang, “Sanger: A co-design framework for enabling sparse attention using reconfigurable architecture,” inMICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 977–991. [Online]. Available: https:/...
-
[39]
J. Dass, S. Wu, H. Shi, C. Li, Z. Ye, Z. Wang, and Y . Lin, “Vitality: Unifying low-rank and sparse approximation for vision transformer acceleration with a linear taylor attention,” in2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2023, pp. 415–428
work page 2023
-
[40]
16.3 a 28nm 384kb 6t-sram computation-in-memory macro with 8b precision for ai edge chips,
J.-W. Su, Y .-C. Chou, R. Liu, T.-W. Liu, P.-J. Lu, P.-C. Wu, Y .-L. Chung, L.-Y . Hung, J.-S. Ren, T. Pan, S.-H. Li, S.-C. Chang, S.-S. Sheu, W.- C. Lo, C.-I. Wu, X. Si, C.-C. Lo, R.-S. Liu, C.-C. Hsieh, K.-T. Tang, and M.-F. Chang, “16.3 a 28nm 384kb 6t-sram computation-in-memory macro with 8b precision for ai edge chips,” in2021 IEEE International Soli...
work page 2021
-
[41]
A. Guo, X. Chen, F. Dong, J. Chen, Z. Yuan, X. Hu, Y . Zhang, J. Zhang, Y . Tang, Z. Zhang, G. Chen, D. Yang, Z. Zhang, L. Ren, T. Xiong, B. Wang, B. Liu, W. Shan, X. Liu, H. Cai, G. Sun, J. Yang, and X. Si, “34.3 a 22nm 64kb lightning-like hybrid computing-in-memory macro with a compressed adder tree and analog-storage quantizers for transformer and cnns...
work page 2024
-
[42]
J.-J. Lee and P. Li, “Reconfigurable dataflow optimization for spatiotem- poral spiking neural computation on systolic array accelerators,” in 2020 IEEE 38th International Conference on Computer Design (ICCD). IEEE, 2020, pp. 57–64
work page 2020
-
[43]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”CoRR, vol. abs/1409.1556, 2014. [Online]. Available: https://api.semanticscholar.org/CorpusID:14124313
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[44]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
work page 2016
-
[45]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” in9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenRevie...
work page 2021
-
[46]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” Tech. Rep., 2009
work page 2009
-
[47]
Cifar10-dvs: An event-stream dataset for object classification,
H. Li, H. Liu, X. Ji, G. Li, and L. Shi, “Cifar10-dvs: An event-stream dataset for object classification,”Frontiers in Neuroscience, vol. 11, 2017
work page 2017
-
[48]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
work page 2009
-
[49]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean conference on computer vision. Springer, 2014, pp. 740–755
work page 2014
-
[50]
The pascal visual object classes (voc) challenge,
M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisser- man, “The pascal visual object classes (voc) challenge,”International journal of computer vision, vol. 88, no. 2, pp. 303–338, 2010
work page 2010
-
[51]
Nvidia. Nvidia jetson agx orin 64 gb. 2021, Nov 09. [Online]. Available: https://www.techpowerup.com/gpu-specs/jetson-agx-orin-64-gb.c4085
work page 2021
-
[52]
NVIDIA. Nvidia a100. 2020, May 04. [Online]. Available: https://www.nvidia.cn/content/dam/en-zz/Solutions/Data-Center/a100/ pdf/ampere-a100-datasheet-a4-nvidia-1293124-r10-web-zhCN.pdf
work page 2020
-
[53]
N. Jouppi, G. Kurian, S. Li, P. Ma, R. Nagarajan, L. Nai, N. Patil, S. Subramanian, A. Swing, B. Towles, C. Young, X. Zhou, Z. Zhou, and D. A. Patterson, “Tpu v4: An optically reconfigurable supercomputer for machine learning with hardware support for embeddings,” inProceedings of the 50th Annual International Symposium on Computer Architecture, ser. ISCA...
-
[54]
Groq. Groqcard accelerator. 2022. [Online]. Available: https://groq. com/wp-content/uploads/2024/02
work page 2022
-
[55]
Seenn: Towards temporal spiking early-exit neural networks,
Y . Li, T. Geller, Y . Kim, and P. Panda, “Seenn: Towards temporal spiking early-exit neural networks,” 2023. [Online]. Available: https://arxiv.org/abs/2304.01230
-
[56]
Optimizing event-driven spiking neural network with regularization and cutoff,
D. Wu, G. Jin, H. Yu, X. Yi, and X. Huang, “Optimizing event-driven spiking neural network with regularization and cutoff,” Frontiers in Neuroscience, vol. 19, Feb. 2025. [Online]. Available: http://dx.doi.org/10.3389/fnins.2025.1522788
-
[57]
J. Chen, S. Park, and O. Simeone, “Knowing when to stop: Delay- adaptive spiking neural network classifiers with reliability guarantees,”
-
[58]
Available: https://arxiv.org/abs/2305.11322
[Online]. Available: https://arxiv.org/abs/2305.11322
-
[59]
You only look once: Unified, real-time object detection,
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 779– 788
work page 2016
-
[60]
Logic-based edram: Origins and rationale for use,
R. E. Matick and S. E. Schuster, “Logic-based edram: Origins and rationale for use,”IBM Journal of Research and Development, vol. 49, no. 1, pp. 145–165, 2005
work page 2005
-
[61]
A survey of architectural approaches for managing embedded dram and non-volatile on-chip caches,
S. Mittal, J. S. Vetter, and D. Li, “A survey of architectural approaches for managing embedded dram and non-volatile on-chip caches,”IEEE Transactions on Parallel and Distributed Systems, vol. 26, no. 6, pp. 1524–1537, 2014
work page 2014
-
[62]
A high-performance, high-density 28nm edram technology with high-k/metal-gate,
K. Huang, Y . Ting, C. Chang, K. Tu, K. Tzeng, H. Chu, C. Pai, A. Katoch, W. Kuo, K. Chenet al., “A high-performance, high-density 28nm edram technology with high-k/metal-gate,” in2011 International Electron Devices Meeting. IEEE, 2011, pp. 24–7
work page 2011
-
[63]
Bit fusion: Bit-level dynamically composable architecture for accelerating deep neural network,
H. Sharma, J. Park, N. Suda, L. Lai, B. Chau, J. K. Kim, V . Chandra, and H. Esmaeilzadeh, “Bit fusion: Bit-level dynamically composable architecture for accelerating deep neural network,” in2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), 2018, pp. 764–775
work page 2018
-
[64]
S. B. Furber, F. Galluppi, S. Temple, and L. A. Plana, “The spinnaker project,”Proceedings of the IEEE, vol. 102, no. 5, pp. 652–665, 2014
work page 2014
-
[65]
Matraptor: A sparse-sparse matrix multiplication accelerator based on row-wise product,
N. Srivastava, H. Jin, J. Liu, D. Albonesi, and Z. Zhang, “Matraptor: A sparse-sparse matrix multiplication accelerator based on row-wise product,” in2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2020, pp. 766–780
work page 2020
-
[66]
S. Lie, “Cerebras architecture deep dive: First look inside the hard- ware/software co-design for deep learning,”Ieee Micro, vol. 43, no. 3, pp. 18–30, 2023
work page 2023
-
[67]
C. Zou, Z. Wei, J. Y . Lee, C. Nie, K. You, and Z. He, “Polymorpic: Em- bedding polymorphic processing-in-cache in risc-v based processor for full-stack efficient ai inference,” in2025 58th IEEE/ACM International Symposium on Microarchitecture (MICRO), 2025
work page 2025
-
[68]
Vspim: Sram processing-in- memory dnn acceleration via vector-scalar operations,
C. Nie, C. Tang, J. Lin, H. Hu, C. Lv, T. Cao, W. Zhang, L. Jiang, X. Liang, W. Qian, Y . Sun, and Z. He, “Vspim: Sram processing-in- memory dnn acceleration via vector-scalar operations,”IEEE Transac- tions on Computers, vol. 73, no. 10, pp. 2378–2390, 2024
work page 2024
-
[69]
R. Fan, Y . Cui, Q. Chen, M. Wang, Y . Zhang, W. Zheng, and Z. Li, “Maicc: A lightweight many-core architecture with in-cache computing for multi-dnn parallel inference,” inProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 411–423. [Online...
-
[70]
Q. Liu, B. Gao, P. Yao, D. Wu, J. Chen, Y . Pang, W. Zhang, Y . Liao, C.-X. Xue, W.-H. Chenet al., “33.2 a fully integrated analog reram based 78.4 tops/w compute-in-memory chip with fully parallel mac com- puting,” in2020 IEEE International Solid-State Circuits Conference- (ISSCC). IEEE, 2020, pp. 500–502
work page 2020
-
[71]
Ir-qnn framework: An ir drop-aware offline training of quantized crossbar arrays,
M. E. Fouda, S. Lee, J. Lee, G. H. Kim, F. Kurdahi, and A. M. Eltawi, “Ir-qnn framework: An ir drop-aware offline training of quantized crossbar arrays,”IEEE Access, vol. 8, pp. 228 392–228 408, 2020
work page 2020
-
[72]
Rxnn: A framework for evaluating deep neural networks on resistive crossbars,
S. Jain, A. Sengupta, K. Roy, and A. Raghunathan, “Rxnn: A framework for evaluating deep neural networks on resistive crossbars,”IEEE Trans- actions on Computer-Aided Design of Integrated Circuits and Systems, vol. 40, no. 2, pp. 326–338, 2020
work page 2020
-
[73]
Spinnaker2: A large-scale neuromorphic system for event-based and asynchronous machine learning,
H. A. Gonzalez, J. Huang, F. Kelber, K. K. Nazeer, T. Langer, C. Liu, M. Lohrmann, A. Rostami, M. Sch¨one, B. V oggingeret al., “Spinnaker2: A large-scale neuromorphic system for event-based and asynchronous machine learning,”arXiv preprint arXiv:2401.04491, 2024
-
[74]
Intel builds world’s largest neuromorphic sys- tem to enable more sustainable ai,
Intel Newsroom, “Intel builds world’s largest neuromorphic sys- tem to enable more sustainable ai,” https://newsroom.intel.com/ artificial-intelligence, 2024, accessed: 2026-04-26
work page 2024
-
[75]
S. Hwang, D. Lee, J. Koo, and J. Kung, “Gustavsnn: Unleashing the power of gustavson’s algorithm on snn acceleration with column-parallel tick-batch dataflow,” in2026 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2026, pp. 1–14. 16
work page 2026
-
[76]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020. 17
work page internal anchor Pith review Pith/arXiv arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.