ArchSIBench: Benchmarking the Architectural Spatial Intelligence of Vision-Language Models
Pith reviewed 2026-05-21 04:52 UTC · model grok-4.3
The pith
Vision-Language Models show marked gaps from trained humans in understanding architectural spaces like layouts and transformations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
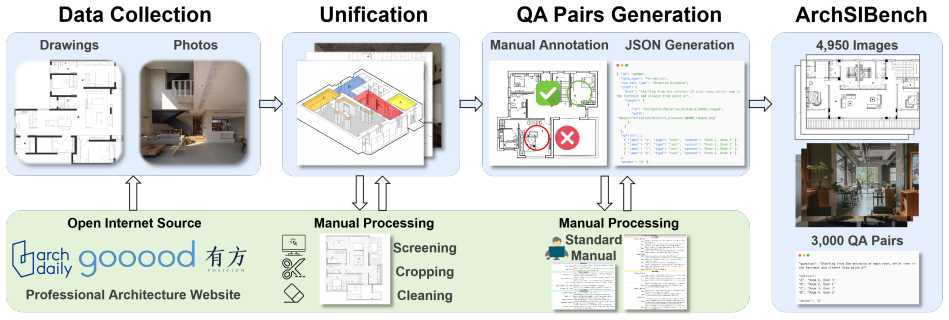
ArchSIBench is a benchmark for architectural spatial intelligence drawn from architecture, cognitive science, and psychology perspectives. It spans five core dimensions with seventeen fine-grained subtasks and three thousand question-answer pairs created through careful manual annotation by experts with architectural backgrounds. Evaluations of various vision-language models show that their architectural spatial intelligence exhibits significant differences from human baselines, along with substantial variability across capability dimensions. Some state-of-the-art models approach the performance of human evaluators without architectural training, yet a clear gap remains relative to human eva
What carries the argument
ArchSIBench, a benchmark with five dimensions and seventeen subtasks that measures higher-level architectural spatial cognition through three thousand expert-annotated QA pairs.
If this is right
- Most vision-language models exhibit substantial variability in performance across the five capability dimensions of perception, reasoning, navigation, transformation, and configuration.
- Some state-of-the-art models can approach the level of human evaluators who lack architectural training.
- A clear gap remains compared to human evaluators with architectural training, particularly in spatial transformation and configuration reasoning.
- The benchmark supplies systematic resources for measuring and advancing vision-language model capabilities in robot navigation, embodied interaction, and 3D scene understanding.
Where Pith is reading between the lines
- Developers might prioritize fine-tuning on transformation and configuration examples to reduce the observed gaps in embodied AI applications.
- Combining ArchSIBench results with existing basic spatial benchmarks could produce a fuller map of vision-language model strengths and weaknesses.
- Architectural firms or simulation platforms could adopt similar task sets to evaluate AI tools for virtual building walkthroughs or automated design review.
Load-bearing premise
The seventeen subtasks and three thousand question-answer pairs created by experts with architectural backgrounds provide a valid and comprehensive measure of higher-level architectural spatial cognition including layout understanding, circulation patterns, and functional zoning.
What would settle it
A new test showing that current vision-language models match or exceed the scores of human evaluators with architectural training on the spatial transformation and configuration subtasks would falsify the reported performance gaps.
Figures









read the original abstract
Architectural spatial intelligence, the ability to recognize and infer architectural space, is fundamental to tasks such as robot navigation, embodied interaction, and 3D scene understanding and generation. Although extensive research has evaluated the basic spatial skills of Vision-Language Models (VLMs) such as relative orientation, distance comparison, and object counting, these tasks cover only the most elementary levels of spatial cognition and largely overlook higher-level cognition of architectural space, including layout understanding, circulation patterns, and functional zoning. In this work, we present ArchSIBench, a Benchmark for Architectural Spatial Intelligence based on the perspectives from architecture, cognitive science, and psychology. ArchSIBench covers five core dimensions: perception, reasoning, navigation, transformation, and configuration, comprising 17 fine-grained subtasks. Through careful manual annotation by experts with architectural backgrounds, we construct 3,000 question-answer pairs to enable comprehensive evaluation of architectural spatial intelligence. Based on ArchSIBench, we evaluate various VLMs and find that the architectural spatial intelligence of most models shows significant differences from human baselines; additionally, models exhibit substantial variability across capability dimensions. Some state-of-the-art models can approach the level of human evaluators without architectural training. However, a clear gap remains compared to human evaluators with architectural training, particularly in spatial transformation and configuration reasoning. We believe that ArchSIBench will provide important insights and systematic resources for measuring and advancing the architectural spatial intelligence of VLMs. The dataset and code are available at https://huggingface.co/datasets/ArchSIBench/ArchSIBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ArchSIBench, a benchmark for architectural spatial intelligence in VLMs. It defines five dimensions (perception, reasoning, navigation, transformation, configuration) with 17 subtasks and 3,000 expert-annotated QA pairs drawn from architecture and cognitive science perspectives. Evaluation of multiple VLMs shows most models differ significantly from human baselines, with some SOTA models approaching performance of humans without architectural training but clear gaps remaining versus trained humans, especially in transformation and configuration reasoning.
Significance. If the subtasks validly isolate higher-level architectural cognition (layout, circulation, zoning) beyond generic visual or linguistic skills, the benchmark supplies a useful public resource for tracking progress in embodied AI and 3D understanding. The release of the dataset and code supports reproducibility.
major comments (2)
- [Benchmark Construction] Benchmark Construction section: No inter-annotator agreement statistics or external validation are reported for the 3,000 QA pairs. This is load-bearing for the central claim, because the reported gaps between VLMs and trained humans are only interpretable if the items genuinely require architectural expertise rather than surface-level spatial or linguistic cues.
- [Experiments] Experiments / Human Baseline subsection: Details on human evaluator recruitment, exact training levels, number of participants per subtask, and statistical tests for performance differences are not provided. Without these, the claim that models approach untrained humans but lag trained humans in transformation and configuration cannot be fully assessed.
minor comments (2)
- [Abstract] Abstract: The phrase 'significant differences' is used without reference to the specific metric (accuracy, normalized score) or effect size; this should be clarified for precision.
- [Results] Figure captions and tables: Ensure all subtasks are explicitly mapped to the five dimensions so readers can trace which capabilities drive the reported variability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and have revised the paper accordingly to improve transparency and rigor.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction section: No inter-annotator agreement statistics or external validation are reported for the 3,000 QA pairs. This is load-bearing for the central claim, because the reported gaps between VLMs and trained humans are only interpretable if the items genuinely require architectural expertise rather than surface-level spatial or linguistic cues.
Authors: We agree that quantitative validation strengthens the benchmark. In the revised Benchmark Construction section we now report inter-annotator agreement (Fleiss' kappa of 0.83 on a 20% overlap sample annotated independently by three experts) and describe an external validation step in which two additional licensed architects reviewed 300 randomly sampled QA pairs for architectural relevance, confirming that items target layout, circulation, and zoning rather than generic visual cues. These additions support the interpretability of the reported VLM-human gaps. revision: yes
-
Referee: [Experiments] Experiments / Human Baseline subsection: Details on human evaluator recruitment, exact training levels, number of participants per subtask, and statistical tests for performance differences are not provided. Without these, the claim that models approach untrained humans but lag trained humans in transformation and configuration cannot be fully assessed.
Authors: We accept that more granular reporting is required. The revised Human Baseline subsection now specifies recruitment (targeted outreach to architecture departments plus general-population crowdsourcing), training definitions (trained: minimum two years of formal architectural education or equivalent professional experience; untrained: none), participant counts (18 trained and 30 untrained evaluators, with 4–6 per subtask), and statistical tests (two-sample t-tests with Bonferroni correction showing p < 0.01 differences concentrated in transformation and configuration). These details allow fuller assessment of the performance claims. revision: yes
Circularity Check
Empirical benchmark creation with no derivations or self-referential predictions
full rationale
This paper presents ArchSIBench as a new dataset of 17 subtasks and 3000 expert-annotated QA pairs for evaluating VLMs on architectural spatial intelligence dimensions. All reported results consist of direct performance comparisons between models and external human baselines (with and without architectural training). No equations, fitted parameters, first-principles derivations, or predictions are claimed; the work contains no self-citation chains that justify core claims, no ansatzes, and no renaming of known results as novel derivations. The evaluation is therefore self-contained against external benchmarks and exhibits no circularity by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five core dimensions (perception, reasoning, navigation, transformation, configuration) and their 17 subtasks adequately represent higher-level architectural spatial cognition.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ArchSIBench covers five core dimensions: perception, reasoning, navigation, transformation, and configuration, comprising 17 fine-grained subtasks... 3,000 question-answer pairs... evaluate 27 VLMs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Howard Gardner.Frames of mind: The theory of multiple intelligences. Basic books, 2011. 1
work page 2011
-
[2]
Spatial intelligence: New futures for architecture.Places Journal, 2010
William L Fox. Spatial intelligence: New futures for architecture.Places Journal, 2010. 1
work page 2010
-
[3]
Daniel R Montello. Spatial cognition and architectural space: Research perspectives.Architectural Design, 84(5):74–79, 2014. 1
work page 2014
-
[4]
The space for culture and cognition.Poetics, 38(2):185–204, 2010
Daina Cheyenne Harvey. The space for culture and cognition.Poetics, 38(2):185–204, 2010. 1
work page 2010
-
[5]
Spatial cognition.Memory and Cognitive Processes, 3:113–163, 2004
Nora S Newcombe. Spatial cognition.Memory and Cognitive Processes, 3:113–163, 2004. 1, 3, 5
work page 2004
-
[6]
Chiara Meneghetti, Laura Miola, Tommaso Feraco, Veronica Muffato, and Miola. Individual differences in navigation: an introductory overview.Prime archives in psychology, 2:3, 2022. 1
work page 2022
-
[7]
Nora S Newcombe. Three kinds of spatial cognition.Stevens’ handbook of experimental psychology and cognitive neuroscience, 3:1–31, 2018. 1, 3, 5
work page 2018
-
[8]
Three spaces of spatial cognition
Barbara Tversky, Julie Bauer Morrison, Nancy Franklin, and David J Bryant. Three spaces of spatial cognition. The Professional Geographer, 51(4):516–524, 1999. 1, 3, 5
work page 1999
-
[9]
Michal Berkowitz, Andri Gerber, Christian M Thurn, Beatrix Emo, Christoph Hoelscher, and Elsbeth Stern. Spatial abilities for architecture: Cross sectional and longitudinal assessment with novel and existing spatial ability tests.Frontiers in psychology, 11:609363, 2021. 1
work page 2021
-
[10]
Functions and applications of spatial cognition.Handbook of Spatial Cognition, 2013
Daniel R Montello and Martin Raubal. Functions and applications of spatial cognition.Handbook of Spatial Cognition, 2013. 1
work page 2013
-
[11]
Ken J Sutton and Anthony P Williams. Spatial cognition and its implications for design.International Association of Societies of Design Research, Hong Kong, China, 2007. 1, 5
work page 2007
-
[12]
Lu Yue, Yue Fan, Shiwei Lian, Yu Zhao, Jiaxin Yu, Liang Xie, and Feitian Zhang. Spatial-vln: Zero-shot vision-and-language navigation with explicit spatial perception and exploration.arXiv preprint arXiv:2601.12766,
-
[13]
Shoubin Chen, Zehao Wu, Kai Zhang, Chunyu Li, Baiyang Zhang, Fei Ma, Fei Richard Yu, and Qingquan Li. Exploring embodied multimodal large models: Development, datasets, and future directions.Information Fusion, 122:103198, 2025. 1
work page 2025
-
[14]
Rao Fu, Jingyu Liu, Xilun Chen, Yixin Nie, and Wenhan Xiong. Scene-llm: Extending language model for 3d visual understanding and reasoning.arXiv preprint arXiv:2403.11401, 2024. 1
-
[15]
Scenethesis: A language and vision agentic framework for 3d scene generation,
Lu Ling, Chen-Hsuan Lin, Tsung-Yi Lin, Yifan Ding, Yu Zeng, Yichen Sheng, Yunhao Ge, Ming-Yu Liu, Aniket Bera, and Zhaoshuo Li. Scenethesis: A language and vision agentic framework for 3d scene generation.arXiv preprint arXiv:2505.02836, 2025. 1
-
[16]
Jun Yin, Pengyu Zeng, Jing Zhong, Peilin Li, Miao Zhang, Ran Luo, and Shuai Lu. Floorplan-deepseek (fpds): A multimodal approach to floorplan generation using vector-based next room prediction.arXiv preprint arXiv:2506.21562, 2025. 1
-
[17]
Spatialgen: Layout-guided 3d indoor scene generation.arXiv preprint arXiv:2509.14981, 3, 2025
Chuan Fang, Heng Li, Yixun Liang, Jia Zheng, Yongsen Mao, Yuan Liu, Rui Tang, Zihan Zhou, and Ping Tan. Spatialgen: Layout-guided 3d indoor scene generation.arXiv preprint arXiv:2509.14981, 3, 2025. 1
-
[18]
Yongsen Mao, Junhao Zhong, Chuan Fang, Jia Zheng, Rui Tang, Hao Zhu, Ping Tan, and Zihan Zhou. Spatiallm: Training large language models for structured indoor modeling.arXiv preprint arXiv:2506.07491, 2025. 1
-
[19]
Li, Adrien Bardes, Suzanne Petryk, Oscar Ma ˜nas, et al
Florian Bordes, Richard Yuanzhe Pang, Anurag Ajay, Alexander C Li, Adrien Bardes, Suzanne Petryk, Oscar Mañas, Zhiqiu Lin, Anas Mahmoud, Bargav Jayaraman, et al. An introduction to vision-language modeling.arXiv preprint arXiv:2405.17247, 2024. 2
-
[20]
Benchmark evaluations, applications, and challenges of large vision language models: A survey,
Zongxia Li, Xiyang Wu, Hongyang Du, Huy Nghiem, and Guangyao Shi. Benchmark evaluations, applications, and challenges of large vision language models: A survey.arXiv preprint arXiv:2501.02189, 1:1, 2025. 2
-
[21]
Xu Zheng, Zihao Dongfang, Lutao Jiang, Boyuan Zheng, Yulong Guo, Zhenquan Zhang, Giuliano Albanese, Runyi Yang, Mengjiao Ma, Zixin Zhang, et al. Multimodal spatial reasoning in the large model era: A survey and benchmarks.arXiv preprint arXiv:2510.25760, 2025. 2
-
[22]
Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods
Weichen Liu, Qiyao Xue, Haoming Wang, Xiangyu Yin, Boyuan Yang, and Wei Gao. Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods.arXiv preprint arXiv:2511.15722,
-
[23]
Francis DK Ching.Architecture: Form, space, and order. John Wiley & Sons, 2023. 2 10
work page 2023
-
[24]
Bill Hillier.Space is the machine: a configurational theory of architecture. Space Syntax, 2007. 2, 3, 5
work page 2007
-
[25]
Cambridge university press, 1989
Bill Hillier and Julienne Hanson.The social logic of space. Cambridge university press, 1989. 2, 3, 5
work page 1989
-
[26]
Mental representation of three-dimensional objects in visual problem solving and recognition
Lynn A Cooper. Mental representation of three-dimensional objects in visual problem solving and recognition. Journal of Experimental Psychology: Learning, Memory, and Cognition, 16(6):1097, 1990. 2
work page 1990
-
[27]
A visualization and orthographic drawing test using the macintosh computer
Gary R Bertoline and Daniel C Miller. A visualization and orthographic drawing test using the macintosh computer. Engineering Design Graphics Journal, 54(1):1–7, 1990. 2
work page 1990
-
[28]
Measuring 3-d understanding on the web and in the laboratory
Ken Sutton, Andrew Heathcote, and Miles Bore. Measuring 3-d understanding on the web and in the laboratory. Behavior Research Methods, 39(4):926–939, 2007. 2
work page 2007
-
[29]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Anthropic. Introducing claude opus 4.5. https://www.anthropic.com/news/claude-opus-4-5, 2025. 3, 6
work page 2025
-
[32]
Anthropic. Introducing claude opus 4.6. https://www.anthropic.com/news/claude-opus-4-6, 2026. 3, 6
work page 2026
-
[33]
Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026. 3, 6
work page 2026
-
[34]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Gemini 3: Our most intelligent ai model that brings any idea to life
Google DeepMind. Gemini 3: Our most intelligent ai model that brings any idea to life. https://deepmind.google/models/gemini/, 2026. 3, 6
work page 2026
-
[36]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024. 3, 6
work page 2024
-
[38]
Gemma: Our most capable open models
Google DeepMind. Gemma: Our most capable open models. https://deepmind.google/models/gemma/, 2026. 3, 6
work page 2026
-
[39]
Marina Vasilyeva and Stella F Lourenco. Development of spatial cognition.Wiley Interdisciplinary Reviews: Cognitive Science, 3(3):349–362, 2012. 3, 4
work page 2012
-
[40]
Cognitive maps in rats and men.Psychological review, 55(4):189, 1948
Edward C Tolman. Cognitive maps in rats and men.Psychological review, 55(4):189, 1948. 3
work page 1948
-
[41]
Russell A Epstein, Eva Zita Patai, Joshua B Julian, and Hugo J Spiers. The cognitive map in humans: spatial navigation and beyond.Nature neuroscience, 20(11):1504–1513, 2017. 3
work page 2017
- [42]
-
[43]
Space syntax.Environment and Planning B: Planning and design, 3(2):147–185, 1976
Bill Hillier, Adrian Leaman, Paul Stansall, and Michael Bedford. Space syntax.Environment and Planning B: Planning and design, 3(2):147–185, 1976. 3, 5
work page 1976
-
[44]
Space3d-bench: Spatial 3d question answering benchmark
Emilia Szyma´nska, Mihai Dusmanu, Jan-Willem Buurlage, Mahdi Rad, and Marc Pollefeys. Space3d-bench: Spatial 3d question answering benchmark. InEuropean Conference on Computer Vision, pages 68–85. Springer,
-
[45]
Openeqa: Embodied question answering in the era of foundation models
Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, et al. Openeqa: Embodied question answering in the era of foundation models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16488–16498, 2024. 3
work page 2024
-
[46]
Weichen Zhang, Zile Zhou, Xin Zeng, Xuchen Liu, Jianjie Fang, Chen Gao, Yong Li, Jinqiang Cui, Xinlei Chen, and Xiao-Ping Zhang. Open3d-vqa: A benchmark for comprehensive spatial reasoning with multimodal large language model in open space.arXiv preprint arXiv:2503.11094, 2025. 3
-
[47]
Mengfei Du, Binhao Wu, Zejun Li, Xuan-Jing Huang, and Zhongyu Wei. Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 346–355, 2024. 3
work page 2024
-
[48]
Scanqa: 3d question answering for spatial scene understanding
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. Scanqa: 3d question answering for spatial scene understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19129–19139, 2022. 3 11
work page 2022
-
[49]
Sqa3d: Situated question answering in 3d scenes,
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. Sqa3d: Situated question answering in 3d scenes.arXiv preprint arXiv:2210.07474, 2022. 3
-
[50]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025. 3
work page 2025
-
[51]
3dsrbench: A comprehensive 3d spatial reasoning benchmark
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso de Melo, and Alan Yuille. 3dsrbench: A comprehensive 3d spatial reasoning benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6924–6934, 2025. 3
work page 2025
-
[52]
Lukas Petersson, Axel Backlund, Axel Wennstöm, Hanna Petersson, Callum Sharrock, and Arash Dabiri. Blueprint- bench: Comparing spatial intelligence of llms, agents and image models.arXiv preprint arXiv:2509.25229, 2025. 4
-
[53]
Waffle: Multimodal floorplan understanding in the wild
Keren Ganon, Morris Alper, Rachel Mikulinsky, and Hadar Averbuch-Elor. Waffle: Multimodal floorplan understanding in the wild. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1488–1497. IEEE, 2025. 4
work page 2025
-
[54]
Aleksei Kondratenko, Mussie Birhane, Houssame E Hsain, and Guido Maciocci. Aecv-bench: Benchmarking multimodal models on architectural and engineering drawings understanding.arXiv preprint arXiv:2601.04819,
-
[55]
Luca Tommasi and Bruno Laeng. Psychology of spatial cognition.Wiley Interdisciplinary Reviews: Cognitive Science, 3(6):565–580, 2012. 4, 5
work page 2012
-
[56]
Spatial perception in virtual environments: Evaluating an architectural application
Daniel Henry and Tom Furness. Spatial perception in virtual environments: Evaluating an architectural application. InProceedings of IEEE Virtual Reality Annual International Symposium, pages 33–40. IEEE, 1993. 4
work page 1993
-
[57]
Levels and structure of spatial knowledge
Barbara Tverksy. Levels and structure of spatial knowledge. InCognitive mapping, pages 24–43. Routledge, 2018. 5
work page 2018
-
[58]
Using orientation information for qualitative spatial reasoning
Christian Freksa. Using orientation information for qualitative spatial reasoning. InTheories and Methods of Spatio-Temporal Reasoning in Geographic Space: International Conference GIS—From Space to Territory: Theories and Methods of Spatio-Temporal Reasoning Pisa, Italy, September 21–23, 1992 Proceedings, pages 162–178. Springer, 2005. 5
work page 1992
-
[59]
Spatial cognition: The role of landmark, route, and survey knowledge in human and robot navigation1
Steffen Werner, Bernd Krieg-Brückner, Hanspeter A Mallot, Karin Schweizer, and Christian Freksa. Spatial cognition: The role of landmark, route, and survey knowledge in human and robot navigation1. InInformatik’97 Informatik als Innovationsmotor: 27. Jahrestagung der Gesellschaft für Informatik Aachen, 24.–26. September 1997, pages 41–50. Springer, 1997. 5
work page 1997
-
[60]
Edgar Chan, Oliver Baumann, Mark A Bellgrove, and Jason B Mattingley. From objects to landmarks: the function of visual location information in spatial navigation.Frontiers in psychology, 3:304, 2012. 5
work page 2012
-
[61]
Jeffrey M Zacks, JON Mires, Barbara Tversky, and Eliot Hazeltine. Mental spatial transformations of objects and perspective.Spatial Cognition and Computation, 2(4):315–332, 2000. 5
work page 2000
-
[62]
A parametric study of mental spatial transformations of bodies.Neuroimage, 16(4):857–872, 2002
Jeffrey M Zacks, John M Ollinger, Margaret A Sheridan, and Barbara Tversky. A parametric study of mental spatial transformations of bodies.Neuroimage, 16(4):857–872, 2002. 5
work page 2002
-
[63]
Space as configuration: Patterns of space and culture.Proceedings of the ARCHTHEO, 2015:9th,
Esin Hasgül. Space as configuration: Patterns of space and culture.Proceedings of the ARCHTHEO, 2015:9th,
work page 2015
-
[64]
Wiem Zerouati and Tahar Bellal. Evaluating the impact of mass housings’ in-between spaces’ spatial configuration on users’ social interaction.Frontiers of Architectural Research, 9(1):34–53, 2020. 5
work page 2020
- [65]
- [66]
- [67]
-
[68]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023. 6
work page 2023
-
[69]
Ruth A Childs and Andrew P Jaciw. Matrix sampling of items in large-scale assessments.Practical Assessment, Research, and Evaluation, 8(1), 2002. 7
work page 2002
-
[70]
Adaptive mixtures of local experts
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts. Neural computation, 3(1):79–87, 1991. 8 12
work page 1991
-
[71]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Out- rageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538,
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
A review of sparse expert models in deep learning.arXiv preprint arXiv:2209.01667,
William Fedus, Jeff Dean, and Barret Zoph. A review of sparse expert models in deep learning.arXiv preprint arXiv:2209.01667, 2022. 8
-
[73]
Infinite photorealistic worlds using procedural generation
Alexander Raistrick, Lahav Lipson, Zeyu Ma, Lingjie Mei, Mingzhe Wang, Yiming Zuo, Karhan Kayan, Hongyu Wen, Beining Han, Yihan Wang, et al. Infinite photorealistic worlds using procedural generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12630–12641, 2023. 9
work page 2023
-
[74]
Alexander Raistrick, Lingjie Mei, Karhan Kayan, David Yan, Yiming Zuo, Beining Han, Hongyu Wen, Meenal Parakh, Stamatis Alexandropoulos, Lahav Lipson, et al. Infinigen indoors: Photorealistic indoor scenes using procedural generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21783–21794, 2024. 9 13 A Detai...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.