ParaCell: Paravirtualized Secure Containers with Lightweight Intra-Container Isolation and Intent-Driven Memory Management
Pith reviewed 2026-05-21 02:09 UTC · model grok-4.3
The pith
ParaCell uses MPK domain switches and proactive memory binding to cut secure container latency while preserving elasticity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
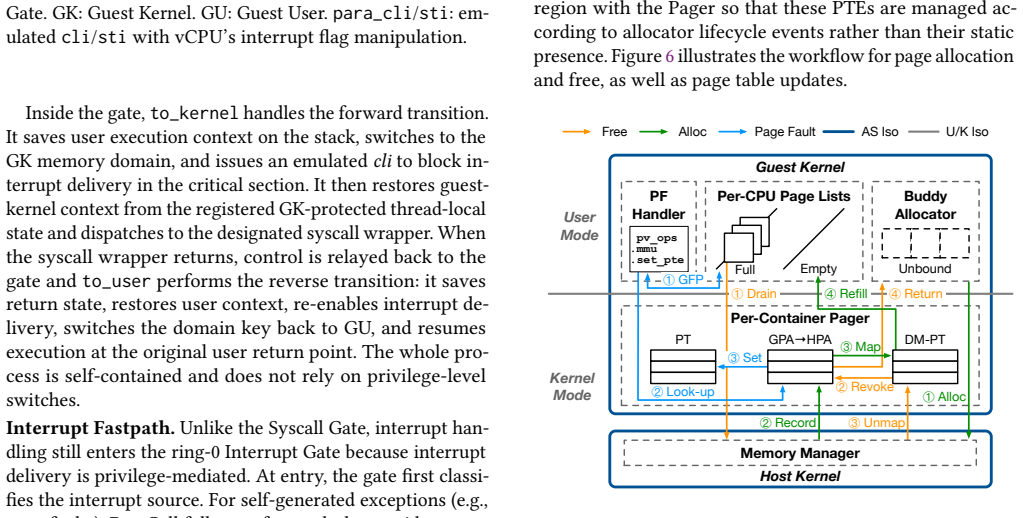
ParaCell achieves its results by combining two mechanisms inside a drop-in replacement for RunV: MPK-based XGates that isolate the container user and container kernel within a single address space so that user-kernel transitions become direct domain switches, and a Pager component that interposes on allocation and free events to perform batch proactive GPA-to-HPA bindings and unbindings, eliminating most reactive shadow page-table faults while keeping fine-grained elasticity.
What carries the argument
MPK-based XGates for intra-address-space user-kernel isolation plus the Pager that extracts memory intent from container kernel allocators to drive proactive page bindings.
If this is right
- Latency drops of up to 57 percent and 79 percent versus PVM in bare-metal and nested setups.
- Latency drops of up to 33 percent and 88 percent versus RunV in the same setups.
- Memory savings up to 35.6 percent versus HyperAlloc on agent workloads.
- Fine-grained memory elasticity is retained while avoiding most secondary page faults.
Where Pith is reading between the lines
- The same intent-extraction idea could be applied to other guest kernels or hypervisor interfaces where allocation events are visible.
- If MPK-style primitives become more common in future CPUs, similar lightweight isolation layers may appear in additional virtualization stacks.
- Agent frameworks that already expose memory hints might integrate directly with the Pager to further improve elasticity.
Load-bearing premise
MPK protection primitives can deliver lightweight isolation for frequent user-kernel transitions without new security risks or hidden costs, and container kernel allocators already encode enough memory-management intent to make proactive GPA-HPA bindings effective.
What would settle it
A measurement showing either that MPK domain switches introduce unacceptable overhead or security holes in container workloads, or that proactive bindings fail to reduce faults below reactive baselines on bursty agent memory patterns.
Figures










read the original abstract
Secure containers isolate each container with its own kernel, mitigating shared-kernel attacks prevalent in traditional container systems. However, existing designs still face a fundamental isolation--performance trade-off. Nested-cloud deployments amplify the cost of VM exits and page-table management, while emerging agentic workloads expose bursty memory demand that requires fine-grained elasticity. We attribute this trade-off to two root causes. First, existing designs lack lightweight intra-container isolation primitives for frequent container user--kernel transitions. Second, the host treats container memory management as opaque, forcing reactive secondary faults and coarse-grained huge page mappings to amortize their cost. This paper presents ParaCell, a paravirtualized secure container runtime built on two insights. First, intra-address-space hardware protection primitives can provide lightweight intra-container isolation. ParaCell uses MPK-based XGates to isolate the container user and container kernel within a single address space, turning frequent user--kernel transitions into direct domain switches. Second, container kernel allocators already encode memory-management intent. ParaCell introduces Pager to interpose on allocation and free events, batch proactive GPA to HPA bindings and unbindings, and avoid reactive shadow page-table faults while preserving fine-grained memory elasticity. ParaCell is implemented as a drop-in replacement for RunV. Our experiments demonstrate that, across traditional cloud and emerging agent applications, ParaCell reduces latency by up to 57% and 79% over PVM, and by up to 33% and 88% over RunV, in bare-metal and nested setups, respectively. On agent workloads, ParaCell saves up to 35.6% memory compared with the state-of-the-art VM memory reclamation technique, HyperAlloc.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ParaCell, a paravirtualized secure container runtime that uses MPK-based XGates to provide lightweight intra-container isolation by placing container user and kernel code in the same address space and converting syscalls to domain switches, along with the Pager mechanism that interposes on kernel allocator events to perform proactive GPA-to-HPA bindings and avoid reactive faults. Experiments claim latency reductions of up to 57% and 79% versus PVM and 33% and 88% versus RunV in bare-metal and nested configurations, plus up to 35.6% memory savings versus HyperAlloc on agent workloads.
Significance. If the reported performance and memory results hold under full scrutiny, the work would offer a practical advance in secure container design by mitigating the isolation-performance trade-off in both traditional and nested-cloud settings while supporting elastic memory for bursty agentic applications. The combination of hardware domain protection with allocator-intent memory management is a concrete contribution that could influence future paravirtualized runtimes.
major comments (2)
- [§3.1] §3.1 (XGates design): The claim that MPK-based domain switches deliver lightweight isolation without new security risks rests on the assumption that the container kernel cannot arbitrarily load PKRU or bypass protections while sharing the address space; the manuscript does not detail the required kernel modifications or prove that TLB invalidations remain minimal in nested virtualization, which is load-bearing for attributing the 57–88% latency gains specifically to the isolation primitive rather than Pager batching.
- [§5.2] §5.2 (evaluation methodology): The latency and memory numbers are presented without error bars, full baseline configurations, or raw data tables; this prevents verification that the reported improvements (e.g., 35.6% memory savings) are statistically robust and not confounded by workload-specific tuning or measurement artifacts.
minor comments (3)
- [Abstract] The abstract and §2 could more clearly distinguish the contributions of XGates versus Pager so readers can assess which component drives the nested-setup gains.
- [Figure 4] Figure 4 (memory elasticity plot) uses overlapping lines without distinct markers or a legend inset, reducing readability for the agent-workload comparison.
- [§6] A short related-work paragraph contrasting ParaCell with prior MPK uses in unikernels or library OSes would help situate the novelty of the intra-container kernel isolation approach.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments help clarify important aspects of the XGates design and evaluation presentation. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§3.1] §3.1 (XGates design): The claim that MPK-based domain switches deliver lightweight isolation without new security risks rests on the assumption that the container kernel cannot arbitrarily load PKRU or bypass protections while sharing the address space; the manuscript does not detail the required kernel modifications or prove that TLB invalidations remain minimal in nested virtualization, which is load-bearing for attributing the 57–88% latency gains specifically to the isolation primitive rather than Pager batching.
Authors: We thank the referee for this observation. Section 3.1 describes the paravirtualized kernel modifications that trap and validate all PKRU writes, restricting the container kernel to only authorized XGates for domain switches; untrusted code cannot load arbitrary PKRU values. On TLB behavior in nested virtualization, MPK domain switches operate within a shared address space and do not trigger additional page-table walks or full TLB flushes beyond those of a standard syscall. To better attribute the reported latency reductions to the isolation mechanism itself, we will add an ablation study in the revised §5 that disables Pager batching while retaining XGates, allowing direct comparison of the two contributions. revision: yes
-
Referee: [§5.2] §5.2 (evaluation methodology): The latency and memory numbers are presented without error bars, full baseline configurations, or raw data tables; this prevents verification that the reported improvements (e.g., 35.6% memory savings) are statistically robust and not confounded by workload-specific tuning or measurement artifacts.
Authors: We agree that the current evaluation presentation would benefit from greater statistical transparency. In the revised manuscript we will add error bars (standard deviation over 10 runs) to all latency and memory figures in §5.2 and include a new appendix table that fully specifies the configuration parameters of PVM, RunV, and HyperAlloc. We will also add a compact summary table of the key raw measurements. The complete per-run dataset will be released as supplementary material rather than embedded in the paper to keep the main text concise. revision: partial
Circularity Check
No circularity in ParaCell design or claims
full rationale
The paper introduces ParaCell as a new paravirtualized secure container runtime using MPK-based XGates for intra-address-space isolation and a Pager for proactive GPA-HPA bindings based on allocator events. All performance claims (latency reductions of 57-88% and memory savings of 35.6%) are presented as outcomes of implementation and direct experimental measurements against baselines like PVM, RunV, and HyperAlloc. No equations, fitted parameters renamed as predictions, self-citations forming load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The derivation chain consists of engineering insights implemented and benchmarked, remaining self-contained against external benchmarks without reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Intra-address-space hardware protection primitives can provide lightweight intra-container isolation.
- domain assumption Container kernel allocators encode memory-management intent usable for proactive GPA to HPA bindings.
invented entities (2)
-
XGates
no independent evidence
-
Pager
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ParaCell uses MPK-based XGates to isolate the container user and container kernel within a single address space, turning frequent user–kernel transitions into direct domain switches.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Pager to interpose on allocation and free events, batch proactive GPA to HPA bindings and unbindings
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Computer use.https://platform.openai.com/docs/guides/tools- computer-use
-
[2]
The container security platform.https://gvisor.dev/
-
[3]
db_bench_sqlite3.cc.https://github.com/google/leveldb/blob/main/ benchmarks/db_bench_sqlite3.cc
-
[4]
Deploy openclaw in seconds.https://www.alibabacloud.com/en/ campaign/ai-openclaw
-
[5]
Hermes agent.https://hermes-agent.nousresearch.com/
-
[6]
How claude code works.https://code.claude.com/docs/en/how- claude-code-works
-
[7]
Introducing claude sonnet 4.6.https://www.anthropic.com/news/ claude-sonnet-4-6
-
[8]
Introducing site isolation in firefox.https://blog.mozilla.org/security/ 2021/05/18/introducing-site-isolation-in-firefox/
work page 2021
-
[9]
Introducing upgrades to codex.https://openai.com/index/introducing- upgrades-to-codex/
-
[10]
Kata containers.https://katacontainers.io/
-
[11]
Let claude use your computer from the cli.https://code.claude.com/ docs/en/computer-use
-
[12]
Lmbench - tools for performance analysis.https://lmbench. sourceforge.net/
-
[13]
Multi-process architecture.https://www.chromium.org/developers/ design-documents/multi-process-architecture/
-
[14]
Openclaw - deploy openclaw in seconds.https://www.tencentcloud. com/act/pro/intl-openclaw
-
[15]
Openclaw overview.https://docs.openclaw.ai/
-
[16]
Playwright mcp.https://playwright.dev/mcp/introduction
-
[17]
Quickly deploy hermes agent on the cloud.https://www.tencentcloud. com/act/pro/hermesagent
-
[18]
runc.https://github.com/opencontainers/runc
-
[19]
runv.https://github.com/hyperhq/runv
-
[20]
Sandboxing.https://docs.openclaw.ai/gateway/sandboxing
-
[21]
Site isolation design document.https://www.chromium.org/ developers/design-documents/site-isolation/
-
[22]
Sqlite.https://www.sqlite.org/
-
[23]
The systrap platform.https://github.com/google/gvisor/blob/master/ pkg/sentry/platform/systrap/README.md
-
[24]
Fire- cracker: Lightweight virtualization for serverless applications
Alexandru Agache, Marc Brooker, Alexandra Iordache, Anthony Liguori, Rolf Neugebauer, Phil Piwonka, and Diana-Maria Popa. Fire- cracker: Lightweight virtualization for serverless applications. In17th USENIX symposium on networked systems design and implementation (NSDI 20), pages 419–434, 2020
work page 2020
-
[25]
Drops: Managing serverless resource pools in mi- crosoft azure functions
Ahmed Alquraan, Abdelrahman Baba, Rafael Mendes da Silva, Sameh Elnikety, Paul Batum, Yan Chen, Hamid Henry Safi, Seth Fine, and Samer Al-Kiswany. Drops: Managing serverless resource pools in mi- crosoft azure functions. InProceedings of the 21st European Conference on Computer Systems, pages 1281–1297, 2026
work page 2026
-
[26]
The design and implementation of hyperupcalls
Nadav Amit and Michael Wei. The design and implementation of hyperupcalls. In2018 USENIX Annual Technical Conference (USENIX ATC 18), pages 97–112, 2018
work page 2018
-
[27]
The turtles project: Design and implementation of nested virtualization
Muli Ben-Yehuda, Michael D Day, Zvi Dubitzky, Michael Factor, Nadav Har’El, Abel Gordon, Anthony Liguori, Orit Wasserman, and Ben-Ami Yassour. The turtles project: Design and implementation of nested virtualization. In9th USENIX Symposium on Operating Systems Design and Implementation (OSDI 10), 2010
work page 2010
-
[28]
Stella Bitchebe and Alain Tchana. Out of hypervisor (ooh): efficient dirty page tracking in userspace using hardware virtualization features. InSC22: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–14. IEEE, 2022
work page 2022
-
[29]
An analysis of linux scalability to many cores
Silas Boyd-Wickizer, Austin T Clements, Yandong Mao, Aleksey Pesterev, M Frans Kaashoek, Robert Morris, and Nickolai Zeldovich. An analysis of linux scalability to many cores. In9th USENIX Sym- posium on Operating Systems Design and Implementation (OSDI 10), 2010
work page 2010
-
[30]
Skernel: An elastic and efficient secure container system at scale with a split- kernel architecture
Xiaohu Chai, Keyang Hu, Jianfeng Tan, Tiwei Bie, Guotao Tan, Tianyu Zhou, Anqi Shen, Dawei Shen, Xinyao Yang, Xin Chen, et al. Skernel: An elastic and efficient secure container system at scale with a split- kernel architecture. InProceedings of the 21st European Conference on Computer Systems, pages 605–623, 2026
work page 2026
-
[31]
Limitations and opportunities of modern hardware isolation mechanisms
Xiangdong Chen, Zhaofeng Li, Tirth Jain, Vikram Narayanan, and Anton Burtsev. Limitations and opportunities of modern hardware isolation mechanisms. In2024 USENIX Annual Technical Conference (USENIX ATC 24), pages 349–368, 2024
work page 2024
-
[32]
Catalyzer: Sub-millisecond startup for serverless computing with initialization-less booting
Dong Du, Tianyi Yu, Yubin Xia, Binyu Zang, Guanglu Yan, Cheng- gang Qin, Qixuan Wu, and Haibo Chen. Catalyzer: Sub-millisecond startup for serverless computing with initialization-less booting. In Proceedings of the Twenty-Fifth International Conference on Architec- tural Support for Programming Languages and Operating Systems, pages 467–481, 2020
work page 2020
-
[33]
Mak- ing kernel bypass practical for the cloud with junction
Joshua Fried, Gohar Irfan Chaudhry, Enrique Saurez, Esha Choukse, Íñigo Goiri, Sameh Elnikety, Rodrigo Fonseca, and Adam Belay. Mak- ing kernel bypass practical for the cloud with junction. In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), pages 55–73, 2024
work page 2024
-
[34]
Jinyu Gu, Xinyue Wu, Wentai Li, Nian Liu, Zeyu Mi, Yubin Xia, and Haibo Chen. Harmonizing performance and isolation in microker- nels with efficient intra-kernel isolation and communication. In2020 USENIX Annual Technical Conference (USENIX ATC 20), pages 401–417, 2020. 13 Wu et al., Yiyang Wu, Xunjie Wang, Jinyu Gu, and Haibo Chen
work page 2020
-
[35]
A {Hardware-Software} co-design for efficient{Intra-Enclave} isolation
Jinyu Gu, Bojun Zhu, Mingyu Li, Wentai Li, Yubin Xia, and Haibo Chen. A {Hardware-Software} co-design for efficient{Intra-Enclave} isolation. In31st USENIX Security Symposium (USENIX Security 22), pages 3129–3145, 2022
work page 2022
-
[36]
Yinggang Guo, Zicheng Wang, Weiheng Bai, Qingkai Zeng, and Kangjie Lu. Bulkhead: secure, scalable, and efficient kernel compart- mentalization with pks.arXiv preprint arXiv:2409.09606, 2024
-
[37]
Sok: A com- prehensive analysis and evaluation of docker container attack and defense mechanisms
Md Sadun Haq, Thien Duc Nguyen, Ali Şaman Tosun, Franziska Vollmer, Turgay Korkmaz, and Ahmad-Reza Sadeghi. Sok: A com- prehensive analysis and evaluation of docker container attack and defense mechanisms. In2024 IEEE symposium on security and privacy (SP), pages 4573–4590. IEEE, 2024
work page 2024
-
[38]
Cross container attacks: The bewildered eBPF on clouds
Yi He, Roland Guo, Yunlong Xing, Xijia Che, Kun Sun, Zhuotao Liu, Ke Xu, and Qi Li. Cross container attacks: The bewildered eBPF on clouds. In32nd USENIX Security Symposium (USENIX Security 23). USENIX Association, 2023
work page 2023
-
[39]
Hodor:{Intra- Process} isolation for {High-Throughput} data plane libraries
Mohammad Hedayati, Spyridoula Gravani, Ethan Johnson, John Criswell, Michael L Scott, Kai Shen, and Mike Marty. Hodor:{Intra- Process} isolation for {High-Throughput} data plane libraries. In 2019 USENIX Annual Technical Conference (USENIX ATC 19), pages 489–504, 2019
work page 2019
-
[40]
Virtio-mem: Paravirtual- ized memory hot (un) plug
David Hildenbrand and Martin Schulz. Virtio-mem: Paravirtual- ized memory hot (un) plug. InProceedings of the 17th ACM SIG- PLAN/SIGOPS International Conference on Virtual Execution Environ- ments, pages 1–14, 2021
work page 2021
-
[41]
Everything you always wanted to know about plan- ning: (but were afraid to ask)
Jörg Hoffmann. Everything you always wanted to know about plan- ning: (but were afraid to ask). InAnnual Conference on Artificial Intelligence, pages 1–13. Springer, 2011
work page 2011
-
[42]
Pvm: Efficient shadow paging for deploying secure containers in cloud-native envi- ronment
Hang Huang, Jiangshan Lai, Jia Rao, Hui Lu, Wenlong Hou, Hang Su, Quan Xu, Jiang Zhong, Jiahao Zeng, Xu Wang, et al. Pvm: Efficient shadow paging for deploying secure containers in cloud-native envi- ronment. InProceedings of the 29th Symposium on Operating Systems Principles, pages 515–530, 2023
work page 2023
-
[43]
TrEnv: Transparently share serverless execution environments across different functions and nodes
Jialiang Huang, Mingxing Zhang, Teng Ma, Zheng Liu, Sixing Lin, Kang Chen, Jinlei Jiang, Xia Liao, Yingdi Shan, Ning Zhang, Mengting Lu, Tao Ma, Haifeng Gong, and Yongwei Wu. TrEnv: Transparently share serverless execution environments across different functions and nodes. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles (SOS...
work page 2024
-
[44]
Memory protection keys for userspace, 2019
Intel. Memory protection keys for userspace, 2019
work page 2019
-
[45]
Omar Jarkas, Ryan Ko, Naipeng Dong, and Redowan Mahmud. A container security survey: Exploits, attacks, and defenses.ACM Com- puting Surveys, 57(7):1–36, 2025
work page 2025
-
[46]
Zhipeng Jia and Emmett Witchel. Nightcore: efficient and scalable serverless computing for latency-sensitive, interactive microservices. InProceedings of the 26th ACM international conference on architectural support for programming languages and operating systems, pages 152– 166, 2021
work page 2021
-
[47]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
kvm: the linux virtual machine monitor
Avi Kivity, Yaniv Kamay, Dor Laor, Uri Lublin, and Anthony Liguori. kvm: the linux virtual machine monitor. InProceedings of the Linux symposium, volume 1, pages 225–230. Dttawa, Dntorio, Canada, 2007
work page 2007
-
[49]
Fhpm: Fine-grained huge page management for virtualization.arXiv preprint arXiv:2307.10618, 2023
Chuandong Li, Sai Sha, Yangqing Zeng, Xiran Yang, Yingwei Luo, Xiaolin Wang, and Zhenlin Wang. Fhpm: Fine-grained huge page management for virtualization.arXiv preprint arXiv:2307.10618, 2023
-
[50]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, et al. Skillsbench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Zijun Li, Jiagan Cheng, Quan Chen, Eryu Guan, Zizheng Bian, Yi Tao, Bin Zha, Qiang Wang, Weidong Han, and Minyi Guo. {RunD}: A lightweight secure container runtime for high-density deployment and high-concurrency startup in serverless computing. In2022 USENIX Annual Technical Conference (USENIX ATC 22), pages 53–68, 2022
work page 2022
-
[52]
Neve: Nested virtualization extensions for arm
Jin Tack Lim, Christoffer Dall, Shih-Wei Li, Jason Nieh, and Marc Zyngier. Neve: Nested virtualization extensions for arm. InProceedings of the 26th Symposium on Operating Systems Principles, pages 201–217, 2017
work page 2017
-
[53]
Optimizing nested virtualization perfor- mance using direct virtual hardware
Jin Tack Lim and Jason Nieh. Optimizing nested virtualization perfor- mance using direct virtual hardware. InProceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, pages 557–574, 2020
work page 2020
-
[54]
Kit: Testing os-level virtualization for functional interference bugs
Congyu Liu, Sishuai Gong, and Pedro Fonseca. Kit: Testing os-level virtualization for functional interference bugs. InProceedings of the 28th ACM International Conference on Architectural Support for Pro- gramming Languages and Operating Systems, Volume 2, pages 427–441, 2023
work page 2023
-
[55]
Shiqi Liu, Yongpeng Gao, Mingyang Zhang, and Jie Wang. Nanozone: Scalable, efficient, and secure memory protection for arm cca.arXiv preprint arXiv:2506.07034, 2025
-
[56]
Dan Magenheimer, Chris Mason, Dave McCracken, and Kurt Hackel. Transcendent memory and linux. InProceedings of the Linux Sympo- sium, pages 191–200, 2009
work page 2009
-
[57]
{LITESHIELD}: Secure containers via lightweight, composable userspace {𝜇 Kernel} services
Kaesi Manakkal, Nathan Daughety, Marcus Pendleton, and Hui Lu. {LITESHIELD}: Secure containers via lightweight, composable userspace {𝜇 Kernel} services. In2025 USENIX Annual Technical Con- ference (USENIX ATC 25), pages 973–985, 2025
work page 2025
-
[58]
My vm is lighter (and safer) than your container
Filipe Manco, Costin Lupu, Florian Schmidt, Jose Mendes, Simon Kuen- zer, Sumit Sati, Kenichi Yasukata, Costin Raiciu, and Felipe Huici. My vm is lighter (and safer) than your container. InProceedings of the 26th Symposium on Operating Systems Principles, pages 218–233, 2017
work page 2017
-
[59]
Edward Oakes, Leon Yang, Dennis Zhou, Kevin Houck, Tyler Harter, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. SOCK: Rapid task provisioning with serverless-optimized containers. In2018 USENIX Annual Technical Conference (USENIX ATC 18), pages 57–70. USENIX Association, 2018
work page 2018
-
[60]
Fast local page-tables for virtualized numa servers with vmitosis
Ashish Panwar, Reto Achermann, Arkaprava Basu, Abhishek Bhat- tacharjee, K Gopinath, and Jayneel Gandhi. Fast local page-tables for virtualized numa servers with vmitosis. InProceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, pages 194–210, 2021
work page 2021
-
[61]
libmpk: Software abstraction for intel memory protection keys (intel {MPK})
Soyeon Park, Sangho Lee, Wen Xu, Hyungon Moon, and Taesoo Kim. libmpk: Software abstraction for intel memory protection keys (intel {MPK}). In2019 USENIX Annual Technical Conference (USENIX ATC 19), pages 241–254, 2019
work page 2019
-
[62]
Shixiong Qi, Leslie Monis, Ziteng Zeng, Ian-chin Wang, and KK Ra- makrishnan. Spright: extracting the server from serverless computing! high-performance ebpf-based event-driven, shared-memory process- ing. InProceedings of the ACM SIGCOMM 2022 Conference, pages 780–794, 2022
work page 2022
-
[63]
Resizing memory with balloons and hotplug
Joel H Schopp, Keir Fraser, and Martine J Silbermann. Resizing memory with balloons and hotplug. InProceedings of the Linux Symposium, volume 2, pages 313–319, 2006
work page 2006
-
[64]
Nanvix: A Multikernel OS Design for High-Density Serverless Deployments
Carlos Segarra, Pedro Henrique Penna, Enrique Saurez, Íñigo Goiri, Peter Pietzuch, Shan Lu, and Rodrigo Fonseca. Nanvix: A multikernel os design for high-density serverless deployments.arXiv preprint arXiv:2604.11669, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Zhiming Shen, Zhen Sun, Gur-Eyal Sela, Eugene Bagdasaryan, Christina Delimitrou, Robbert Van Renesse, and Hakim Weatherspoon. X-containers: Breaking down barriers to improve performance and iso- lation of cloud-native containers. InProceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Sy...
work page 2019
-
[66]
A hardware-software co-design for efficient secure containers
Jiacheng Shi, Yang Yu, Jinyu Gu, and Yubin Xia. A hardware-software co-design for efficient secure containers. InProceedings of the Twentieth European Conference on Computer Systems, pages 1229–1245, 2025. 14 ParaCell: Paravirtualized Secure Containers with Lightweight Intra-Container Isolation and Intent-Driven Memory Management
work page 2025
-
[67]
Locked in, leaked out: Measuring isolation via kernel locks.arXiv preprint arXiv:2507.21248, 2025
Michael M Swift et al. Locked in, leaked out: Measuring isolation via kernel locks.arXiv preprint arXiv:2507.21248, 2025
-
[68]
A study on container vulnerability exploit detection
Olufogorehan Tunde-Onadele, Jingzhu He, Ting Dai, and Xiaohui Gu. A study on container vulnerability exploit detection. In2019 ieee international conference on cloud engineering (IC2E), pages 121–127. IEEE, 2019
work page 2019
-
[69]
Intel virtualization technology.Computer, 38(5):48–56, 2005
Rich Uhlig, Gil Neiger, Dion Rodgers, Amy L Santoni, Fernando CM Martins, Andrew V Anderson, Steven M Bennett, Alain Kagi, Felix H Leung, and Larry Smith. Intel virtualization technology.Computer, 38(5):48–56, 2005
work page 2005
-
[70]
Duarte, Michael Sammler, Peter Druschel, and Deepak Garg
Anjo Vahldiek-Oberwagner, Eslam Elnikety, Nuno O. Duarte, Michael Sammler, Peter Druschel, and Deepak Garg. Erim: secure, efficient in- process isolation with protection keys (mpk). InProceedings of the 28th USENIX Conference on Security Symposium, SEC’19, page 1221–1238, USA, 2019. USENIX Association
work page 2019
-
[71]
Using smt to accel- erate nested virtualization
Lluís Vilanova, Nadav Amit, and Yoav Etsion. Using smt to accel- erate nested virtualization. InProceedings of the 46th International Symposium on Computer Architecture, pages 750–761, 2019
work page 2019
-
[72]
Secure virtual machine architecture reference man- ual.AMD Publication, 33047, 2005
A Virtualization. Secure virtual machine architecture reference man- ual.AMD Publication, 33047, 2005
work page 2005
-
[73]
Detecting noisy neighbors in cpu-isolated cgroups environments
Simon Volpert, Sascha Winkelhofer, Jörg Domaschka, and Stefan Wes- ner. Detecting noisy neighbors in cpu-isolated cgroups environments. InProceedings of the 16th ACM/SPEC International Conference on Per- formance Engineering, ICPE ’25, page 224–231, New York, NY, USA,
-
[74]
Association for Computing Machinery
-
[75]
You shall not (by) pass! practical, secure, and fast pku-based sandboxing
Alexios Voulimeneas, Jonas Vinck, Ruben Mechelinck, and Stijn Vol- ckaert. You shall not (by) pass! practical, secure, and fast pku-based sandboxing. InProceedings of the Seventeenth European Conference on Computer Systems, pages 266–282, 2022
work page 2022
-
[76]
Carl A Waldspurger. Memory resource management in vmware esx server.ACM SIGOPS Operating Systems Review, 36(SI):181–194, 2002
work page 2002
-
[77]
Kun Wang, Song Wu, Kun Suo, Yijie Liu, Hang Huang, Zhuo Huang, and Hai Jin. Characterizing and optimizing kernel resource isolation for containers.Future Generation Computer Systems, 141:218–229, 2023
work page 2023
-
[78]
Yaohui Wang, Ben Luo, and Yibin Shen. Efficient memory overcom- mitment for {I/O} passthrough enabled {VMs} via fine-grained page meta-data management. In2023 USENIX Annual Technical Conference (USENIX ATC 23), pages 769–783, 2023
work page 2023
-
[79]
No provisioned concurrency: Fast RDMA- codesigned remote fork for serverless computing
Xingda Wei, Fangming Lu, Tianxia Wang, Jinyu Gu, Yuhan Yang, Rong Chen, and Haibo Chen. No provisioned concurrency: Fast RDMA- codesigned remote fork for serverless computing. In17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23), pages 497–517. USENIX Association, 2023
work page 2023
-
[80]
Enabling efficient hypervisor- as-a-service clouds with ephemeral virtualization
Dan Williams, Yaohui Hu, Umesh Deshpande, Piush K Sinha, Nilton Bila, Kartik Gopalan, and Hani Jamjoom. Enabling efficient hypervisor- as-a-service clouds with ephemeral virtualization. InProceedings of the12th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments, pages 79–92, 2016
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.