Sutra: Tensor-Op RNNs as a Compilation Target for Vector Symbolic Architectures
Pith reviewed 2026-05-21 06:25 UTC · model grok-4.3
The pith
A single Sutra program compiles to a tensor graph that decodes bundles at 100% accuracy on four frozen embeddings where Hadamard products fail and supports end-to-end training via autograd.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
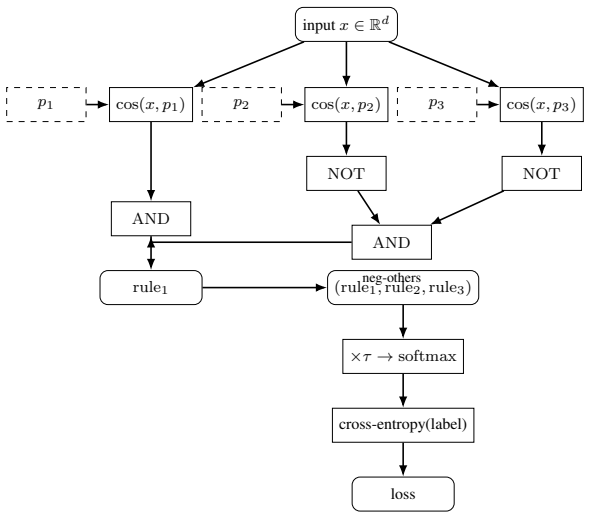
Sutra is a typed, purely functional programming language whose compiled forward pass is a PyTorch neural network. The compiler beta-reduces the whole program -- primitives, control flow, string I/O -- to one fused tensor-op graph over a frozen embedding substrate. Rotation binding, unbind, bundle, polynomial Kleene three-valued logic, and tail-recursive loops all lower to tensor operations; the Kleene connectives are Lagrange-interpolated polynomials exact on the {-1, 0, +1} truth grid. Validation shows the same program runs on four frozen embeddings spanning two modalities and decodes bundles at 100% accuracy through width k=8 on every substrate, where the textbook Hadamard product has уже塌
What carries the argument
The Sutra compiler that beta-reduces functional programs containing vector-symbolic primitives into a single fused PyTorch tensor graph over a frozen embedding substrate.
If this is right
- The identical source achieves perfect bundle decoding on three text encoders and one protein encoder even after the Hadamard product baseline collapses.
- Autograd through the emitted graph trains a fuzzy-rule classifier from chance-level accuracy to 100 percent without altering the symbolic source.
- A weighted variant learns a scalar gain and writes the value back into the original Sutra source as a literal that reproduces the trained behavior upon recompilation.
- The resulting artifact functions simultaneously as executable logic and as a trainable neural network.
Where Pith is reading between the lines
- Existing embeddings may already embed enough algebraic structure to support symbolic manipulation across modalities without fine-tuning.
- Hybrid systems could let engineers write logic once and obtain modality-specific neural implementations by choosing different frozen substrates.
- The approach opens a route to inspect trained models by reading the updated numeric literals back in the original source language.
Load-bearing premise
The chosen frozen embedding substrates already contain sufficient geometric structure for the tensor-op implementations of rotation binding, unbinding, and polynomial logic to succeed without any embedding adaptation or additional learned parameters.
What would settle it
Running the same compiled Sutra program on one of the four tested embeddings at bundle width k=8 and observing decoding accuracy below 100 percent.
Figures


read the original abstract
Sutra is a typed, purely functional programming language whose compiled forward pass is a PyTorch neural network. The compiler beta-reduces the whole program -- primitives, control flow, string I/O -- to one fused tensor-op graph over a frozen embedding substrate. Rotation binding, unbind, bundle, polynomial Kleene three-valued logic, and tail-recursive loops all lower to tensor operations; the Kleene connectives are Lagrange-interpolated polynomials exact on the {-1, 0, +1} truth grid. Validation is one fact tested two ways. (1) The same program runs on four frozen embeddings spanning two modalities -- three text encoders (nomic-embed-text, all-minilm, mxbai-embed-large) and one protein language model (ESM-2) -- and decodes bundles at 100% accuracy through width k=8 on every substrate, where the textbook Hadamard product has already collapsed (2.5% on mxbai-embed-large, 7.5% on all-minilm). (2) PyTorch autograd flows through the actually compiled graph: a fuzzy-rule classifier written in .su trains from random init (18.7 +/- 9.5%; chance = 20%, five classes) to 100.0 +/- 0.0% (three seeds) by backpropagating through the emitted graph, the symbolic source unmodified. A weighted variant additionally trains a scalar cosine gain and writes it back into the .su source as a numeric literal; recompiling reproduces the trained behaviour to ~2e-7 per logit, so the trained model is itself legible, recompilable code. The same artifact is therefore both a logic program and a trainable neural network.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Sutra, a typed purely functional language that compiles entire programs (including rotation binding, unbinding, bundling, polynomial Kleene logic, and loops) to a single fused tensor-op graph executable as a PyTorch network over a frozen embedding substrate. It claims that the identical Sutra source achieves 100% bundle decoding accuracy through width k=8 on four diverse frozen embeddings (nomic-embed-text, all-minilm, mxbai-embed-large, ESM-2) where the textbook Hadamard product already fails, and that PyTorch autograd flows through the emitted graph to train a fuzzy-rule classifier from random initialization (18.7% to 100%) with trained scalar parameters exportable back into the source for exact reproduction (~2e-7 error).
Significance. If substantiated, the work supplies a concrete compilation target that renders vector symbolic architectures differentiable and directly trainable inside standard ML frameworks while preserving source-level legibility. The cross-embedding consistency and the closed loop from symbolic source through training back to recompilable code are concrete strengths that could support hybrid neuro-symbolic systems without embedding fine-tuning.
major comments (2)
- [Abstract] Abstract (validation paragraph): the headline result that the same compiled tensor-op graph decodes bundles at 100% for k=8 on all four listed embeddings (while Hadamard collapses) is load-bearing for the claim that the primitives are substrate-agnostic; however, no control experiments on random or non-contrastively-trained vectors of matching dimension are reported, leaving open the possibility that success exploits latent superposition statistics already present in the chosen pre-trained encoders rather than the rotation/Lagrange operators themselves.
- [Abstract] Abstract (training paragraph): the reported end-to-end training (18.7 +/- 9.5% to 100.0 +/- 0.0% across three seeds) and the ~2e-7 reproduction error after writing the learned cosine gain back into the .su source are central to the differentiability claim, yet the manuscript provides neither the classifier architecture, loss function, nor any ablation on the contribution of the compiled graph versus the embedding, rendering the numerical support difficult to verify or reproduce from the given text.
minor comments (1)
- The description of how tail-recursive loops and string I/O lower to tensor operations is stated at a high level; an explicit small example program together with its emitted graph would clarify the beta-reduction claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate additional controls and details for improved clarity and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract (validation paragraph): the headline result that the same compiled tensor-op graph decodes bundles at 100% for k=8 on all four listed embeddings (while Hadamard collapses) is load-bearing for the claim that the primitives are substrate-agnostic; however, no control experiments on random or non-contrastively-trained vectors of matching dimension are reported, leaving open the possibility that success exploits latent superposition statistics already present in the chosen pre-trained encoders rather than the rotation/Lagrange operators themselves.
Authors: We agree that control experiments on random vectors would strengthen the substrate-agnostic claim. The current results show 100% decoding on four diverse frozen embeddings (including cross-modal ESM-2) where Hadamard fails, but we acknowledge the absence of random-vector baselines leaves room for alternative explanations. In the revised manuscript we will add experiments with randomly initialized vectors of matching dimension to isolate the contribution of the rotation/Lagrange operators. revision: yes
-
Referee: [Abstract] Abstract (training paragraph): the reported end-to-end training (18.7 +/- 9.5% to 100.0 +/- 0.0% across three seeds) and the ~2e-7 reproduction error after writing the learned cosine gain back into the .su source are central to the differentiability claim, yet the manuscript provides neither the classifier architecture, loss function, nor any ablation on the contribution of the compiled graph versus the embedding, rendering the numerical support difficult to verify or reproduce from the given text.
Authors: We accept that the training details are insufficient for verification. The revised manuscript will explicitly describe the fuzzy-rule classifier architecture written in Sutra, the loss function (cross-entropy over five classes), and an ablation that compares performance with and without the compiled graph. These additions will make the autograd flow and closed-loop reproduction (~2e-7 error) fully reproducible from the text. revision: yes
Circularity Check
No significant circularity; empirical results on independent frozen embeddings
full rationale
The paper's derivation consists of a compiler that lowers Sutra programs (including rotation binding, unbinding, bundling, and Lagrange-interpolated Kleene logic) to fused tensor operations over a frozen embedding substrate, followed by direct empirical validation. The headline result—identical source achieving 100% bundle decode accuracy at k=8 across nomic-embed-text, all-minilm, mxbai-embed-large, and ESM-2 while Hadamard collapses—is measured on public, independently trained models with no adaptation or learned parameters in the embeddings themselves. Training a fuzzy-rule classifier from random initialization (18.7% to 100.0%) via autograd through the emitted graph further confirms differentiability without any fitted quantity being renamed as a prediction. No self-definitional loop, fitted-input prediction, or load-bearing self-citation chain appears in the provided text; the chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Beta-reduction of the functional program to a fused tensor graph is semantics-preserving
- domain assumption Lagrange interpolation yields exact Kleene connectives on the {-1,0,+1} grid
invented entities (1)
-
Sutra language and its compiler
no independent evidence
Reference graph
Works this paper leans on
-
[1]
• Darwiche, A., & Marquis, P. (2002). A knowledge compilation map.JAIR17:229–264. • Gayler, R. W. (2003). Vector symbolic architectures answer Jackendoff's challenges for cognitive neuroscience.Joint International Conference on Cognitive Science. • Kanerva, P. (2009). Hyperdimensional computing: An introduction to computing in dis- tributed representation...
work page 2002
-
[2]
Kluwer Academic. The standard reference for t-norm-based fuzzy logics (Gödel, Łukasiewicz, product) cited in §1.1-1 to place Sutra's polynomial connectives. • Heddes, M., Nunes, I., Vergés, P., Kleyko, D., Abraham, D., Givargis, T., Nicolau, A., & Veidenbaum, A. (2023). Torchhd: An open source python library to support research on hyperdimensional computi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.