MemConflict: Evaluating Long-Term Memory Systems Under Memory Conflicts
Pith reviewed 2026-05-21 02:23 UTC · model grok-4.3
The pith
Long-term memory systems perform unevenly under different memory conflicts, with answer correctness often diverging from retrieval quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
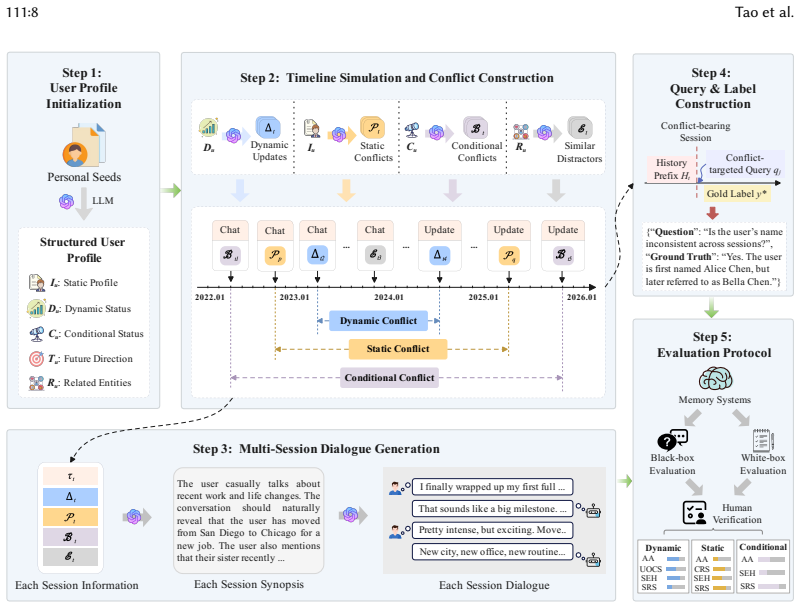
MemConflict formalizes dynamic, static, and conditional conflicts over temporal validity, factual correctness, and contextual applicability in long-term memory. By simulating multi-session dialogues from user profiles with injected conflicts and distractors, it enables evaluation of both the final answer and the internal retrieval and ranking of memories, revealing that systems have uneven capabilities and that correctness can separate from good memory selection.
What carries the argument
The MemConflict diagnostic framework, which treats memory validity as a query-conditioned fitness-for-use problem and supports black-box answer evaluation alongside white-box memory retrieval analysis.
If this is right
- Systems exhibit different strengths depending on whether conflicts are dynamic, static, or conditional.
- Answer correctness frequently does not align with the quality of memory retrieval and ranking.
- Performance declines as history length increases, with more distractors, implicit queries, or greater conflict distances.
- Common failures include missing the supporting memory or failing to use retrieved memories effectively.
Where Pith is reading between the lines
- Developers could use this to prioritize fixes for retrieval mechanisms that ignore conflict resolution.
- Extending the framework to real user logs might show different sensitivity patterns than simulated profiles.
- Similar conflict-aware testing could apply to other memory-dependent AI systems beyond conversation agents.
Load-bearing premise
Simulated histories built from structured user profiles with injected conflicts match the memory conflicts that arise in actual user interactions with conversational agents.
What would settle it
Running the same systems on a dataset of real multi-session user conversations and finding that conflict handling performance or sensitivity patterns differ substantially from the benchmark results.
Figures







read the original abstract
Long-term memory systems enable conversational agents based on large language models (LLMs) to retain, retrieve, and apply user-specific information across multi-session interactions. However, existing evaluations mainly assess outcome-level performance or temporal updating, providing limited insight into how systems retrieve and rank temporally valid, factually correct, and contextually applicable memory evidence under conflicting alternatives. To address this gap, we propose MemConflict, a diagnostic framework that treats memory validity as a query-conditioned fitness-for-use problem. MemConflict formalizes dynamic, static, and conditional conflicts over temporal validity, factual correctness, and contextual applicability. It simulates controlled long-horizon histories from structured user profiles, introduces cross-session conflicts, and injects semantically similar distractors to create competition among memory candidates. The resulting multi-session dialogue benchmark supports black-box evaluation of final answers and white-box analysis of supporting-memory retrieval and ranking. Experiments on six representative long-term memory systems show uneven strengths across conflict types, with answer correctness often diverging from memory retrieval and ranking. Sensitivity analyses reveal that longer histories, distractors, implicit queries, and larger conflict distances degrade performance. Diagnostics show failures from missing supporting memories and ineffective use of retrieved memories. Collectively, MemConflict advances principled long-term memory governance through retrieval-aware, conflict-aware reliability assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MemConflict, a diagnostic evaluation framework for long-term memory systems in LLM-based conversational agents. It formalizes dynamic, static, and conditional memory conflicts across temporal validity, factual correctness, and contextual applicability dimensions. The approach simulates controlled multi-session histories from structured user profiles, injects cross-session conflicts and semantically similar distractors, and supports both black-box answer evaluation and white-box analysis of memory retrieval and ranking. Experiments on six representative systems report uneven performance across conflict types, divergences between answer correctness and retrieval/ranking, and performance degradation from longer histories, distractors, implicit queries, and larger conflict distances, along with diagnostics on missing or ineffective memory use.
Significance. If the controlled simulations prove representative, MemConflict offers a principled way to diagnose retrieval-aware reliability issues in long-term memory systems, which is increasingly important for multi-session conversational agents. The framework's separation of conflict types and its sensitivity analyses provide concrete, falsifiable insights into failure modes that existing outcome-level or temporal-update evaluations miss. Strengths include the black-box/white-box dual evaluation design and the application to six diverse systems, which together could inform more robust memory governance mechanisms.
major comments (2)
- [Framework and Experiments (abstract description)] The central claims about uneven system strengths and specific degradation factors (longer histories, distractors, implicit queries, larger conflict distances) rest on the assumption that structured user profiles plus injected conflicts produce representative memory competition. This assumption is load-bearing for generalizing the observed failure modes (missing supporting memories, ineffective use) beyond the simulation. No calibration against real user logs, organic conflict distributions, or human realism ratings is described.
- [Experiments section] The paper reports performance divergences between answer correctness and memory retrieval/ranking, but without details on the exact retrieval metrics, ranking functions, or statistical significance tests for the six systems, it is difficult to assess whether the divergences are robust or sensitive to implementation choices.
minor comments (2)
- Clarify how the six representative long-term memory systems were selected and whether they cover recent retrieval-augmented or memory-augmented LLM architectures.
- The abstract mentions 'sensitivity analyses' but does not specify the ranges or sampling methods used for history length, conflict distance, or distractor density; adding this would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential value of MemConflict as a diagnostic framework. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Framework and Experiments (abstract description)] The central claims about uneven system strengths and specific degradation factors (longer histories, distractors, implicit queries, larger conflict distances) rest on the assumption that structured user profiles plus injected conflicts produce representative memory competition. This assumption is load-bearing for generalizing the observed failure modes (missing supporting memories, ineffective use) beyond the simulation. No calibration against real user logs, organic conflict distributions, or human realism ratings is described.
Authors: We agree that the synthetic construction of conflicts from structured profiles is a core design choice whose representativeness merits explicit discussion. MemConflict prioritizes controlled isolation of conflict types and sensitivity factors over ecological validity, enabling reproducible diagnostics that existing evaluations lack. In the revision we will expand the Limitations section with a dedicated paragraph on this assumption, its implications for generalizing failure modes, and planned future calibration against real logs or human ratings. This will better scope our claims without altering the current experimental results. revision: yes
-
Referee: [Experiments section] The paper reports performance divergences between answer correctness and memory retrieval/ranking, but without details on the exact retrieval metrics, ranking functions, or statistical significance tests for the six systems, it is difficult to assess whether the divergences are robust or sensitive to implementation choices.
Authors: We acknowledge the need for greater methodological transparency. The revised Experiments section will specify all retrieval metrics (including exact formulas for precision@K, recall, and ranking scores such as MRR or NDCG), describe the ranking functions and scoring implementations for each of the six systems, and report statistical significance tests (paired t-tests or Wilcoxon signed-rank tests with p-values and effect sizes) on the observed divergences. These additions will allow readers to evaluate robustness directly. revision: yes
Circularity Check
No circularity: new evaluation framework applied to external systems
full rationale
The paper proposes MemConflict as a diagnostic benchmark that formalizes conflict types over temporal/factual/contextual dimensions, generates controlled multi-session histories from structured user profiles, injects conflicts and distractors, and then runs black-box and white-box evaluations on six pre-existing long-term memory systems. No equations, fitted parameters, or predictions are defined in terms of the target results; the reported performance divergences, sensitivity findings, and failure modes are direct outputs of applying the new framework to independent systems. There are no self-citations used as load-bearing uniqueness theorems, no ansatzes smuggled from prior author work, and no renaming of known results as novel derivations. The derivation chain is therefore self-contained empirical measurement rather than reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Memory validity can be treated as a query-conditioned fitness-for-use problem.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MemConflict formalizes dynamic, static, and conditional conflicts over temporal validity, factual correctness, and contextual applicability... simulates controlled long-horizon histories... Support Evidence Hit@K (SEH@K) and Support Rank Score (SRS)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
treats memory validity as a query-conditioned fitness-for-use problem
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Chen Amiraz, Florin Cuconasu, Simone Filice, and Zohar Karnin. 2025. The distracting effect: Understanding irrelevant passages in rag. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. 18228–18258
work page 2025
- [2]
-
[3]
Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun. 2024. Benchmarking large language models in retrieval-augmented generation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 17754–17762
work page 2024
-
[4]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Florin Cuconasu, Giovanni Trappolini, Federico Siciliano, Simone Filice, Cesare Campagnano, Yoelle Maarek, Nicola Tonellotto, and Fabrizio Silvestri. 2024. The power of noise: Redefining retrieval for rag systems. InProceedings of the J. ACM, Vol. 37, No. 4, Article 111. Publication date: August 2018. 111:30 Tao et al. 47th International ACM SIGIR Confere...
work page 2024
-
[6]
Yubin Ge, Salvatore Romeo, Jason Cai, Raphael Shu, Yassine Benajiba, Monica Sunkara, and Yi Zhang. 2025. Tremu: Towards neuro-symbolic temporal reasoning for llm-agents with memory in multi-session dialogues. InFindings of the Association for Computational Linguistics: ACL 2025. 18974–18988
work page 2025
- [7]
-
[8]
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, et al. 2025. Memory in the age of ai agents.arXiv preprint arXiv:2512.13564(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Yuanzhe Hu, Yu Wang, and Julian McAuley. 2025. Evaluating memory in llm agents via incremental multi-turn interactions.arXiv preprint arXiv:2507.05257(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [10]
-
[11]
Hao Li, Chenghao Yang, An Zhang, Yang Deng, Xiang Wang, and Tat-Seng Chua. 2025. Hello again! llm-powered personalized agent for long-term dialogue. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies. 5259–5276
work page 2025
-
[12]
Zhiyu Li, Chenyang Xi, Chunyu Li, et al. 2025. Memos: A memory os for ai system.arXiv preprint arXiv:2507.03724 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Shayne Longpre, Kartik Perisetla, Anthony Chen, Nikhil Ramesh, Chris DuBois, and Sameer Singh. 2021. Entity-based knowledge conflicts in question answering. InProceedings of the 2021 conference on empirical methods in natural language processing. 7052–7063
work page 2021
-
[14]
Yuanjie Lyu, Zhiyu Li, Simin Niu, Feiyu Xiong, Bo Tang, Wenjin Wang, Hao Wu, Huanyong Liu, Tong Xu, and Enhong Chen. 2025. Crud-rag: A comprehensive chinese benchmark for retrieval-augmented generation of large language models.ACM Transactions on Information Systems43, 2 (2025), 1–32
work page 2025
-
[15]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. 13851–13870
work page 2024
- [16]
- [17]
-
[18]
Ella Neeman, Roee Aharoni, Or Honovich, Leshem Choshen, Idan Szpektor, and Omri Abend. 2023. Disentqa: Disentangling parametric and contextual knowledge with counterfactual question answering. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics. 10056–10070
work page 2023
-
[19]
Kai Tzu-iunn Ong, Namyoung Kim, Minju Gwak, Hyungjoo Chae, Taeyoon Kwon, Yohan Jo, Seung-won Hwang, Dongha Lee, and Jinyoung Yeo. 2025. Towards lifelong dialogue agents via timeline-based memory management. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technolo...
work page 2025
-
[20]
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. 2023. MemGPT: Towards LLMs as Operating Systems.arXiv preprint arXiv:2310.08560(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th Annual Acm Symposium on User Interface Software and Technology. 1–22
work page 2023
-
[22]
Lianhui Qin, Aditya Gupta, Shyam Upadhyay, Luheng He, Yejin Choi, and Manaal Faruqui. 2021. TIMEDIAL: Temporal commonsense reasoning in dialog. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. 7066–7076
work page 2021
- [23]
-
[24]
Diane M Strong, Yang W Lee, and Richard Y Wang. 1997. Data quality in context.Commun. ACM40, 5 (1997), 103–110
work page 1997
-
[25]
Haoran Tan, Zeyu Zhang, Chen Ma, Xu Chen, Quanyu Dai, and Zhenhua Dong. 2025. Membench: Towards more comprehensive evaluation on the memory of llm-based agents. InFindings of the Association for Computational Linguistics: ACL 2025. 19336–19352
work page 2025
-
[26]
Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, et al. 2025. In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. 8416–8439. J. ACM, Vol. 37, No. 4, A...
work page 2025
-
[27]
Haoran Tang, Shiqing Wu, Xueyao Sun, Jun Zeng, Guandong Xu, and Qing Li. 2025. TCGC: Temporal collaboration- aware graph co-evolution learning for dynamic recommendation.ACM Transactions on Information Systems43, 1 (2025), 1–27
work page 2025
- [28]
-
[29]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. 2024. A survey on large language model based autonomous agents.Frontiers of Computer Science18, 6 (2024), 186345
work page 2024
-
[30]
Richard Y Wang and Diane M Strong. 1996. Beyond accuracy: What data quality means to data consumers.Journal of management information systems12, 4 (1996), 5–33
work page 1996
-
[31]
Weizhi Wang, Li Dong, Hao Cheng, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, and Furu Wei. 2023. Augmenting language models with long-term memory. InProceedings of the 37th International Conference on Neural Information Processing Systems. 74530–74543
work page 2023
-
[32]
Wenjie Wang, Xinyu Lin, Liuhui Wang, Fuli Feng, Yunshan Ma, and Tat-Seng Chua. 2023. Causal disentangled recommendation against user preference shifts.ACM Transactions on Information Systems42, 1 (2023), 1–27
work page 2023
-
[33]
Yu Wang, Yifan Gao, Xiusi Chen, Haoming Jiang, Shiyang Li, Jingfeng Yang, Qingyu Yin, Zheng Li, Xian Li, Bing Yin, et al. 2024. MEMORYLLM: Towards Self-Updatable Large Language Models. InInternational Conference on Machine Learning. PMLR, 50453–50466
work page 2024
-
[34]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. 2024. Longmemeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Yunxuan Xiong, Yuntao Chen, and Hai Zhang. 2026. ICR: A Framework for Resolving Knowledge Conflicts in Retrieval-Augmented Generation.Neurocomputing664 (2026), 132139
work page 2026
-
[36]
Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunxiang Wang, Hongru Wang, Yue Zhang, and Wei Xu. 2024. Knowledge conflicts for llms: A survey. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 8541–8565
work page 2024
-
[37]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. 2025. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Ruifeng Yuan, Shichao Sun, Yongqi Li, Zili Wang, Ziqiang Cao, and Wenjie Li. 2025. Personalized large language model assistant with evolving conditional memory. InProceedings of the 31st International Conference on Computational Linguistics. 3764–3777
work page 2025
-
[39]
Kai Zhang, Yangyang Kang, Fubang Zhao, and Xiaozhong Liu. 2024. Llm-based medical assistant personalization with short-and long-term memory coordination. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2386–2398
work page 2024
-
[40]
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. 2025. A survey on the memory mechanism of large language model-based agents.ACM Transactions on Information Systems 43, 6 (2025), 1–47
work page 2025
-
[41]
Siyan Zhao, Mingyi Hong, Yang Liu, Devamanyu Hazarika, and Kaixiang Lin. 2025. Do llms recognize your preferences? evaluating personalized preference following in llms. In13th International Conference on Learning Representations, ICLR 2025. 72531–72574
work page 2025
-
[42]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 19724–19731. J. ACM, Vol. 37, No. 4, Article 111. Publication date: August 2018. 111:32 Tao et al. A Prompt Templates for MemConflict Construction ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.