DASH: Fast Differentiable Architecture Search for Hybrid Attention in Minutes on a Single GPU
Pith reviewed 2026-05-21 06:15 UTC · model grok-4.3
The pith
DASH shows that differentiable search can discover high-performing hybrid attention architectures for LLMs in about 20 minutes on a single GPU using only 12.3 million tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By converting discrete operator placements per layer into continuous architecture logits and optimizing only these with frozen weights after preparing linear candidates aligned to a teacher, DASH discovers discrete hybrid attention architectures. On Qwen2.5-3B-Instruct these architectures consistently beat selector-style baselines and achieve better RULER scores than released Jet-Nemotron models, all while using 12.3M tokens and 20 minutes on one GPU, which is 0.006% of the tokens used in prior PostNAS stages.
What carries the argument
The relaxation of discrete layer-wise attention operator placement into continuous architecture logits, optimized with model and operator weights frozen.
If this is right
- Hybrid attention architectures can be designed through direct differentiable optimization rather than manual rules or proxy selectors.
- Search for such architectures becomes feasible as a routine step requiring minimal compute and data.
- Discovered designs preserve competitiveness on short-context and general tasks while improving on long-context benchmarks.
- Architecture quality found under frozen weights transfers to end-to-end evaluation and training scenarios.
Where Pith is reading between the lines
- If the search consistently produces strong architectures across different base models, it could standardize hybrid attention as a default efficiency technique.
- This efficiency might allow exploring hybrid designs at larger scales where full searches were previously prohibitive.
- Extending the candidate preparation to other operator types could broaden the applicability beyond attention hybrids.
Load-bearing premise
That the architectures discovered by searching only the continuous logits with frozen weights will retain their performance advantages once the full model including those operators is trained or fine-tuned end-to-end.
What would settle it
A direct comparison where a DASH-discovered architecture is trained from scratch alongside a strong baseline architecture and shows no improvement or worse results on RULER and other benchmarks.
Figures



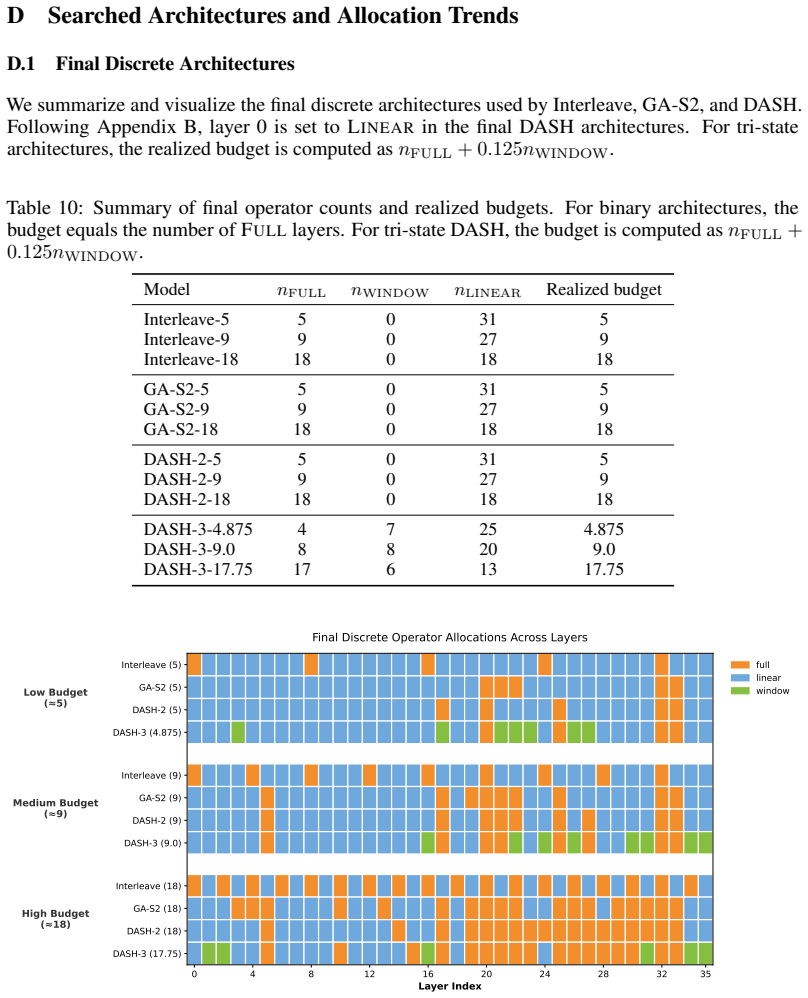


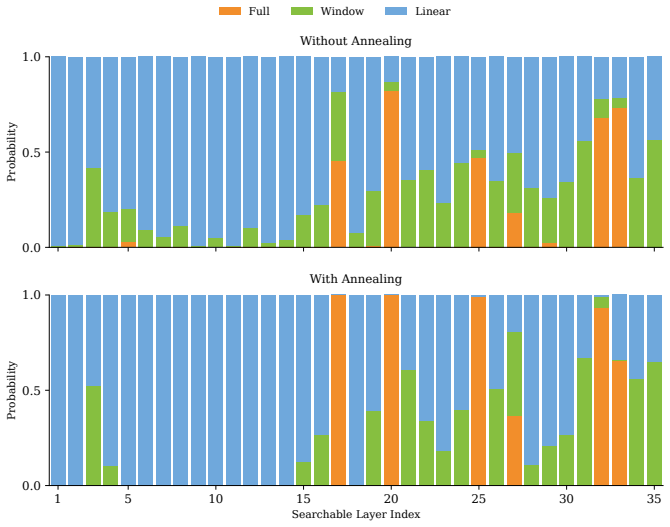
read the original abstract
Hybrid attention architectures are becoming an increasingly important paradigm for improving LLM inference efficiency while preserving model quality, making hybrid architecture design a central problem. Existing designs often rely on manual empirical rules or proxy-based selector signals for layer-wise operator allocation. Recent NAS-style systems such as Jet-Nemotron demonstrate the promise of automated hybrid architecture search. However, Jet-Nemotron's PostNAS search stages alone use 200B tokens, making such search pipelines difficult to use as routine methods for hybrid architecture design. We introduce DASH, a fast differentiable search framework for hybrid attention architecture design, which relaxes discrete layer-wise attention operator placement into continuous architecture logits, prepares reusable teacher-aligned linear candidates, and performs architecture-only search with model and operator weights frozen to significantly enhance search efficiency. On Qwen2.5-3B-Instruct, DASH consistently outperforms a comprehensive suite of existing selector-style hybrid attention design baselines, showing that direct differentiable search can discover stronger hybrid architectures. Moreover, DASH achieves stronger RULER performance than released Jet-Nemotron models while remaining competitive on overlapping short-context and general benchmarks. Notably, each DASH search run uses only 12.3M tokens and takes about 20 minutes on a single RTX Pro 6000 GPU, corresponding to merely 0.006% of the PostNAS search tokens reported by Jet-Nemotron. These results suggest that high-quality hybrid attention architectures can be obtained through minutes-level differentiable search, providing a promising direction for hybrid architecture design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DASH, a differentiable architecture search method for hybrid attention in LLMs. It relaxes discrete layer-wise attention operator choices into continuous architecture logits, prepares reusable teacher-aligned linear candidates, and performs architecture-only search with model and operator weights frozen. On Qwen2.5-3B-Instruct, the discovered architectures outperform selector-style baselines, achieve stronger RULER performance than released Jet-Nemotron models, and remain competitive on short-context and general benchmarks, with each search using only 12.3M tokens and ~20 minutes on a single RTX Pro 6000 GPU (0.006% of Jet-Nemotron PostNAS tokens).
Significance. If the central claims hold, DASH would make automated hybrid attention design practical and routine by reducing search cost by four orders of magnitude relative to prior NAS pipelines. This could accelerate iteration on efficient LLM inference architectures and shift the field from manual rules or expensive selector proxies toward direct differentiable search. The work provides concrete evidence that high-quality hybrids are discoverable under a frozen-weight proxy, which—if the proxy is reliable—represents a substantial efficiency gain.
major comments (2)
- [Method section] Method section (architecture search procedure): The central performance claims rest on the assumption that architectures selected via differentiable search with frozen model and operator weights will preserve their quality ranking and absolute performance once the full model is trained or evaluated end-to-end. The manuscript provides no explicit validation experiment (e.g., an ablation that measures proxy scores versus final RULER or benchmark scores across multiple candidate architectures after unfreezing and retraining), which is load-bearing for interpreting the reported gains over Jet-Nemotron and selector baselines.
- [Experimental results] Experimental results (Qwen2.5-3B-Instruct evaluation): While the abstract and results claim consistent outperformance and stronger RULER scores, the support would be strengthened by reporting error bars or multiple random seeds for the discovered architectures, as the search procedure itself involves stochastic elements in the continuous relaxation and discretization step.
minor comments (2)
- [Figure 1] Figure 1 (search pipeline diagram): The distinction between frozen components and the architecture logits could be labeled more explicitly to clarify what remains fixed during the 20-minute search.
- [Related work] Related work: The positioning against Jet-Nemotron would benefit from a brief quantitative comparison table of search token counts and wall-clock time in addition to the narrative description.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important aspects of validating the frozen-weight proxy and quantifying stochasticity in the search procedure. We address each point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Method section] Method section (architecture search procedure): The central performance claims rest on the assumption that architectures selected via differentiable search with frozen model and operator weights will preserve their quality ranking and absolute performance once the full model is trained or evaluated end-to-end. The manuscript provides no explicit validation experiment (e.g., an ablation that measures proxy scores versus final RULER or benchmark scores across multiple candidate architectures after unfreezing and retraining), which is load-bearing for interpreting the reported gains over Jet-Nemotron and selector baselines.
Authors: We agree that an explicit proxy-to-final validation would further support the claims. DASH is explicitly designed around a frozen-weight, architecture-only search using teacher-aligned linear candidates to enable minutes-scale discovery. The architectures found under this proxy are then directly instantiated and evaluated end-to-end on RULER and other benchmarks, where they outperform both selector baselines and released Jet-Nemotron models. This provides empirical evidence that the proxy produces high-quality hybrids in practice. To address the concern directly, we will add a new ablation in the revised manuscript that reports proxy scores alongside final benchmark performance for a set of candidate architectures sampled during search. revision: yes
-
Referee: [Experimental results] Experimental results (Qwen2.5-3B-Instruct evaluation): While the abstract and results claim consistent outperformance and stronger RULER scores, the support would be strengthened by reporting error bars or multiple random seeds for the discovered architectures, as the search procedure itself involves stochastic elements in the continuous relaxation and discretization step.
Authors: The continuous relaxation is optimized via gradient descent on architecture logits, and the final discretization selects the highest-probability operator per layer. While the optimization trajectory can vary with initialization, we acknowledge that reporting variability would improve robustness. In the revised version we will run the full DASH search three times with independent random seeds on the same base model, report the resulting architectures and their RULER scores with standard deviation, and include these statistics in the main results table. revision: yes
Circularity Check
No circularity: claims rest on external benchmark comparisons
full rationale
The paper introduces DASH as a differentiable search procedure that relaxes discrete operator choices to continuous logits, prepares teacher-aligned linear candidates, and runs architecture search with weights frozen. Reported gains are obtained by direct empirical comparison against selector-style baselines and released Jet-Nemotron models on RULER, short-context, and general benchmarks. No equation or self-citation chain is shown that reduces the discovered architectures or their performance numbers to quantities defined by construction inside the paper. The central result therefore remains an independent empirical finding rather than a tautological restatement of the search procedure itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Relaxing discrete layer-wise attention operator placement into continuous architecture logits preserves the quality of the eventual discrete solution.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DASH relaxes discrete layer-wise attention operator placement into continuous architecture logits, prepares reusable teacher-aligned linear candidates, and performs architecture-only search with model and operator weights frozen
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lsearch = LKL + λ Lcost with c = (1, w/T, 0) for FULL/WINDOW/LINEAR
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Gomez and Lukasz Kaiser and Illia Polosukhin , editor =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , editor =. Attention is All you Need , booktitle =. 2017 , url =
work page 2017
-
[3]
Proceedings of the 37th International Conference on Machine Learning,
Angelos Katharopoulos and Apoorv Vyas and Nikolaos Pappas and Fran. Proceedings of the 37th International Conference on Machine Learning,. 2020 , url =
work page 2020
-
[4]
The Thirteenth International Conference on Learning Representations,
Michael Zhang and Simran Arora and Rahul Chalamala and Benjamin Frederick Spector and Alan Wu and Krithik Ramesh and Aaryan Singhal and Christopher R. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[5]
Daniel Goldstein and Eric Alcaide and Janna Lu and Eugene Cheah , title =. CoRR , volume =. 2025 , url =
work page 2025
-
[6]
Yanhong Li and Songlin Yang and Shawn Tan and Mayank Mishra and Rameswar Panda and Jiawei Zhou and Yoon Kim , title =. CoRR , volume =. 2025 , url =
work page 2025
-
[7]
Yuxian Gu and Qinghao Hu and Shang Yang and Haocheng Xi and Junyu Chen and Song Han and Han Cai , title =. CoRR , volume =. 2025 , url =
work page 2025
- [8]
-
[9]
7th International Conference on Learning Representations,
Hanxiao Liu and Karen Simonyan and Yiming Yang , title =. 7th International Conference on Learning Representations,. 2019 , url =
work page 2019
-
[10]
The Thirteenth International Conference on Learning Representations,
Songlin Yang and Jan Kautz and Ali Hatamizadeh , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[11]
An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and Jingren Zhou and Junyang Lin and Kai Dang and Keming Lu and Keqin Bao and Kexin Yang and Le Yu and Mei Li and Mi...
work page 2024
- [12]
-
[13]
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , title =. CoRR , volume =. 2018 , url =
work page 2018
-
[14]
Yonatan Bisk and Rowan Zellers and Ronan Le Bras and Jianfeng Gao and Yejin Choi , title =. CoRR , volume =. 2019 , url =
work page 2019
-
[15]
Keisuke Sakaguchi and Ronan Le Bras and Chandra Bhagavatula and Yejin Choi , title =. The Thirty-Fourth. 2020 , url =
work page 2020
-
[16]
Kakade and Eran Malach , editor =
Samy Jelassi and David Brandfonbrener and Sham M. Kakade and Eran Malach , editor =. Repeat After Me:. Forty-first International Conference on Machine Learning,. 2024 , url =
work page 2024
-
[17]
Ruisheng Cao and Mouxiang Chen and Jiawei Chen and Zeyu Cui and Yunlong Feng and Binyuan Hui and Yuheng Jing and Kaixin Li and Mingze Li and Junyang Lin and Zeyao Ma and Kashun Shum and Xuwu Wang and Jinxi Wei and Jiaxi Yang and Jiajun Zhang and Lei Zhang and Zongmeng Zhang and Wenting Zhao and Fan Zhou , title =. CoRR , volume =. 2026 , url =
work page 2026
-
[18]
A Systematic Analysis of Hybrid Linear Attention , journal =
Dustin Wang and Rui. A Systematic Analysis of Hybrid Linear Attention , journal =. 2025 , url =
work page 2025
-
[19]
Xiaojie Xia and Huigang Zhang and Chaoliang Zhong and Jun Sun and Yusuke Oishi , title =. CoRR , volume =. 2026 , url =
work page 2026
-
[20]
Yu Zhang and Zongyu Lin and Xingcheng Yao and Jiaxi Hu and Fanqing Meng and Chengyin Liu and Xin Men and Songlin Yang and Zhiyuan Li and Wentao Li and Enzhe Lu and Weizhou Liu and Yanru Chen and Weixin Xu and Longhui Yu and Yejie Wang and Yu Fan and Longguang Zhong and Enming Yuan and Dehao Zhang and Yizhi Zhang and T. Y. Liu and Haiming Wang and Shengjun...
work page 2025
-
[21]
Junxiong Wang and Daniele Paliotta and Avner May and Alexander M. Rush and Tri Dao , editor =. The. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 , year =
work page 2024
-
[22]
ICLR 2025 Workshop on New Frontiers in Associative Memories , year=
Test-time scaling meets associative memory: Challenges in subquadratic models , author=. ICLR 2025 Workshop on New Frontiers in Associative Memories , year=
work page 2025
-
[23]
Ahderom and Najmeh Samadiani and Andrew Maiorana and Girish Dwivedi , title =
Najmeh Fayyazifar and Selam T. Ahderom and Najmeh Samadiani and Andrew Maiorana and Girish Dwivedi , title =. Proceedings of the 15th International Conference on Machine Learning and Computing,. 2023 , url =
work page 2023
-
[24]
Xiangxiang Chu and Tianbao Zhou and Bo Zhang and Jixiang Li , editor =. Fair. Computer Vision -. 2020 , url =
work page 2020
-
[25]
arXiv preprint arXiv:2402.02834 , volume=
Bo-Kyeong Kim and Geonmin Kim and Tae-Ho Kim and Thibault Castells and Shinkook Choi and Junho Shin and Hyoung-Kyu Song , year=. Shortened. 2402.02834 , archivePrefix=
-
[26]
Mingyu Yang and Mehdi Rezagholizadeh and Guihong Li and Vikram Appia and Emad Barsoum , title =. CoRR , volume =. 2025 , url =
work page 2025
-
[27]
Gerber and Elad Dolev and Eran Krakovsky and Erez Safahi and Erez Schwartz and Gal Cohen and et al
Barak Lenz and Opher Lieber and Alan Arazi and Amir Bergman and Avshalom Manevich and Barak Peleg and Ben Aviram and Chen Almagor and Clara Fridman and Dan Padnos and Daniel Gissin and Daniel Jannai and Dor Muhlgay and Dor Zimberg and Edden M. Gerber and Elad Dolev and Eran Krakovsky and Erez Safahi and Erez Schwartz and Gal Cohen and et al. , title =. Th...
work page 2025
-
[28]
Jungo Kasai and Hao Peng and Yizhe Zhang and Dani Yogatama and Gabriel Ilharco and Nikolaos Pappas and Yi Mao and Weizhu Chen and Noah A. Smith , editor =. Finetuning Pretrained. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing,. 2021 , url =
work page 2021
-
[29]
Barret Zoph and Quoc V. Le , title =. 5th International Conference on Learning Representations,. 2017 , url =
work page 2017
-
[30]
Esteban Real and Alok Aggarwal and Yanping Huang and Quoc V. Le , title =. The Thirty-Third. 2019 , url =
work page 2019
-
[31]
Jeffrey Li and Alex Fang and Georgios Smyrnis and Maor Ivgi and Matt Jordan and Samir Yitzhak Gadre and Hritik Bansal and Etash Kumar Guha and Sedrick Scott Keh and Kushal Arora and Saurabh Garg and Rui Xin and Niklas Muennighoff and Reinhard Heckel and Jean Mercat and Mayee F. Chen and Suchin Gururangan and Mitchell Wortsman and Alon Albalak and Yonatan ...
work page 2024
-
[32]
Peters and Arman Cohan , title =
Iz Beltagy and Matthew E. Peters and Arman Cohan , title =. CoRR , volume =. 2020 , url =
work page 2020
-
[33]
9th International Conference on Learning Representations,
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , title =. 9th International Conference on Learning Representations,. 2021 , url =
work page 2021
-
[34]
7th International Conference on Learning Representations,
Ilya Loshchilov and Frank Hutter , title =. 7th International Conference on Learning Representations,. 2019 , url =
work page 2019
-
[35]
Zichuan Fu and Wentao Song and Yejing Wang and Xian Wu and Yefeng Zheng and Yingying Zhang and Derong Xu and Xuetao Wei and Tong Xu and Xiangyu Zhao , title =. CoRR , volume =. 2025 , url =
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.