Bridging Structure and Language: Graph-Based Visual Reasoning for Autonomous Road Understanding
Pith reviewed 2026-05-21 05:21 UTC · model grok-4.3
The pith
Graph structure lets small vision-language models master compositional road reasoning with few examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
State-of-the-art VLMs struggle significantly with structured road reasoning, yet training a small 2- or 4-billion-parameter model with as few as 20 to 80 CRS-enriched scenes yields stable gains in compositional reasoning tasks of varying depth. Verifiable reasoning traces show that CRS-trained models reduce failures at relational scene understanding and leave mainly attribute-recognition errors.
What carries the argument
Combined Road Substrate (CRS), a graph-grounded framework that makes geometric road structure and open-vocabulary semantics jointly executable, supporting recursive graph queries for QA generation plus chain-of-thought traces.
If this is right
- Small models achieve measurable gains in road geometry and relational reasoning once supplied with graph-derived supervision.
- The dominant error type moves from relational misunderstanding to attribute recognition after CRS training.
- Automatic generation of compositionally varied QA pairs scales supervision without manual annotation.
- Structured graph input can be more decisive for precise road understanding than increasing model size.
Where Pith is reading between the lines
- The same graph-plus-language substrate could be applied to other spatial domains that require both geometry and semantics, such as indoor robot navigation.
- If the gains persist on real driving data, hybrid graph-VLM systems become a practical route to safer autonomous perception without ever-larger models.
- The traceable reasoning traces supplied by CRS open a route to post-hoc verification or correction of model outputs in safety-critical settings.
Load-bearing premise
The QA pairs produced by recursive graph queries are logically valid, free of contradictions, and representative of real-world road complexity.
What would settle it
If human-verified QA pairs drawn from the same maps produce no gains or no shift away from relational errors, the value of the automatic CRS generation process would be called into question.
Figures





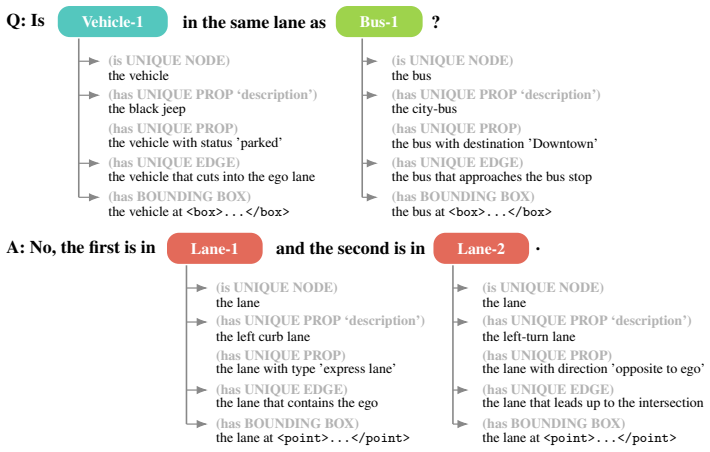




read the original abstract
Structured road understanding of lane geometry, topology, and traffic element relationships is foundational to safe autonomous driving. While vision-language models (VLMs) offer promising semantic flexibility, they lack the geometric and relational grounding required for precise road reasoning. Conversely, traditional modular systems, e.g., HD maps and topological road graphs, provide structural precision but remain semantically rigid. To bridge this gap, we introduce the Combined Road Substrate (CRS), a graph-grounded framework that makes geometric road structure and open-vocabulary semantics jointly executable in a single representation. CRS enables the automatic generation of compositionally complex and linguistically varied question-answer pairs via recursive graph queries, augmented with a "grounding for free" mechanism that ensures logical traceability to specific map elements, and procedurally extracted chain-of-thought supervision traces. We demonstrate that state-of-the-art VLMs - including large, closed-source models - struggle significantly with structured road reasoning, yet training a small 2- or 4-billion-parameter model with as few as 20 to 80 CRS-enriched scenes yields stable gains in compositional reasoning tasks of varying depth. Analysis of model behavior via verifiable reasoning traces reveals a systematic shift in failure modes: whereas baseline models fail at relational scene understanding, CRS-trained models reduce failures to attribute recognition, suggesting that the primary bottleneck in road understanding is not model scale, but the absence of structured supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Combined Road Substrate (CRS), a graph-grounded framework integrating geometric road structure with open-vocabulary semantics for autonomous driving. It claims that state-of-the-art VLMs struggle with structured road reasoning, while training small 2- or 4-billion-parameter models on only 20-80 CRS-enriched scenes yields stable gains in compositional reasoning tasks of varying depth, accompanied by a shift in failure modes from relational to attribute errors via verifiable reasoning traces.
Significance. If the results hold, the work indicates that structured supervision via graph representations can address key bottlenecks in VLMs for safety-critical road understanding more efficiently than scaling model size or data volume. The automatic generation of traceable QA pairs and chain-of-thought traces from recursive graph queries represents a practical contribution for creating falsifiable, compositionally rich training signals in autonomous driving applications.
major comments (2)
- Abstract: the central empirical claim of performance gains and failure-mode shift with 20-80 scenes is asserted without any quantitative metrics, baseline comparisons, statistical significance tests, or details on scene selection and test-set construction, preventing assessment of whether the gains are load-bearing or reproducible.
- Method section on recursive graph queries and QA generation: the claim that automatically generated pairs are logically valid, contradiction-free, and representative of real-world road complexity lacks any quantitative error audit, inter-annotator agreement on held-out samples, or comparison against human-authored queries; this directly affects the validity of the conclusion that structured supervision is the primary bottleneck.
minor comments (2)
- Figure captions and notation: the 'grounding for free' traceability mechanism would benefit from an explicit diagram showing how graph elements map to generated QA pairs and CoT traces.
- Related work: additional citations to recent graph-neural and topological reasoning approaches in autonomous driving would better situate the CRS contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions will be made to improve clarity and rigor without altering the core claims of the work.
read point-by-point responses
-
Referee: Abstract: the central empirical claim of performance gains and failure-mode shift with 20-80 scenes is asserted without any quantitative metrics, baseline comparisons, statistical significance tests, or details on scene selection and test-set construction, preventing assessment of whether the gains are load-bearing or reproducible.
Authors: We agree that the abstract would be strengthened by including specific quantitative indicators to allow immediate evaluation of the reported improvements. The full manuscript already contains detailed performance tables, baseline comparisons against unmodified VLMs, and descriptions of the scene selection and test-set construction in the experiments section. We will revise the abstract to incorporate key metrics (e.g., accuracy gains across compositional depths) and a concise reference to the evaluation protocol, while preserving the high-level summary style. revision: yes
-
Referee: Method section on recursive graph queries and QA generation: the claim that automatically generated pairs are logically valid, contradiction-free, and representative of real-world road complexity lacks any quantitative error audit, inter-annotator agreement on held-out samples, or comparison against human-authored queries; this directly affects the validity of the conclusion that structured supervision is the primary bottleneck.
Authors: The referee is correct that the current manuscript does not report a quantitative error audit or inter-annotator agreement study for the generated QA pairs. The recursive graph query design ensures traceability and logical consistency by construction through grounding to map elements, but we acknowledge the absence of explicit empirical validation of error rates. We will add a dedicated subsection describing a manual audit performed on a held-out sample of generated queries, including error rates, inter-annotator agreement, and a limited comparison to human-authored queries. This addition will directly support the claim regarding the value of structured supervision. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces an independent Combined Road Substrate (CRS) as an external graph representation, uses recursive graph queries to generate QA pairs and chain-of-thought traces, and reports empirical gains from training small models on 20-80 CRS-enriched scenes against state-of-the-art VLMs. These gains and the observed shift in failure modes are measured on tasks produced by the same generation procedure but are not equivalent to the inputs by construction, nor do they rely on self-citation, fitted parameters renamed as predictions, or uniqueness theorems imported from prior author work. The framework supplies its own verifiable traceability mechanism and is evaluated via direct comparison to baseline models, making the central claims externally falsifiable rather than tautological.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Road scenes can be faithfully represented as graphs that jointly encode geometry, topology, and open-vocabulary semantics.
- domain assumption Recursive graph queries produce logically consistent and diverse question-answer pairs suitable for training.
invented entities (1)
-
Combined Road Substrate (CRS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hdmapnet: An online hd map construction and evaluation framework
Qi Li, Yue Wang, Yilun Wang, and Hang Zhao. Hdmapnet: An online hd map construction and evaluation framework. In2022 International Conference on Robotics and Automation (ICRA), pages 4628–4634. IEEE, 2022
work page 2022
-
[2]
Vectormapnet: End- to-end vectorized hd map learning
Yicheng Liu, Tianyuan Yuan, Yue Wang, Yilun Wang, and Hang Zhao. Vectormapnet: End- to-end vectorized hd map learning. InInternational conference on machine learning, pages 22352–22369. PMLR, 2023
work page 2023
-
[3]
Maptr: Structured modeling and learning for online vectorized hd map construction
Bencheng Liao, Shaoyu Chen, Xinggang Wang, Tianheng Cheng, Qian Zhang, Wenyu Liu, and Chang Huang. Maptr: Structured modeling and learning for online vectorized hd map construction. InInternational Conference on Learning Representations, 2023
work page 2023
-
[4]
Huijie Wang, Tianyu Li, Yang Li, Li Chen, Chonghao Sima, Zhenbo Liu, Bangjun Wang, Peijin Jia, Yuting Wang, Shengyin Jiang, et al. Openlane-v2: A topology reasoning benchmark for unified 3d hd mapping.Advances in Neural Information Processing Systems, 36:18873–18884, 2023
work page 2023
-
[5]
Graph-based topology reasoning for driving scenes.arXiv preprint arXiv:2304.05277, 2023
Tianyu Li, Li Chen, Huijie Wang, Yang Li, Jiazhi Yang, Xiangwei Geng, Shengyin Jiang, Yuting Wang, Hang Xu, Chunjing Xu, et al. Graph-based topology reasoning for driving scenes.arXiv preprint arXiv:2304.05277, 2023
-
[6]
Hdnet: Exploiting hd maps for 3D object detection
Bin Yang, Ming Liang, and Raquel Urtasun. Hdnet: Exploiting hd maps for 3D object detection. InCoRL, 2018
work page 2018
-
[7]
Mp3: A unified model to map, perceive, predict and plan
Sergio Casas, Abbas Sadat, and Raquel Urtasun. Mp3: A unified model to map, perceive, predict and plan. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14403–14412, 2021
work page 2021
-
[8]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023
work page 2023
-
[9]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[10]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 91–104, 2025
work page 2025
-
[12]
Babyvision: Visual reasoning beyond language
Liang Chen, Weichu Xie, Yiyan Liang, Hongfeng He, Hans Zhao, Zhibo Yang, Zhiqi Huang, Haoning Wu, Haoyu Lu, Yiping Bao, et al. Babyvision: Visual reasoning beyond language. arXiv preprint arXiv:2601.06521, 2026
-
[13]
Stanford HAI AI Index Team. Technical performance. Technical report, Stanford University Institute for Human-Centered Artificial Intelligence, 2026. Accessed: April 30, 2026. 10
work page 2026
-
[14]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[15]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
work page 2022
-
[16]
Lever- aging vision-language models for improving domain generalization in image classification
Sravanti Addepalli, Ashish Ramayee Asokan, Lakshay Sharma, and R Venkatesh Babu. Lever- aging vision-language models for improving domain generalization in image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23922–23932, 2024
work page 2024
-
[17]
Gemini 3.1 Pro: A smarter model for your most com- plex tasks
The Gemini Team. Gemini 3.1 Pro: A smarter model for your most com- plex tasks. https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-pro/, February 2026
work page 2026
-
[18]
OpenAI. Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/ , March 2026. OpenAI Blog
work page 2026
-
[19]
Anthropic. Claude sonnet 4.5. https://www.anthropic.com, September 2025. Large language model, released September 29, 2025. Model string: claude-sonnet-4-5-20250929
work page 2025
-
[20]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
work page 2020
-
[21]
Argoverse 2: Next generation datasets for self-driving perception and forecasting
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lambert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Ratnesh Kumar, Andrew Hartnett, Jhony Kaesemodel Pontes, Deva Ramanan, Peter Carr, and James Hays. Argoverse 2: Next generation datasets for self-driving perception and forecasting. InProceedings of the Neural Information Processing Systems Track on D...
work page 2021
-
[22]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Anguelov. Scalability in perception...
work page 2020
-
[23]
Cross-view transformers for real-time map-view semantic segmentation
Brady Zhou and Philipp Krähenbühl. Cross-view transformers for real-time map-view semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13760–13769, 2022
work page 2022
-
[24]
Heiko G. Seif and Xiaolong Hu. Autonomous driving in the icity—hd maps as a key challenge of the automotive industry.Engineering, 2:159–162, 2016
work page 2016
-
[25]
Juyeb Shin, Hyeonjun Jeong, Francois Rameau, and Dongsuk Kum. Instagram: Instance-level graph modeling for vectorized hd map learning.IEEE Transactions on Intelligent Transportation Systems, 26(2):1889–1899, 2025
work page 2025
-
[26]
Bencheng Liao, Shaoyu Chen, Yunchi Zhang, Bo Jiang, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Maptrv2: An end-to-end framework for online vectorized hd map construction.International Journal of Computer Vision, 133(3):1352–1374, 2025
work page 2025
-
[27]
Lanesegnet: Map learning with lane segment perception for autonomous driving
Tianyu Li, Peijin Jia, Bangjun Wang, Li Chen, Kun Jiang, Junchi Yan, and Hongyang Li. Lanesegnet: Map learning with lane segment perception for autonomous driving. InICLR, 2024
work page 2024
-
[28]
Topomlp: A simple yet strong pipeline for driving topology reasoning.ICLR, 2024
Dongming Wu, Jiahao Chang, Fan Jia, Yingfei Liu, Tiancai Wang, and Jianbing Shen. Topomlp: A simple yet strong pipeline for driving topology reasoning.ICLR, 2024. 11
work page 2024
-
[29]
Augmenting lane perception and topology understanding with standard definition navigation maps
Katie Z Luo, Xinshuo Weng, Yan Wang, Shuang Wu, Jie Li, Kilian Q Weinberger, Yue Wang, and Marco Pavone. Augmenting lane perception and topology understanding with standard definition navigation maps. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 4029–4035. IEEE, 2024
work page 2024
-
[30]
Graphad: Interaction scene graph for end-to-end autonomous driving
Yunpeng Zhang, Deheng Qian, Ding Li, Yifeng Pan, Yong Chen, Zhenbao Liang, Zhiyao Zhang, Yingzong Liu, Jianhui Mei, Maolei Fu, Yun Ye, Zhujin Liang, Yi Shan, and Dalong Du. Graphad: Interaction scene graph for end-to-end autonomous driving. In James Kwok, editor,Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJ...
work page 2025
-
[31]
Fabian Schmidt, Markus Enzweiler, and Abhinav Valada. Graphpilot: Grounded scene graph conditioning for language-based autonomous driving.arXiv preprint arXiv:2511.11266, 2025
-
[32]
Vqa: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. InProceedings of the IEEE international conference on computer vision, pages 2425–2433, 2015
work page 2015
-
[33]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017
work page 2017
-
[34]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019
work page 2019
-
[35]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
work page 2024
-
[36]
Embodied scene understanding for vision language models via metavqa
Weizhen Wang, Chenda Duan, Zhenghao Peng, Yuxin Liu, and Bolei Zhou. Embodied scene understanding for vision language models via metavqa. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22453–22464, 2025
work page 2025
-
[37]
Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario
Tianwen Qian, Jingjing Chen, Linhai Zhuo, Yang Jiao, and Yu-Gang Jiang. Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4542–4550, 2024
work page 2024
-
[38]
Lingoqa: Visual question answering for autonomous driving
Ana-Maria Marcu, Long Chen, Jan Hünermann, Alice Karnsund, Benoit Hanotte, Prajwal Chidananda, Saurabh Nair, Vijay Badrinarayanan, Alex Kendall, Jamie Shotton, et al. Lingoqa: Visual question answering for autonomous driving. InEuropean Conference on Computer Vision, pages 252–269. Springer, 2024
work page 2024
-
[39]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InEuropean conference on computer vision, pages 256–274. Springer, 2024
work page 2024
-
[40]
Talk2car: Taking control of your self-driving car
Thierry Deruyttere, Simon Vandenhende, Dusan Grujicic, Luc Van Gool, and Marie Francine Moens. Talk2car: Taking control of your self-driving car. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2088–2098, 2019
work page 2019
-
[41]
Drama: Joint risk localization and captioning in driving
Srikanth Malla, Chiho Choi, Isht Dwivedi, Joon Hee Choi, and Jiachen Li. Drama: Joint risk localization and captioning in driving. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1043–1052, 2023. 12
work page 2023
-
[42]
Talk2bev: Language-enhanced bird’s-eye view maps for autonomous driving
Tushar Choudhary, Vikrant Dewangan, Shivam Chandhok, Shubham Priyadarshan, Anushka Jain, Arun K Singh, Siddharth Srivastava, Krishna Murthy Jatavallabhula, and K Madhava Krishna. Talk2bev: Language-enhanced bird’s-eye view maps for autonomous driving. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 16345–16352. IEEE, 2024
work page 2024
-
[43]
Drivevlm: The convergence of autonomous driving and large vision-language models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models. InConference on Robot Learning (CoRL), 2024
work page 2024
-
[44]
Reason2drive: Towards interpretable and chain-based reasoning for autonomous driving
Ming Nie, Renyuan Peng, Chunwei Wang, Xinyue Cai, Jianhua Han, Hang Xu, and Li Zhang. Reason2drive: Towards interpretable and chain-based reasoning for autonomous driving. In European Conference on Computer Vision, pages 292–308. Springer, 2024
work page 2024
-
[45]
DRIVINGVQA: A dataset for interleaved visual chain-of-thought in real-world driving scenar- ios
Charles Corbière, Simon Roburin, Syrielle Montariol, Antoine Bosselut, and Alexandre Alahi. DRIVINGVQA: A dataset for interleaved visual chain-of-thought in real-world driving scenar- ios. In Vera Demberg, Kentaro Inui, and Lluís Marquez, editors,Findings of the Association for Computational Linguistics: EACL 2026, pages 3309–3333, Rabat, Morocco, March 2...
work page 2026
-
[46]
Show and tell: A neural image caption generator
Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan. Show and tell: A neural image caption generator. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3156–3164, 2015
work page 2015
-
[47]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[48]
Yang Zhou, Hongyi Liu, Zhuoming Chen, Yuandong Tian, and Beidi Chen. Gsm-infinite: How do your llms behave over infinitely increasing context length and reasoning complexity?arXiv preprint arXiv:2502.05252, 2025
-
[49]
Phantomwiki: On-demand datasets for reasoning and retrieval evaluation
Albert Gong, Kamil˙e Stankeviˇci¯ut˙e, Chao Wan, Anmol Kabra, Raphael Thesmar, Johann Lee, Julius Klenke, Carla P Gomes, and Kilian Q Weinberger. Phantomwiki: On-demand datasets for reasoning and retrieval evaluation. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[50]
Image retrieval using scene graphs
Justin Johnson, Ranjay Krishna, Michael Stark, Li-Jia Li, David Shamma, Michael Bernstein, and Li Fei-Fei. Image retrieval using scene graphs. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3668–3678, 2015
work page 2015
-
[51]
Auto-encoding scene graphs for image captioning
Xu Yang, Kaihua Tang, Hanwang Zhang, and Jianfei Cai. Auto-encoding scene graphs for image captioning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10685–10694, 2019
work page 2019
-
[52]
Explainable and explicit visual reasoning over scene graphs
Jiaxin Shi, Hanwang Zhang, and Juanzi Li. Explainable and explicit visual reasoning over scene graphs. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8376–8384, 2019
work page 2019
-
[53]
Vinay Damodaran, Sharanya Chakravarthy, Akshay Kumar, Anjana Umapathy, Teruko Mita- mura, Yuta Nakashima, Noa Garcia, and Chenhui Chu. Understanding the role of scene graphs in visual question answering.arXiv preprint arXiv:2101.05479, 2021
-
[54]
Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh V Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, and Bryan Hooi. G-retriever: Retrieval-augmented generation for textual graph understanding and question answering.Advances in Neural Information Processing Systems, 37, 2024
work page 2024
-
[55]
Graphvis: Boosting llms with visual knowledge graph integration
Yihe Deng, Chenchen Ye, Zijie Huang, Mingyu Derek Ma, Yiwen Kou, and Wei Wang. Graphvis: Boosting llms with visual knowledge graph integration. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 67511–67534. Curran Associates, Inc., 2024. 13
work page 2024
-
[56]
Localization is all you evaluate: Data leakage in online mapping datasets and how to fix it
Adam Lilja, Junsheng Fu, Erik Stenborg, and Lars Hammarstrand. Localization is all you evaluate: Data leakage in online mapping datasets and how to fix it. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22150–22159, 2024
work page 2024
-
[57]
OpenAI. GPT-4o mini: Advancing Cost-Efficient Intelligence.https://openai.com/index/ gpt-4o-mini-advancing-cost-efficient-intelligence/, July 2024. OpenAI Blog
work page 2024
- [58]
-
[59]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
What is the direction of d∗(l)?
Google DeepMind. Gemma 4: Our Most Intelligent Open Models. https://deepmind. google/models/gemma/gemma-4/, April 2026. Google DeepMind. 14 A Supplementary Material A.1 Query instantiation Let Gt = (V t, Et) denote the CRS scene graph at the queried frame and let Gt−w:t denote the temporal window of size w= 4 used by temporal queries. τ(n) is the node typ...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.