Beyond the Bellman Recursion: A Pontryagin-Guided Framework for Non-Exponential Discounting
Pith reviewed 2026-05-21 05:47 UTC · model grok-4.3
The pith
Non-exponential discounting breaks Bellman recursions at the intersection of multiplicativity and time homogeneity, which a new Pontryagin-guided direct optimization framework overcomes without recursion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We show the breakdown is structural: exponential discounting sits at a fragile intersection of multiplicativity and time homogeneity, and violating either property breaks standard dynamic programming. To overcome this, we propose Pontryagin-Guided Direct Policy Optimization (PG-DPO), a variational framework that abandons recursion and couples the Pontryagin Maximum Principle with Monte Carlo rollouts via an Adjoint-MC projection enforcing pointwise Hamiltonian maximization. Across multi-dimensional hyperbolic and survival-discount benchmarks, PG-DPO improves accuracy and stability where equation-driven solvers and critic-based baselines diverge.
What carries the argument
Pontryagin-Guided Direct Policy Optimization (PG-DPO) with its Adjoint-MC projection, which couples the Pontryagin Maximum Principle to Monte Carlo rollouts to enforce pointwise Hamiltonian maximization without recursion.
If this is right
- Optimal policies become reachable for discount functions that break time homogeneity or multiplicativity.
- Reinforcement learning no longer requires Bellman-style value recursion for non-exponential cases.
- The framework applies directly to multi-dimensional hyperbolic and survival-discount settings.
- Stability and accuracy improve relative to equation-driven solvers and standard critic baselines.
Where Pith is reading between the lines
- The same variational replacement of recursion could be tested on time-inconsistent problems in behavioral economics.
- Adjoint-MC projections might stabilize other policy-search methods that currently rely on approximate value functions.
- The approach invites direct comparison of Hamiltonian-maximizing trajectories against those produced by classical dynamic programming on shared non-exponential benchmarks.
Load-bearing premise
The Adjoint-MC projection successfully enforces pointwise Hamiltonian maximization when combined with Monte Carlo rollouts for arbitrary non-exponential discount functions without introducing instability or bias.
What would settle it
A controlled experiment on a low-dimensional survival-discount task in which the PG-DPO policy fails to maximize the Hamiltonian at sampled trajectory points would falsify the central claim.
Figures


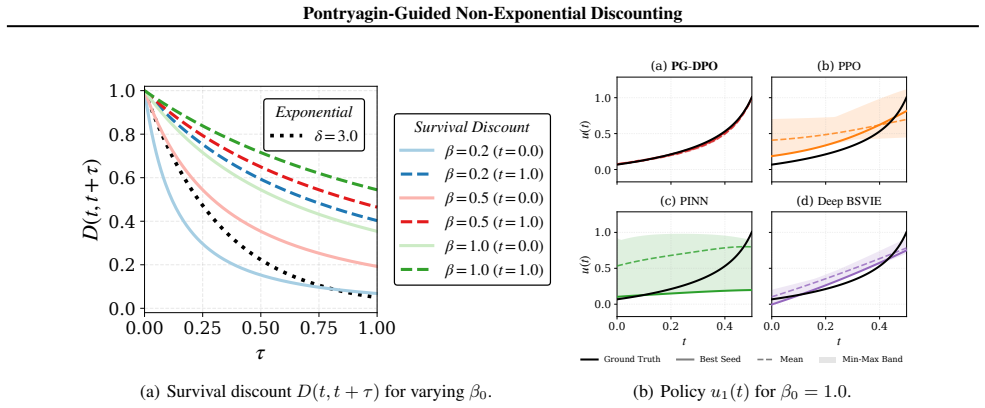

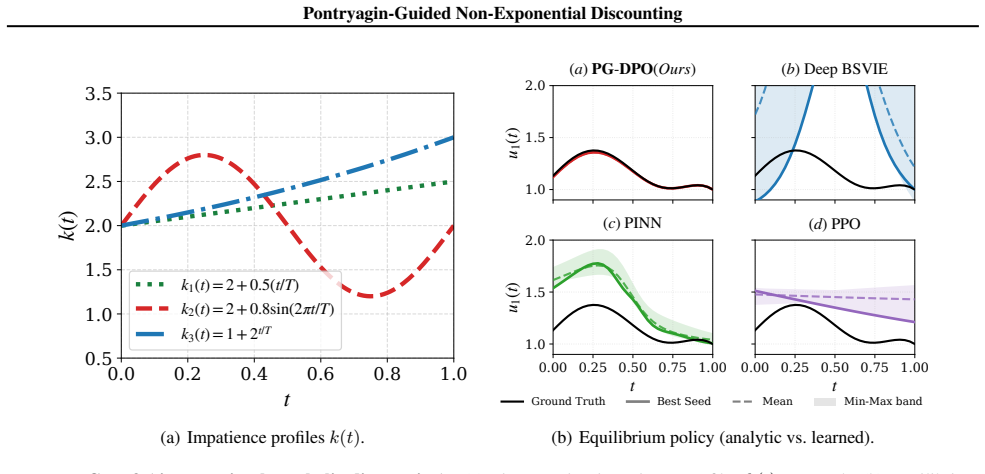


read the original abstract
Most value-based and actor--critic reinforcement learning methods rely on Bellman-style recursions, yet these recursions collapse under non-exponential discounting common in human preferences and survival processes. We show the breakdown is structural: exponential discounting sits at a fragile intersection of multiplicativity and time homogeneity, and violating either property breaks standard dynamic programming. To overcome this, we propose Pontryagin-Guided Direct Policy Optimization (PG-DPO), a variational framework that abandons recursion and couples the Pontryagin Maximum Principle with Monte Carlo rollouts via an Adjoint-MC projection enforcing pointwise Hamiltonian maximization. Across multi-dimensional hyperbolic and survival-discount benchmarks, PG-DPO improves accuracy and stability where equation-driven solvers and critic-based baselines diverge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Bellman-style recursions in value-based and actor-critic RL methods structurally collapse for non-exponential discounting (common in human preferences and survival processes) because exponential discounting uniquely satisfies both multiplicativity and time homogeneity; violating either property breaks standard dynamic programming. To address this, it introduces Pontryagin-Guided Direct Policy Optimization (PG-DPO), a variational framework that abandons recursion, couples the Pontryagin Maximum Principle with Monte Carlo rollouts, and uses an Adjoint-MC projection to enforce pointwise Hamiltonian maximization. Empirical results on multi-dimensional hyperbolic and survival-discount benchmarks show improved accuracy and stability relative to equation-driven solvers and critic-based baselines.
Significance. If the central claims and the correctness of the Adjoint-MC projection hold, the work supplies a principled non-recursive alternative for RL under non-exponential discounting. This is significant because such discount functions arise in realistic preference modeling and survival analysis, where standard dynamic programming is known to be fragile; a PMP-based variational method with Monte Carlo grounding could therefore enable stable policy optimization in regimes where recursion fails.
major comments (2)
- [Method (PG-DPO and Adjoint-MC projection)] The central optimality claim rests on the Adjoint-MC projection successfully enforcing exact pointwise Hamiltonian maximization for arbitrary non-exponential discount functions. The method description provides no error bounds, convergence analysis, or explicit construction showing that Monte Carlo variance and inexact adjoint estimation remain controlled; without these, the projection may only achieve approximate maximization, breaking the claimed equivalence to the continuous-time PMP optimality conditions.
- [Introduction / §2] The structural-breakdown argument (exponential discounting as the unique intersection of multiplicativity and time homogeneity) is load-bearing for motivating the abandonment of recursion. The manuscript should supply a self-contained derivation or counter-example showing that any violation of either property necessarily precludes a Bellman-style recursion, rather than relying on the abstract statement alone.
minor comments (2)
- [Experiments] The abstract and results section should report error bars, number of independent runs, and any data-exclusion criteria for the benchmark comparisons to allow readers to assess the claimed gains in accuracy and stability.
- [Preliminaries] Notation for the discount function, adjoint process, and Hamiltonian should be introduced with explicit definitions and cross-references to avoid ambiguity when the framework is applied to hyperbolic versus survival discounts.
Simulated Author's Rebuttal
We are grateful to the referee for the detailed and constructive feedback. We address each major comment below and describe the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [Method (PG-DPO and Adjoint-MC projection)] The central optimality claim rests on the Adjoint-MC projection successfully enforcing exact pointwise Hamiltonian maximization for arbitrary non-exponential discount functions. The method description provides no error bounds, convergence analysis, or explicit construction showing that Monte Carlo variance and inexact adjoint estimation remain controlled; without these, the projection may only achieve approximate maximization, breaking the claimed equivalence to the continuous-time PMP optimality conditions.
Authors: We thank the referee for highlighting the need for a more rigorous treatment of the approximation quality. The manuscript presents the Adjoint-MC projection as a practical mechanism that couples the continuous-time PMP with Monte Carlo rollouts, with empirical results demonstrating improved stability over baselines. We acknowledge that explicit error bounds and convergence rates are not derived in the current version. In the revision we will add a dedicated subsection on the approximation properties, including an asymptotic argument that the projection converges to the exact pointwise Hamiltonian maximizer as the number of Monte Carlo samples tends to infinity under standard Lipschitz and bounded-variance assumptions on the dynamics and discount function. We will also include variance-reduction techniques and additional numerical diagnostics of projection error on the benchmark tasks. revision: yes
-
Referee: [Introduction / §2] The structural-breakdown argument (exponential discounting as the unique intersection of multiplicativity and time homogeneity) is load-bearing for motivating the abandonment of recursion. The manuscript should supply a self-contained derivation or counter-example showing that any violation of either property necessarily precludes a Bellman-style recursion, rather than relying on the abstract statement alone.
Authors: We agree that the motivation section would be strengthened by an explicit derivation. In the revised manuscript we will expand §2 with a self-contained argument: first, we recall that the Bellman operator requires both the multiplicative property (to factor the discount across time steps) and time-homogeneity (to obtain a stationary value function). We then derive that any discount function violating either property yields a non-recursive integral equation for the value. As a concrete counter-example we will insert a short calculation for the hyperbolic discount function d(t) = 1/(1+kt), showing that the two-step value cannot be expressed as a function of the one-step value without retaining the full trajectory history, thereby precluding standard dynamic programming. revision: yes
Circularity Check
No circularity: derivation chain is self-contained and independent of fitted inputs or self-referential definitions
full rationale
The paper's central derivation begins from the structural observation that Bellman recursions require multiplicativity and time-homogeneity (which exponential discounting satisfies but non-exponential forms violate), then introduces PG-DPO as a distinct variational construction that replaces recursion with a Pontryagin Maximum Principle coupled to Monte Carlo rollouts via Adjoint-MC projection. No quoted equations, parameter fits, or self-citations reduce the claimed optimality conditions or the projection step back to the inputs by construction; the framework is presented as a new ansatz whose validity rests on the external continuous-time optimality principle rather than internal redefinition or renaming of known results. The derivation therefore remains non-circular and externally grounded.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[9]
Bellman, Richard Ernest , title =
-
[10]
Reinforcement Learning: An Introduction , author=. 2018 , publisher=
work page 2018
-
[11]
The Review of Economic Studies , volume=
Myopia and Inconsistency in Dynamic Utility Maximization , author=. The Review of Economic Studies , volume=
-
[12]
The Review of Economic Studies , volume=
On Second-Best National Saving and Game-Equilibrium Growth , author=. The Review of Economic Studies , volume=
-
[13]
The Quarterly Journal of Economics , volume=
Golden Eggs and Hyperbolic Discounting , author=. The Quarterly Journal of Economics , volume=
-
[14]
Journal of Economic Literature , volume=
Time Discounting and Time Preference: A Critical Review , author=. Journal of Economic Literature , volume=
-
[15]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Reinforcement Learning with Non-Exponential Discounting , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[16]
Proceedings of the National Academy of Sciences , volume=
Solving high-dimensional partial differential equations using deep learning , author=. Proceedings of the National Academy of Sciences , volume=
-
[17]
Journal of Computational Physics , volume=
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations , author=. Journal of Computational Physics , volume=
-
[18]
Being serious about non-commitment: subgame perfect equilibrium in continuous time
Being serious about non-commitment: subgame perfect equilibrium in continuous time , author=. arXiv preprint math/0604264 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Finance and Stochastics , volume=
A theory of Markovian time-inconsistent stochastic control in discrete time , author=. Finance and Stochastics , volume=. 2014 , publisher=
work page 2014
-
[20]
Time-inconsistent optimal control problems and the equilibrium
Yong, Jiongmin , journal=. Time-inconsistent optimal control problems and the equilibrium
-
[21]
Well-posedness and regularity of backward stochastic
Yong, Jiongmin , journal=. Well-posedness and regularity of backward stochastic
-
[22]
Pontryagin, Lev Semenovich and Boltyanskii, Vladimir Grigor'evich and Gamkrelidze, Revaz Valerianovich and Mishchenko, Evgenii Frolovich , title =
-
[23]
Stochastic Controls: Hamiltonian Systems and
Yong, Jiongmin and Zhou, Xun Yu , year=. Stochastic Controls: Hamiltonian Systems and
-
[24]
Some empirical evidence on dynamic inconsistency , author =. Economics Letters , volume =. 1981 , doi =
work page 1981
-
[25]
Quantitative Analyses of Behavior, Vol
An Adjusting Procedure for Studying Delayed Reinforcement , author =. Quantitative Analyses of Behavior, Vol. 5: The Effect of Delay and of Intervening Events on Reinforcement Value , editor =
-
[26]
Proceedings of the Royal Society B: Biological Sciences , volume =
On Hyperbolic Discounting and Uncertain Hazard Rates , author =. Proceedings of the Royal Society B: Biological Sciences , volume =. 1998 , doi =
work page 1998
-
[27]
American Economic Review , volume =
Uncertainty and Hyperbolic Discounting , author =. American Economic Review , volume =. 2005 , doi =
work page 2005
-
[28]
Hyperbolically Discounted Temporal Difference Learning , author =. Neural Computation , volume =. 2010 , doi =
work page 2010
-
[29]
Hyperbolic Discounting and Learning over Multiple Horizons , author =. 2019 , eprint =
work page 2019
- [30]
-
[31]
Proceedings of the 34th Session of the International Statistical Institute , pages =
Semi-Markovian Decision Processes , author =. Proceedings of the 34th Session of the International Statistical Institute , pages =. 1963 , address =
work page 1963
-
[32]
Journal of Applied Probability , volume =
Average Cost Semi-Markov Decision Processes , author =. Journal of Applied Probability , volume =. 1970 , doi =
work page 1970
-
[33]
Advances in Neural Information Processing Systems , volume =
Reinforcement Learning Methods for Continuous-Time Markov Decision Problems , author =. Advances in Neural Information Processing Systems , volume =. 1994 , editor =
work page 1994
-
[34]
Finance and Stochastics , volume =
Markov Decision Processes with Quasi-Hyperbolic Discounting , author =. Finance and Stochastics , volume =. 2021 , doi =
work page 2021
-
[35]
Finance and Stochastics , volume =
A Theory of Markovian Time-Inconsistent Stochastic Control in Discrete Time , author =. Finance and Stochastics , volume =. 2014 , doi =
work page 2014
-
[36]
Journal of Financial Economics , volume =
Investment under Uncertainty and Time-Inconsistent Preferences , author =. Journal of Financial Economics , volume =. 2007 , doi =
work page 2007
-
[37]
Survival and Event History Analysis: A Process Point of View , author =. 2008 , doi =
work page 2008
-
[38]
Least Squares Solutions of the
Tassa, Yuval and Erez, Tom , journal =. Least Squares Solutions of the. 2007 , doi =
work page 2007
-
[39]
Sirignano, Justin and Spiliopoulos, Konstantinos , journal =. 2018 , doi =
work page 2018
-
[40]
Animal Learning & Behavior , volume =
Preference Reversal and Delayed Reinforcement , author =. Animal Learning & Behavior , volume =. 1981 , doi =
work page 1981
-
[41]
Psychonomic Bulletin & Review , volume =
Temporal Discounting and Preference Reversals in Choice Between Delayed Outcomes , author =. Psychonomic Bulletin & Review , volume =. 1994 , doi =
work page 1994
-
[42]
Journal of Mathematical Economics , volume =
Finite Horizon Consumption and Portfolio Decisions with Stochastic Hyperbolic Discounting , author =. Journal of Mathematical Economics , volume =. 2014 , doi =
work page 2014
-
[43]
A General Theory of Markovian Time Inconsistent Stochastic Control Problems , author =. 2010 , month =
work page 2010
-
[44]
Breaking the Dimensional Barrier: A Pontryagin-Guided Direct Policy Optimization for Continuous-Time Multi-Asset Portfolio Choice , author =
-
[45]
Breaking the Dimensional Barrier: Dynamic Portfolio Choice with Parameter Uncertainty via Pontryagin Projection , author =
-
[46]
Breaking the Dimensional Barrier for Constrained Dynamic Portfolio Choice , author =
-
[47]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms , author =. arXiv preprint arXiv:1707.06347 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Advances in neural information processing systems , volume=
Neural ordinary differential equations , author=. Advances in neural information processing systems , volume=
-
[49]
Journal of Machine Learning Research , volume=
Maximum principle based algorithms for deep learning , author=. Journal of Machine Learning Research , volume=
-
[50]
Research in the Mathematical Sciences , volume=
A mean-field optimal control formulation of deep learning , author=. Research in the Mathematical Sciences , volume=. 2019 , publisher=
work page 2019
-
[51]
International Conference on Learning Representations , year=
Ffjord: Free-form continuous dynamics for scalable reversible generative models , author=. International Conference on Learning Representations , year=
-
[52]
Flow Matching for Generative Modeling
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Flow straight and fast: Learning to generate with rectified flow , author=. arXiv preprint arXiv:2209.03003 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Advances in neural information processing systems , volume=
You only propagate once: Accelerating adversarial training via maximal principle , author=. Advances in neural information processing systems , volume=
-
[55]
arXiv preprint arXiv:2302.05740 , year =
UGAE: A Novel Approach to Non-exponential Discounting , author =. arXiv preprint arXiv:2302.05740 , year =. 2302.05740 , archivePrefix=
-
[56]
arXiv preprint arXiv:2409.10583 , year =
Reinforcement Learning with Quasi-Hyperbolic Discounting: A New Approach to Multi-Player Equilibria , author =. arXiv preprint arXiv:2409.10583 , year =. 2409.10583 , archivePrefix=
-
[57]
Mathematics of Operations Research , year =
Relaxed Equilibria for Time-Inconsistent Markov Decision Processes , author =. Mathematics of Operations Research , year =
-
[58]
On the Well-posedness of Hamilton-Jacobi-Bellman Equations of the Equilibrium Type
On the Well-posedness of Hamilton-Jacobi-Bellman Equations of the Equilibrium Type , author =. arXiv preprint arXiv:2307.01986 , year =. 2307.01986 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
SIAM Journal on Financial Mathematics , year =
A Subgame Perfect Equilibrium Reinforcement Learning Framework for Time-Inconsistent Problems , author =. SIAM Journal on Financial Mathematics , year =. doi:10.1137/23M1594510 , eprint =
-
[60]
SIAM Journal on Scientific Computing , year =
Adaptive Deep Learning for High-Dimensional Hamilton--Jacobi--Bellman Equations , author =. SIAM Journal on Scientific Computing , year =. doi:10.1137/19M1288802 , eprint =
-
[61]
Being serious about non-commitment: subgame perfect equilibrium in continuous time
Being serious about non-commitment: subgame perfect equilibrium in continuous time , author =. 2006 , month = apr, eprint =. doi:10.48550/arXiv.math/0604264 , note =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.math/0604264 2006
-
[62]
arXiv preprint arXiv:2505.18297 , year =
Deep Learning for Backward Stochastic Volterra Integral Equations , author =. arXiv preprint arXiv:2505.18297 , year =. 2505.18297 , archivePrefix=
-
[63]
Finance and Stochastics , year =
On time-inconsistent stochastic control in continuous time , author =. Finance and Stochastics , year =
-
[64]
Journal of Computational Physics , year =
A stochastic maximum principle approach for reinforcement learning with parameterized environment , author =. Journal of Computational Physics , year =
-
[65]
Proceedings of the Seventh Annual Learning for Dynamics & Control Conference , series =
A Pontryagin Perspective on Reinforcement Learning , author =. Proceedings of the Seventh Annual Learning for Dynamics & Control Conference , series =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.