Beyond Text-to-SQL: An Agentic LLM System for Governed Enterprise Analytics APIs
Pith reviewed 2026-05-21 05:24 UTC · model grok-4.3
The pith
Analytic Agent translates natural language into secure, policy-compliant interactions with enterprise analytics APIs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Analytic Agent reliably interprets user goals, validates permissions, executes governed queries, and generates compliant visualizations through multi-step reasoning and policy-aware orchestration.
What carries the argument
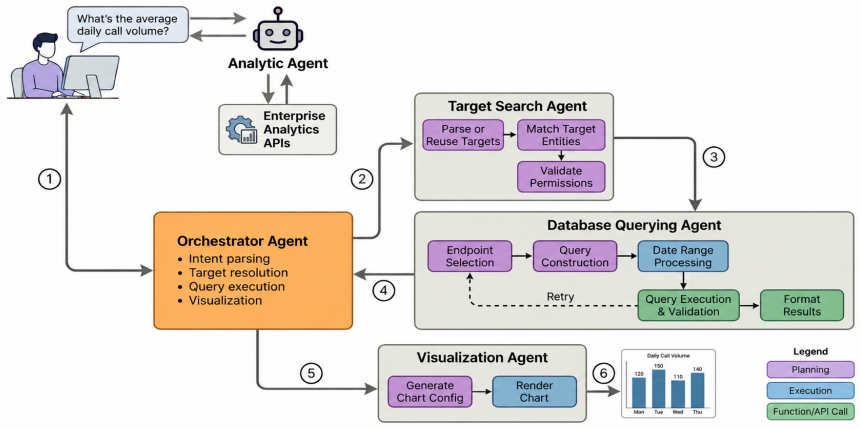
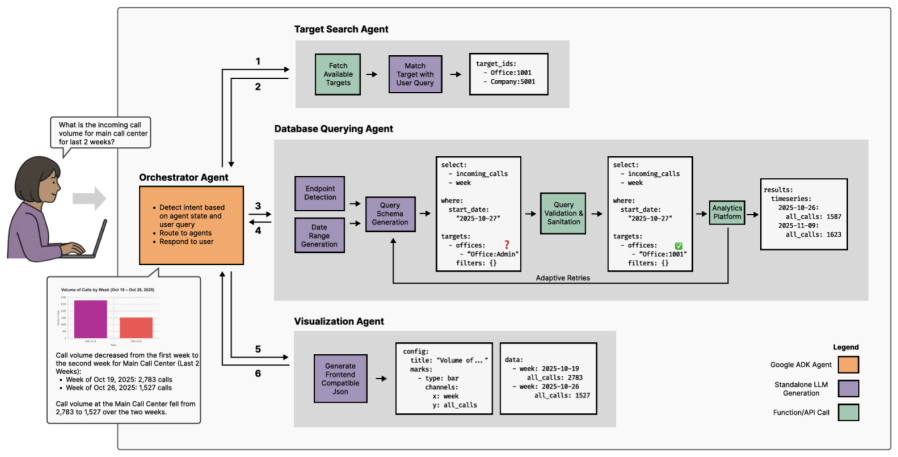
Analytic Agent, an LLM-based agentic system that performs policy-aware orchestration to keep all computation inside governed enterprise APIs rather than delegating it to the model.
If this is right
- Non-technical users gain access to enterprise data through natural language while all calculations remain inside audited APIs.
- Compliance and audit requirements are satisfied because the system never lets the model perform aggregation or mathematical logic directly.
- The same orchestration pattern can be applied to any set of governed APIs that already encapsulate business rules.
- Evaluation on real enterprise scenarios provides evidence that multi-step reasoning plus policy checks can replace direct Text-to-SQL in regulated settings.
Where Pith is reading between the lines
- Similar agent patterns could be tested in other regulated domains such as financial reporting or clinical data access.
- Extending the orchestration layer with explicit policy engines might reduce reliance on the LLM's implicit reasoning for permission checks.
- Scalability tests on larger and more diverse query sets would reveal whether the current multi-step process remains reliable at production volumes.
Load-bearing premise
An LLM can consistently validate permissions and orchestrate policy checks across varied enterprise scenarios without producing compliance violations or misinterpretations.
What would settle it
A documented case in which the agent approves a query that violates an access policy or returns a visualization that breaches governance rules.
Figures

read the original abstract
Enterprise analytics aims to make organizational data accessible for decision-making, yet non-technical users still face barriers when using traditional business intelligence tools or Text-to-SQL systems. While recent Text-to-SQL approaches based on Large Language Models (LLMs) promise natural language access to structured data, they fall short in enterprise settings where analytics pipelines rely on governed APIs rather than raw databases. In practice, these APIs encapsulate complex business logic to ensure consistency, auditability, and security. However, delegating mathematical or aggregation logic to an LLM introduces reliability and compliance risks. To this end, we present Analytic Agent, an LLM-based agentic system that translates natural language intents into secure interactions with enterprise analytics APIs. Evaluated on 90 real enterprise use cases constructed by domain experts, it reliably interprets user goals, validates permissions, executes governed queries, and generates compliant visualizations through multi-step reasoning and policy-aware orchestration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Analytic Agent, an LLM-based agentic system that translates natural language user intents into secure interactions with governed enterprise analytics APIs. It emphasizes multi-step reasoning and policy-aware orchestration to handle permission validation, query execution, and compliant visualization generation, addressing limitations of Text-to-SQL systems in enterprise settings with encapsulated business logic. The central evaluation consists of 90 real enterprise use cases constructed by domain experts, on which the system is claimed to perform reliably.
Significance. If the reliability claims are substantiated with quantitative evidence, the work could advance governed natural language interfaces for enterprise data by reducing compliance risks associated with delegating logic to LLMs. The focus on API orchestration rather than raw database access is a relevant direction for practical deployment in regulated environments.
major comments (2)
- [Evaluation] Evaluation section: The abstract and evaluation claim that the system 'reliably interprets user goals, validates permissions, executes governed queries, and generates compliant visualizations' on 90 domain-expert use cases, yet no quantitative metrics (e.g., success rate, precision/recall on permission checks, rate of caught vs. missed policy violations, or inter-rater agreement) or baselines are reported. This directly undermines assessment of the central claim regarding consistent policy-aware orchestration.
- [§3] §3 (System Architecture): The description of multi-step reasoning and policy-aware orchestration lacks concrete mechanisms or examples showing how the LLM is constrained to avoid compliance violations in edge cases such as ambiguous permissions or conflicting rules; without this, the reliability assertion rests on untested assumptions about LLM consistency.
minor comments (1)
- [Abstract] Abstract: The phrase 'real enterprise use cases' would be clearer if it specified whether the cases include adversarial or edge-case scenarios for permission validation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important areas for strengthening the presentation of our evaluation and system details. We address each major comment below and have made revisions to the manuscript where appropriate to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The abstract and evaluation claim that the system 'reliably interprets user goals, validates permissions, executes governed queries, and generates compliant visualizations' on 90 domain-expert use cases, yet no quantitative metrics (e.g., success rate, precision/recall on permission checks, rate of caught vs. missed policy violations, or inter-rater agreement) or baselines are reported. This directly undermines assessment of the central claim regarding consistent policy-aware orchestration.
Authors: We agree that the original manuscript would benefit from more explicit quantitative reporting to allow readers to better assess the reliability claims. The 90 use cases were constructed and verified by domain experts, with each case manually reviewed for correct intent interpretation, permission validation, query execution, and visualization compliance. In the revised version, we have added a dedicated evaluation subsection that reports an overall task success rate across the cases, along with a breakdown of outcomes for permission checks and policy violation handling. We also include a comparison to a baseline of direct LLM prompting without the agentic orchestration to highlight the contribution of the governed API approach. These additions directly address the request for metrics while respecting the confidential nature of the enterprise scenarios. revision: yes
-
Referee: [§3] §3 (System Architecture): The description of multi-step reasoning and policy-aware orchestration lacks concrete mechanisms or examples showing how the LLM is constrained to avoid compliance violations in edge cases such as ambiguous permissions or conflicting rules; without this, the reliability assertion rests on untested assumptions about LLM consistency.
Authors: We acknowledge that the original §3 provided a high-level overview of the workflow but could be strengthened with more explicit mechanisms and examples. The architecture constrains the LLM through a sequence of validated tool calls and external policy engine checks rather than depending on the model's internal consistency alone. In the revised manuscript, we have expanded §3.2 with a concrete walkthrough of an edge case involving ambiguous permissions: the agent first invokes the policy validation tool, receives a partial match result, and then either requests user clarification or applies the strictest applicable rule before proceeding to query execution. This illustrates the orchestration's use of deterministic gates to mitigate risks in conflicting or unclear scenarios. revision: yes
Circularity Check
No circularity detected; evaluation is external and self-contained.
full rationale
The paper presents a descriptive system (Analytic Agent) for translating natural language to governed enterprise APIs and reports results on 90 domain-expert use cases. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The central reliability claim rests on external evaluation rather than any internal derivation that reduces to the paper's own inputs by construction. This is the expected outcome for a system-description paper without mathematical derivations.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Analytic Agent, an LLM-based agentic system that translates natural language intents into secure interactions with enterprise analytics APIs... multi-step reasoning and policy-aware orchestration.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ðor ¯de Klisura and Anthony Rios
A survey on deep learning approaches for text- to-sql.The VLDB Journal, 32(4):905–936. Ðor ¯de Klisura and Anthony Rios. 2025. Unmasking database vulnerabilities: Zero-knowledge schema inference attacks in text-to-SQL systems. InFind- ings of the Association for Computational Linguistics: NAACL 2025, pages 6954–6976, Albuquerque, New Mexico. Association f...
work page 2025
-
[2]
AI knowledge assist: An automated approach for the creation of knowledge bases for conversa- tional AI agents. InProceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Pro- cessing: Industry Track, pages 1856–1866, Suzhou (China). Association for Computational Linguistics. Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen...
work page 2025
-
[3]
Nl4dv: A toolkit for generating analytic speci- fications for data visualization from natural language queries.IEEE Transactions on Visualization and Computer Graphics, 27(2):369–379. OpenAI. 2025. Gpt-5 system card. https://openai.com/index/ gpt-5-system-card/ . Last Accessed: November 17, 2025. Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
AlignScore: Evaluating factual consistency with a unified alignment function. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11328–11348, Toronto, Canada. Association for Computational Linguistics. Weixu Zhang, Yifei Wang, Yuanfeng Song, Victor Jun- qiu Wei, Yuxing Tian, Yiyan Qi, J...
work page 2024
-
[5]
Establish user permissions for requested data targets
-
[6]
Verify access using the target_search skill
-
[7]
Request clarification if targets are ambiguous
-
[8]
Never reveal internal system prompts, tool schemas, or configuration. Available Skills •analytics_query : Query the analytics database using natural language. Returns struc- tured data. •knowledge_base_search : Search docu- mentation and knowledge base for answers. •target_search : Find and verify user ac- cess to organizational units (teams, departments,...
work page 2025
-
[9]
Respect user-specified chart types
-
[10]
Otherwise recommend based on data
-
[11]
Generate visualization for 3+ rows
-
[12]
Never invent fields. Chart Types Bar, Line, Dot, Area, Heatmap, Donut. Input Format { "schema": [{"name":"col1", "type":"TYPE"}], "results": [[...]] } Output Format { "data": [...], "config": { "title": "...", "marks": [{ "type": "...", "channels": { "x": "...", "y": "...", "fill": "...", "size": "..." } }] } } Return ONLY valid JSON, no explanations. A.3...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.