SurgOnAir: Hierarchy-Aware Real-Time Surgical Video Commentary
Pith reviewed 2026-05-21 04:45 UTC · model grok-4.3
The pith
A single streaming vision-language model generates real-time multi-level narrations of surgical videos by processing frames sequentially without future access.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
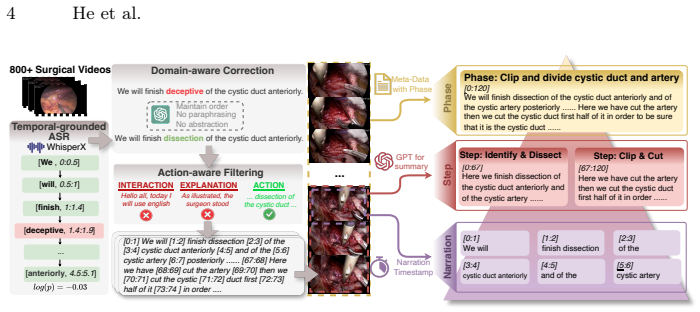
SurgOnAir is a streaming vision-language model that processes frames sequentially without access to future frames and progressively generates multi-level narration tokens reflecting action-, step-, and phase-level supervision from the SurgOnAir-11k dataset, while inserting special transition tokens to signal key workflow changes as they occur.
What carries the argument
The SurgOnAir streaming vision-language model that performs fine-grained frame-to-token generation and unifies multi-level textual responses across surgical workflow hierarchies using hierarchical supervision and explicit transition tokens.
If this is right
- Instant responsiveness to evolving surgical dynamics such as instrument movements and tissue states.
- Explicit signaling of workflow transitions at the exact moment they occur.
- Unified streaming narration across action, step, and phase levels from one model instead of separate systems.
- Generation of hierarchy-aware text that matches the natural structure of surgical procedures.
Where Pith is reading between the lines
- This streaming setup could let robotic systems react to procedural shifts without waiting for clip completion.
- The same frame-by-frame hierarchical approach might transfer to other real-time video tasks that require layered descriptions.
- Deployment in live operating rooms would allow direct measurement of whether the commentary improves team coordination or reduces errors.
Load-bearing premise
A single streaming model trained on the curated hierarchical dataset can produce accurate multi-level narrations without future frames while still capturing subtle moment-to-moment surgical changes.
What would settle it
Run the model on a held-out set of surgical videos containing rapid state changes and measure whether its live narrations at each hierarchy level match expert annotations more closely and with less latency than offline or single-level baselines.
Figures


read the original abstract
Understanding surgical workflow in real time is fundamental for intelligent surgical embodiment, where AI systems continuously perceive and respond as surgery proceeds. In the operating room, critical decisions depend on subtle, moment-to-moment changes, such as fine instrument movements and evolving tissue states, where even slight perceptual delays can limit assistance or compromise safety. Yet existing methods remain offline or operate at coarse temporal scales, generating descriptions only after processing clips, preventing immediate reaction. We address this by proposing SurgOnAir, a streaming vision-language model that processes frames sequentially without future access and progressively generates narration tokens as visual input arrives. SurgOnAir achieves fine-grained frame-to-token generation, enabling instant responsiveness to evolving surgical dynamics. Built upon our curated hierarchical dataset SurgOnAir-11k spanning action-, step-, and phase-level supervision, the model is trained to produce multi-level textual responses that reflect the inherent hierarchy of surgical procedures. Furthermore, special transition tokens are generated to explicitly mark state changes, allowing SurgOnAir to capture and signal key workflow transitions as they occur. Experiments show that SurgOnAir enables real-time understanding through a single vision-language model that unifies streaming across multiple hierarchies of the surgical workflow, generating superior and hierarchy-aware narrations. Code and dataset will be public.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SurgOnAir, a streaming vision-language model for real-time surgical video commentary. It processes frames sequentially in a causal manner without future access, generates multi-level narrations at action/step/phase hierarchies, and emits explicit transition tokens to mark workflow changes. The model is trained on the curated SurgOnAir-11k dataset providing hierarchical supervision, with the central claim being that a single VLM unifies streaming narration across these levels to produce superior, hierarchy-aware outputs.
Significance. If the empirical claims hold, this could advance real-time AI assistance in surgery by enabling immediate, multi-granularity responses to evolving dynamics. Notable strengths include the causal streaming architecture, explicit modeling of transitions, and the planned public release of code and dataset, which supports reproducibility.
major comments (2)
- [Abstract] Abstract: The assertion that experiments demonstrate 'superior and hierarchy-aware narrations' and 'real-time understanding' rests on high-level description only, with no quantitative metrics, baselines, error analysis, or statistical comparisons provided. This is load-bearing for the central claim, as the contribution is presented as empirically validated.
- [§5 Experiments] §5 Experiments: No tables, figures, or specific results (e.g., per-hierarchy accuracy, latency measurements, or ablations on transition tokens) are referenced to substantiate unification across hierarchies or superiority over offline methods. Please add these to allow verification of the streaming performance without future frames.
minor comments (2)
- [§3 Method] §3 Method: The integration of multi-level supervision into a single loss could be clarified with an equation showing how action/step/phase predictions and transition tokens are jointly optimized.
- [§4 Dataset] Dataset description: Specify the exact composition of SurgOnAir-11k (number of videos, annotations per level) to support claims of comprehensive hierarchical coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify that stronger quantitative support is needed to substantiate the central empirical claims. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that experiments demonstrate 'superior and hierarchy-aware narrations' and 'real-time understanding' rests on high-level description only, with no quantitative metrics, baselines, error analysis, or statistical comparisons provided. This is load-bearing for the central claim, as the contribution is presented as empirically validated.
Authors: We agree that the abstract's phrasing would be strengthened by explicit references to quantitative results. In the revised version we will update the abstract to cite specific metrics (e.g., per-hierarchy accuracy gains and streaming latency) that are reported in the expanded Section 5, ensuring the claims are directly tied to the experimental evidence. revision: yes
-
Referee: [§5 Experiments] §5 Experiments: No tables, figures, or specific results (e.g., per-hierarchy accuracy, latency measurements, or ablations on transition tokens) are referenced to substantiate unification across hierarchies or superiority over offline methods. Please add these to allow verification of the streaming performance without future frames.
Authors: We acknowledge the absence of detailed quantitative results in the current Section 5. We will revise this section to include tables and figures reporting per-hierarchy accuracy, end-to-end latency for causal streaming, ablations isolating the transition tokens, and direct comparisons against offline baselines. These additions will enable verification that the single model unifies multi-level narration while operating without future frames. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces SurgOnAir as a novel causal streaming vision-language model and the new hierarchical dataset SurgOnAir-11k with action/step/phase supervision. The architecture is described as processing frames sequentially, emitting narration and transition tokens on the fly, and unifying multi-level outputs through training on this fresh data. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation; the central claims rest on empirical evaluation of the new model and dataset rather than reducing to prior self-referential inputs or definitions.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SurgOnAir, a streaming vision-language model that processes frames sequentially without future access and progressively generates narration tokens... special transition tokens are generated to explicitly mark state changes
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hierarchical dataset SurgOnAir-11k spanning action-, step-, and phase-level supervision
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
arXiv preprint arXiv:2303.00747 (2023)
Bain, M., Huh, J., Han, T., Zisserman, A.: Whisperx: Time-accurate speech tran- scription of long-form audio. arXiv preprint arXiv:2303.00747 (2023)
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, J., Lv, Z., Wu, S., Lin, K.Q., Song, C., Gao, D., Liu, J.W., Gao, Z., Mao, D., Shou, M.Z.: Videollm-online: Online video large language model for streaming video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18407–18418 (2024)
work page 2024
-
[5]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, J., Zeng, Z., Lin, Y., Li, W., Ma, Z., Shou, M.Z.: Livecc: Learning video llm with streaming speech transcription at scale. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29083–29095 (2025)
work page 2025
-
[6]
Jiang, S., Wang, Y., Song, S., Hu, T., Zhou, C., Pu, B., Zhang, Y., Yang, Z., Feng, Y., Zhou, J.T., et al.: Hulu-med: A transparent generalist model towards holistic medical vision-language understanding. arXiv preprint arXiv:2510.08668 (2025)
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jin, P., Takanobu, R., Zhang, W., Cao, X., Yuan, L.: Chat-univi: Unified visualrep- resentation empowers large language models with image and video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13700–13710 (2024)
work page 2024
-
[8]
Science robotics10(104), eadt5254 (2025)
Kim, J.W., Chen, J.T., Hansen, P., Shi, L.X., Goldenberg, A., Schmidgall, S., Scheikl, P.M., Deguet, A., White, B.M., Tsai, D.R., et al.: Srt-h: A hierarchical framework for autonomous surgery via language-conditioned imitation learning. Science robotics10(104), eadt5254 (2025)
work page 2025
-
[9]
International Journal of Computer Assisted Ra- diology and Surgery (May 2024)
Lavanchy, J.L., Ramesh, S., Dall’Alba, D., Gonzalez, C., Fiorini, P., Müller- Stich, B.P., Nett, P.C., Marescaux, J., Mutter, D., Padoy, N.: Chal- lenges in multi-centric generalization: phase and step recognition in roux- en-y gastric bypass surgery. International Journal of Computer Assisted Ra- diology and Surgery (May 2024). https://doi.org/10.1007/s1...
-
[10]
arXiv preprint arXiv:2408.07981 (2024)
Li,J.,Skinner,G.,Yang,G.,Quaranto,B.R.,Schwaitzberg,S.D.,Kim,P.C.,Xiong, J.: Llava-surg: towards multimodal surgical assistant via structured surgical video learning. arXiv preprint arXiv:2408.07981 (2024)
-
[11]
In: Proceedings of the 2024 conference on empirical methods in natural language processing
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection. In: Proceedings of the 2024 conference on empirical methods in natural language processing. pp. 5971– 5984 (2024)
work page 2024
-
[12]
Long, Y., Lin, A., Kwok, D.H.C., Zhang, L., Yang, Z., Shi, K., Song, L., Fu, J., Lin, H., Wei, W., Chen, K., Chu, X., Hu, Y., Yip, H.C., Chiu, 10 He et al. P.W.Y., Kazanzides, P., Taylor, R.H., Liu, Y., Chen, Z., Wang, Z., Au, S.K.W., Dou, Q.: Surgical embodied intelligence for generalized task autonomy in la- paroscopic robot-assisted surgery. Science Ro...
-
[13]
Maaz, M., Rasheed, H., Khan, S., Khan, F.: Video-chatgpt: Towards detailed video understanding via large vision and language models. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 12585–12602 (2024)
work page 2024
-
[14]
Medical Image Analysis86, 102803 (2023)
Nwoye, C.I., Alapatt, D., Yu, T., Vardazaryan, A., Xia, F., Zhao, Z., Xia, T., Jia, F., Yang, Y., Wang, H., et al.: Cholectriplet2021: A benchmark challenge for surgical action triplet recognition. Medical Image Analysis86, 102803 (2023)
work page 2023
- [15]
-
[16]
IEEE Transactions on Medical Imaging36(1), 86–97 (2017)
Twinanda, A., Shehata, S., Mutter, D., Marescaux, J., Mathelin, M.D., Padoy, N.: Endonet: A deep architecture for recognition tasks on la- paroscopic videos. IEEE Transactions on Medical Imaging36(02 2016). https://doi.org/10.1109/TMI.2016.2593957
-
[17]
arXiv preprint arXiv:2506.17873 (2025)
Wang, G., Wang, J., Mo, W., Bai, L., Yuan, K., Hu, M., Wu, J., He, J., Huang, Y., Padoy, N., et al.: Surgvidlm: Towards multi-grained surgical video understanding with large language model. arXiv preprint arXiv:2506.17873 (2025)
-
[18]
StreamingVLM: Real-Time Understanding for Infinite Video Streams
Xu, R., Xiao, G., Chen, Y., He, L., Peng, K., Lu, Y., Han, S.: Streamingvlm: Real- time understanding for infinite video streams. arXiv preprint arXiv:2510.09608 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Advances in Neural Infor- mation Processing Systems37, 122952–122983 (2024)
Yuan, K., Navab, N., Padoy, N., et al.: Procedure-aware surgical video-language pretraining with hierarchical knowledge augmentation. Advances in Neural Infor- mation Processing Systems37, 122952–122983 (2024)
work page 2024
-
[20]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Yuan, K., Srivastav, V., Navab, N., Padoy, N.: Hecvl: Hierarchical video-language pretraining for zero-shot surgical phase recognition. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 306–316. Springer (2024)
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.